來自:玉樹芝蘭(微訊號:nkwangshuyi)
https://www.jianshu.com/p/0db025ebf0a1
視覺
進化的作用,讓人類對影象的處理非常高效。
這裡,我給你展示一張照片。

如果我這樣問你:
你能否分辨出圖片中哪個是貓,哪個是狗?
你可能立即會覺得自己遭受到了莫大的侮辱。並且大聲質問我:你覺得我智商有問題嗎?!
息怒。
換一個問法:
你能否把自己分辨貓狗圖片的方法,描述成嚴格的規則,教給計算機,以便讓它替我們人類分辨成千上萬張圖片呢?
對大多數人來說,此時感受到的,就不是羞辱,而是壓力了。
如果你是個有毅力的人,可能會嘗試各種判別標準:圖片某個位置的畫素顏色、某個區域性的邊緣形狀、某個水平位置的連續顏色長度……
你把這些描述告訴計算機,它果然就可以判斷出左邊的貓和右邊的狗了。
問題是,計算機真的會分辨貓狗圖片了嗎?
我又拿出一張照片給你。

你會發現,幾乎所有的規則定義,都需要改寫。
當機器好不容易可以用近似投機取巧的方法正確分辨了這兩張圖片裡面的動物時,我又拿出來一張新圖片……

幾個小時以後,你決定放棄。
彆氣餒。
你遭遇到的,並不是新問題。就連大法官,也有過同樣的煩惱。

1964年,美國最高法院的大法官Potter Stewart在“Jacobellis v. Ohio”一案中,曾經就某部電影中出現的某種具體影象分類問題,說過一句名言“我不準備就其概念給出簡短而明確的定義……但是,我看見的時候自然會知道”(I know it when I see it)。
原文如下:
I shall not today attempt further to define the kinds of material I understand to be embraced within that shorthand description (“hard-core pornography”), and perhaps I could never succeed in intelligibly doing so. But I know it when I see it, and the motion picture involved in this case is not that.
考慮到精神文明建設的需要,這一段就不翻譯了。
人類沒法把圖片分辨的規則詳細、具體而準確地描述給計算機,是不是意味著計算機不能辨識圖片呢?
當然不是。
2017年12月份的《科學美國人》雜誌,就把“視覺人工智慧”(AI that sees like humans)定義為2017年新興技術之一。

你早已聽說過自動駕駛汽車的神奇吧?沒有機器對影象的辨識,能做到嗎?
你的好友可能(不止一次)給你演示如何用新買的iPhone X做面部識別解鎖了吧?沒有機器對影象的辨識,能做到嗎?

醫學領域裡,計算機對於科學影像(如X光片)的分析能力,已經超過有多年從業經驗的醫生了。沒有機器對影象的辨識,能做到嗎?

你可能一下子覺得有些迷茫了——這難道是奇跡?
不是。
計算機所做的,是學習。
透過學習足夠數量的樣本,機器可以從資料中自己構建模型。其中,可能涉及大量的判斷準則。但是,人類不需要告訴機器任何一條。它是完全自己領悟和掌握的。
你可能會覺得很興奮。
那麼,下麵我來告訴你一個更令你興奮的訊息——你自己也能很輕易地構建圖片分類系統!
不信?請跟著我下麵的介紹,來試試看。
資料
咱們就不辨識貓和狗了,這個問題有點不夠新鮮。
咱們來分辨機器貓,好不好?
對,我說的就是哆啦a夢。

把它和誰進行區分呢?
一開始我想找霸王龍,後來覺得這樣簡直是作弊,因為他倆長得實在差別太大。

既然哆啦a夢是機器人,咱們就另外找個機器人來區分吧。
一提到機器人,我立刻就想起來了它。

對,機器人瓦力(WALLE)。
我給你準備好了119張哆啦a夢的照片,和80張瓦力的照片。圖片已經上傳到了這個Github專案。
請點選這個連結,下載壓縮包。然後在本地解壓。作為咱們的演示目錄。
解壓後,你會看到目錄下有個image檔案夾,其中包含兩個子目錄,分別是doraemon和walle。

開啟其中doraemon的目錄,我們看看都有哪些圖片。

可以看到,哆啦a夢的圖片真是五花八門。各種場景、背景顏色、表情、動作、角度……不一而足。
這些圖片,大小不一,長寬比例也各不相同。
我們再來看看瓦力,也是類似的狀況。
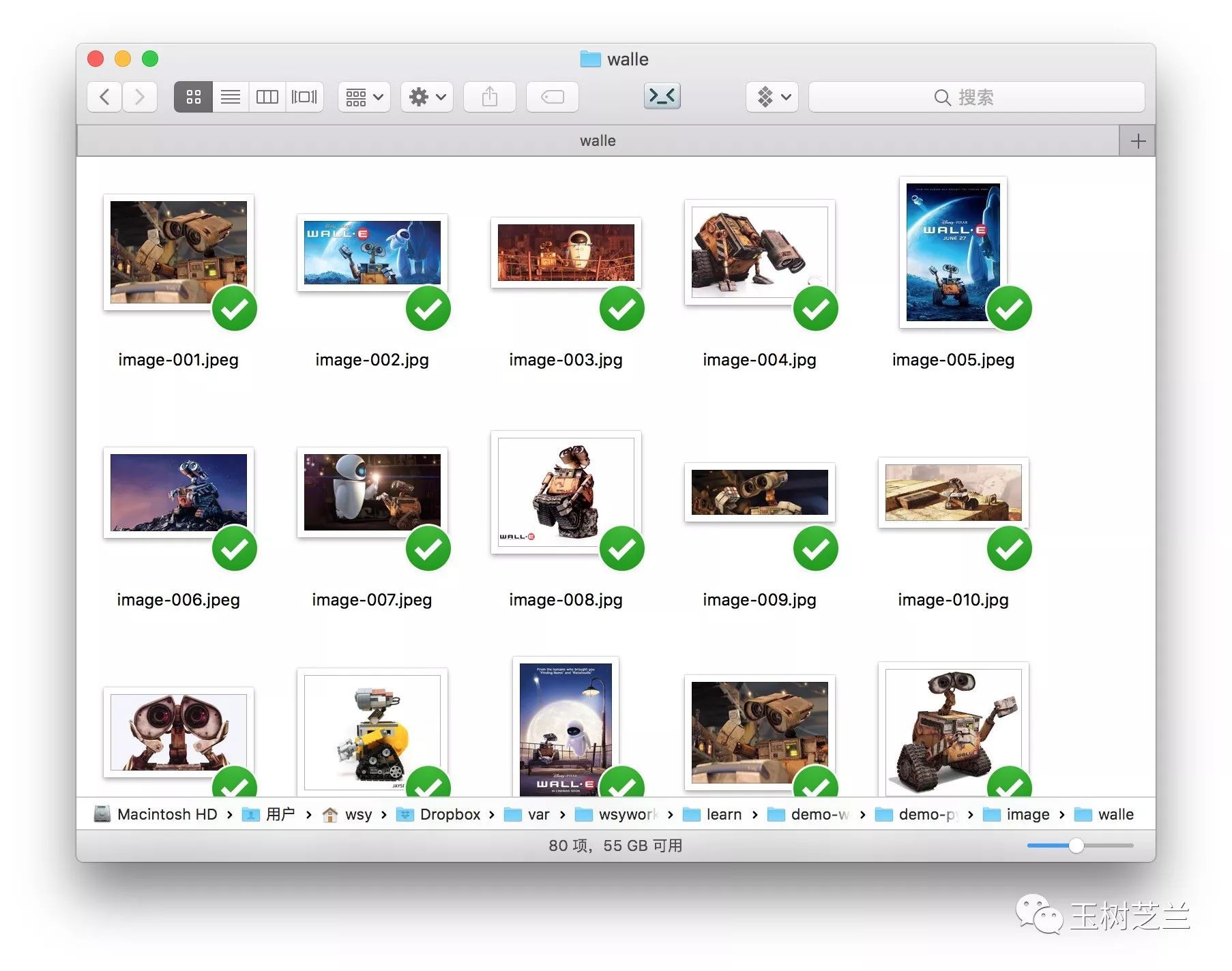
資料已經有了,下麵我們來準備一下環境配置。
環境
我們使用Python整合執行環境Anaconda。
請到這個網址 下載最新版的Anaconda。下拉頁面,找到下載位置。根據你目前使用的系統,網站會自動推薦給你適合的版本下載。我使用的是macOS,下載檔案格式為pkg。

下載頁面區左側是Python 3.6版,右側是2.7版。請選擇2.7版本。
雙擊下載後的pkg檔案,根據中文提示一步步安裝即可。

安裝好Anaconda後,我們需要安裝TuriCreate。
請到你的“終端”(Linux, macOS)或者“命令提示符”(Windows)下麵,進入咱們剛剛下載解壓後的樣例目錄。
執行以下命令,我們來建立一個Anaconda虛擬環境,名字叫做turi。
conda create -n turi python=2.7 anaconda
然後,我們啟用turi虛擬環境。
source activate turi
在這個環境中,我們安裝最新版的TuriCreate。
pip install -U turicreate
安裝完畢後,執行:
jupyter notebook

這樣就進入到了Jupyter筆記本環境。我們新建一個Python 2筆記本。
這樣就出現了一個空白筆記本。

點選左上角筆記本名稱,修改為有意義的筆記本名“demo-python-image-classification”。

準備工作完畢,下麵我們就可以開始編寫程式了。
程式碼
首先,我們讀入TuriCreate軟體包。它是蘋果併購來的機器學習框架,為開發者提供非常簡便的資料分析與人工智慧介面。
import turicreate as tc
我們指定影象所在的檔案夾image。
img_folder = 'image'
前面介紹了,image下,有哆啦a夢和瓦力這兩個檔案夾。註意如果將來你需要辨別其他的圖片(例如貓和狗),請把不同類別的圖片也在image中分別存入不同的檔案夾,這些檔案夾的名稱就是圖片的類別名(cat和dog)。
然後,我們讓TuriCreate讀取所有的影象檔案,並且儲存到data資料框。
data = tc.image_analysis.load_images(img_folder, with_path=True)
這裡可能會有錯誤資訊。
Unsupported image format. Supported formats are JPEG and PNG
file: /Users/wsy/Dropbox/var/wsywork/learn/demo-workshops/demo-python-image-classification/image/walle/.DS_Store
本例中提示,有幾個.DS_Store檔案,TuriCreate不認識,無法當作圖片來讀取。
這些.DS_Store檔案,是蘋果macOS系統建立的隱藏檔案,用來儲存目錄的自定義屬性,例如圖示位置或背景顏色。
我們忽略這些資訊即可。
下麵,我們來看看,data資料框裡面都有什麼。
data

可以看到,data包含兩列資訊,第一列是圖片的地址,第二列是圖片的長寬描述。
因為我們使用了119張哆啦a夢圖片,80張瓦力圖片,所以總共的資料量是199條。資料讀取完整性驗證透過。
下麵,我們需要讓TuriCreate瞭解不同圖片的標記(label)資訊。也就是,一張圖片到底是哆啦a夢,還是瓦力呢?
這就是為什麼一開始,你就得把不同的圖片分類儲存到不同的檔案夾下麵。
此時,我們利用檔案夾名稱,來給圖片打標記。
data['label'] = data['path'].apply(lambda path: 'doraemon' if 'doraemon' in path else 'walle')
這條陳述句,把doraemon目錄下的圖片,在data資料框裡打標記為doraemon。反之就都視為瓦力(walle)。
我們來看看標記之後的data資料框。
data
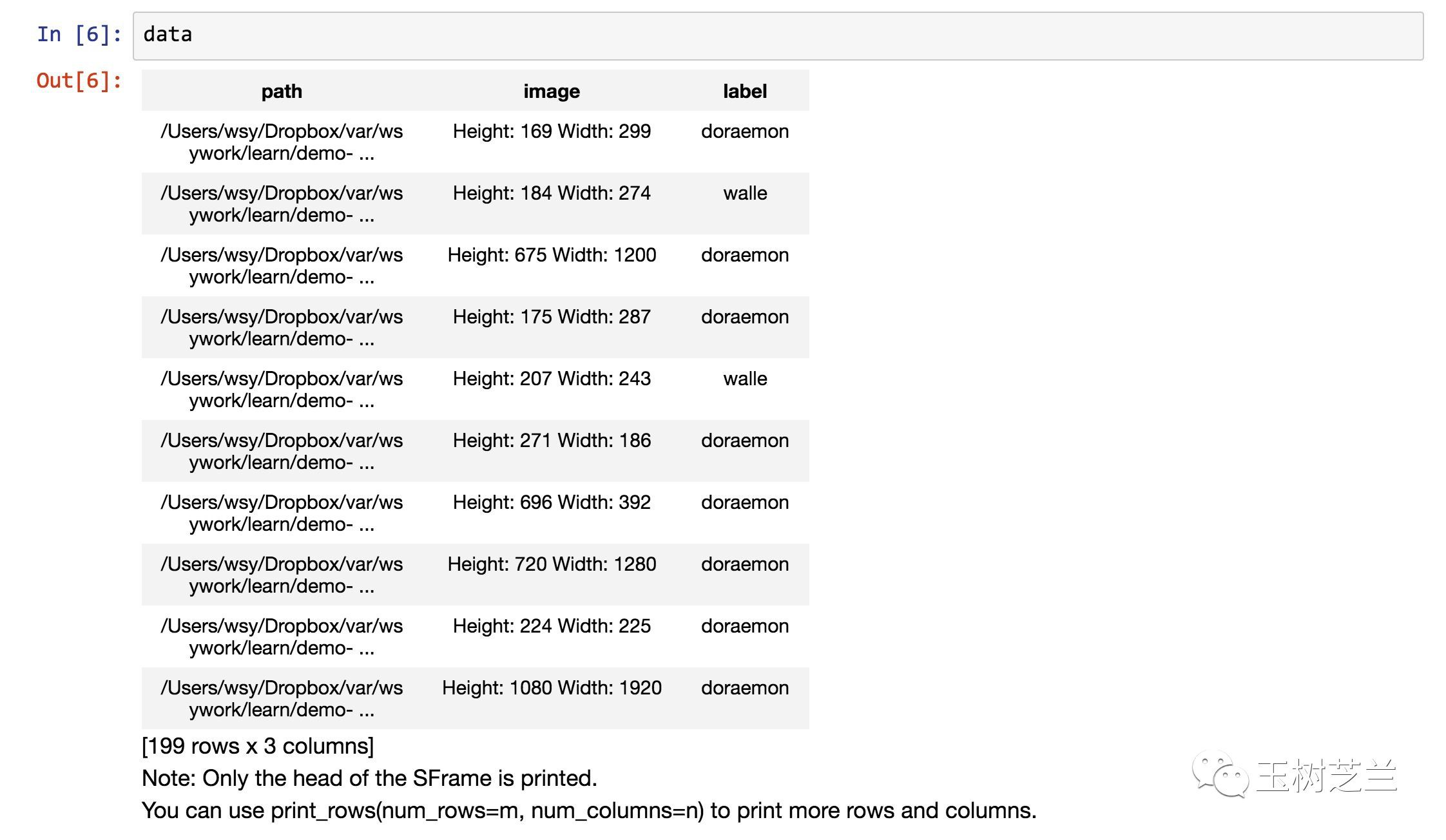
可以看到,資料的條目數量(行數)是一致的,只是多出來了一個標記列(label),說明圖片的類別。
我們把資料儲存一下。
data.save('doraemon-walle.sframe')
這個儲存動作,讓我們儲存到目前的資料處理結果。之後的分析,只需要讀入這個sframe檔案就可以了,不需要從頭去跟檔案夾打交道了。
從這個例子裡,你可能看不出什麼優勢。但是想象一下,如果你的圖片有好幾個G,甚至幾個T,每次做分析處理,都從頭讀取檔案和打標記,就會非常耗時。
我們深入探索一下資料框。
TuriCreate提供了非常方便的explore()函式,幫助我們直觀探索資料框資訊。
data.explore()
這時候,TuriCreate會彈出一個頁面,給我們展示資料框裡面的內容。

原先列印data資料框,我們只能看到圖片的尺寸,此時卻可以瀏覽圖片的內容。
如果你覺得圖片太小,沒關係。把滑鼠懸停在某張縮圖上面,就可以看到大圖。

資料框探索完畢。我們回到notebook下麵,繼續寫程式碼。
這裡我們讓TuriCreate把data資料框分為訓練集合和測試集合。
train_data, test_data = data.random_split(0.8, seed=2)
訓練集合是用來讓機器進行觀察學習的。電腦會利用訓練集合的資料自己建立模型。但是模型的效果(例如分類的準確程度)如何?我們需要用測試集來進行驗證測試。
這就如同老師不應該把考試題目都拿來給學生做作業和練習一樣。只有考學生沒見過的題,才能區分學生是掌握了正確的解題方法,還是死記硬背了作業答案。
我們讓TuriCreate把80%的資料分給了訓練集,把剩餘20%的資料拿到一邊,等待測試。這裡我設定了隨機種子取值為2,這是為了保證資料拆分的一致性。以便重覆驗證我們的結果。
好了,下麵我們讓機器開始觀察學習訓練集中的每一個資料,並且嘗試自己建立模型。
下麵程式碼第一次執行的時候,需要等候一段時間。因為TuriCreate需要從蘋果開發者官網上下載一些資料。這些資料大概100M左右。
需要的時長,依你和蘋果伺服器的連線速度而異。反正在我這兒,下載挺慢的。
好在只有第一次需要下載。之後的重覆執行,會跳過下載步驟。
model = tc.image_classifier.create(train_data, target='label')
下載完畢後,你會看到TuriCreate的訓練資訊。
Resizing images...
Performing feature extraction on resized images...
Completed 168/168
PROGRESS: Creating a validation set from 5 percent of training data. This may take a while.
You can set ``validation_set=None`` to disable validation tracking.
你會發現,TuriCreateh會幫助你把圖片進行尺寸變換,並且自動抓取圖片的特徵。然後它會從訓練集裡面抽取5%的資料作為驗證集,不斷迭代尋找最優的引數配置,達到最佳模型。
這裡可能會有一些警告資訊,忽略就可以了。
當你看到下列資訊的時候,意味著訓練工作已經順利完成了。
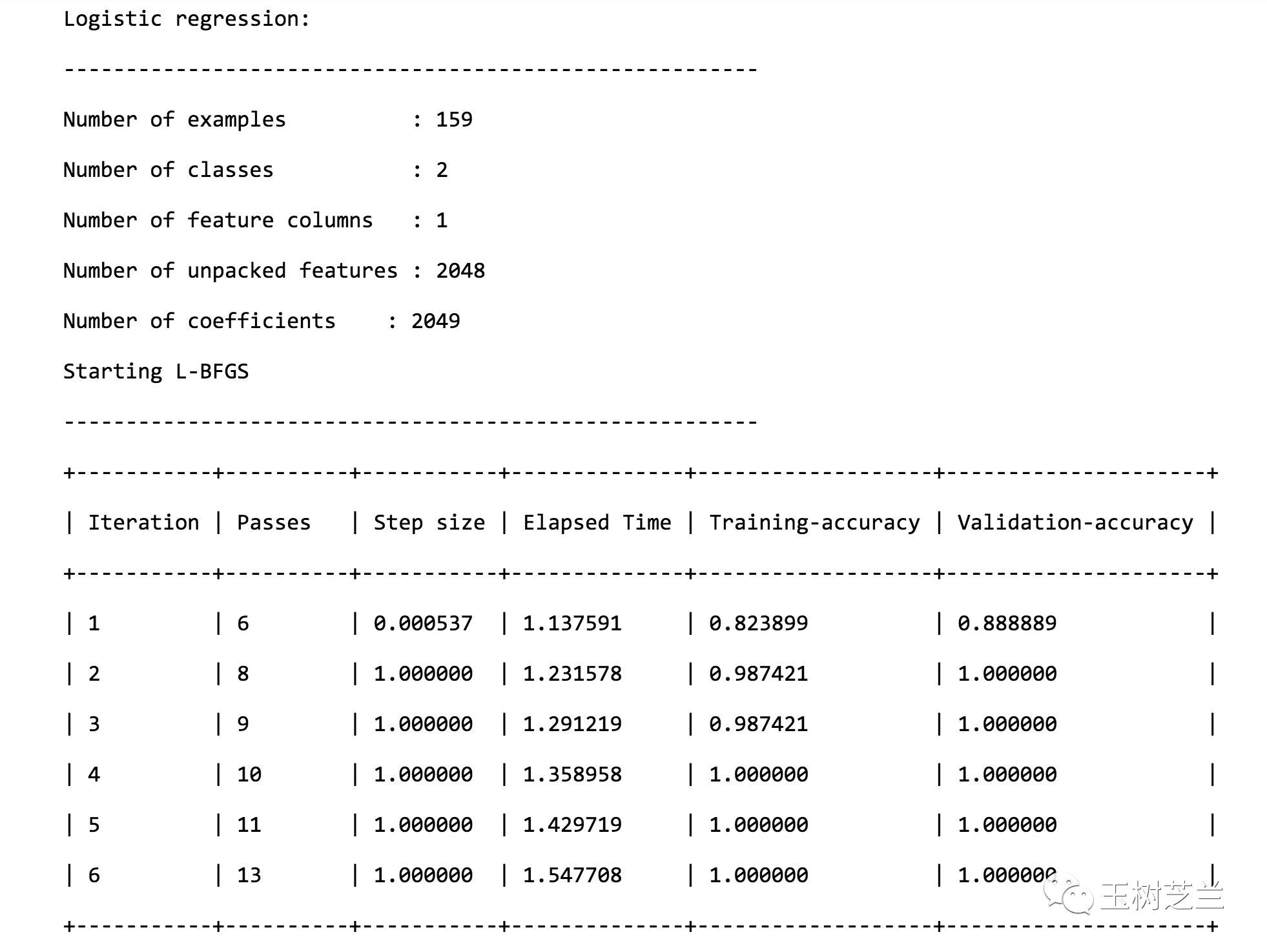
可以看到,幾個輪次下來,不論是訓練的準確度,還是驗證的準確度,都已經非常高了。
下麵,我們用獲得的圖片分類模型,來對測試集做預測。
predictions = model.predict(test_data)
我們把預測的結果(一系列圖片對應的標記序列)存入了predictions變數。
然後,我們讓TuriCreate告訴我們,在測試集上,我們的模型表現如何。
先別急著往下看,猜猜結果正確率大概是多少?從0到1之間,猜測一個數字。
猜完後,請繼續。
metrics = model.evaluate(test_data)
print(metrics['accuracy'])
這就是正確率的結果:
0.967741935484
我第一次看見的時候,震驚不已。
我們只用了100多個資料做了訓練,居然就能在測試集(機器沒有見過的圖片資料)上,獲得如此高的辨識準確度。
為了驗證這不是準確率計算部分程式碼的失誤,我們來實際看看預測結果。
predictions
這是打印出的預測標記序列:
dtype: str
Rows: 31
['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']
再看看實際的標簽。
test_data['label']
這是實際標記序列:
dtype: str
Rows: 31
['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']
我們查詢一下,到底哪些圖片預測失誤了。
你當然可以一個個對比著檢查。但是如果你的測試集有成千上萬的資料,這樣做效率就會很低。
我們分析的方法,是首先找出預測標記序列(predictions)和原始標記序列(test_data['label'])之間有哪些不一致,然後在測試資料集裡展示這些不一致的位置。
test_data[test_data['label'] != predictions]

我們發現,在31個測試資料中,只有1處標記預測發生了失誤。原始的標記是瓦力,我們的模型預測結果是哆啦a夢。
我們獲得這個資料點對應的原始檔案路徑。
wrong_pred_img_path = test_data[predictions != test_data['label']][0]['path']
然後,我們把影象讀取到img變數。
img = tc.Image(wrong_pred_img_path)
用TuriCreate提供的show()函式,我們檢視一下這張圖片的內容。
img.show()
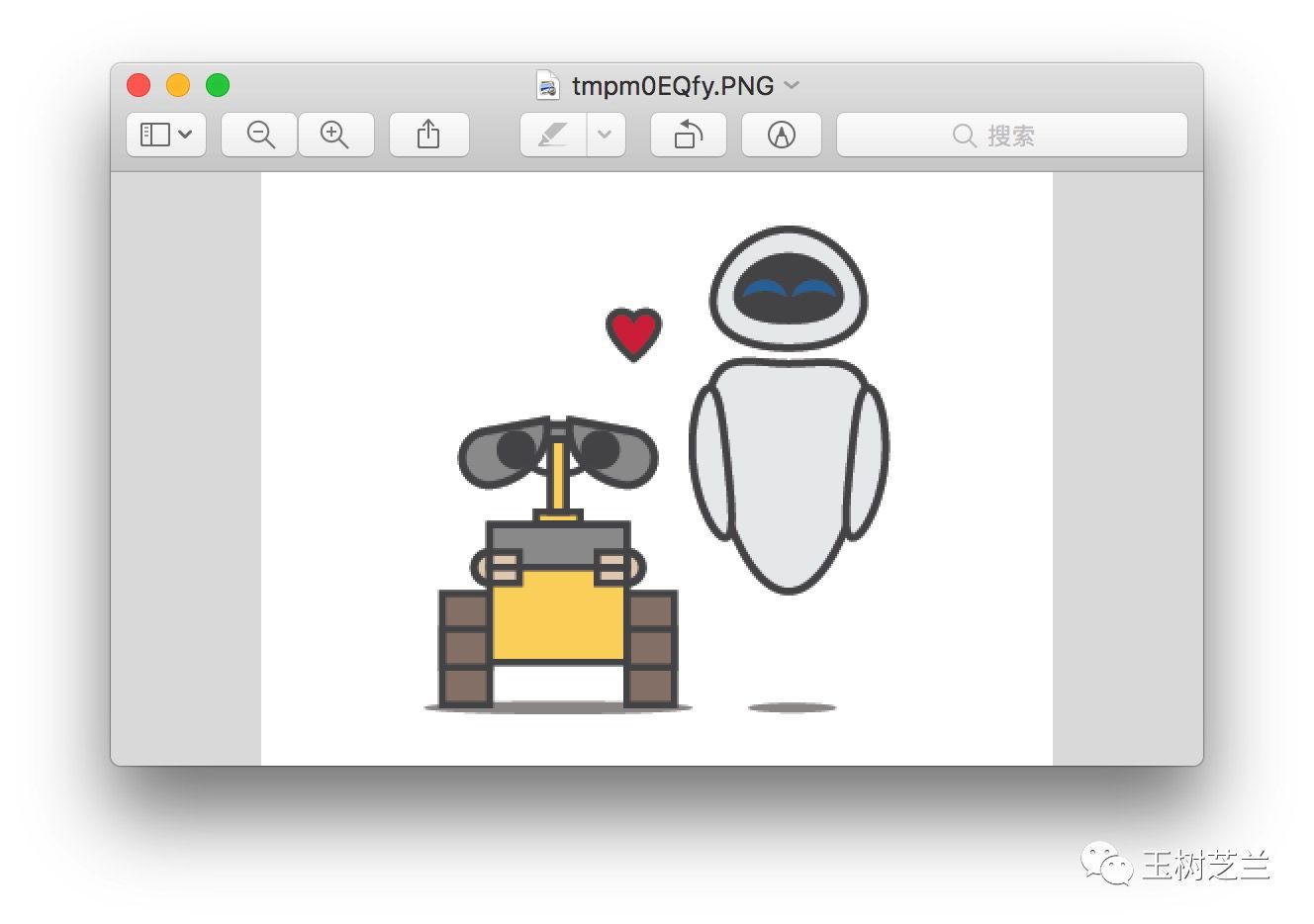
因為深度學習的一個問題在於模型過於複雜,所以我們無法精確判別機器是怎麼錯誤辨識這張圖的。但是我們不難發現這張圖片有些特徵——除了瓦力以外,還有另外一個機器人。
如果你看過這部電影,應該知道兩個機器人之間的關係。這裡我們按下不表。問題在於,這個右上方的機器人圓頭圓腦,看上去與稜角分明的瓦力差別很大。但是,別忘了,哆啦a夢也是圓頭圓腦的。
原理
按照上面一節的程式碼執行後,你應該已經瞭解如何構建自己的圖片分類系統了。在沒有任何原理知識的情況下,你研製的這個模型已經做得非常棒了。不是嗎?
如果你對原理不感興趣,請跳過這一部分,看“小結”。
如果你對知識喜歡刨根問底,那咱們來講講原理。
雖然不過寫了10幾行程式碼,但是你構建的模型卻足夠複雜和高大上。它就是傳說中的摺積神經網路(Convolutional Neural Network, CNN)。
它是深度機器學習模型的一種。最為簡單的摺積神經網路大概長這個樣子:
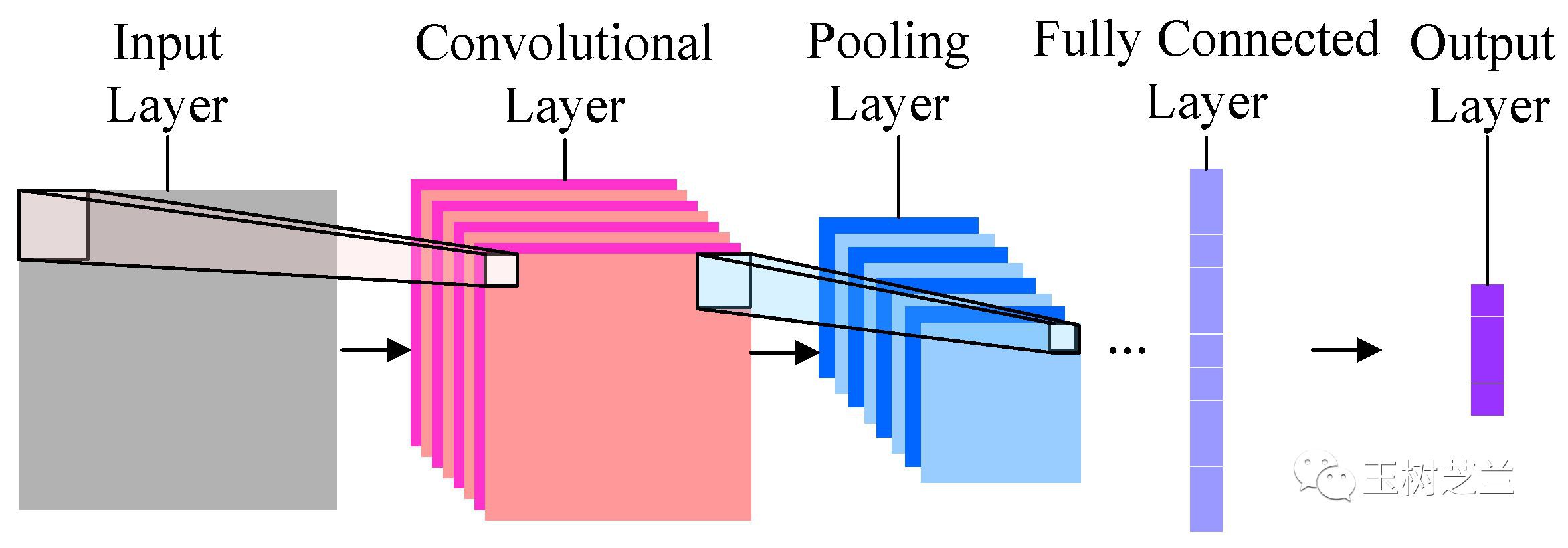
最左邊的,是輸入層。也就是咱們輸入的圖片。本例中,是哆啦a夢和瓦力。
在計算機裡,圖片是按照不同顏色(RGB,即Red, Green, Blue)分層儲存的。就像下麵這個例子。
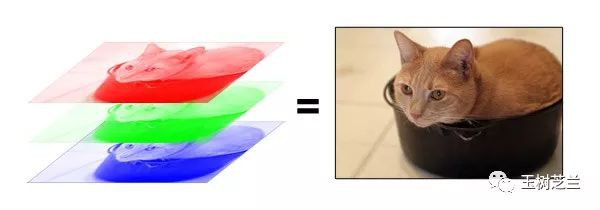
根據解析度不同,電腦會把每一層的圖片存成某種大小的矩陣。對應某個行列位置,存的就是個數字而已。
這就是為什麼,在執行程式碼的時候,你會發現TuriCreate首先做的,就是重新設定圖片的大小。因為如果輸入圖片大小各異的話,下麵步驟無法進行。
有了輸入資料,就順序進入下一層,也就是摺積層(Convolutional Layer)。
摺積層聽起來似乎很神秘和複雜。但是原理非常簡單。它是由若干個過濾器組成的。每個過濾器就是一個小矩陣。
使用的時候,在輸入資料上,移動這個小矩陣,跟原先與矩陣重疊的位置上的數字做乘法後加在一起。這樣原先的一個矩陣,就變成了“摺積”之後的一個數字。
下麵這張動圖,很形象地為你解釋了這一過程。

這個過程,就是不斷從一個矩陣上去尋找某種特徵。這種特徵可能是某個邊緣的形狀之類。
再下一層,叫做“池化層”(Pooling Layer)。這個翻譯簡直讓人無語。我覺得翻譯成“彙總層”或者“取樣層”都要好許多。下文中,我們稱其為“取樣層”。
取樣的目的,是避免讓機器認為“必須在左上角的方格位置,有一個尖尖的邊緣”。實際上,在一張圖片裡,我們要識別的物件可能發生位移。因此我們需要用彙總取樣的方式模糊某個特徵的位置,將其從“某個具體的點”,擴充套件成“某個區域”。
如果這樣說,讓你覺得不夠直觀,請參考下麵這張動圖。

這裡使用的是“最大值取樣”(Max-Pooling)。以原先的2×2範圍作為一個分塊,從中找到最大值,記錄在新的結果矩陣裡。
一個有用的規律是,隨著層數不斷向右推進,一般結果影象(其實正規地說,應該叫做矩陣)會變得越來越小,但是層數會變得越來越多。
只有這樣,我們才能把圖片中的規律資訊抽取出來,並且儘量掌握足夠多的樣式。
如果你還是覺得不過癮,請訪問這個網站。
它為你生動解析了摺積神經網路中,各個層次上到底發生了什麼。

左上角是使用者輸入位置。請利用滑鼠,手寫一個數字(0-9)。寫得難看一些也沒有關係。
我輸入了一個7。
觀察輸出結果,模型正確判斷第一選擇為7,第二可能性為3。回答正確。
讓我們觀察模型建構的細節。
我們把滑鼠挪到第一個摺積層。停在任意一個畫素上。電腦就告訴我們這個點是從上一層圖形中哪幾個畫素,經過特徵檢測(feature detection)得來的。

同理,在第一個Max pooling層上懸停,電腦也可以視覺化展示給我們,該畫素是從哪幾個畫素區塊裡抽樣獲得的。

這個網站,值得你花時間多玩兒一會兒。它可以幫助你理解摺積神經網路的內涵。
回顧我們的示例圖:
下一層叫做全連線層(Fully Connected Layer),它其實就是把上一層輸出的若干個矩陣全部壓縮到一維,變成一個長長的輸出結果。
之後是輸出層,對應的結果就是我們需要讓機器掌握的分類。
如果只看最後兩層,你會很容易把它跟之前學過的深度神經網路(Deep Neural Network, DNN)聯絡起來。

既然我們已經有了深度神經網路,為什麼還要如此費力去使用摺積層和取樣層,導致模型如此複雜呢?
這裡出於兩個考慮:
首先是計算量。圖片資料的輸入量一般比較大,如果我們直接用若干深度神經層將其連線到輸出層,則每一層的輸入輸出數量都很龐大,總計算量是難以想像的。
其次是樣式特徵的抓取。即便是使用非常龐大的計算量,深度神經網路對於圖片樣式的識別效果也未必盡如人意。因為它學習了太多噪聲。而摺積層和取樣層的引入,可以有效過濾掉噪聲,突出圖片中的樣式對訓練結果的影響。
你可能會想,咱們只編寫了10幾行程式碼而已,使用的摺積神經網路一定跟上圖差不多,只有4、5層的樣子吧?
不是這樣的,你用的層數,有足足50層呢!
它的學名,叫做Resnet-50,是微軟的研發成果,曾經在2015年,贏得過ILSRVC比賽。在ImageNet資料集上,它的分類辨識效果,已經超越人類。
我把對應論文的地址附在這裡,如果你有興趣,可以參考。

請看上圖中最下麵的那一個,就是它的大略樣子。
足夠深度,足夠複雜吧。
如果你之前對深度神經網路有一些瞭解,一定會更加覺得不可思議。這麼多層,這麼少的訓練資料量,怎麼能獲得如此好的測試結果呢?而如果要獲得好的訓練效果,大量圖片的訓練過程,豈不是應該花很長時間嗎?
沒錯,如果你自己從頭搭建一個Resnet-50,並且在ImageNet資料集上做訓練,那麼即便你有很好的硬體裝置(GPU),也需要很長時間。
如果你在自己的筆記本上訓練……算了吧。
那麼,TuriCreate難道真的是個奇跡?既不需要花費長時間訓練,又只需要小樣本,就能獲得高水平的分類效果?
不,資料科學裡沒有什麼奇跡。
到底是什麼原因導致這種看似神奇的效果呢?這個問題留作思考題,請善用搜索引擎和問答網站,來幫助自己尋找答案。
小結
透過本文,你已掌握了以下內容:
-
如何在Anaconda虛擬環境下,安裝蘋果公司的機器學習框架TuriCreate。
-
如何在TuriCreate中讀入檔案夾中的圖片資料。並且利用檔案夾的名稱,給圖片打上標記。
-
如何在TuriCreate中訓練深度神經網路,以分辨圖片。
-
如何利用測試資料集,檢驗圖片分類的效果。並且找出分類錯誤的圖片。
-
摺積神經網路(Convolutional Neural Network, CNN)的基本構成和工作原理。
但是由於篇幅所限,我們沒有提及或深入解釋以下問題:
-
如何批次獲取訓練與測試圖片資料。
-
如何利用預處理功能,轉換TuriCreate不能識別的圖片格式。
-
如何從頭搭建一個摺積神經網路(Convolutional Neural Network, CNN),對於模型的層次和引數做到完全掌控。
-
如何既不需要花費長時間訓練,又只需要小樣本,就能獲得高水平的分類效果(提示關鍵詞:遷移學習,transfer learning)。
請你在實踐中,思考上述問題。歡迎留言和傳送郵件,與我交流你的思考所得。
討論
你之前做過圖片分類任務嗎?你是如何處理的?用到了哪些好用的工具?比起咱們的方法,有什麼優缺點?歡迎留言,把你的經驗和思考分享給大家,我們一起交流討論。
●本文編號327,以後想閱讀這篇文章直接輸入327即可
●輸入m獲取文章目錄

大資料與人工智慧
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
