
本文經機器之心(微信公眾號:almosthuman2014)授權轉載,禁止二次轉載”
在眾多經典的貝葉斯方法中,馬爾可夫鏈蒙特卡洛(MCMC)由於包含大量數學知識,且計算量很大,而顯得格外特別。本文反其道而行之,試圖透過通俗易懂且不包含數學語言的方法,幫助讀者對 MCMC 有一個直觀的理解,使得毫無數學基礎的人搞明白 MCMC。
在我們中的很多人看來,貝葉斯統計學家不是巫術師,就是完全主觀的胡說八道者。在貝葉斯經典方法中,馬爾可夫鏈蒙特卡洛(Markov chain Monte Carlo/MCMC)尤其神秘,其中數學很多,計算量很大,但其背後原理與資料科學有諸多相似之處,並可闡釋清楚,使得毫無數學基礎的人搞明白 MCMC。這正是本文的標的。
那麼,到底什麼是 MCMC 方法?一言以蔽之:
MCMC 透過在機率空間中隨機取樣以近似興趣引數(parameter of interest)的後驗分佈。
我將在本文中做出簡短明瞭的解釋,並且不借助任何數學知識。
首先,解釋重要的術語。「興趣引數」(parameter of interest)可以總結我們感興趣現象的一些數字。我們通常使用統計學評估引數,比如,如果想要瞭解成年人的身高,我們的興趣引數可以是精確到英寸的平均身高。「分佈」是引數的每個可能值、以及我們有多大可能觀察每個引數的數學表徵,其最著名的實體是鐘形曲線:
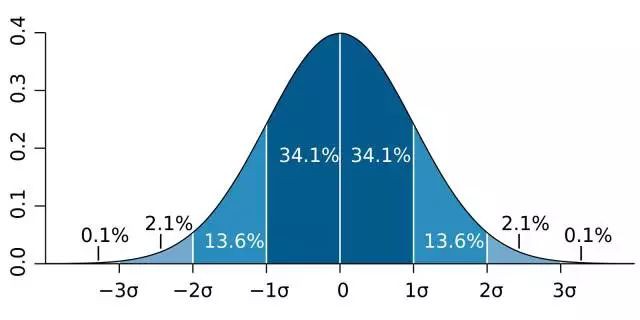
在貝葉斯統計學中,分佈還有另外一種解釋。貝葉斯不是僅僅表徵一個引數值以及每個引數有多大可能是真值,而是把分佈看作是我們對引數的「信念」。因此,鐘形曲線表明我們非常確定引數值相當接近於零,但是我們認為在一定程度上真值高於或低於該值的可能性是相等的。
事實上,人的身高確實遵從一個正態曲線,因此我們假定平均身高的真值符合鐘形曲線,如下所示:

很明顯,上圖表徵是巨人的身高分佈,因為據圖可知,最有可能的平均身高是 6’2″(但他們也並非超級自信)。
讓我們假設其中某個人後來收集到一些資料,並且觀察了身高在 5″和 6″之間的一些人。我們可以用另一條正態曲線表徵下麵的資料,該曲線表明瞭哪些平均身高值能最好地解釋這些資料:
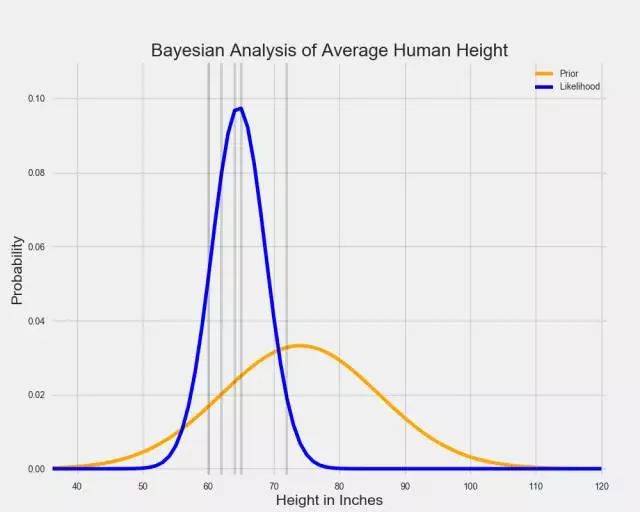
在貝葉斯統計中,表徵我們對引數信念的分佈被稱為「先驗分佈」,因為它在我們看到任何資料之前捕捉到了我們的信念。「可能性分佈」(likelihood distribution)透過表徵一系列引數值以及伴隨的每個引數值解釋觀察資料的可能性,以總結資料之中的資訊。評估最大化可能性分佈的引數值只是回答這一問題:什麼引數值會使我們更可能觀察到已經觀察過的資料?如果沒有先驗信念,我們可能無法對此作出評估。
但是,貝葉斯分析的關鍵是結合先驗與可能性分佈以確定後驗分佈。它可以告訴我們哪個引數值最大化了觀察到已觀察過的特定資料的機率,並把先驗信念考慮在內。在我們的實體中,後驗分佈如下所示:

如上所示,紅線表徵後驗分佈。你可以將其看作先驗和可能性分佈的一種平均值。由於先驗分佈較小且更加分散,它表徵了一組關於平均身高真值的「不太確定」的信念。同時,可能性分佈在相對較窄的範圍內總結資料,因此它表徵了對真引數值的「更確定」的猜測。
當先驗與可能性分佈結合在一起,資料(由可能性分佈表徵)主導了假定存在於這些巨人之中的個體的先驗弱信念。儘管該個體依然認為平均身高比資料告訴他的稍高一些,但是他非常可能被資料說服。
在兩條鐘形曲線的情況下,求解後驗分佈非常容易。有一個結合了兩者的簡單等式。但是如果我們的先驗和可能性分佈表現很差呢?有時使用非簡化的形狀建模資料或先驗信念時是最精確的。如果可能性分佈需要帶有兩個峰值的分佈才能得到最好地表徵呢?並且出於某些原因我們想要解釋一些非常奇怪的先驗分佈?透過手動繪製一個醜陋的先驗分佈,我已可視化了該情景,如下所示:

視覺化由 Matplotlib 渲染,並使用 MS Paint 做了改善
如前所述,存在一些後驗分佈,它給出了每個引數值的可能性分佈。但是很難得到完整的分佈,也無法解析地求解。這就是使用 MCMC 方法的時候了。
MCMC 允許我們在無法直接計算的情況下評估後驗分佈的形狀。為了理解其工作原理,我將首先介紹蒙特卡洛模擬(Monte Carlo simulation),接著討論馬爾可夫鏈。
蒙特卡洛模擬只是一種透過不斷地生成隨機數來評估固定引數的方法。透過生成隨機數並對其做一些計算,蒙特卡洛模擬給出了一個引數的近似值(其中直接計算是不可能的或者計算量過大)。
假設我們想評估下圖中的圓圈面積:
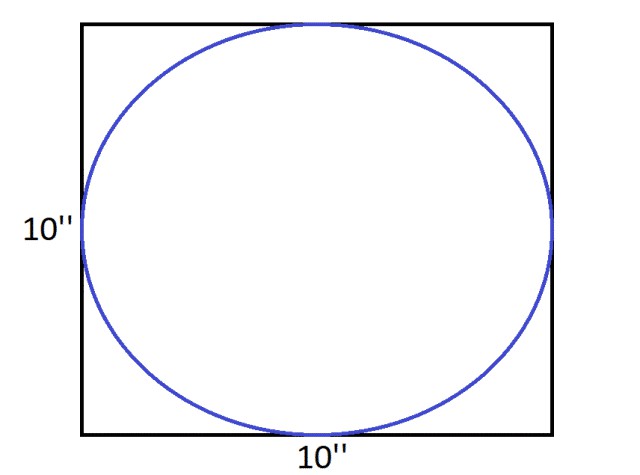
由於圓在邊長為 10 英寸的正方形之內,所以透過簡單計算可知其面積為 78.5 平方英寸。但是,如果我們隨機地在正方形之內放置 20 個點,接著我們計算點落在圓內的比例,並乘以正方形的面積,所得結果非常近似於圓圈面積。
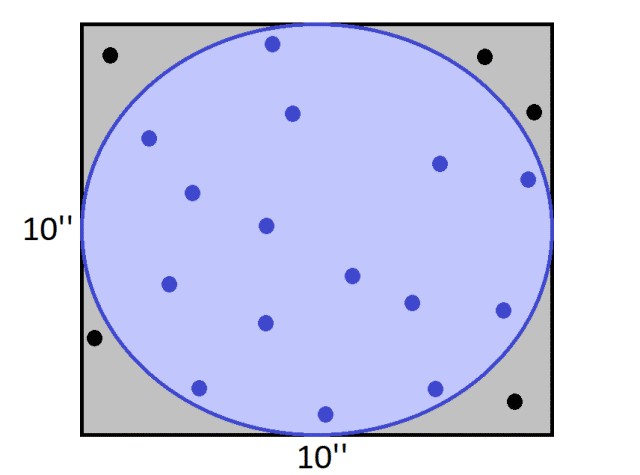
由於 15 個點落在了圓內,那麼圓的面積可以近似地為 75 平方英寸,對於只有 20 個隨機點的蒙特卡洛模擬來說,結果並不差。
現在,假設我們想要計算下圖中由蝙蝠俠方程(Batman Equation)繪製的圖形的面積:

我們從來沒有學過一個方程可以求這樣的面積。不管怎樣,透過隨機地放入隨機點,蒙特卡洛模擬可以相當容易地為該面積提供一個近似值。
蒙特卡洛模擬不只用於估算複雜形狀的面積。透過生成大量隨機數字,它還可用於建模非常複雜的過程。實際上,蒙特卡洛模擬還可以預測天氣,或者評估選舉獲勝的機率。
理解 MCMC 方法的第二個要素是馬爾科夫鏈(Markov chains)。馬爾科夫鏈由存在機率相關性的事件的序列構成。每個事件源於一個結果集合,根據一個固定的機率集合,每個結果決定了下一個將出現的結果。
馬爾科夫鏈的一個重要特徵是「無記憶性」:可能需要用於預測下一個時間的一切都已經包含在當前的狀態中,從事件的歷史中得不到任何新資訊。例如 Chutes and Ladders 這個遊戲就展示了這種無記憶性,或者說馬爾科夫性,但在現實世界中很少事物是這種性質的。儘管如此,馬爾科夫鏈也是理解現實世界的強大工具。
在十九世紀,人們觀察到鐘形曲線在自然中是一種很常見的樣式。(我們註意到,例如,人類的身高服從鐘形曲線分佈。)Galton Boards 曾透過將彈珠墜落並透過佈滿木釘的板模擬了重覆隨機事件的平均值,在彈珠的最終數量分佈中重現了鐘形曲線:

俄羅斯數學家和神學家 Pavel Nekrasov 認為鐘形曲線,或者更一般的說,大數規律只不過是小孩子的遊戲和普通的謎題中的偽假象,其中每個事件之間都是完全獨立的。他認為現實世界中的互相依賴的事件,例如人類行為,並不遵循漂亮的數學樣式或分佈。
Andrey Markov(馬爾科夫鏈正是以他的名字命名)試圖證明非獨立的事件可能也遵循特定的樣式。他的其中一個最著名的例子是從一份俄羅斯詩歌作品中數出幾千個兩字元對(two-character pairs)。他使用這些兩字元對計算了每個字元的條件機率。即,給定一個確定的上述字母或空白,關於下一個字母將是 A、T 或者空白等,存在一個確定的機率。透過這些機率,Markov 可以模擬一個任意的長字元序列。這就是馬爾科夫鏈。雖然早先的幾個字元很大程度上依賴於初始字元的選擇,Markov 表明在長字元序列中,字元的分佈會出現特定的樣式。因此,即使是互相依賴的事件,如果服從固定的機率分佈,將遵循平均水平的樣式。
舉一個更有意義的例子,假設你住在一個有 5 個房間的房子裡,裡面有一個臥室、浴室、客廳、廚房、飯廳。然後我們收集一些資料,假定只需要當前你所處的房間和相應的時間就可以預測下一個你所處的房間的機率。例如,如果你在廚房,你有 30% 的機率會留在廚房,有 30% 的機率會走到飯廳,有 20% 的機率會走到客廳,有 10% 的機率會走到浴室,以及有 10% 的機率會走到臥室。使用每個房間的機率集合,我們可以構建一個關於你接下來要去的房間的預測鏈。
如果想預測一個人處於廚房之後所在的房間,基於幾個狀態而做出預測可能有效。但由於我們的預測僅僅基於一個人在房子中的單次觀察,可以合理地認為預測結果是不夠好的。例如,如果一個人從臥室走到浴室,相比從廚房走到浴室的情況,他更可能會傳回原來的房間。因此,馬爾科夫鏈並不真正適用於現實世界。
然而,透過迭代執行馬爾科夫鏈數千次,確實能給出關於你接下來可能所處的房間的長期預測。更重要的是,這個預測並不受這個人起始所處的房間的影響。對此可以直觀地理解為:在模擬和描述長期過程(或普遍情況)一個人所處房間的機率時,時間因素是不重要的。因此,如果我們理解了控制行為的機率,就可以使用馬爾科夫鏈計算變化的長期趨勢。
希望透過介紹一些蒙特卡洛模擬和馬爾科夫鏈,可以使你對 MCMC 方法的零數學解釋有更直觀的理解。
回到原來的問題,即評估平均身高的後驗分佈:

這個平均身高的後驗分佈的實體沒有基於真實資料。
我們知道後驗分佈在某種程度上處於先驗分佈和可能性分佈的範圍內,但無論如何都無法直接計算。使用 MCMC 方法,我們可以有效地從後驗分佈中提取樣本,然後計算統計特徵,例如提取樣本的平均值。
首先,MCMC 方法選擇一個隨機引數值。模擬過程中會持續生成隨機的值(即蒙特卡洛部分),但服從某些能生成更好引數值的規則。即對於一對引數值,可以透過給定先驗信度計算每個值解釋資料的有效性,從而確定哪個值更好。我們會將更好的引數值以及由這個值的解釋資料有效性決定的特定機率新增到引數值的鏈中(即馬爾科夫鏈部分)。
為了視覺化地解釋上述過程,首先強調一下,一個分佈的特定值的高度代表的是觀察到該值的機率。因此,引數值(x 軸)對應的機率(y 軸)可能或高或低。對於單個引數,MCMC 方法會從隨機在 x 軸上取樣開始。

紅點表徵隨機引數取樣。
由於隨機取樣服從固定的機率,它們傾向於經過一段時間後收斂於引數的高機率區域:
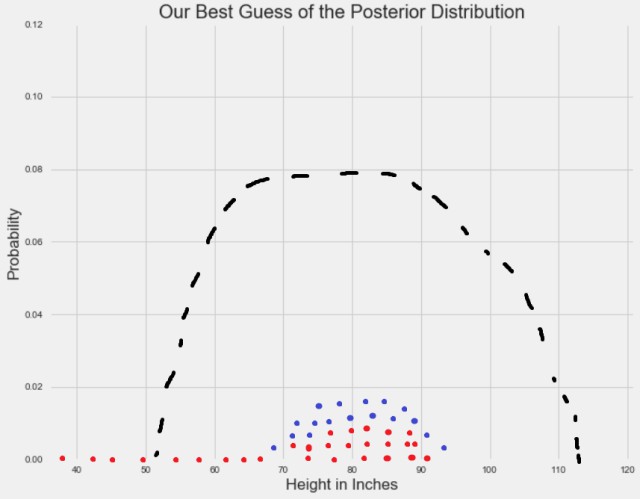
藍點表示當取樣收斂之後,經過任意時間的隨機取樣。註意:垂直堆疊這些點僅僅是為了說明目的。
收斂出現之後,MCMC 取樣會得到作為後驗分佈樣本的一系列點。用這些點畫直方圖,然後你可以計算任何感興趣的統計特徵:

透過 MCMC 模擬生成的樣本集合計算的任何統計特徵,都是對真實後驗分佈的統計特徵的最佳近似。
MCMC 方法也可以用於評估多於一個引數的後驗分佈(例如,人類身高和體重)。對於 n 個引數,在 n 維空間中存在高機率的區域,其中特定的引數值集合可以更有效地解釋資料。因此,我認為 MCMC 方法的本質,就是在一個機率空間中進行隨機取樣以近似後驗分佈。
原文連結:https://towardsdatascience.com/a-zero-math-introduction-to-markov-chain-monte-carlo-methods-dcba889e0c50
精彩活動
推薦閱讀
2017年資料視覺化的七大趨勢!
全球100款大資料工具彙總(前50款)
Q: 現在瞭解MCMC 方法了嗎?
你認為它還有哪些應用?
歡迎留言與大家分享
請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:hzzy@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

