前言
假如面試官讓你編寫求斐波那契數列的程式碼時,是不是心中暗喜?不就是遞迴麼,早就會了。如果真這麼想,那就危險了。
遞迴解法
遞迴,在數學與電腦科學中,是指在函式的定義中使用函式自身的方法。
斐波那契數列的計算運算式很簡單:
F(n) = n; n = 0,1
F(n) = F(n-1) + F(n-2),n >= 2;
因此,我們能很快根據運算式寫出遞迴版的程式碼:
/*fibo.c*/
#include
#include
/*求斐波那契數列遞迴版*/
unsigned long fibo(unsigned long int n)
{
if(n <= 1)
return n;
else
return fibo(n-1) + fibo(n-2);
}
int main(int argc,char *argv[])
{
if(1 >= argc)
{
printf("usage:./fibo num\n");
return -1;
}
unsigned long n = atoi(argv[1]);
unsigned long fiboNum = fibo(n);
printf("the %lu result is %lu\n",n,fiboNum);
return 0;
}
關鍵程式碼只有4行。簡潔明瞭,一氣呵成。
編譯:
gcc -o fibo fibo.c
執行計算第5個斐波那契數:
$ time ./fibo 5
the 5 result is 5
real 0m0.001s
user 0m0.001s
sys 0m0.000s
看起來並沒有什麼不妥,執行時間也很短。
繼續計算第50個斐波那契數列:
$ time ./fibo 50
the 50 result is 12586269025
real 1m41.655s
user 1m41.524s
sys 0m0.076s
計算第50個斐波那契數的時候,竟然將近兩多鐘!
遞迴分析
為什麼計算第50個的時候竟然需要1分多鐘。我們仔細分析我們的遞迴演演算法,就會發現問題,當我們計算fibo(5)的時候,是下麵這樣的:
|--F(1)
|--F(2)|
|--F(3)| |--F(0)
| |
|--F(4)| |--F(1)
| |
| | |--F(1)
| |--F(2)|
| |--F(0)
F(5)|
| |--F(1)
| |--F(2)|
| | |--F(0)
|--F(3)|
|
|--F(1)
為了計算fibo(5),需要計算fibo(3),fibo(4);而為了計算fibo(4),需要計算fibo(2),fibo(3)……最終為了得到fibo(5)的結果,fibo(0)被計算了3次,fibo(1)被計算了5次,fibo(2)被計算了2次。可以看到,它的計算次數幾乎是指數級的!
因此,雖然遞迴演演算法簡潔,但是在這個問題中,它的時間複雜度卻是難以接受的。除此之外,遞迴函式呼叫的越來越深,它們在不斷入棧卻遲遲不出棧,空間需求越來越大,雖然訪問速度高,但大小是有限的,最終可能導致棧上限溢位。
在linux中,我們可以透過下麵的命令檢視棧空間的軟限制:
$ ulimit -s
8192
可以看到,預設棧空間大小隻有8M。一般來說,8M的棧空間對於一般程式完全足夠。如果8M的棧空間不夠使用,那麼就需要重新審視你的程式碼設計了。
遞迴改進版
既然我們知道最初版本的遞迴存在大量的重覆計算,那麼我們完全可以考慮將已經計算的值儲存起來,從而避免重覆計算,該版本程式碼實現如下:
/*fibo0.c*/
#include
#include
/*求斐波那契數列,避免重覆計算版本*/
unsigned long fiboProcess(unsigned long *array,unsigned long n)
{
if(n 2)
return n;
else
{
/*遞迴儲存值*/
array[n] = fiboProcess(array,n-1) + array[n-2];
return array[n];
}
}
unsigned long fibo(unsigned long n)
{
if(n <= 1)
return n;
unsigned long ret = 0;
/*申請陣列用於儲存已經計算過的內容*/
unsigned long *array = (unsigned long*)calloc(n+1,sizeof(unsigned long));
if(NULL == array)
{
return -1;
}
array[1] = 1;
ret = fiboProcess(array,n);
free(array);
array = NULL;
return ret;
}
/**main函式部分與fibo.c相同,這裡省略*/
效率如何呢?
$ gcc -o fibo0 fibo0.c
$ time ./fibo0 50
the 50 result is 12586269025
real 0m0.002s
user 0m0.000s
sys 0m0.002s
可見其效率還是不錯的,時間複雜度為O(n)。但是特別註意的是,這種改進版的遞迴,雖然避免了重覆計算,但是呼叫鏈仍然比較長。
迭代解法
既然遞迴法不夠優雅,我們換一種方法。如果不用計算機計算,讓你去算第n個斐波那契數,你會怎麼做呢?我想最簡單直接的方法應該是:知道第一個和第二個後,計算第三個;知道第二個和第三個後,計算第四個,以此類推。最終可以得到我們需要的結果。這種思路,沒有冗餘的計算。基於這個思路,我們的C語言實現如下:
/*fibo1.c*/
#include
#include
/*求斐波那契數列迭代版*/
unsigned long fibo(unsigned long n)
{
unsigned long preVal = 1;
unsigned long prePreVal = 0;
if(n <= 2)
return n;
unsigned long loop = 1;
unsigned long returnVal = 0;
while(loop {
returnVal = preVal +prePreVal;
/*更新記錄結果*/
prePreVal = preVal;
preVal = returnVal;
loop++;
}
return returnVal;
}
/**main函式部分與fibo.c相同,這裡省略*/
編譯並計算第50個斐波那契數:
$ gcc -o fibo1 fibo1.c
$ time ./fibo1 50
the 50 result is 12586269025
real 0m0.002s
user 0m0.000s
sys 0m0.002s
可以看到,計算第50個斐波那契數只需要0.002s!時間複雜度為O(n)。
尾遞迴解法
同樣的思路,但是採用尾遞迴的方法來計算。要計算第n個斐波那契數,我們可以先計算第一個,第二個,如果未達到n,則繼續遞迴計算,尾遞迴C語言實現如下:
/*fibo2.c*/
#include
#include
/*求斐波那契數列尾遞迴版*/
unsigned long fiboProcess(unsigned long n,unsigned long prePreVal,unsigned long preVal,unsigned long begin)
{
/*如果已經計算到我們需要計算的,則傳回*/
if(n == begin)
return preVal+prePreVal;
else
{
begin++;
return fiboProcess(n,preVal,prePreVal+preVal,begin);
}
}
unsigned long fibo(unsigned long n)
{
if(n <= 1)
return n;
else
return fiboProcess(n,0,1,2);
}
/**main函式部分與fibo.c相同,這裡省略*/
效率如何呢?
$ gcc -o fibo2 fibo2.c
$ time ./fibo2 50
the 50 result is 12586269025
real 0m0.002s
user 0m0.001s
sys 0m0.002s
可見,其效率並不遜於迭代法。尾遞迴在函式傳回之前的最後一個操作仍然是遞迴呼叫。尾遞迴的好處是,進入下一個函式之前,已經獲得了當前函式的結果,因此不需要保留當前函式的環境,記憶體佔用自然也是比最開始提到的遞迴要小。時間複雜度為O(n)。
矩陣快速冪解法
這是一種高效的解法,需要推導,對此不感興趣的可直接看最終推導結果。下麵的式子成立是顯而易見的,不多做解釋。
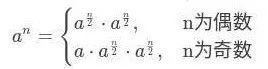
如果a為矩陣,等式同樣成立,後面我們會用到它。
假設有矩陣2*2矩陣A,滿足下麵的等式:
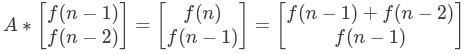
可以得到矩陣A: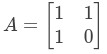
因此也就可以得到下麵的矩陣等式: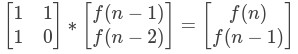
再進行變換如下:
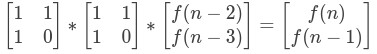
以此類推,得到: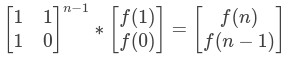
實際上f(n)就是矩A^(n-1)中的A[0][0],或者是矩A^n中的A[0][1]。
那麼現在的問題就歸結為,如何求A^n,其中A為2*2的矩陣。根據我們最開始的公式,很容易就有思路,程式碼實現如下:
/*fibo3.c*/
#include
#include
#include
#define MAX_COL 2
#define MAX_ROW 2
typedef unsigned long MatrixType;
/*計算2*2矩陣乘法,這裡沒有寫成通用形式,有興趣的可以自己實現通用矩陣乘法*/
int matrixDot(MatrixType A[MAX_ROW][MAX_COL],MatrixType B[MAX_ROW][MAX_COL],MatrixType C[MAX_ROW][MAX_COL])
{
/*C為傳回結果,由於A可能和C相同,因此使用臨時矩陣儲存*/
MatrixType tempMa[MAX_ROW][MAX_COL] ;
memset(tempMa,0,sizeof(tempMa));
/*這裡簡便處理*/
tempMa[0][0] = A[0][0] * B[0][0] + A[0][1] * B [1][0];
tempMa[0][1] = A[0][0] * B[0][1] + A[0][1] * B [1][1];
tempMa[1][0] = A[1][0] * B[0][0] + A[1][1] * B [1][0];
tempMa[1][1] = A[1][0] * B[0][1] + A[1][1] * B [1][1];
memcpy(C,tempMa,sizeof(tempMa));
return 0;
}
MatrixType fibo(int n)
{
if(n <= 1)
return n;
MatrixType result[][MAX_COL] = {1,0,0,1};
MatrixType A[][2] = {1,1,1,0};
while (n > 0)
{
/*判斷最後一位是否為1,即可知奇偶*/
if (n&1)
{
matrixDot(result,A,result);
}
n /= 2;
matrixDot(A,A,A);
}
return result[0][1];
}
/**main函式部分與fibo.c相同,這裡省略*/
該演演算法的關鍵部分在於對A^n的計算,它利用了我們開始提到的等式,對奇數和偶數分別處理。假設n為9,初始矩陣為INIT則計算過程如下:
-
9為奇數,則計算INIT*A,隨後A變為A*A,n變為9/2,即為4
-
4為偶數,則結果仍為INIT*A,隨後A變為
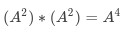 ,n變為4/2,即2
,n變為4/2,即2 -
2為偶數,則結果仍未INIT*A,隨後變A變為
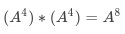 ,n變為2/2,即1
,n變為2/2,即1 -
1為奇數,則結果為INIT*(A^8)*A
可以看到,計算次數類似與二分查詢次數,其時間複雜度為O(logn)。
執行試試看:
$ gcc -o fibo3 fibo3.c
$ time ./fibo3 50
the 50 result is 12586269025
real 0m0.002s
user 0m0.002s
sys 0m0.000s
通項公式解法
斐波那契數列的通項公式為:
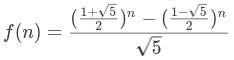
關於通項公式的求解,可以當成一道高考數列大題,有興趣的可以嘗試一下(提示:兩次構造等比數列)。C語言程式碼實現如下:
/*fibo4.c*/
#include
#include
#include
unsigned long fibo(unsigned long n)
{
if(n <=1 )
return n;
return (unsigned long)((pow((1+sqrt(5))/2,n)-pow((1-sqrt(5))/2,n))/sqrt(5));
}
/**main函式部分與fibo.c相同,這裡省略*/
來看一下效率:
$ gcc -o fibo4 fibo4.c -lm
$ time ./fibo4
the 50 result is 12586269025
real 0m0.002s
user 0m0.002s
sys 0m0.000s
計算第50個,速度還不錯。
串列法
如果需要求解的斐波那契數列的第n個在有限範圍內,那麼完全可以將已知的斐波那契數列儲存起來,在需要的時候讀取即可,時間複雜度可以為O(1)。
斐波那契數列應用
關於斐波那契數列在實際中很常見,數學上也有很多奇特的性質,有興趣的可在百科中檢視。
總結
總結一下遞迴的優缺點:
優點:
-
實現簡單
-
可讀性好
缺點:
-
遞迴呼叫,佔用空間大
-
遞迴太深,易發生棧上限溢位
-
可能存在重覆計算
可以看到,對於求斐波那契數列的問題,使用一般的遞迴並不是一種很好的解法。
所以,當你使用遞迴方式實現一個功能之前,考慮一下使用遞迴帶來的好處是否抵得上它的代價。
【本文作者】
守望:一名好文學,好技術的開發者。在個人公眾號「程式設計珠璣」分享原創技術文章,期待一起交流學習