作者丨劉知遠
單位丨清華大學自然語言處理實驗室副教授
研究方向丨知識圖譜與語意計算,社會計算與計算社會科學
本文經授權轉載自知乎專欄「NLP日知錄」。
2017 年 12 月底,清華大學張鈸院士做了一場題為《AI 科學突破的前夜,教授們應當看到什麼?》的精彩特邀報告。他認為,處理知識是人類所擅長的,而處理資料是計算機所擅長的,如果能夠將二者結合起來,一定能夠構建出比人類更加智慧的系統。因此他提出,AI 未來的科學突破是建立一種同時基於知識和資料的 AI 系統。
我完全贊同張鈸老師的學術觀點。最近一年裡,我們在這方面也做了一些嘗試,將語言知識庫 HowNet 中的義原標註資訊融入面向 NLP 的深度學習模型中,取得了一些有意思的結果,在這裡整理與大家分享一下。
什麼是 HowNet
HowNet 是董振東先生、董強先生父子畢數十年之功標註的大型語言知識庫,主要面向中文(也包括英文)的詞彙與概念[1]。
HowNet 秉承還原論思想,認為詞彙/詞義可以用更小的語意單位來描述。這種語意單位被稱為“義原”(Sememe),顧名思義就是原子語意,即最基本的、不宜再分割的最小語意單位。在不斷標註的過程中,HowNet 逐漸構建出了一套精細的義原體系(約 2000 個義原)。HowNet 基於該義原體繫累計標註了數十萬詞彙/詞義的語意資訊。
例如“頂點”一詞在 HowNet 有兩個代表義項,分別標註義原資訊如下,其中每個“xx|yy”代表一個義原,“|”左邊為英文右邊為中文;義原之間還被標註了複雜的語意關係,如 host、modifier、belong 等,從而能夠精確地表示詞義的語意資訊。
頂點#1
DEF={Boundary|界限:host={entity|物體},modifier={GreaterThanNormal|高於正常:degree={most|最}}}
頂點#2
DEF={location|位置:belong={angular|角},modifier={dot|點}}
在 NLP 領域知識庫資源一直扮演著重要角色,在英語世界中最具知名度的是 WordNet,採用同義詞集(synset)的形式標註詞彙/詞義的語意知識。HowNet 採取了不同於 WordNet 的標註思路,可以說是我國學者為 NLP 做出的最獨具特色的傑出貢獻。
HowNet 在 2000 年前後引起了國內 NLP 學術界極大的研究熱情,在詞彙相似度計算、文字分類、資訊檢索等方面探索了 HowNet 的重要應用價值[2,3],與當時國際上對 WordNet 的應用探索相映成趣。
深度學習時代 HowNet 有什麼用
進入深度學習時代,人們發現透過大規模文字資料也能夠很好地學習詞彙的語意表示。例如以 word2vec[4]為代表的詞表示學習方法,用低維(一般數百維)、稠密、實值向量來表示每個詞彙/詞義的語意資訊,又稱為分散式表示(distributed representation,或 embedding),利用大規模文字中的詞彙背景關係資訊自動學習向量表示。
我們可以用這些向量方便地計算詞彙/詞義相似度,能夠取得比傳統基於語言知識庫的方法還好的效果。也正因為如此,近年來無論是 HowNet 還是 WordNet 的學術關註度都有顯著下降,如以下兩圖所示。
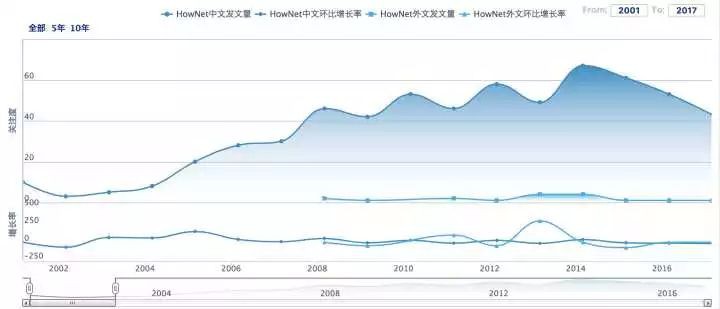
△ 中國期刊網(CNKI)統計HowNet學術關註度變化趨勢

△ Semantic Scholar統計WordNet相關論文變化趨勢
是不是說,深度學習時代以 WordNet、HowNet 為代表的語言知識庫就毫無用處了呢?實際並非如此。實際上自 word2vec 剛提出一年後,我們[5]以及 ACL 2015 最佳學生論文[6]等工作,都發現將 WordNet 知識融入到詞表示學習過程中,能夠有效提升詞表示效果。
雖然目前大部分 NLP 深度學習模型尚沒有為語言知識庫留出位置,但正由於深度學習模型 data-hungry、black-box 等特性,正使其發展遭遇不可突破的瓶頸。
回顧最開始提及的張鈸院士的觀點,我們堅信 AI 未來的科學突破是建立一種同時基於知識和資料的 AI 系統。看清楚了這個大形勢,針對 NLP 深度學習模型的關鍵問題就在於,利用什麼知識,怎樣利用知識。
在自然語言理解方面,HowNet 更貼近語言本質特點。自然語言中的詞彙是典型的符號資訊,這些符號背後蘊藏豐富的語意資訊。可以說,詞彙是最小的語言使用單位,卻不是最小的語意單位。HowNet 提出的義原標註體系,正是突破詞彙屏障,深入瞭解詞彙背後豐富語意資訊的重要通道。
在融入學習模型方面,HowNet 具有無可比擬的優勢。在 WordNet、同義詞詞林等知識庫中,每個詞的詞義是透過同義詞集(synset)和定義(gloss)來間接體現的,具體每個詞義到底什麼意義,缺少細粒度的精準刻畫,缺少顯式定量的資訊,無法更好為計算機所用。
而 HowNet 透過一套統一的義原標註體系,能夠直接精準刻畫詞義的語意資訊;而每個義原含義明確固定,可被直接作為語意標簽融入機器學習模型。
也許是由於 HowNet 採用了收費授權的政策,並且主要面向中文世界,近年來 HowNet 知識庫有些淡出人們的視野。然而,對 HowNet 逐漸深入理解,以及最近我們在 HowNet 與深度學習模型融合的成功嘗試,讓我開始堅信,HowNet 語言知識體系與思想必將在深度學習時代大放異彩。
我們的嘗試
最近我們分別探索了詞彙表示學習、新詞義原推薦、和詞典擴充套件等任務上,驗證了 HowNet 與深度學習模型融合的有效性。
1. 融合義原知識的詞彙表示學習

■ 論文 | Improved Word Representation Learning with Sememes
■ 連結 | https://www.paperweekly.site/papers/1498
■ 原始碼 | https://github.com/thunlp/SE-WRL
我們考慮將詞義的義原知識融入詞彙表示學習模型中。在該工作中,我們將 HowNet 的義原標註資訊具象化為如下圖所示的 word-sense-sememe 結構。需要註意的是,為了簡化模型,我們沒有考慮詞義的義原結構資訊,即我們將每個詞義的義原標註看做一個無序集合。

△ HowNet義原標註知識的word-sense-sememe結構示意圖
基於 word2vec 中的 Skip-Gram 模型,我們提出了 SAT(sememe attention over target model)模型。與 Skip-Gram 模型只考慮背景關係資訊相比,SAT 模型同時考慮單詞的義原資訊,使用義原資訊輔助模型更好地“理解”單詞。
具體做法是,根據背景關係單詞來對中心詞做詞義消歧,使用 attention 機制計算背景關係對該單詞各個詞義(sense)的權重,然後使用 sense embedding 的加權平均值表示單詞向量。在詞語相似度計算和類比推理兩個任務上的實驗結果表明,將義原資訊融入詞彙表示學習能夠有效提升詞向量效能。

△ SAT(Sememe Attention over Target Model)模型示意圖
2. 基於詞彙表示的新詞義原推薦

■ 論文 | Lexical Sememe Prediction via Word Embeddings and Matrix Factorization
■ 連結 | https://www.paperweekly.site/papers/450
■ 原始碼 | https://github.com/thunlp/Sememe_prediction
在驗證了分散式表示學習與義原知識庫之間的互補關係後,我們進一步提出,是否可以利用詞彙表示學習模型,對新詞進行義原推薦,輔助知識庫標註工作。為了實現義原推薦,我們分別探索了矩陣分解和協同過濾等方法。
矩陣分解方法首先利用大規模文字資料學習單詞向量,然後用已有詞語的義原標註構建“單詞-義原”矩陣,透過矩陣分解建立與單詞向量匹配的義原向量。
當給定新詞時,利用新詞在大規模文字資料得到的單詞向量推薦義原資訊。協同過濾方法則利用單詞向量自動尋找與給定新詞最相似的單詞,然後利用這些相似單詞的義原進行推薦。
義原推薦的實驗結果表明,綜合利用矩陣分解和協同過濾兩種手段,可以有效進行新詞的義原推薦,併在一定程度上能夠發現 HowNet 知識庫的標註不一致現象。該技術將有利於提高 HowNet 語言知識庫的標註效率與質量。
3. 基於詞彙表示和義原知識的詞典擴充套件

■ 論文 | Chinese LIWC Lexicon Expansion via Hierarchical Classification of Word Embeddings with Sememe Attention
■ 連結 | https://www.paperweekly.site/papers/1499
■ 原始碼 | https://github.com/thunlp/Auto_CLIWC
最近,我們又嘗試了利用詞語表示學習與 HowNet 知識庫進行詞典擴充套件。詞典擴充套件任務旨在根據詞典中的已有詞語,自動擴展出更多的相關詞語。
該任務可以看做對詞語的分類問題。我們選用在社會學中享有盛名的 LIWC 詞典(Linguistic Inquiry and Word Count)中文版來開展研究。LIWC 中文版中每個單詞都被標註層次化心理學類別。
我們利用大規模文字資料學習每個詞語的分散式向量表示,然後用 LIWC 詞典單詞作為訓練資料訓練分類器,並用 HowNet 提供的義原標註資訊構建 sememe attention。實驗表明,義原資訊的引入能夠顯著提升單詞的層次分類效果。

△ 基於Sememe Attention的詞典擴充套件模型
ps. 值得一提的是,這三份工作都是本科生(牛藝霖、袁星馳、曾祥楷)為主完成的,模型方案都很簡單,但都是第一次投稿就被 ACL、IJCAI 和 AAAI 錄用,也可以看出國際學術界對於這類技術路線的認可。
未來展望
以上介紹的三項工作只是初步驗證了深度學習時代 HowNet 語言知識庫在某些任務的重要作用。以 HowNet 語言知識庫為代表的人類知識與以深度學習為代表的資料驅動模型如何深度融合,尚有許多重要的開放問題亟待探索與解答。我認為以下幾個方向深具探索價值:
1. 目前的研究工作仍停留在詞法層面,對 HowNet 知識的應用亦非常有限。如何在以 RNN/LSTM 為代表的語言模型中有效融合 HowNet 義原知識庫,併在自動問答、機器翻譯等應用任務中驗證有效性,具有重要的研究價值。是否需要考慮義原標註的結構資訊,也值得探索與思考。
2. 經過幾十年的精心標註,HowNet 知識庫已有相當規模,但面對日新月異的資訊時代,對開放域詞彙的改寫度仍存在不足。需要不斷探索更精準的新詞義原自動推薦技術,讓計算機輔助人類專家進行更及時高效的知識庫標註工作。
此外,HowNet 義原知識庫規模宏大、標註時間跨度長,難免出現標註不一致現象,這將極大影響相關模型的效果,需要探索相關演演算法,輔助人類專家做好知識庫的一致性檢測和質量控制。
3. HowNet 知識庫的義原體系是專家在不斷標註過程中反思總結的結晶。但義原體系並非一成不變,也不見得完美無瑕。它應當隨時間變化而演化,並隨語言理解的深入而擴充套件。我們需要探索一種資料驅動與專家驅動相結合的手段,不斷最佳化與擴充義原體系,更好地滿足自然語言處理需求。
總之,HowNet 知識庫是進入深度學習時代後被極度忽視的一片寶藏,它也許會成為解決 NLP 深度學習模型諸多瓶頸的一把鑰匙。在深度學習時代用 HowNet 搞事情,廣闊天地,大有可為!
參考文獻
1. 知網官方介紹:http://www.keenage.com/zhiwang/c_zhiwang.html
2. 劉群, 李素建. 基於《知網》的詞彙語意相似度計算. 中文計算語言學 7, no. 2 (2002): 59-76.
3. 朱嫣嵐, 閔錦, 周雅倩, 黃萱菁, 吳立德. 基於 HowNet 的詞彙語意傾向計算. 中文資訊學報 20, no. 1 (2006): 16-22.
4. Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S. Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In NIPS, pp. 3111-3119. 2013.
5. Chen, Xinxiong, Zhiyuan Liu, and Maosong Sun. A unified model for word sense representation and disambiguation. In EMNLP, pp. 1025-1035. 2014.
6. Rothe, Sascha, and Hinrich Schütze. Autoextend: Extending word embeddings to embeddings for synsets and lexemes. In ACL, 2015.
7. Yilin Niu, Ruobing Xie, Zhiyuan Liu, Maosong Sun. Improved Word Representation Learning with Sememes. In ACL, 2017.
8. Ruobing Xie, Xingchi Yuan, Zhiyuan Liu, Maosong Sun. Lexical Sememe Prediction via Word Embeddings and Matrix Factorization. In IJCAI, 2017.
9. Xiangkai Zeng, Cheng Yang, Cunchao Tu, Zhiyuan Liu, Maosong Sun. Chinese LIWC Lexicon Expansion via Hierarchical Classification of Word Embeddings with Sememe Attention. In AAAI, 2018.
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。


