

隨著網際網路的發展,資料日益增多,增長超過了單機能夠處理的上線,資料如何儲存和處理成為了科技公司的難題,隨著google的三篇論文的釋出,大家終於找到了一個方案:分散式檔案系統+MapReduce。Hadoop是參考google論文實現的,集成了分散式檔案系統與分散式批處理平臺。hadoop的設計標的是用來解決大檔案海量儲存和批處理的,為了避免單個節點故障導致資料丟失,設計副本冗餘機制。 本文將主要分析一下幾個方面:
- HDFS的概念與架構
- NameNode的HA機制
- 讀寫流程分析
- 使用場景與缺點
1、HDFS的概念與架構
HDFS採用的master/slave架構。一個HDFS叢集通常由一個Active的NameNode和若干DataNode組成,為了避免NameNode單點問題,通常會做一個NameNode的standby作為備份。在整個hdfs涉及到許多的核心概念,下麵做一個簡單介紹
- NameNode: NameNode是一個中心伺服器,負責管理檔案系統的名字空間以及客戶端的訪問,比如檔案的打卡、關閉、重新命名檔案或者目錄。它負責確定資料塊到具體的儲存節點的對映。在其同意排程下進行資料塊的建立、刪除、複製。
- DataNode: DataNode是HDFS的實際儲存節點,負責管理它所在節點的儲存;客戶端的讀寫請求。並且定期上報心跳和塊的儲存位置。
- Block: HDFS上檔案,從其內部看,一個檔案其實是被分成一個或者多個資料塊儲存的,這些資料塊儲存在一組DataNode上。
- Edits: 在HDFS發起的建立、刪除等操作其實是一個事物,事物在NameNode上以Edit物件儲存在edits檔案中,持久化在NameNode的本地磁碟上。
- FSimage: FSimage是NameNode的元資料儲存快照,持久化在NameNode的本地磁碟上。
當NameNode重啟的時候,NameNode從FSImage和Edits檔案中讀取資料,載入到記憶體中。
在HDFS體系來看,NameNode主要負責元資料的儲存與操作,DataNode負責實際的儲存。DataNode通常在一個機器上部署一個行程,這些機器分散式在多個機架上。整體架構如下圖所示:

客戶端操作HDFS上的檔案時,向NameNode獲取檔案的元資料資訊,NameNode傳回檔案的塊儲存位置,Client選擇塊儲存位置最近的節點進行塊操作。通常優先順序是本機>本機櫃>其他機櫃的節點。資料塊的分散式通常是在同一機架的兩個節點儲存兩份,為了避免單個機架的故障導致資料塊丟失,會選擇在另外一個機架上的節點儲存一份。如果把資料儲存在三個不同的機架上,由於不同機架之間透過交換機進行資料交換,網路速度會比單機架慢,因此複製資料也會慢,此外,還會增加機架之間的交換機的壓力。資料塊分佈如下圖:

DataNode除了負責客戶端的讀寫操作外,還需要定期的向NameNode的active和standby做心跳彙報,如果有DataNode的心跳異常,被確定為死的節點,NameNode將會對儲存在該節點的資料進行複製,保證資料塊的資料塊的副本數。DataNode除了心跳還會將本節點的資料塊上報給NameNode的active和standby。
2、NameNode的HA機制
在hadoop 1.x的時候,NameNode儲存單點問題,導致叢集故障,成為叢集的瓶頸。在hadoop 2.x之後,增加了NameNode的HA機制。對於NameNode單點問題,大家首先想到的解決方案是給NameNode做一些備份,但是難點是在於如何保證NameNode和它的備份節點的資料一致性問題。在分散式環境下要保證資料一致性問題,需要考慮的問題很多,比如腦裂,分割槽容錯,一致性協議等等。下麵一起看看Hadoop是如何解決的。
HA的架構

上圖是Hadoop的2.x版本提供的NameNode的HA機制的架構。在這個架構體系涉及到Zookeeper,NameNode Active和NameNode Standby和共享儲存空間,ZKFC。在整個高可用架構中,Active NameNode和Standby NameNode兩臺NameNode形成互備,一臺處於Active狀態,作為主節點,另外一臺是Standby狀態,作為備節點,只有主節點才能對外提供讀寫服務。
ZKFC(ZKFailoverContoller)作為獨立的行程執行,對NameNode的主備切換進行總體控制。ZKFC能夠及時加測到NameNode的健康狀況,在active的NameNode故障的時候,藉助Zookeeper實現自動主備選舉和切換。當然,NameNode目前也支援不依賴Zookeeper的手動主備切換。Zookeeper叢集主要是為控制器提供主被選舉支援。
共享儲存系統是NameNode實現高可用的關鍵部分,共享儲存系統儲存了NameNode執行過程中的所有產生的HDFS的元資料。active NameNode和standby NameNode透過共享儲存系統實現元資料同步。在主備切換的時候,新的active NameNode在確認元資料同步之後才能繼續對外提供服務。
除了透過共享儲存系統共享HDFS的元資料資訊之外,active NameNode和 standby NameNode還需要共享HDFS的資料塊和DataNode之間的對映關係,DataNode會同時向active NameNode和standby NameNode上報資料塊位置資訊。
基於QJM的共享儲存系統
共享儲存系統主要是由多個JournalNode行程組成,JournalNode由奇數個組成。當Active NameNode中有事物提交,active NameNode會將editLog發給jouranlNode叢集,journalNode叢集透過paxos協議保證資料一致性(即:超過一半以上的jounalNode節點確認),這個資料完成了提交到共享儲存。standby NameNode定期從journalNode讀取editLog,合併到自己的fsimage上。總體的架構如下:
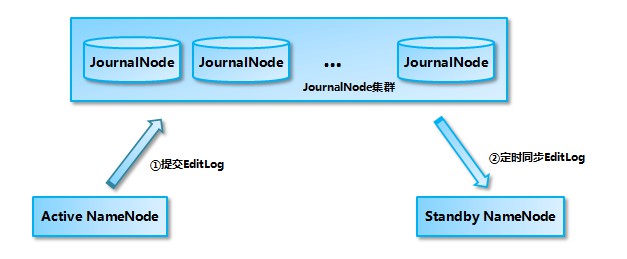
處於 Standby 狀態的 NameNode 轉換為 Active 狀態的時候,有可能上一個 Active NameNode 發生了異常退出,那麼 JournalNode 叢集中各個 JournalNode 上的 EditLog 就可能會處於不一致的狀態,所以首先要做的事情就是讓 JournalNode 叢集中各個節點上的 EditLog 恢復為一致。
另外如前所述,當前處於 Standby 狀態的 NameNode 的記憶體中的檔案系統映象有很大的可能是落後於舊的 Active NameNode 的,所以在 JournalNode 叢集中各個節點上的 EditLog 達成一致之後,接下來要做的事情就是從 JournalNode 叢集上補齊落後的 EditLog。只有在這兩步完成之後,當前新的 Active NameNode 才能安全地對外提供服務。
基於QJM的共享儲存系統內部實現

- FSEditLog:這個類封裝了對 EditLog 的所有操作,是 NameNode 對 EditLog 的所有操作的入口。
- JournalSet: 這個類封裝了對本地磁碟和 JournalNode 叢集上的 EditLog 的操作,內部包含了兩類 JournalManager,一類為 FileJournalManager,用於實現對本地磁碟上 EditLog 的操作。一類為 QuorumJournalManager,用於實現對 JournalNode 叢集上共享目錄的 EditLog 的操作。FSEditLog 只會呼叫 JournalSet 的相關方法,而不會直接使用 FileJournalManager 和 QuorumJournalManager。
- FileJournalManager:封裝了對本地磁碟上的 EditLog 檔案的操作,不僅 NameNode 在向本地磁碟上寫入 EditLog 的時候使用 FileJournalManager,JournalNode 在向本地磁碟寫入 EditLog 的時候也復用了 FileJournalManager 的程式碼和邏輯。
- QuorumJournalManager:封裝了對 JournalNode 叢集上的 EditLog 的操作,它會根據 JournalNode 叢集的 URI 建立負責與 JournalNode 叢集通訊的類 AsyncLoggerSet, QuorumJournalManager 透過 AsyncLoggerSet 來實現對 JournalNode 叢集上的 EditLog 的寫操作,對於讀操作,QuorumJournalManager 則是透過 Http 介面從 JournalNode 上的 JournalNodeHttpServer 讀取 EditLog 的資料。
- AsyncLoggerSet:內部包含了與 JournalNode 叢集進行通訊的 AsyncLogger 串列,每一個 AsyncLogger 對應於一個 JournalNode 節點,另外 AsyncLoggerSet 也包含了用於等待大多數 JournalNode 傳回結果的工具類方法給 QuorumJournalManager 使用。
- AsyncLogger:具體的實現類是 IPCLoggerChannel,IPCLoggerChannel 在執行方法呼叫的時候,會把呼叫提交到一個單執行緒的執行緒池之中,由執行緒池執行緒來負責向對應的 JournalNode 的 JournalNodeRpcServer 傳送 RPC 請求。
- JournalNodeRpcServer:執行在 JournalNode 節點行程中的 RPC 服務,接收 NameNode 端的 AsyncLogger 的 RPC 請求。
- JournalNodeHttpServer:執行在 JournalNode 節點行程中的 Http 服務,用於接收處於 Standby 狀態的 NameNode 和其它 JournalNode 的同步 EditLog 檔案流的請求。
關於NameNode HA機制更多細節
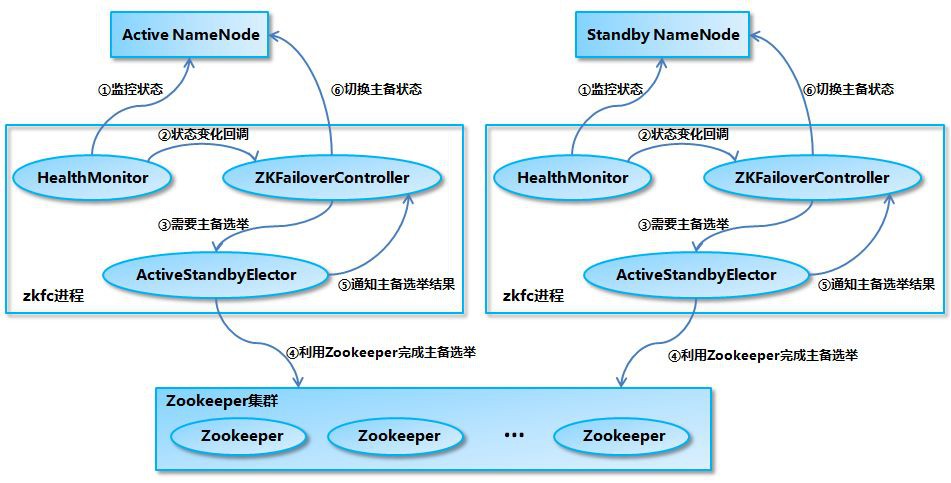
NameNode的切換流程
HA機制更多細節,NameNode的切換流程分為以下幾個步驟:
- HealthMonitor 初始化完成之後會啟動內部的執行緒來定時呼叫對應 NameNode 的 HAServiceProtocol RPC 介面的方法,對 NameNode 的健康狀態進行檢測。
- HealthMonitor 如果檢測到 NameNode 的健康狀態發生變化,會回呼 ZKFailoverController 註冊的相應方法進行處理。
- 如果 ZKFailoverController 判斷需要進行主備切換,會首先使用 ActiveStandbyElector 來進行自動的主備選舉。
- ActiveStandbyElector 與 Zookeeper 進行互動完成自動的主備選舉。
- ActiveStandbyElector 在主備選舉完成後,會回呼 ZKFailoverController 的相應方法來通知當前的 NameNode 成為主 NameNode 或備 NameNode。
- ZKFailoverController 呼叫對應 NameNode 的 HAServiceProtocol RPC 介面的方法將 NameNode 轉換為 Active 狀態或 Standby 狀態。
3、HDFS的讀寫流程
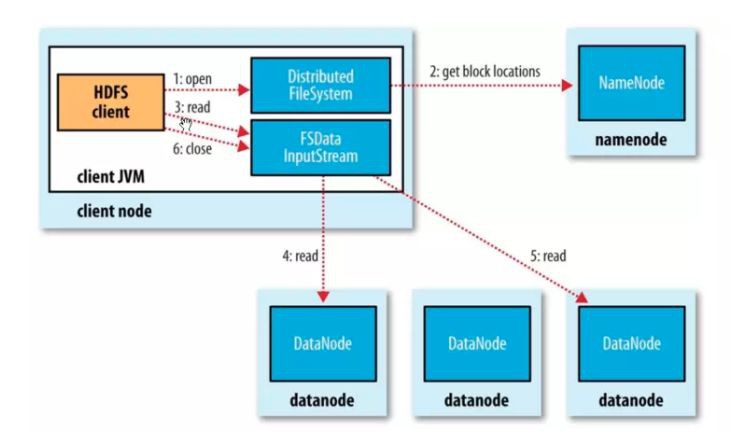
讀流程分析
客戶端開啟檔案,透過rpc的方式向NameNode獲取檔案快的儲存位置資訊,NameNode會將檔案中的各個塊的所有副本DataNode全部傳回,這些DataNode會按照與客戶端的位置的距離排序。如果客戶端就是在DataNode上,客戶端可以直接從本地讀取檔案,跳過網路IO,效能更高。客戶端調研read方法,儲存了檔案的前幾個塊的地址的DFSInputStream,就會連線儲存了第一個塊的最近的DataNode。然後透過DFSInputStream就透過重覆呼叫read方法,資料就從DataNode流動到可後端,當改DataNode的最後一個快讀取完成了,DFSInputSteam會關閉與DataNode的連線,然後尋找下一個快的最佳節點。這個過程讀客戶端來說透明的,在客戶端那邊來看們就像是隻讀取了一個連續不斷的流。
塊是按順序讀的,透過 DFSInputStream 在 datanode 上開啟新的連線去作為客戶端讀取的流。他也將會呼叫 namenode 來取得下一批所需要的塊所在的 datanode 的位置(註意剛才說的只是從 namenode 獲取前幾個塊的)。當客戶端完成了讀取,就在 FSDataInputStream 上呼叫 close() 方法結束整個流程。
在這個設計中一個重要的方面就是客戶端直接從 DataNode 上檢索資料,並透過 NameNode 指導來得到每一個塊的最佳 DataNode。這種設計允許 HDFS 擴充套件大量的併發客戶端,因為資料傳輸只是叢集上的所有 DataNode 展開的。期間,NameNode 僅僅只需要服務於獲取塊位置的請求(塊位置資訊是存放在記憶體中,所以效率很高)。如果不這樣設計,隨著客戶端資料量的增長,資料服務就會很快成為一個瓶頸。

寫流程分析
- 透過Client向遠端的NameNode傳送RPC請求;
- 接收到請求後NameNode會首先判斷對應的檔案是否存在以及使用者是否有對應的許可權,成功則會為檔案建立一個記錄,否則會讓客戶端丟擲異常;
- 當客戶端開始寫入檔案的時候,開發庫會將檔案切分成多個packets,併在內部以”data queue”的形式管理這些packets,並向Namenode申請新的blocks,獲取用來儲存replicas的合適的datanodes串列,串列的大小根據在Namenode中對replication的設定而定。
- 開始以pipeline(管道)的形式將packet寫入所有的replicas中。開發庫把packet以流的方式寫入第一個 datanode,該datanode把該packet儲存之後,再將其傳遞給在此pipeline中的下一個datanode,直到最後一個 datanode, 這種寫資料的方式呈流水線的形式。
- 最後一個datanode成功儲存之後會傳回一個ack packet,在pipeline裡傳遞至客戶端,在客戶端的開發庫內部維護著 “ack queue”,成功收到datanode傳回的ack packet後會從”ack queue”移除相應的packet。
- 如果傳輸過程中,有某個datanode出現了故障,那麼當前的pipeline會被關閉,出現故障的datanode會從當前的 pipeline中移除,剩餘的block會繼續剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的 datanode,保持replicas設定的數量。
DFSOutputStream內部原理
開啟一個DFSOutputStream流,Client會寫資料到流內部的一個緩衝區中,然後資料被分解成多個Packet,每個Packet大小為64k位元組,每個Packet又由一組chunk和這組chunk對應的checksum資料組成,預設chunk大小為512位元組,每個checksum是對512位元組資料計算的校驗和資料。
當Client寫入的位元組流資料達到一個Packet的長度,這個Packet會被構建出來,然後會被放到佇列dataQueue中,接著DataStreamer執行緒會不斷地從dataQueue佇列中取出Packet,傳送到複製Pipeline中的第一個DataNode上,並將該Packet從dataQueue佇列中移到ackQueue佇列中。ResponseProcessor執行緒接收從Datanode傳送過來的ack,如果是一個成功的ack,表示覆制Pipeline中的所有Datanode都已經接收到這個Packet,ResponseProcessor執行緒將packet從佇列ackQueue中刪除。
在傳送過程中,如果發生錯誤,所有未完成的Packet都會從ackQueue佇列中移除掉,然後重新建立一個新的Pipeline,排除掉出錯的那些DataNode節點,接著DataStreamer執行緒繼續從dataQueue佇列中傳送Packet。
下麵是DFSOutputStream的結構及其原理,從下麵3個方面來描述內部流程:

- 建立Packet
Client寫資料時,會將位元組流資料快取到內部的緩衝區中,當長度滿足一個Chunk大小(512B)時,便會建立一個Packet物件,然後向該Packet物件中寫Chunk Checksum校驗和資料,以及實際資料塊Chunk Data,校驗和資料是基於實際資料塊計算得到的。每次滿足一個Chunk大小時,都會向Packet中寫上述資料內容,直到達到一個Packet物件大小(64K),就會將該Packet物件放入到dataQueue佇列中,等待DataStreamer執行緒取出併傳送到DataNode節點。
- 傳送Packet
DataStreamer執行緒從dataQueue佇列中取出Packet物件,放到ackQueue佇列中,然後向DataNode節點傳送這個Packet物件所對應的資料。
- 接收ack
傳送一個Packet資料包以後,會有一個用來接收ack的ResponseProcessor執行緒,如果收到成功的ack,則表示一個Packet傳送成功。如果成功,則ResponseProcessor執行緒會將ackQueue佇列中對應的Packet刪除。
4、HDFS的使用場景和缺點
-
使用場景
- hdfs的設計一次寫入,多次讀取,支援修改。
- 大檔案,在hdfs中一個塊通常是64M、128M、256M,小檔案會佔用更多的元資料儲存,增加檔案資料塊的定址時間。
- 延時高,批處理。
- 高容錯,多副本。
-
缺點
- 延遲比較高,不適合低延遲高吞吐率的場景
- 不適合小檔案,小檔案會佔用NameNode的大量元資料儲存記憶體,並且增加定址時間
- 支援併發寫入,一個檔案只能有一個寫入者
- 不支援隨機修改,僅支援append
