作者:羅攀 蔣仟
如需轉載請聯絡大資料(ID:hzdashuju)
本文涉及的主要知識點如下:
-
Python和PyCharm的安裝:學會Python和PyCharm的安裝方法
-
變數和字串:學會使用變數和字串的基本用法
-
函式與控制陳述句:學會Python迴圈、判斷陳述句、迴圈陳述句和函式的使用
-
Python資料結構:理解和使用串列、字典、元組和集合
-
Python檔案操作:學習使用Python建立檔案並寫入資料
-
Python面向物件:瞭解Python中類的定義和使用方法
01 Python與PyCharm安裝
“工欲善其事,必先利其器”,本節介紹Python環境的安裝和Python的整合開發環境(IDE)PyCharm的安裝。
1. Python安裝(Windows、Mac和Linux)
當前主流的Python版本為2.x和3.x。由於Python 2第三方庫更多(很多庫沒有向Python 3轉移),企業普遍使用Python 2。如果作為學習和研究的話,建議使用Python 3,因為它是未來的發展方向。所以本教程選擇Python 3的環境。
1.1 Windows中安裝Python 3
在Windows系統中安裝Python 3,請參照下麵的步驟進行。
-
開啟瀏覽器,訪問Python官網(https://www.python.org/)。
-
游標移動至Downloads連結,單擊Windows連結。
-
根據自己的Windows版本(32位或64位),下載相應的Python 3.5版本,如為Windows 32位系統,應下載Windows x86 executable installer,如果為Windows 64位系統,應下載Windows x86-64 executable installer。
-
單擊執行檔案,勾選Add Python 3.5 to PATH,然後單擊Install Now按鈕即可完成安裝。
在計算機中開啟命令提示符(cmd)視窗,輸入python,如圖1.1所示,說明Python環境安裝成功。

▲圖1.1 執行Python環境
當介面出現提示符>>>時,就表明進入了Python互動式環境,輸入程式碼後按Enter鍵即可執行Python程式碼,透過輸入exit()並按Enter鍵,就可以退出Python互動式環境。
註意:如果出現錯誤,可能是因為安裝時未勾選Add Python3.5 to PATH選項,此時解除安裝Python後重新安裝時勾選Add Python3.5 to PATH選項即可。
1.2 Mac中安裝Python3
Mac系統中自帶了Python 2.7,需到Python官網上下載並安裝Python 3.5。Mac系統中的安裝比Windows更為簡單,一直單擊“下一步”按鈕即可完成。安裝完後,開啟終端並輸入python3,即可進入Mac的Python 3的互動式環境。
1.3 Linux中安裝Python 3
大部分Linux系統內建了Python 2和Python 3,透過在終端輸入python –version,可以檢視當前Python 3的版本。如果需要安裝某個特定版本的Python,可以在終端中輸入:
sudo apt-get install python3.5
2. PyCharm安裝
安裝好Python環境後,還需要安裝一個整合開發環境(IDE),IDE集成了程式碼編寫功能、分析功能、編譯功能和除錯功能。在這裡向讀者推薦一個最智慧、好用的Python IDE,叫做PyCharm。進入PyCharm的官網,下載社群版即可:
http://www.jetbrains.com/pycharm/
由於PyCharm上手極為簡單,因此就不詳細講解PyCharm的使用方法了。以下講解如何使用PyCharm關聯Python直譯器,讓PyCharm可以執行Python程式碼。
-
開啟PyCharm,在選單欄中選擇File ∣ Defalut Settings命令。
-
在彈出的對話方塊中選擇Project Interpreter,然後在右邊選擇Python環境,這裡選擇Python 3.5,單擊OK按鈕,即可關聯Python直譯器,如圖1.2所示。
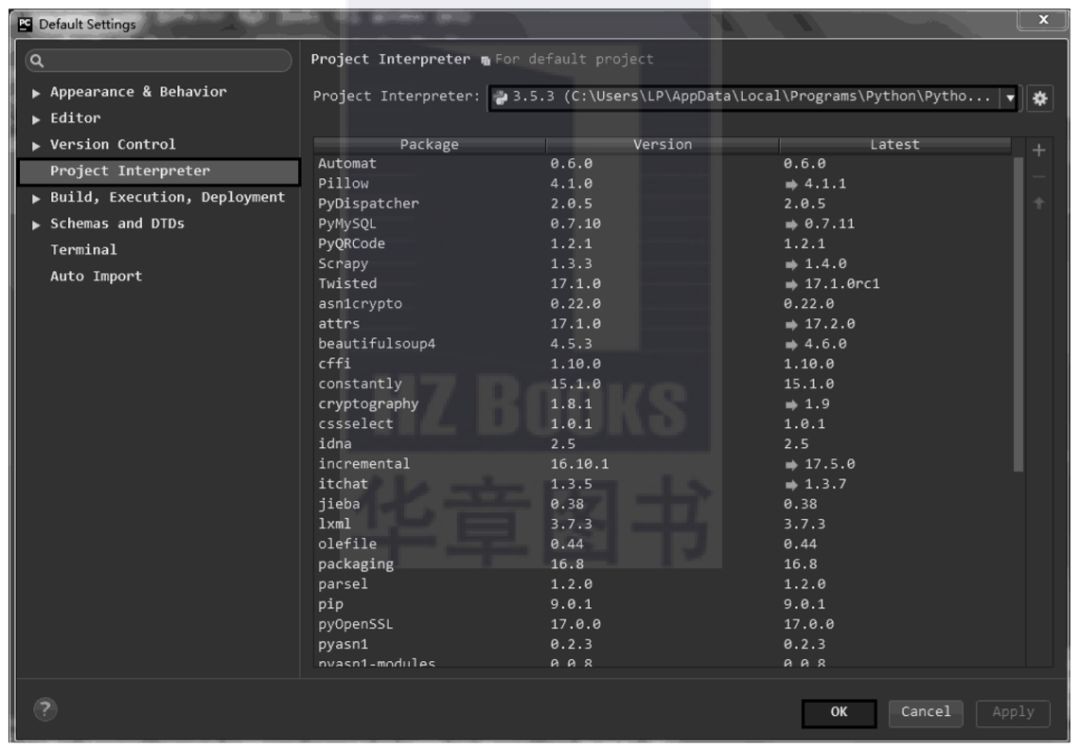
▲圖1.2 關聯Python直譯器
02 變數和字串
本節主要介紹Python變數的概念、字串的基本使用方法、字串的切片和索引,以及字串的幾種常用方法。
1. 變數
Python中的變數很好理解,例如:
a = 1
這種操作稱為賦值,意思為將數值1賦給了變數a。
註意:Python中陳述句結束不需要以分號結束,變數不需要提前定義。
現在有變數a和變數b,可以透過下麵程式碼進行變數a、b值的對換。
a = 4
b = 5
t = a #把a值賦給t變數
a = b #把b值賦給a變數
b = t #把t值賦給b變數
print(a,b)
# result 5 4
這種方法類似於將兩個杯子中的飲料對換,只需要多加一個杯子,即可完成飲料的對換工作。
2. 字串的“加法”和“乘法”
由於Python爬蟲的物件大部分為文字,所以字串的用法尤為重要。在Python中,字串由雙引號或單引號和引號中的字元組成。首先,透過下麵程式碼看看字串的“加法”:
a = 'I'
b = ' love'
c = ' Python'
print(a + b + c) #字串相加
# result I love Python
在爬蟲程式碼中,會經常構造URL,例如,在爬取一個網頁連結時,只有一部分/u/9104ebf5e177,這部分連結是無法訪問的,還需要http://www.jianshu.com,這時可以透過字串的“加法”進行合併。
註意:此網站為筆者的簡書首頁。
Python的字串不僅可以相加,也可以乘以一個數字:
a = 'word'
print(a*3) #字串乘法
#result wordwordword
字串乘以一個數字,意思就是將字串複製這個數字的份數。
3. 字串的切片和索引
字串的切片和索引就是透過string[x],獲取字串的一部分資訊:
a = 'I love python'
print(a[0]) #取字串第一個元素
#result I
print(a[0:5]) #取字串第一個到第五個元素
#result I lov
print(a[-1]) #取字串最後一個元素
#result n
透過圖1.3就能清楚地理解字串的切片和索引。

▲圖1.3 字串切片和索引
註意:a[0:5]中的第5個是不會選擇的。
在爬蟲實戰中,經常會透過字串的切片和索引,提取需要的部分,剔除一些不需要的部分。
4. 字串方法
Python作為面向物件的語言,每個物件都有相應的方法,字串也一樣,擁有多種方法,在這裡介紹爬蟲技術中常用的幾種方法。
4.1 split()方法
a = 'www.baidu.com'
print(a.split('.'))
# result ['www', 'baidu', 'com']
字串的split()方法就是透過給定的分隔符(在這裡為‘.’),將一個字串分割為一個串列(後面將詳細講解串列)。
註意:如果沒有提供任何分隔符,程式會把所有的空格作為分隔符(空格、製表、換行等)。
4.2 repalce()方法
a = 'There is apples'
b = a.replace('is','are')
print(b)
# result There are apples
這種方法類似文字中的“查詢和替換”功能。
4.3 strip()方法
a = ' python is cool '
print(a.strip())
# result python is cool
strip()方法傳回去除兩側(不包括內部)空格的字串,也可以指定需要去除的字元,將它們列為引數中即可。
a = '***python *is *good***'
print(a.strip('*!'))
# result python *is *good
這個方法只能去除兩側的字元,在爬蟲得到的文字中,文字兩側常會有多餘的空格,只需使用字串的strip()方法即可去除多餘的空格部分。
4.4 format()方法
最後,再講解下好用的字串格式化符,首先看以下程式碼:
a = '{} is my love'.format('Python')
print(a)
# result Python is my love
字串格式化符就像是做選擇題,留了空給做題者選擇。在爬蟲過程中,有些網頁連結的部分引數是可變的,這時使用字串格式化符可以減少程式碼的使用量。
例如,Pexels素材網(https://www.pexels.com/),當搜尋圖片時,網頁連結也會發生變化,如在搜尋欄中輸入book,網頁跳轉為https://www.pexels.com/search/book/,可以設計如下程式碼,筆者只需輸入搜尋內容,便可傳回網頁連結。
content = input('請輸入搜尋內容:')
url_path = 'https://www.pexels.com/search/{}/'.format(content)
print(url_path)
執行程式並輸入book,便可傳回網頁連結,單擊網頁連結便可訪問網頁了,如圖1.4所示。

▲圖1.4 字串格式化符演示
03 函式與控制陳述句
本節主要介紹Python()函式的定義與使用方法,介紹Python的判斷和迴圈兩種爬蟲技術中常用的控制陳述句。
1. 函式
“臟活累活交給函式來做”,首先,看看Python中定義函式的方法。
def 函式名(引數1,引數2...):
return '結果'
製作一個輸入直角邊就能計算出直角三角形的面積函式:
def function(a,b):
return '1/2*a*b'
#也可以這樣寫
def function(a,b):
print( 1/2*a*b)
註意:讀者不需要太糾結二者的區別,用return是傳回一個值,而第二個是呼叫函式執行列印功能。
透過輸入function(2,3),便可以呼叫函式,計算直角邊為2和3的直角三角形的面積。現在來做一個綜合練習:讀者都知道網上公佈的電話號碼,如156****9354,中間的數值用其他符號代替了,而使用者輸入手機號時卻是完整地輸入,下麵就透過Python()函式來實現這種轉換功能。
def change_number(number):
hiding_number = number.replace(number[3:7],'*'*4)
print(hiding_number)
change_number('15648929354')
# result 156****9354
註意:這裡的手機號碼是隨意輸入的,不是真實的號碼。
程式碼說明如下:
-
定義了一個名為change_number的函式。
-
對輸入的引數進行切片,把引數的[3:7]部分替換為‘*’號,並打印出來。
-
呼叫函式。
2. 判斷陳述句
在爬蟲實戰中也會經常使用判斷陳述句,Python的判斷陳述句格式如下:
if condition:
do
else:
do
# 註意:冒號和縮排不要忘記了
# 再看一下多重條件的格式
if condition:
do
elif condition:
do
else:
do
在平時使用密碼時,輸入的密碼正確即可登入,密碼錯誤時就需要再次輸入密碼。
def count_login():
password = input('password:')
if password == '12345':
print('輸入成功!')
else:
print('錯誤,再輸入')
count_login()
count_login()
程式說明如下:
-
執行程式,輸入密碼後按Enter鍵。
-
如果輸入的字串為12345,則列印“輸入成功!”,程式結束。
-
如果輸入的字串不是12345,則列印“錯誤,再輸入”,繼續執行程式,直到輸入正確為止。
讀者也可以將程式設計得更為有趣,例如,“3次輸入失敗後,退出程式”等。
3. 迴圈陳述句
Python的迴圈陳述句包括for迴圈和while迴圈,程式碼如下:
#for迴圈
for item in iterable:
do
#item表示元素,iterable是集合
for i in range(1,11):
print(i)
#其結果為依次輸出1到10,切記11是不輸出的,range為Python內建函式
#while迴圈
while condition:
do
例如,設計一個小程式,計算1~100的和:
i = 0
sum = 0
while i 100:
i = i + 1
sum = sum + i
print(sum)
# result 5050
04 Python資料結構
資料結構是存放資料的容器,本節主要講解Python的4種基本資料結構,即串列、字典、元組和集合。
1. 串列
在爬蟲實戰中,使用最多的就是串列資料結構,不論是構造出的多個URL,還是爬取到的資料,大多數都為串列資料結構。下麵首先介紹串列最顯著的特徵:
-
串列中的每一個元素都是可變的。
-
串列的元素都是有序的,也就是說每個元素都有對應的位置(類似字串的切片和索引)。
-
串列可以容納所有的物件。
串列中的每個元素都是可變的,這意味著可以對串列進行增、刪、改操作,這些操作在爬蟲中很少使用,因此這裡不再給讀者新增知識負擔。
串列的每個元素都有對應的位置,這種用法與字串的切片和索引很相似。
list = ['peter', 'lilei', 'wangwu', 'xiaoming']
print(list[0])
print(list[2:])
# result
peter
['wangwu', 'xiaoming']
如果為切片,傳回的也是串列的資料結構。
串列可以容納所有的物件:
list = [
1,
1.1,
'string',
print(1),
True,
[1, 2],
(1, 2),
{'key', 'value'}
]
串列中會經常用到多重迴圈,因此讀者有必要去瞭解和使用多重迴圈。現在,擺在讀者面前有兩個串列,分別是姓名和年齡的串列:
names = ['xiaoming','wangwu','peter']
ages = [23,15,58]
這時可以透過多重迴圈讓name和age同時列印在螢幕上:
names = ['xiaoming','wangwu','peter']
ages = [23,15,58]
for name, age in zip(names, ages):
print(name,age)
# result
xiaoming 23
wangwu 15
peter 58
註意:多重迴圈前後變數要一致。
在爬蟲中,經常請求多個網頁,通常情況下會把網頁存到串列中,然後迴圈依次取出並訪問爬取資料。這些網頁都有一定的規律,如果是手動將這些網頁URL存入到串列中,不僅花費太多時間,也會造成程式碼冗餘。這時可透過串列推導式,構造出這樣的串列,例如某個網站每頁的URL是這樣的(一共13頁):
http://bj.xiaozhu.com/search-duanzufang-p1-0/
http://bj.xiaozhu.com/search-duanzufang-p2-0/
http://bj.xiaozhu.com/search-duanzufang-p3-0/
http://bj.xiaozhu.com/search-duanzufang-p4-0/
……
透過以下程式碼即可構造出13頁URL的串列資料:
urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in range(1,14)]
for url in urls:
print(url)
透過一行程式碼即可構造出來,透過for迴圈打印出每個URL,如圖1.5所示。

▲圖1.5 串列推導式構造URL串列
註意:本網站為小豬短租網。
2. 字典
Python的字典資料結構與現實中的字典類似,以鍵值對(’key’-‘value’)的形式表現出來。本文中只講解字典的創造,字典的操作在後面會詳細介紹。字典的格式如下:
user_info = {
'name':'xiaoming',
'age':'23',
'sex':'man'
}
註意:插入MongoDB資料庫需用字典結構。
3. 元組和集合
在爬蟲中,元組和集合很少用到,因此這裡只做簡單介紹。元組類似於串列,但是元組的元素不能修改只能檢視,元組的格式如下:
tuple = (1,2,3)
集合的概念類似數學中的集合。每個集合中的元素是無序的,不可以有重覆的物件,因此可以透過集合把重覆的資料去除。
list = ['xiaoming','zhangyun','xiaoming']
set = set(list)
print(set)
# result {'zhangyun', 'xiaoming'}
註意:集合是用大括號構建的。
05 Python檔案操作
在爬蟲初期的工作中,常常會把資料儲存到檔案中。本節主要講解Python如何開啟檔案和讀寫資料。
1. 開啟檔案
Python中透過open()函式開啟檔案,語法如下:
open(name[, mode[, buffering]])
open()函式使用檔案名作為唯一的強制引數,然後傳回一個檔案物件。樣式(mode)和緩衝(buffering)是可選引數。在Python的檔案操作中,mode引數的輸入是有必要的,而buffering使用較少。
如果在本機上有名為file.txt的檔案(讀者可以在本機中新建一個文字檔案),其儲存路徑為C:\Users\Administrator\Desktop,那麼可以透過下麵程式碼開啟檔案:
f = open('C:/Users/Administrator/Desktop/file.txt')
註意:此程式碼為Windows系統下的路徑寫法。
如果檔案不存在,則會出現如圖1.6所示的錯誤。
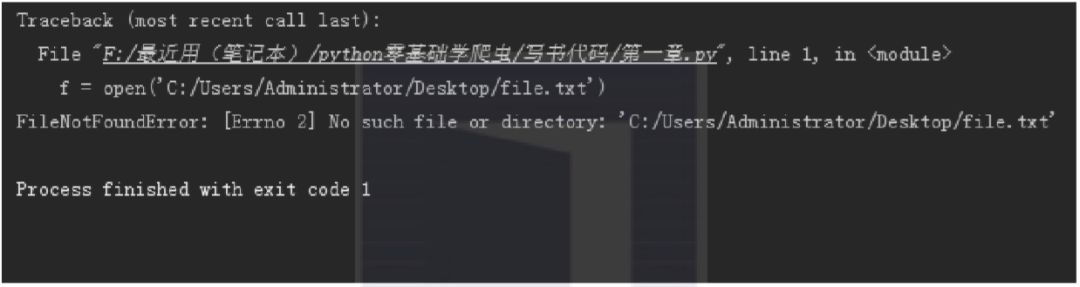
▲圖1.6 檔案不存在報錯資訊
如果open()函式只是加入檔案的路徑這一個引數,則只能開啟檔案並讀取檔案的相關內容。如果要向檔案中寫入內容,則必須加入樣式這個引數了。下麵首先來看看open()函式中樣式引數的常用值,如表1.1所示。

▲表1.1 open()函式中樣式引數的常用值
2. 讀寫檔案
上一節中有了名為f的類檔案物件,那麼就可以透過f.write()方法和f.read()方法寫入和讀取資料了。
f = open('C:/Users/Administrator/Desktop/file.txt','w+')
f.write('hello world')
這時,在本機上開啟file.txt檔案,可以看到如圖1.7所示的結果。

▲圖1.7 Python寫檔案
註意:如果沒有建立檔案,執行上面程式碼也可以成功。
如果再次執行程式,txt檔案中的內容不會繼續新增,可以修改樣式引數為’r+’,便可一直寫入檔案。
Python讀取檔案透過read()方法,下麵嘗試把f的類檔案物件寫入的資料讀取出來,使用如下程式碼即可完成操作:
f = open('C:/Users/Administrator/Desktop/file.txt','r')
content = f.read()
print(content)
# result hello world
3. 關閉檔案
當完成讀寫工作後,應該牢記使用close()方法關閉檔案。這樣可以保證Python進行緩衝的清理(出於效率考慮而把資料臨時儲存在記憶體中)和檔案的安全性。透過下麵程式碼即可關閉檔案。
f = open('C:/Users/Administrator/Desktop/file.txt','r')
content = f.read()
print(content)
f.close()
06 Python面向物件
Python作為一個面向物件的語言,很容易建立一個類和物件。本節主要講解類的定義及其相關使用方法。
1. 定義類
類是用來描述具有相同屬性和方法的物件集合。人可以透過不同的膚色劃分為不同的種族,食物也有不同的種類,商品也是形形色色。但劃分為同一類的物體,肯定具有相似的特徵和行為方式。
對於同一款腳踏車而言,它們的組成結構都是一樣的,如車架、車輪和腳踏板等。透過Python可以定義這個腳踏車的類:
class Bike:
compose = ['frame','wheel','pedal']
透過使用class定義一個腳踏車的類,類中的變數compose稱為類的變數,專業術語為類的屬性。這樣,顧客購買的腳踏車組成結構就是一樣的了。
my_bike = Bike()
you_bike = Bike()
print(my_bike.compose)
print(you_bike.compose) #類的屬性都是一樣的
結果如圖1.8所示。

▲圖1.8 類屬性取用
在左邊寫上變數名,右邊寫上類的名稱,這個過程稱之為類的實體化,而my_bike就是類的實體。透過“.”加上類的屬性,就是類屬性的取用。類的屬性會被類的實體共享,所以結果都是一樣的。
2. 實體屬性
對於同一款腳踏車來說,有些顧客買回去後會改造下,如加一個車筐可以放東西等。
class Bike:
compose = ['frame','wheel','pedal']
my_bike = Bike()
my_bike.other = 'basket'
print(my_bike.other) #實體屬性
結果如圖1.9所示。

▲圖1.9 實體屬性
說明:透過給類的實體屬性進行賦值,也就是實體屬性。compose屬性屬於所有的該款腳踏車,而other屬性只屬於my_bike這個類的實體。
3. 實體方法
讀者是否還記得字串的format()方法。方法就是函式,方法是對實體進行使用的,所以又叫實體方法。對於腳踏車而言,它的方法就是騎行。
class Bike:
compose = ['frame','wheel','pedal']
def use(self):
print('you are riding')
my_bike = Bike()
my_bike.use()
結果如圖1.10所示。
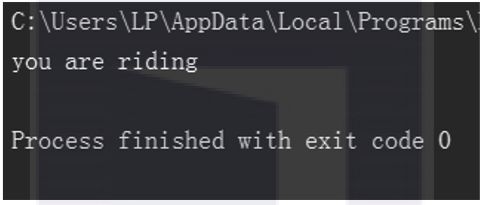
▲圖1.10 實體方法
註意:這裡的self引數就是實體本身。
和函式一樣,實體方法也是可以有引數的。
class Bike:
compose = ['frame','wheel','pedal']
def use(self,time):
print('you ride {}m'.format(time*100))
my_bike = Bike()
my_bike.use(10)
結果如圖1.11所示。

▲圖1.11 實體方法多引數
Python的類中有一些“魔法方法”,_init_()方法就是其中之一。在我們創造實體的時候,不需要取用該方法也會被自動執行。
class Bike:
compose = ['frame','wheel','pedal']
def __init__(self):
self.other = 'basket'
def use(self,time):
print('you ride {}m'.format(time*100))
my_bike = Bike()
print(my_bike.other)
結果如圖1.12所示。

▲圖1.12 魔術方法
4. 類的繼承
共享單車的出現,方便了人們的出行。共享單車和原來的腳踏車組成結構類似,但多了付費的功能。
class Bike:
compose = ['frame','wheel','pedal']
def __init__(self):
self.other = 'basket' #定義實體的屬性
def use(self,time):
print('you ride {}m'.format(time*100))
class Share_bike(Bike):
def cost(self,hour):
print('you spent {}'.format(hour*2))
bike = Share_bike()
print(bike.other)
bike.cost(2)
結果如圖1.13所示。
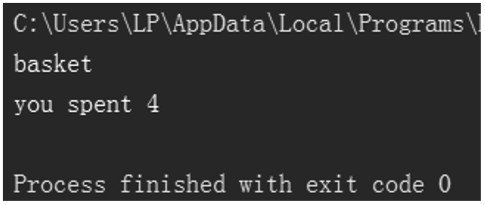
▲圖1.13 類的繼承
在新的類Share_bike後面的括號中加入Bike,表示Share_bike繼承了Bike父類。父類中的變數和方法可以完全被子類繼承,在特殊情況下,也可以對其改寫。
關於作者:羅攀,知名論壇Python爬蟲專題管理員。擅長Python爬蟲技術,並對Python資料分析與挖掘也有研究。曾經在CSDN等多個知名部落格網站發表多篇技術文章,深受讀者的喜愛。目前從事線上Python網路爬蟲的培訓工作。
蔣仟,喜愛並擅長Python程式設計,並將Python作為學術研究手段。在資料採集、資料分析等方面均有較為深入的研究。對Python網路爬蟲技術應用也頗有心得。目前從事林業遙感技術的研究,並利用業餘時間兼職從事Python培訓方面的工作。
本文摘編自《從零開始學Python網路爬蟲》,經出版方授權釋出。
延伸閱讀《從零開始學Python網路爬蟲》
點選上圖瞭解及購買
轉載請聯絡微信:DoctorData
推薦語:爬蟲暢銷書,上市1年暢銷萬餘冊!帶小白一週掌握Python網路爬蟲。涵蓋爬蟲的3大方法/爬取資料的4大儲存方式/22個實戰案例/30個網站資訊提取/64個避坑技巧/2500行程式碼詳解/原始碼/PPT。
