作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
前言
今天在 QQ 群裡的討論中看到了 Focal Loss,經搜尋它是 Kaiming 大神團隊在他們的論文 Focal Loss for Dense Object Detection 提出來的損失函式,利用它改善了影象物體檢測的效果。不過我很少做影象任務,不怎麼關心影象方面的應用。
本質上講,Focal Loss 就是一個解決分類問題中類別不平衡、分類難度差異的一個 loss,總之這個工作一片好評就是了。大家還可以看知乎的討論:如何評價 Kaiming 的 Focal Loss for Dense Object Detection?[1]
看到這個 loss,開始感覺很神奇,感覺大有用途。因為在 NLP 中,也存在大量的類別不平衡的任務。
最經典的就是序列標註任務中類別是嚴重不平衡的,比如在命名物體識別中,顯然一句話裡邊物體是比非物體要少得多,這就是一個類別嚴重不平衡的情況。我嘗試把它用在我的基於序列標註的問答模型中,也有微小提升。嗯,這的確是一個好 loss。
接著我再仔細對比了一下,我發現這個 loss 跟我昨晚構思的一個 loss 具有異曲同工之理。這就促使我寫這篇文章了。我將從我自己的思考角度出發,來分析這個問題,最後得到 Focal Loss,也給出我昨晚得到的類似的 loss。
硬截斷
整篇文章都是從二分類問題出發,同樣的思想可以用於多分類問題。二分類問題的標準 loss 是交叉熵。

其中 y∈{0,1} 是真實標簽,ŷ 是預測值。當然,對於二分類我們幾乎都是用 sigmoid 函式啟用 ŷ =σ(x),所以相當於:

我們有 1−σ(x)=σ(−x)。
我在上半年寫過的文章「文字情感分類(四):更好的損失函式」[2]中,曾經針對“集中精力關註難分樣本”這個想法提出了一個“硬截斷”的 loss,形式為:

其中:

這樣的做法就是:正樣本的預測值大於 0.5 的,或者負樣本的預測值小於 0.5 的,我都不更新了,把註意力集中在預測不準的那些樣本,當然這個閾值可以調整。這樣做能部分地達到目的,但是所需要的迭代次數會大大增加。
原因是這樣的:以正樣本為例,我只告訴模型正樣本的預測值大於 0.5 就不更新了,卻沒有告訴它要“保持”大於 0.5,所以下一階段,它的預測值就很有可能變回小於 0.5 了。
當然,如果是這樣的話,下一回合它又被更新了,這樣反覆迭代,理論上也能達到目的,但是迭代次數會大大增加。
所以,要想改進的話,重點就是“不只是要告訴模型正樣本的預測值大於0.5就不更新了,而是要告訴模型當其大於0.5後就只需要保持就好了”。
好比老師看到一個學生及格了就不管了,這顯然是不行的。如果學生已經及格,那麼應該要想辦法要他保持目前這個狀態甚至變得更好,而不是不管。
軟化 loss
硬截斷會出現不足,關鍵地方在於因子 λ(y,ŷ) 是不可導的,或者說我們認為它導數為 0,因此這一項不會對梯度有任何幫助,從而我們不能從它這裡得到合理的反饋(也就是模型不知道“保持”意味著什麼)。
解決這個問題的一個方法就是“軟化”這個 loss,“軟化”就是把一些本來不可導的函式用一些可導函式來近似,數學角度應該叫“光滑化”。
這樣處理之後本來不可導的東西就可導了,類似的算例還有「梯度下降和EM演演算法:系出同源,一脈相承」[3] 中的 kmeans 部分。我們首先改寫一下 L∗。

這裡的 θ 就是單位階躍函式:
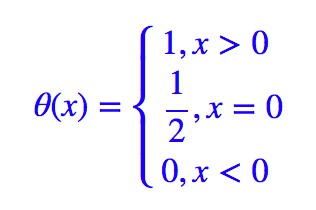
這樣的 L∗ 跟原來的是完全等價的,由於 σ(0)=0.5,因此它也等價於:

這時候思路就很明顯了,要想“軟化”這個 loss,就得“軟化” θ(x),而軟化它就再容易不過,它就是 sigmoid 函式。我們有:

所以很顯然,我們將 θ(x) 替換為 σ(Kx) 即可:

這就是我昨晚思考得到的 loss 了,顯然實現上也是很容易的。
現在跟 Focal Loss 做個比較。
Focal Loss
Kaiming 大神的 Focal Loss 形式是:
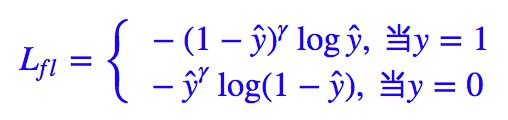
如果落實到 ŷ =σ(x) 這個預測,那麼就有:

特別地,如果 K 和 γ 都取 1,那麼 L∗∗=Lfl。
事實上 K 和 γ 的作用都是一樣的,都是調節權重曲線的陡度,只是調節的方式不一樣。註意 L∗∗ 或 Lfl 實際上都已經包含了對不均衡樣本的解決方法,或者說,類別不均衡本質上就是分類難度差異的體現。
比如負樣本遠比正樣本多的話,模型肯定會傾向於數目多的負類(可以想象全部樣本都判為負類),這時候,負類的 ŷ γ 或 σ(Kx) 都很小,而正類的 (1−ŷ )γ 或 σ(−Kx) 就很大,這時候模型就會開始集中精力關註正樣本。
當然,Kaiming 大神還發現對 Lfl 做個權重調整,結果會有微小提升。
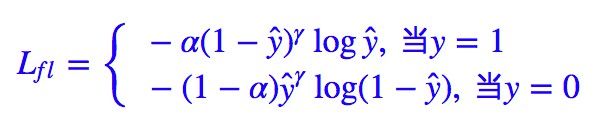
透過一系列調參,得到 α=0.25, γ=2(在他的模型上)的效果最好。註意在他的任務中,正樣本是屬於少數樣本,也就是說,本來正樣本難以“匹敵”負樣本,但經過 (1−ŷ )γ 和 ŷγ 的“操控”後,也許形勢還逆轉了,還要對正樣本降權。
不過我認為這樣調整隻是經驗結果,理論上很難有一個指導方案來決定 α 的值,如果沒有大算力調參,倒不如直接讓 α=0.5(均等)。
多分類
Focal Loss 在多分類中的形式也很容易得到,其實就是:

ŷt 是標的的預測值,一般就是經過 softmax 後的結果。那我自己構思的 L∗∗ 怎麼推廣到多分類?也很簡單:

這裡 xt 也是標的的預測值,但它是 softmax 前的結果。
結語
什麼?你得到了跟 Kaiming 大神一樣想法的東西?
不不不,本文只是對 Kaiming 大神的 Focal Loss 的一個介紹而已。更準確地說,是應對分類不平衡、分類難度差異的一些方案的介紹,並盡可能給出自己的看法而已。當然,本文這樣的寫法難免有附庸風雅、東施效顰之嫌,請讀者海涵。
相關連結
[1]. 如何評價 Kaiming 的 Focal Loss for Dense Object Detection?
https://www.zhihu.com/question/63581984
[2]. 文字情感分類(四):更好的損失函式
http://kexue.fm/archives/4293/
[3]. 梯度下降和EM演演算法:系出同源,一脈相承
http://kexue.fm/archives/4277/
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群