作者丨徐阿衡
學校丨卡耐基梅隆大學碩士
研究方向丨QA系統
本文經授權轉載自知乎專欄「徐阿衡-自然語言處理」。
開始涉獵多輪對話,這一篇想寫一寫對話管理(Dialog Management),感覺是個很龐大的工程,涉及的知識又多又雜,在這裡只好挑重點做一個引導性的介紹,後續會逐個以單篇形式展開。
放一張多輪語音對話流程圖,理解下 DM 在整個對話流程中處於什麼地位。
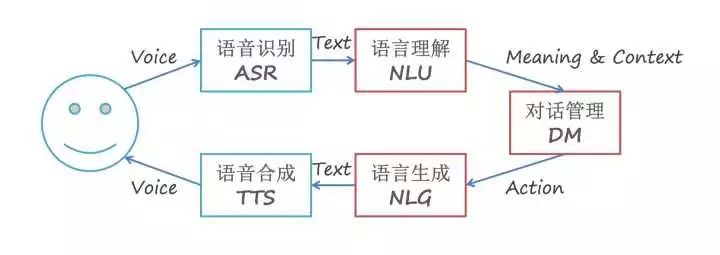
簡單描述一下這個流程圖常見的一種資訊流動方式,首先是語音識別 ASR,產生語音識別結果也就是使用者話語![]() ;語意解析模組 NLU 將
;語意解析模組 NLU 將![]() 對映成使用者對話行為
對映成使用者對話行為![]() ;對話管理模組 DM 選擇需要執行的系統行為
;對話管理模組 DM 選擇需要執行的系統行為![]() 。
。
如果這個系統行為需要和使用者互動,那麼語言生成模組 NLG 會被觸發,生成自然語言或者說是系統話語![]() ;最後,生成的語言由語音合成模組 TTS 朗讀給使用者聽。
;最後,生成的語言由語音合成模組 TTS 朗讀給使用者聽。
這一篇第一部分介紹下對話管理及重要的幾個小知識點,第二部分介紹對話管理的一些方法,主要有三大類:
Structure-based Approaches
-
Key phrase reactive
-
Tree and FSM
-
…
Principle-based Approaches
-
Frame
-
Information-State
-
Plan
-
…
Statistical Approaches
-
這一類其實和上面兩類有交叉…不過重點想提的是:
-
Reinforcement Learning
方法不等於模型,這裡只介紹一些重要概念,不會涉及模型細節。
Dialog Management
對話管理(Dialog Management, DM)控制著人機對話的過程,DM 根據對話歷史資訊,決定此刻對使用者的反應。最常見的應用還是任務驅動的多輪對話,使用者帶著明確的目的如訂餐、訂票等,使用者需求比較複雜,有很多限制條件,可能需要分多輪進行陳述。
一方面,使用者在對話過程中可以不斷修改或完善自己的需求,另一方面,當使用者的陳述的需求不夠具體或明確的時候,機器也可以透過詢問、澄清或確認來幫助使用者找到滿意的結果。
總的來說,對話管理的任務大致有下麵一些:
1. 對話狀態維護(dialog state tracking, DST)
t+1 時刻的對話狀態![]() ,依賴於之前時刻 t 的狀態
,依賴於之前時刻 t 的狀態![]() ,和之前時刻 t 的系統行為
,和之前時刻 t 的系統行為![]() ,以及當前時刻 t+1 對應的使用者行為
,以及當前時刻 t+1 對應的使用者行為![]() 。可以寫成
。可以寫成 。
。
2. 生成系統決策(dialog policy)
根據 DST 中的對話狀態(DS),產生系統行為(dialog act),決定下一步做什麼 dialog act 可以表示觀測到的使用者輸入(使用者輸入 -> DA,就是 NLU 的過程),以及系統的反饋行為(DA -> 系統反饋,就是 NLG 的過程)。
3. 作為介面與後端/任務模型進行互動
4. 提供語意表達的期望值(expectations for interpretation)
interpretation:使用者輸入的 internal representation,包括 speech recognition 和 parsing/semantic representation 的結果。
本質上,任務驅動的對話管理實際就是一個決策過程,系統在對話過程中不斷根據當前狀態決定下一步應該採取的最優動作(如:提供結果,詢問特定限制條件,澄清或確認需求等),從而最有效的輔助使用者完成資訊或服務獲取的任務。

如圖,DM 的輸入就是使用者輸入的語意表達(或者說是使用者行為,是 NLU 的輸出)和當前對話狀態,輸出就是下一步的系統行為和更新的對話狀態。這是一個迴圈往複不斷流轉直至完成任務的過程。
其中,語意輸入就是流轉的動力,DM 的限制條件(即透過每個節點需要補充的資訊/付出的代價)就是阻力,輸入攜帶的語意資訊越多,動力就越強;完成任務需要的資訊越多,阻力就越強。
一個例子:

實際上,DM 可能有更廣泛的職責,比如融合更多的資訊(業務+背景關係),進行第三方服務的請求和結果處理等等。
Initiative
對話引擎根據對話按對話由誰主導可以分為三種型別:
系統主導:系統詢問使用者資訊,使用者回答,最終達到標的。
使用者主導:使用者主動提出問題或者訴求,系統回答問題或者滿足使用者的訴求。
混合:使用者和系統在不同時刻交替主導對話過程,最終達到標的。
有兩種型別,一是使用者/系統轉移任何時候都可以主導權,這種比較困難,二是根據 prompt type 來實現主導權的移交。
Prompts 又分為 open prompt(如 ‘How may I help you‘ 這種,使用者可以回覆任何內容 )和 directive prompt(如 ‘Say yes to accept call, or no’ 這種,系統限制了使用者的回覆選擇)。
Basic Concepts
Ground and Repair
對話是對話雙方共同的行為,雙方必須不斷地建立共同基礎(common ground, Stalnaker, 1978),也就是雙方都認可的事物的集合。共同基礎可以透過聽話人依靠(ground)或者確認(acknowledge)說話人的話段來實現。
確認行為(acknowledgement)由弱到強的 5 種方法(Clark and Schaefer 1989)有:持續關註(continued attention),相關鄰接貢獻(relevant next contribution),確認(acknowledgement),表明(demonstration),展示(display)。
聽話人可能會提供正向反饋(如確認等行為),也可能提供負向反饋(如拒絕理解/要求重覆/要求 rephrase 等),甚至是要求反饋(request feedback)。
如果聽話人也可以對說話人的語段存在疑惑,會發出一個修複請求(request for repair),如:

還有的概念如 speech acts,discourse 這類,之前陸陸續續都介紹過一些了。
Challenges
人的複雜性(complex)、隨機性(random)和非理性化(illogical)的特點導致對話管理在應用場景下面臨著各種各樣的問題,包括但不僅限於:
-
模型描述能力與模型複雜度的權衡
-
使用者對話偏離業務設計的路徑
如系統問使用者導航目的地的時候,使用者反問了一句某地天氣情況。
-
多輪對話的容錯性
如 3 輪對話的場景,使用者已經完成 2 輪,第 3 輪由於 ASR 或者 NLU 錯誤,導致前功盡棄,這樣使用者體驗就非常差。
-
多場景的切換和恢復
絕大多數業務並不是單一場景,場景的切換與恢復即能作為亮點,也能作為容錯手段之一。
-
降低互動變更難度,適應業務迅速變化
-
跨場景資訊繼承
Structure-based Approaches
Key Pharse Reactive Approaches
本質上就是關鍵詞匹配,通常是透過捕捉使用者最後一句話的關鍵詞/關鍵短語來進行回應,比較知名的兩個應用是 ELIZA 和 AIML。
AIML (人工智慧標記語言),XML 格式,支援 ELIZA 的規則,並且更加靈活,能支援一定的背景關係實現簡單的多輪對話(利用 that),支援變數,支援按 topic 組織規則等。
<pattern>DO YOU KNOW WHO * ISpattern><srai>WHO IS <star/>srai>template>
</category>
<template> Tell me more about your family. template>
</category>
<that>DO YOU LIKE MOVIESthat>
What is your favorite movie?template>
</category>
附上自己改寫的 aiml 地址[1],在原有基礎上增添了一些功能:
-
支援 python3
-
支援中文
-
支援 * 擴充套件
Trees and FSM-based Approaches
Trees and FSM-based approach 通常把對話建模為透過樹或者有限狀態機(圖結構)的路徑。相比於 simple reactive approach,這種方法融合了更多的背景關係,能用一組有限的資訊交換模板來完成對話的建模。
這種方法適用於:
-
系統主導
-
需要從使用者收集特定資訊
-
使用者對每個問題的回答在有限集合中
這裡主要講 FSM,把對話看做是在有限狀態內跳轉的過程,每個狀態都有對應的動作和回覆,如果能從開始節點順利的流轉到終止節點,任務就完成了。


FSM 的狀態對應系統問使用者的問題,弧線對應將採取的行為,依賴於使用者回答。
FSM-based DM 的特點是:
-
人為定義對話流程
-
完全由系統主導,系統問,使用者答
-
答非所問的情況直接忽略
-
建模簡單,能清晰明瞭的把互動匹配到模型
-
難以擴充套件,很容易變得複雜
-
適用於簡單任務,對簡單資訊獲取很友好,難以處理複雜的問題
-
缺少靈活性,表達能力有限,輸入受限,對話結構/流轉路徑受限
對特定領域要設計 task-specific FSM,簡單的任務 FSM 可以比較輕鬆的搞定,但稍複雜的問題就困難了,畢竟要考慮對話中的各種可能組合,編寫和維護都要細節導向,非常耗時。
一旦要擴充套件 FSM,哪怕只是去 handle 一個新的 observation,都要考慮很多問題。實際中,通常會加入其它機制(如變數等)來擴充套件 FSM 的表達能力。
Principle-based Approaches
Frame-based Approaches
Frame-based approach 透過允許多條路徑更靈活的獲得資訊的方法擴充套件了基於 FSM 的方法,它將對話建模成一個填槽的過程,槽就是多輪對話過程中將初步使用者意圖轉化為明確使用者指令所需要補全的資訊。
一個槽與任務處理中所需要獲取的一種資訊相對應。槽直接沒有順序,缺什麼槽就向用戶詢問對應的資訊。

Frame-based DM 包含下麵一些要素:
-
Frame:是槽位的集合,定義了需要由使用者提供什麼資訊。
-
對話狀態:記錄了哪些槽位已經被填充 行為選擇:下一步該做什麼,填充什麼槽位,還是進行何種操作。
-
行為選擇:可以按槽位填充/槽位加權填充,或者是利用本體選擇。
基於框架/模板的系統本質上是一個生成系統,不同型別的輸入激發不同的生成規則,每個生成能夠靈活的填入相應的模板。常常用於使用者可能採取的行為相對有限、只希望使用者在這些行為中進行少許轉換的場合。
Frame-based DM 特點:
-
使用者回答可以包含任何一個片段/全部的槽資訊
-
系統來決定下一個行為
-
支援混合主導型系統
-
相對靈活的輸入,支援多種輸入/多種順序
-
適用於相對複雜的資訊獲取
-
難以應對更複雜的情境
-
缺少層次
槽的更多資訊可以參考這篇文章[2]。
Agenda + Frame (CMU Communicator)
Agenda + Frame (CMU Communicator) 對 frame model 進行了改進,有了層次結構,能應對更複雜的資訊獲取,支援話題切換、回退、退出。主要要素如下:
Product:樹的結構,能夠反映為完成這個任務需要的所有資訊的順序。相比於普通的 Tree and FSM approach,這裡產品樹(product tree)的創新在於它是動態的,可以在 session 中對樹進行一系列操作比如加一個子樹或者挪動子樹 。
Process:
Agenda:相當於任務的計劃(plan),類似棧的結構(generalization of stack),是話題的有序串列(ordered list of topics),也是 handler 的有序串列(list of handlers),handler 有優先順序。
Handler:產品樹上的每個節點對應一個 handler,一個 handler 封裝了一個 information item。
從 product tree 從左到右、深度優先遍歷生成 agenda 的順序。當使用者輸入時,系統按照 agenda 中的順序呼叫每個 handler,每個 handler 嘗試解釋並回應使用者輸入。
handler 捕獲到資訊就把資訊標記為 consumed,這保證了一個 information item 只能被一個 handler 消費。
input pass 完成後,如果使用者輸入不會直接導致特定的 handler 生成問題,那麼系統將會進入 output pass,每個 handler 都有機會產生自己的 prompt(例如,departure date handler 可以要求使用者出發日期)。
可以從 handler 傳回程式碼中確定下一步,選擇繼續 current pass,還是退出 input pass 切換到 output pass,還是退出 current pass 並等待來自使用者輸入等。
handler 也可以透過傳回碼宣告自己為當前焦點(focus),這樣這個 handler 就被提升到 agenda 的頂端。
為了保留特定主題的背景關係,這裡使用 sub-tree promotion 的方法,handler 首先被提升到兄弟節點中最左邊的節點,父節點同樣以此方式提升。

系統還能處理產品樹中節點之間的依賴關係。典型的依賴關係在父節點和子節點之間。通常父節點的值取決於其子節點。每個節點都維護一個依賴節點的串列,並且會通知依賴節點值的變化,然後依賴節點可以宣告自己是無效的併成為當前對話的候選主題。
給一個例子,能夠回應使用者的顯式/隱式話題轉移(A1-A3, U11),也能夠動態新增子樹到現有的 agenda(A8-A10)。

具體可參考論文:AN AGENDA-BASED DIALOG MANAGEMENT ARCHITECTURE FOR SPOKEN LANGUAGE SYSTEMS [3]。
Information-State Approaches
Information State Theories 提出的背景是:
-
很難去評估各種 DM 系統
-
理論和實踐模型存在很大的 gap
理論型模型有:logic-based, BDI, plan-based, attention/intention,實踐中模型大多數是 finite-state 或者 frame-based。即使從理論模型出發,也有很多種實現方法。
因此,Information State Models 作為對話建模的形式化理論,為工程化實現提供了理論指導,也為改進當前對話系統提供了大的方向。
Information-state theory 的關鍵是識別對話中流轉資訊的 relevant aspects,以及這些成分是怎麼被更新的,更新過程又是怎麼被控制的。
idea 其實比較簡單,不過執行很複雜罷了。理論架構如下:

介紹下簡單的一些要素:
Statics
-
Informational components:包括背景關係、內部驅動因子(internal motivating factors),e.g., QUD, common ground, beliefs, intentions, dialogue history, user models, etc.
-
Formal representations:informational components 的表示,e.g., lists, records, DRSs,…
Dynamics
-
dialog moves:會觸發更新 information state 的行為的集合,e.g., speech acts;
-
update rules:更新 information state 的規則集合,e.g., selection rules;
-
update strategy:更新規則的選擇策略,選擇在給定時刻選用哪一條 update rules。
意義在於可以遵循這一套理論體系來構建/分析/評價/改進對話系統。基於 information-state 的系統有:
TrindiKit Systems
– GoDiS (Larsson et al)
– information state: Questions Under Discussion
– MIDAS
– DRS information state, first-order reasoning (Bos &Gabsdil;, 2000)
– EDIS
– PTT Information State, (Matheson et al 2000)
– SRI Autoroute –Conversational Game Theory (Lewin 2000)
Successor Toolkits
– Dipper (Edinburgh)
– Midiki (MITRE)
Other IS approaches
– Soar (USC virtual humans)
– AT&T; MATCH system
Plan-based Approaches
一般指大名鼎鼎的 BDI (Belief, Desire, Intention) 模型。起源於三篇經典論文:
-
Cohen and Perrault 1979
-
Perrault and Allen 1980
-
Allen and Perrault 1980
基本假設是,一個試圖發現資訊的行為人,能夠利用標準的 plan 找到讓聽話人告訴說話人該資訊的 plan。這就是 Cohen and Perrault 1979 提到的 AI Plan model。
Perrault and Allen 1980 和 Allen and Perrault 1980 將 BDI 應用於理解,特別是間接言語語效的理解,本質上是對 Searle 1975 的 speech acts 給出了可計算的形式體系。
官方描述(Allen and Perrault 1980):
A has a goal to acquire certain information. This causes him to create a plan that involves asking B a question. B will hopefully possess the sought information. A then executes the plan, and thereby asks B the question. B will now receive the question and attempt to infer A’s plan. In the plan there might be goals that A cannot achieve without assistance. B can accept some of these obstacles as his own goals and create a plan to achieve them. B will then execute his plan and thereby respond to A’s question.
重要的概念都提到了,goals, actions, plan construction, plan inference。
理解上有點繞,簡單來說就是 agent 會捕捉對 internal state (beliefs) 有益的資訊,然後這個 state 與 agent 當前標的(goals/desires)相結合,再然後計劃(plan/intention)就會被選擇並執行。
對於 communicative agents 而言,plan 的行為就是單個的 speech acts。speech acts 可以是複合(composite)或原子(atomic)的,從而允許 agent 按照計劃步驟傳達複雜或簡單的 conceptual utterance。
這裡簡單提一下重要的概念。
信念(Belief):基於謂詞 KNOW,如果 A 相信 P 為真,那麼用 B(A, P) 來表示。
期望(Desire):基於謂詞 WANT,如果 S 希望 P 為真(S 想要實現 P),那麼用 WANT(S, P) 來表示,P 可以是一些行為的狀態或者實現,W(S, ACT(H)) 表示 S 想讓 H 來做 ACT。
Belief 和 WANT 的邏輯都是基於公理。最簡單的是基於 action schema。每個 action 都有下麵的引數集:
前提(precondition):為成功實施該行為必須為真的條件。
效果(effect):成功實施該行為後變為真的條件。
體(body):為實施該行為必須達到的部分有序的標的集(partially ordered goal states)。
計劃推理(Plan Recognition/Inference, PI):根據 B 實施的行為,A 試圖去推理 B 的計劃的過程。
-
PI.AE Action-Effect Rule(行為-效果規則)
-
PI.PA Precondition-Action Rule(前提-行為規則)
-
PI.BA Body-Action Rule(體-行為規則)
-
PI.KB Know-Desire Rule(知道-期望規則)
-
E1.1 Extended Inference Rule(擴充套件推理規則)
計劃構建(Plan construction):
找到從當前狀態(current state)達到標的狀態(goal state)需要的行為序列(sequence of actions)。
Backward chaining,大抵是說,試圖找到一個行為,如果這個行為實施了能夠實現這個標的,且它的前提在初始狀態已經得到滿足,那麼計劃就完成了,但如果未得到滿足,那麼會把前提當做新的標的,試圖滿足前提,直到所有前提都得到滿足。
Backward chaining 詳細可參考 NLP 筆記 – Meaning Representation Languages [4]。
還有個重要的概念是 speech acts,在 NLP 筆記 – Discourse Analysis [5]中提到過,之後會細講。更多可見 Plan-based models of dialogue [6]。
值得一提的是,基於 logic 和基於 plan 的方法雖然有更強大更完備的功能,但實際場景中並不常用,大概是因為大部分的系統都是相對簡單的單個領域,任務小且具體,並不需要複雜的推理。
Statistical Approaches
RL-Based Approaches
前面提到的很多方法還是需要人工來定規則的(hand-crafted approaches),然而人很難預測所有可能的場景,這種方法也並不能重用,換個任務就需要從頭再來。而一般的基於統計的方法又需要大量的資料。再者,對話系統的評估也需要花費很大的代價。
這種情況下,強化學習的優勢就凸顯出來了。RL-Based DM 能夠對系統理解使用者輸入的不確定性進行建模,讓演演算法來自己學習最好的行為序列。
首先利用 simulated user 模擬真實使用者產生各種各樣的行為(捕捉了真實使用者行為的豐富性),然後由系統和 simulated user 進行互動,根據 reward function 獎勵好的行為,懲罰壞的行為,最佳化行為序列。
由於 simulated user 只用在少量的人機互動語料中訓練,並沒有大量資料的需求,不過 user simulation 也是個很難的任務就是了。
對話模擬的整體框架如下圖:

相關連結
1. aiml 地址
https://github.com/Shuang0420/aiml
2. 填槽與多輪對話
http://t.cn/RQfkTPP
3. CMU Communicator 論文
http://www.cs.cmu.edu/~xw/asru99-agenda.pdf
4. NLP 筆記 – Meaning Representation Languages
http://t.cn/RQfFMAo
5. NLP 筆記 – Discourse Analysis
http://t.cn/RQfFacE
6. Plan-based models of dialogue
http://t.cn/RQfFC1b
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。


