
伺服器模型涉及到執行緒樣式和IO樣式,搞清楚這些就能針對各種場景有的放矢。該系列分成三部分:
-
單執行緒/多執行緒阻塞I/O模型
-
單執行緒非阻塞I/O模型
-
多執行緒非阻塞I/O模型,Reactor及其改進
這裡探討的伺服器模型主要指的是伺服器端對I/O的處理模型。從不同維度可以有不同的分類,這裡從I/O的阻塞與非阻塞、I/O處理的單執行緒與多執行緒角度探討伺服器模型。
對於I/O,可以分成阻塞I/O與非阻塞I/O兩大型別。阻塞I/O在做I/O讀寫操作時會使當前執行緒進入阻塞狀態,而非阻塞I/O則不進入阻塞狀態。
對於執行緒,單執行緒情況下由一條執行緒負責所有客戶端連線的I/O操作,而多執行緒情況下則由若干執行緒共同處理所有客戶端連線的I/O操作。
單執行緒阻塞I/O模型是最簡單的一種伺服器模型,幾乎所有程式員在剛開始接觸網路程式設計時都從這個簡單的模型開始。這種模型只能同時處理一個客戶端訪問,並且在I/O操作上是阻塞的,執行緒會一直在等待,而不會做其他事情。對於多個客戶端訪問,必須要等到前一個客戶端訪問結束才能進行下一個訪問的處理,請求一個一個排隊,只提供一問一答服務。

首先,伺服器必須初始化一個套接字伺服器,並系結某個埠號並使之監聽客戶端的訪問。接著,客戶端1呼叫伺服器的服務,伺服器接收到請求後對其進行處理,處理完後寫資料回客戶端1,整個過程都是在一個執行緒裡面完成的。最後,處理客戶端2的請求並寫資料回客戶端2,期間就算客戶端2在伺服器處理完客戶端1之前就進行請求,也要等伺服器對客戶端1響應完後才會對客戶端2進行響應處理。
這種模型的特點在於單執行緒和阻塞I/O。單執行緒即伺服器端只有一個執行緒處理客戶端的所有請求,客戶端連線與伺服器端的處理執行緒比是n:1,它無法同時處理多個連線,只能序列處理連線。而阻塞I/O是指伺服器在讀寫資料時是阻塞的,讀取客戶端資料時要等待客戶端傳送資料並且把作業系統核心覆制到使用者行程中,這時才解除阻塞狀態。寫資料回客戶端時要等待使用者行程將資料寫入核心併傳送到客戶端後才解除阻塞狀態。這種阻塞給網路程式設計帶來了一個問題,伺服器必須要等到客戶端成功接收才能繼續往下處理另外一個客戶端的請求,在此期間執行緒將無法響應任何客戶端請求。
該模型的特點:它是最簡單的伺服器模型,整個執行過程都只有一個執行緒,只能支援同時處理一個客戶端的請求(如果有多個客戶端訪問,就必須排隊等待),伺服器系統資源消耗較小,但併發能力低,容錯能力差。
針對單執行緒阻塞I/O模型的缺點,我們可以使用多執行緒對其進行改進,使之能併發地對多個客戶端同時進行響應。多執行緒模型的核心就是利用多執行緒機製為每個客戶端分配一個執行緒。伺服器端開始監聽客戶端的訪問,假如有兩個客戶端傳送請求過來,伺服器端在接收到客戶端請求後分別建立兩個執行緒對它們進行處理,每條執行緒負責一個客戶端連線,直到響應完成。期間兩個執行緒併發地為各自對應的客戶端處理請求,包括讀取客戶端資料、處理客戶端資料、寫資料回客戶端等操作。

這種模型的I/O操作也是阻塞的,因為每個執行緒執行到讀取或寫入操作時都將進入阻塞狀態,直到讀取到客戶端的資料或資料成功寫入客戶端後才解除阻塞狀態。儘管I/O操作阻塞,但這種樣式比單執行緒處理的效能明顯高了,它不用等到第一個請求處理完才處理第二個,而是併發地處理客戶端請求,客戶端連線與伺服器端處理執行緒的比例是1:1。
多執行緒阻塞I/O模型的特點:支援對多個客戶端併發響應,處理能力得到大幅提高,有較大的併發量,但伺服器系統資源消耗量較大,而且多執行緒之間會產生執行緒切換成本,同時擁有較複雜的結構。
多執行緒阻塞I/O模型透過引入多執行緒確實提高了伺服器端的併發處理能力,但每個連線都需要一個執行緒負責I/O操作。當連線數量較多時可能導致機器執行緒數量太多,而這些執行緒大多數時間卻處於等待狀態,造成極大的資源浪費。鑒於多執行緒阻塞I/O模型的缺點,有沒有可能用一個執行緒就可以維護多個客戶端連線並且不會阻塞在讀寫操作呢?下麵介紹單執行緒非阻塞I/O模型。
單執行緒非阻塞I/O模型最重要的一個特點是,在呼叫讀取或寫入介面後立即傳回,而不會進入阻塞狀態。在探討單執行緒非阻塞I/O模型前必須要先瞭解非阻塞情況下套接字事件的檢測機制,因為對於單執行緒非阻塞模型最重要的事情是檢測哪些連線有感興趣的事件發生。一般會有如下三種檢測方式。
應用程式遍歷套接字的事件檢測
當多個客戶端向伺服器請求時,伺服器端會儲存一個套接字連線串列中,應用層執行緒對套接字串列輪詢嘗試讀取或寫入。對於讀取操作,如果成功讀取到若干資料,則對讀取到的資料進行處理;如果讀取失敗,則下一個迴圈再繼續嘗試。對於寫入操作,先嘗試將資料寫入指定的某個套接字,寫入失敗則下一個迴圈再繼續嘗試。

這樣看來,不管有多少個套接字連線,它們都可以被一個執行緒管理,一個執行緒負責遍歷這些套接字串列,不斷地嘗試讀取或寫入資料。這很好地利用了阻塞的時間,處理能力得到提升。但這種模型需要在應用程式中遍歷所有的套接字串列,同時需要處理資料的拼接,連線空閑時可能也會佔用較多CPU資源,不適合實際使用。對此改進的方法是使用事件驅動的非阻塞方式。
核心遍歷套接字的事件檢測
這種方式將套接字的遍歷工作交給了作業系統核心,把對套接字遍歷的結果組織成一系列的事件串列並傳回應用層處理。對於應用層,它們需要處理的物件就是這些事件,這就是其中一種事件驅動的非阻塞方式的實現。
伺服器端有多個客戶端連線,應用層向內核請求讀寫事件串列。核心遍歷所有套接字並生成對應的可讀串列readList和可寫串列writeList。readList標明瞭每個套接字是否可讀,例如套接字1的值為1,表示可讀,socket2的值為0,表示不可讀。writeList則標明瞭每個套接字是否可寫。應用層遍歷讀寫事件串列readList和writeList,做相應的讀寫操作。
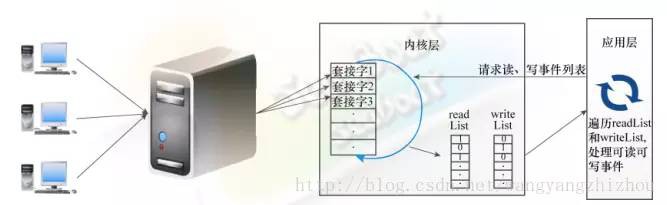
核心遍歷套接字時已經不用在應用層對所有套接字進行遍歷,將遍歷工作下移到核心層,這種方式有助於提高檢測效率。然而,它需要將所有連線的可讀事件串列和可寫事件串列傳到應用層,假如套接字連線數量變大,串列從核心覆制到應用層也是不小的開銷。另外,當活躍連線較少時,核心與應用層之間存在很多無效的資料副本,因為它將活躍和不活躍的連線狀態都複製到應用層中。
核心基於回呼的事件檢測
透過遍歷的方式檢測套接字是否可讀可寫是一種效率比較低的方式,不管是在應用層中遍歷還是在核心中遍歷。所以需要另外一種機制來最佳化遍歷的方式,那就是回呼函式。核心中的套接字都對應一個回呼函式,當客戶端往套接字傳送資料時,核心從網絡卡接收資料後就會呼叫回呼函式,在回呼函式中維護事件串列,應用層獲取此事件串列即可得到所有感興趣的事件。
核心基於回呼的事件檢測方式有兩種。第一種是用可讀串列readList和可寫串列writeList標記讀寫事件,套接字的數量與readList和writeList兩個串列的長度一樣,readList第一個元素標為1則表示套接字1可讀,同理,writeList第二個元素標為1則表示套接字2可寫。如圖所示,多個客戶端連線伺服器端,當客戶端傳送資料過來時,核心從網絡卡複製資料成功後呼叫回呼函式將readList第一個元素置為1,應用層傳送請求讀、寫事件串列,傳回核心包含了事件標識的readList和writeList事件串列,進而分表遍歷讀事件串列readList和寫事件串列writeList,對置為1的元素對應的套接字進行讀或寫操作。這樣就避免了遍歷套接字的操作,但仍然有大量無用的資料(狀態為0的元素)從核心覆制到應用層中。於是就有了第二種事件檢測方式。

核心基於回呼的事件檢測方式二如圖所示。伺服器端有多個客戶端套接字連線。首先,應用層告訴核心每個套接字感興趣的事件。接著,當客戶端傳送資料過來時,對應會有一個回呼函式,核心從網絡卡複製資料成功後即調回呼函式將套接字1作為可讀事件event1加入到事件串列。同樣地,核心發現網絡卡可寫時就將套接字2作為可寫事件event2新增到事件串列中。最後,應用層向內核請求讀、寫事件串列,核心將包含了event1和event2的事件串列傳回應用層,應用層透過遍歷事件串列得知套接字1有資料待讀取,於是進行讀操作,而套接字2則可以寫入資料。

上面兩種方式由作業系統核心維護客戶端的所有連線並透過回呼函式不斷更新事件串列,而應用層執行緒只要遍歷這些事件串列即可知道可讀取或可寫入的連線,進而對這些連線進行讀寫操作,極大提高了檢測效率,自然處理能力也更強。
對於Java來說,非阻塞I/O的實現完全是基於作業系統內核的非阻塞I/O,它將作業系統的非阻塞I/O的差異遮蔽並提供統一的API,讓我們不必關心作業系統。JDK會幫我們選擇非阻塞I/O的實現方式,例如對於Linux系統,在支援epoll的情況下JDK會優先選擇用epoll實現Java的非阻塞I/O。這種非阻塞方式的事件檢測機制就是效率最高的“核心基於回呼的事件檢測”中的第二種方式。
在瞭解了非阻塞樣式下的事件檢測方式後,重新回到對單執行緒非阻塞I/O模型的討論。雖然只有一個執行緒,但是它透過把非阻塞讀寫操作與上面幾種檢測機制配合就可以實現對多個連線的及時處理,而不會因為某個連線的阻塞操作導致其他連線無法處理。在客戶端連線大多數都保持活躍的情況下,這個執行緒會一直迴圈處理這些連線,它很好地利用了阻塞的時間,大大提高了這個執行緒的執行效率。
單執行緒非阻塞I/O模型的主要優勢體現在對多個連線的管理,一般在同時需要處理多個連線的發場景中會使用非阻塞NIO樣式,此模型下只通過一個執行緒去維護和處理連線,這樣大大提高了機器的效率。一般伺服器端才會使用NIO樣式,而對於客戶端,出於方便及習慣,可使用阻塞樣式的套接字進行通訊。
單執行緒非阻塞I/O模型已經大大提高了機器的效率,而在多核的機器上可以透過多執行緒繼續提高機器效率。最樸實、最自然的做法就是將客戶端連線按組分配給若干執行緒,每個執行緒負責處理對應組內的連線。如圖所示,有4個客戶端訪問伺服器,伺服器將套接字1和套接字2交由執行緒1管理,而執行緒2則管理套接字3和套接字4,透過事件檢測及非阻塞讀寫就可以讓每個執行緒都能高效處理。

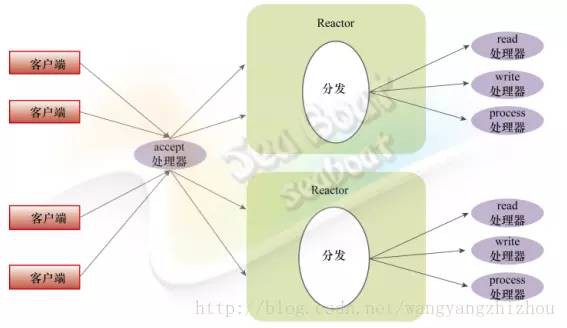
最經典的多執行緒非阻塞I/O模型方式是Reactor樣式。首先看單執行緒下的Reactor,Reactor將伺服器端的整個處理過程分成若干個事件,例如分為接收事件、讀事件、寫事件、執行事件等。Reactor透過事件檢測機制將這些事件分發給不同處理器去處理。如圖所示,若干客戶端連線訪問伺服器端,Reactor負責檢測各種事件並分發到處理器,這些處理器包括接收連線的accept處理器、讀資料的read處理器、寫資料的write處理器以及執行邏輯的process處理器。在整個過程中只要有待處理的事件存在,即可以讓Reactor執行緒不斷往下執行,而不會阻塞在某處,所以處理效率很高。
基於單執行緒Reactor模型,根據實際使用場景,把它改進成多執行緒樣式。常見的有兩種方式:一種是在耗時的process處理器中引入多執行緒,如使用執行緒池;另一種是直接使用多個Reactor實體,每個Reactor實體對應一個執行緒。

Reactor樣式的一種改進方式如圖所示。其整體結構基本上與單執行緒的Reactor類似,只是引入了一個執行緒池。由於對連線的接收、對資料的讀取和對資料的寫入等操作基本上都耗時較少,因此把它們都放到Reactor執行緒中處理。然而,對於邏輯處理可能比較耗時的工作,可以在process處理器中引入執行緒池,process處理器自己不執行任務,而是交給執行緒池,從而在Reactor執行緒中避免了耗時的操作。將耗時的操作轉移到執行緒池中後,儘管Reactor只有一個執行緒,它也能保證Reactor的高效。

Reactor樣式的另一種改進方式如圖所示。其中有多個Reactor實體,每個Reactor實體對應一個執行緒。因為接收事件是相對於伺服器端而言的,所以客戶端的連線接收工作統一由一個accept處理器負責,accept處理器會將接收的客戶端連線均勻分配給所有Reactor實體,每個Reactor實體負責處理分配到該Reactor上的客戶端連線,包括連線的讀資料、寫資料和邏輯處理。這就是多Reactor實體的原理。
多執行緒非阻塞I/O樣式讓伺服器端處理能力得到很大提高,它充分利用機器的CPU,適合用於處理高併發的場景,但它也讓程式更複雜,更容易出現問題。
作者:超人汪小建
連結:https://juejin.im/post/5a4d813d5188257d1718ea15
————近期開班————
《馬哥Linux雲端計算及架構師》課程,由知名Linux佈道師馬哥創立,經歷了8年的發展,聯合阿裡巴巴、唯品會、大眾點評、騰訊、陸金所等大型網際網路一線公司的馬哥課程團隊的工程師進行深度定製開發,課程採用 Centos7.2系統教學,加入了大量實戰案例,授課案例均來自於一線的技術案例,自動化運維、Devops、雲服務、python等技能一站式搞定,掌握2018年linux雲端計算高薪未來。
28期面授班:2018年01月08號(鄭州)
29期網路班:2018年02月10號(網路)

 掃描二維碼領取學習資料
掃描二維碼領取學習資料

更多Linux好文請點選【閱讀原文】哦
↓↓↓
