什麼是 SOFAJRaft ?
SOFAJRaft 是一個基於 Raft 一致性演演算法的生產級高效能 Java 實現,支援 MULTI-RAFT-GROUP,適用於高負載低延遲的場景。 使用 SOFAJRaft 你可以專註於自己的業務領域,由 SOFAJRaft 負責處理所有與 Raft 相關的技術難題,並且 SOFAJRaft 非常易於使用,你可以透過幾個示例在很短的時間內掌握它。
SOFAJRaft 是從百度的 braft 移植而來,做了一些最佳化和改進,感謝百度 braft 團隊開源瞭如此優秀的 C++ Raft 實現。
SOFAJRaft :
https://github.com/alipay/sofa-jraft
基礎知識:分散式共識演演算法 (Consensus Algorithm)
如何理解分散式共識?
-
多個參與者 針對 某一件事 達成完全 一致 :一件事,一個結論
-
已達成一致的結論,不可推翻
有哪些分散式共識演演算法?
-
Paxos:被認為是分散式共識演演算法的根本,其他都是其變種,但是 Paxos 論文中只給出了單個提案的過程,並沒有給出複製狀態機中需要的 multi-paxos 的相關細節的描述,實現 Paxos 具有很高的工程複雜度(如多點可寫,允許日誌空洞等)。
-
Zab:被應用在 Zookeeper 中,業界使用廣泛,但沒有抽象成通用的 library。
-
Raft:以容易理解著稱,業界也湧現出很多 Raft 實現,比如大名鼎鼎的 etcd, braft, tikv 等。
什麼是 Raft?
Raft 是一種更易於理解的分散式共識演演算法,核心協議本質上還是師承 Paxos 的精髓,不同的是依靠 Raft 模組化的拆分以及更加簡化的設計,Raft 協議相對更容易實現。
模組化的拆分主要體現在:Raft 把一致性協議劃分為 Leader 選舉、Membership 變更、日誌複製、Snapshot 等幾個幾乎完全解耦的模組。
更加簡化的設計則體現在:Raft 不允許類似 Paxos 中的亂序提交、簡化系統中的角色狀態(只有 Leader、Follower、Candidate 三種角色)、限制僅 Leader 可寫入、使用隨機化的超時時間來設計 Leader Election 等等。
特點:Strong Leader
-
系統中必須存在且同一時刻只能有一個 Leader,只有 Leader 可以接受 Clients 發過來的請求;
-
Leader 負責主動與所有 Followers 通訊,負責將“提案”傳送給所有 Followers,同時收集多數派的 Followers 應答;
-
Leader 還需向所有 Followers 主動傳送心跳維持領導地位(保持存在感)。
一句話總結 Strong Leader:“你們不要 BB! 按我說的做,做完了向我彙報!”。
另外,身為 Leader 必須保持一直 BB(heartbeat) 的狀態,否則就會有別人跳出來想要 BB 。

Raft 中的基本概念
篇幅有限,這裡只對 Raft 中的幾個概念做一個簡單介紹,詳細請參考 Raft paper。
Raft-node 的 3 種角色/狀態

1. Follower:完全被動,不能傳送任何請求,只接受並響應來自 Leader 和 Candidate 的 Message,每個節點啟動後的初始狀態一定是 Follower;
2. Leader:處理所有來自客戶端的請求,以及複製 Log 到所有 Followers;
3. Candidate:用來競選一個新 Leader (Candidate 由 Follower 觸發超時而來)。
Message 的 3 種型別
1. RequestVote RPC:由 Candidate 發出,用於傳送投票請求;
2. AppendEntries (Heartbeat) RPC:由 Leader 發出,用於 Leader 向 Followers 複製日誌條目,也會用作 Heartbeat (日誌條目為空即為 Heartbeat);
3. InstallSnapshot RPC:由 Leader 發出,用於快照傳輸,雖然多數情況都是每個伺服器獨立建立快照,但是 Leader 有時候必鬚髮送快照給一些落後太多的 Follower,這通常發生在 Leader 已經丟棄了下一條要發給該 Follower 的日誌條目(Log Compaction 時清除掉了) 的情況下。
任期邏輯時鐘
1. 時間被劃分為一個個任期 (term),term id 按時間軸單調遞增;
2. 每一個任期開始後要做的第一件事都是 Leader 選舉,選舉成功之後,Leader 在任期內管理整個叢集,也就是 “選舉 + 常規操作”;
3. 每個任期最多一個 Leader,可能沒有 Leader (spilt-vote 導致)。
 本圖出自《Raft: A Consensus Algorithm for Replicated Logs》
本圖出自《Raft: A Consensus Algorithm for Replicated Logs》
什麼是 SOFAJRaft?
SOFAJRaft 是一個基於 Raft 一致性演演算法的生產級高效能 Java 實現,支援 MULTI-RAFT-GROUP,適用於高負載低延遲的場景。 使用 SOFAJRaft 你可以專註於自己的業務領域,由 SOFAJRaft 負責處理所有與 Raft 相關的技術難題,並且 SOFAJRaft 非常易於使用,你可以透過幾個示例在很短的時間內掌握它。
SOFAJRaft 是從百度的 braft 移植而來,做了一些最佳化和改進,感謝百度 braft 團隊開源瞭如此優秀的 C++ Raft 實現。
SOFAJRaft 整體功能&效能最佳化
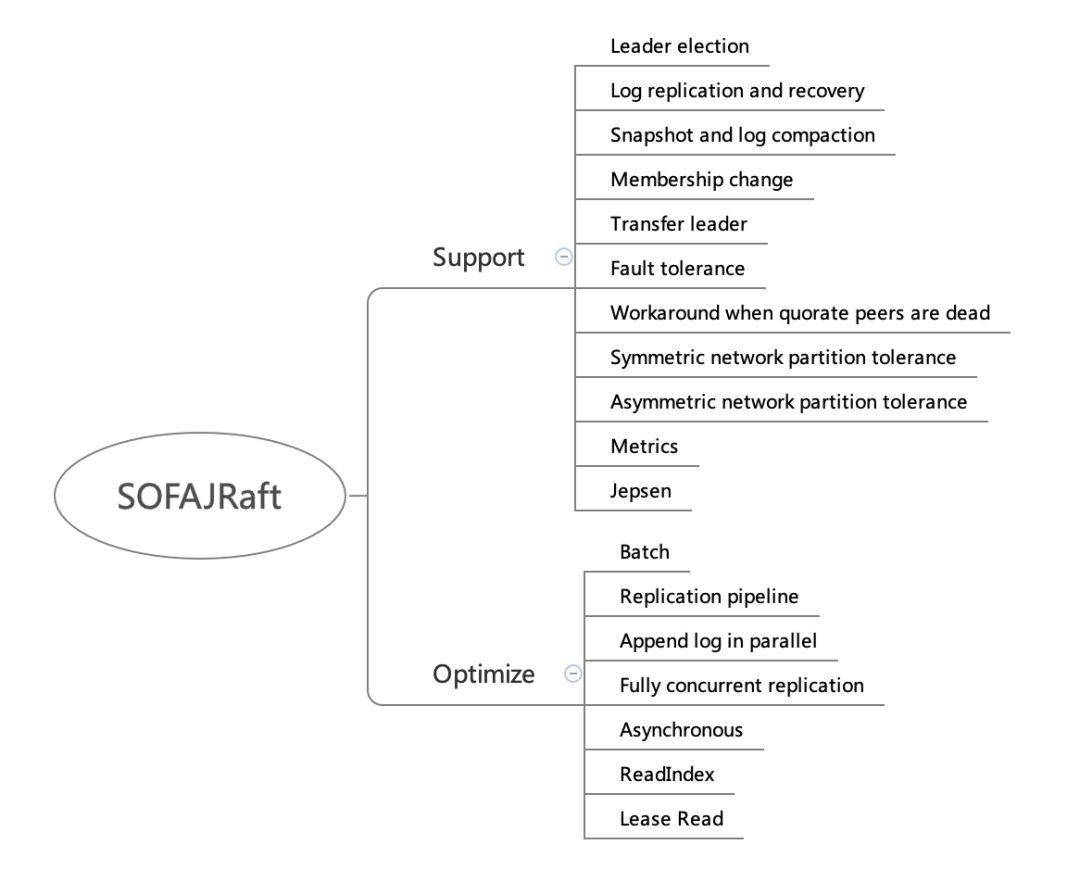
功能支援
1. Leader election:Leader 選舉,這個不多說,上面已介紹過 Raft 中的 Leader 機制。
2. Log replication and recovery:日誌複製和日誌恢復。
-
Log replication 就是要保證已經被 commit 的資料一定不會丟失,即一定要成功複製到多數派。
-
Log recovery 包含兩個方面:
-
Current term 日誌恢復:主要針對一些 Follower 節點重啟加入叢集或者是新增 Follower 節點後如何追日誌;
-
Prev term 日誌恢復:主要針對 Leader 切換前後的日誌一致性。
3. Snapshot and log compaction:定時生成 snapshot,實現 log compaction 加速啟動和恢復,以及 InstallSnapshot 給 Followers 複製資料,如下圖:
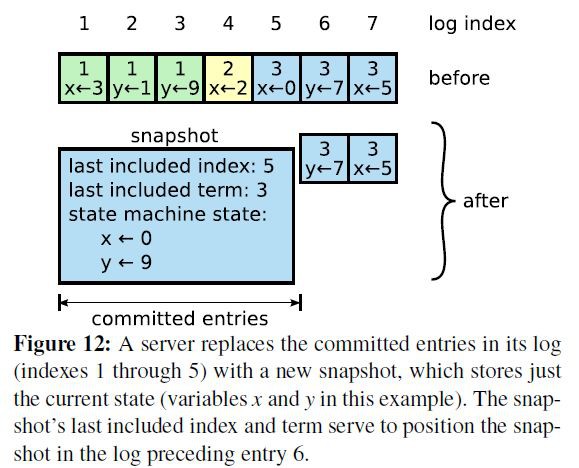 本圖出自《In Search of an Understandable Consensus Algorithm》
本圖出自《In Search of an Understandable Consensus Algorithm》
4. Membership change:用於叢集線上配置變更,比如增加節點、刪除節點、替換節點等。
5. Transfer leader:主動變更 Leader,用於重啟維護,Leader 負載平衡等。
6. Symmetric network partition tolerance:對稱網路分割槽容忍性。

如上圖 S1 為當前 Leader,網路分割槽造成 S2 不斷增加本地 term,為了避免網路恢復後 S2 發起選舉導致正在良心 工作的 Leader step-down,從而導致整個叢集重新發起選舉,SOFAJRaft 中增加了 pre-vote 來避免這個問題的發生。
-
SOFAJRaft 中在 request-vote 之前會先進行 pre-vote(currentTerm + 1, lastLogIndex, lastLogTerm),多數派成功後才會轉換狀態為 candidate 發起真正的 request-vote,所以分割槽後的節點,pre-vote 不會成功,也就不會導致叢集一段時間內無法正常提供服務。
7. Asymmetric network partition tolerance:非對稱網路分割槽容忍性。
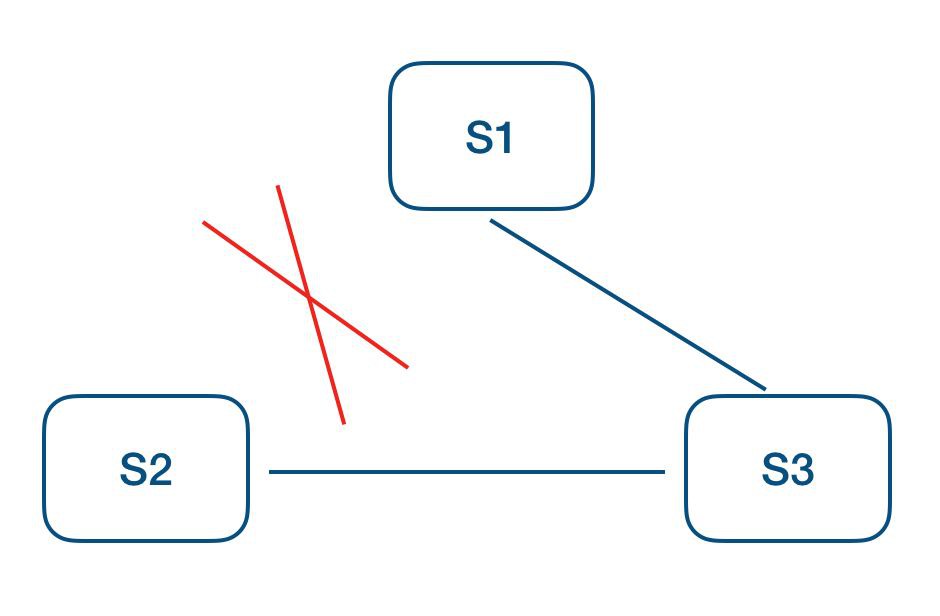
如上圖 S1 為當前 Leader,S2 不斷超時觸發選主,S3 提升 term 打斷當前 lease,從而拒絕 Leader 的更新。
-
在 SOFAJRaft 中增加了一個 tick 的檢查,每個 Follower 維護一個時間戳記錄下收到 Leader 上資料更新的時間(也包括心跳),只有超過 election timeout 之後才允許接受 request-vote 請求。
8. Fault tolerance:容錯性,少數派故障不影響系統整體可用性,包括但不限於:
-
機器掉電
-
強殺應用
-
慢節點(GC, OOM 等)
-
網路故障
-
其他各種奇葩原因導致 Raft 節點無法正常工作
9. Workaround when quorate peers are dead:多數派故障時,整個 group 已不具備可用性,安全的做法是等待多數節點恢復,只有這樣才能保證資料安全;但是如果業務更加追求系統可用性,可以放棄資料一致性的話,SOFAJRaft 提供了手動觸發 reset_peers 的指令以迅速重建整個叢集,恢復叢集可用。
10. Metrics:SOFAJRaft 內建了基於 Metrics 類庫的效能指標統計,具有豐富的效能統計指標,利用這些指標資料可以幫助使用者更容易找出系統效能瓶頸。
11. Jepsen:除了幾百個單元測試以及部分 chaos 測試之外, SOFAJRaft 還使用 jepsen 這個分散式驗證和故障註入測試框架模擬了很多種情況,都已驗證透過:
-
隨機分割槽,一大一小兩個網路分割槽
-
隨機增加和移除節點
-
隨機停止和啟動節點
-
隨機 kill -9 和啟動節點
-
隨機劃分為兩組,互通一個中間節點,模擬分割槽情況
-
隨機劃分為不同的 majority 分組
效能最佳化
除了功能上的完整性,SOFAJRaft 還做了很多效能方面的最佳化,這裡有一份 KV 場景(get/put)的 Benchmark 資料(連結見文末), 在小資料包,讀寫比例為 9:1,保證線性一致讀的場景下,三副本最高可以達到 40w+ 的 ops。
這裡挑重點介紹幾個最佳化點:
1. Batch: 我們知道網際網路兩大最佳化法寶便是 Cache 和 Batch,SOFAJRaft 在 Batch 上花了較大心思,整個鏈路幾乎都是 Batch 的,依靠 disruptor 的 MPSC 模型批次消費,對整體效能有著極大的提升,包括但不限於:
-
批次提交 task
-
批次網路傳送
-
本地 IO batch 寫入
要保證日誌不丟,一般每條 log entry 都要進行 fsync 同步刷盤,比較耗時,SOFAJRaft 中做了合併寫入的最佳化。
-
批次應用到狀態機
-
需要說明的是,雖然 SOFAJRaft 中大量使用了 Batch 技巧,但對單個請求的延時並無任何影響,SOFAJRaft 中不會對請求做延時的攢批處理。
2. Replication pipeline:流水線複製,通常 Leader 跟 Followers 節點的 Log 同步是序列 Batch 的方式,每個 Batch 傳送之後需要等待 Batch 同步完成之後才能繼續傳送下一批(ping-pong),這樣會導致較長的延遲。SOFAJRaft 中透過 Leader 跟 Followers 節點之間的 pipeline 複製來改進,非常有效降低了資料同步的延遲,提高吞吐。經我們測試,開啟 pipeline 可以將吞吐提升 30% 以上,詳細資料請參照 Benchmark。
3. Append log in parallel:在 SOFAJRaft 中 Leader 持久化 log entries 和向 Followers 傳送 log entries 是並行的。
4. Fully concurrent replication:Leader 向所有 Follwers 傳送 Log 也是完全相互獨立和併發的。
-
Asynchronous:SOFAJRaft 中整個鏈路幾乎沒有任何阻塞,完全非同步的,是一個完全的 callback 程式設計模型。
-
ReadIndex:最佳化 Raft read 走 Raft log 的效能問題,每次 read,僅記錄 commitIndex,然後傳送所有 peers heartbeat 來確認 Leader 身份,如果 Leader 身份確認成功,等到 appliedIndex >= commitIndex,就可以傳回 Client read 了,基於 ReadIndex Follower 也可以很方便的提供線性一致讀,不過 commitIndex 是需要從 Leader 那裡獲取,多了一輪 RPC;關於線性一致讀文章後面會詳細分析。
-
Lease Read:SOFAJRaft 還支援透過租約 (lease) 保證 Leader 的身份,從而省去了 ReadIndex 每次 heartbeat 確認 Leader 身份,效能更好,但是透過時鐘維護 lease 本身並不是絕對的安全(時鐘漂移問題,所以 SOFAJRaft 中預設配置是 ReadIndex,因為通常情況下 ReadIndex 效能已足夠好)。
SOFAJRaft 設計

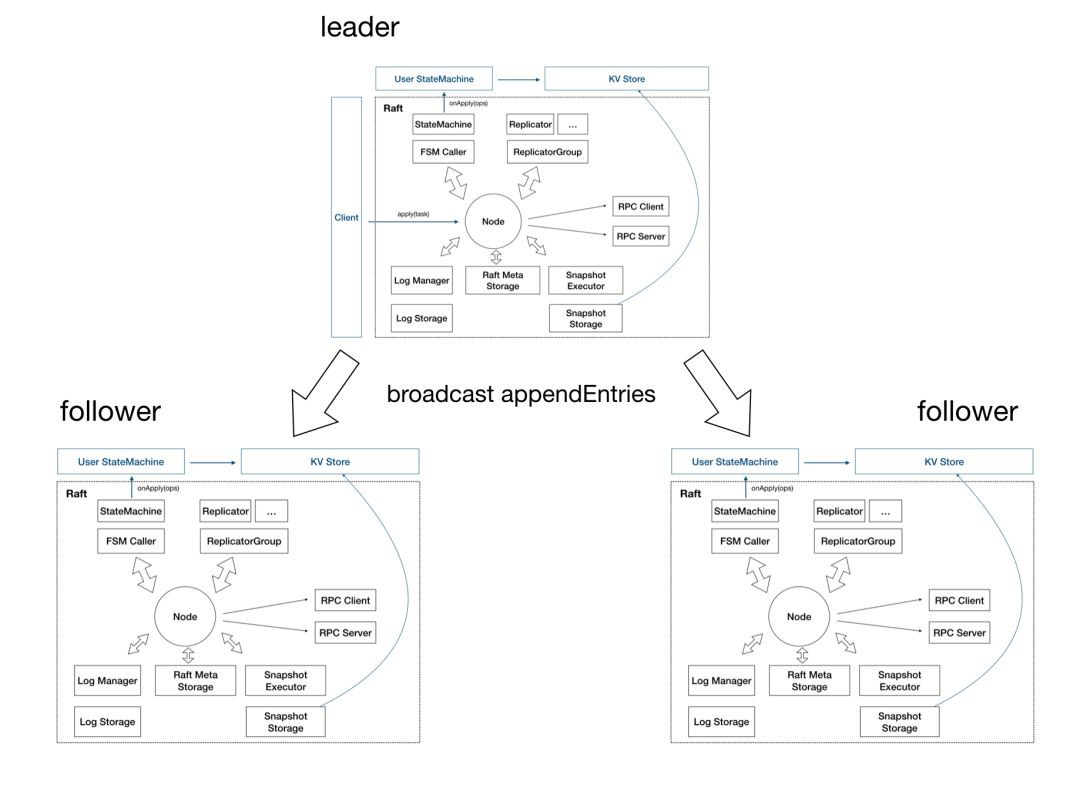
1. Node:Raft 分組中的一個節點,連線封裝底層的所有服務,使用者看到的主要服務介面,特別是 apply(task)用於向 raft group 組成的複製狀態機叢集提交新任務應用到業務狀態機。
2.儲存:上圖靠下的部分均為儲存相關。
-
Log 儲存,記錄 Raft 使用者提交任務的日誌,將日誌從 Leader 複製到其他節點上。
-
LogStorage 是儲存實現,預設實現基於 RocksDB 儲存,你也可以很容易擴充套件自己的日誌儲存實現;
-
LogManager 負責對底層儲存的呼叫,對呼叫做快取、批次提交、必要的檢查和最佳化。
-
Metadata 儲存,元資訊儲存,記錄 Raft 實現的內部狀態,比如當前 term、投票給哪個節點等資訊。
-
Snapshot 儲存,用於存放使用者的狀態機 snapshot 及元資訊,可選:
-
SnapshotStorage 用於 snapshot 儲存實現;
-
SnapshotExecutor 用於 snapshot 實際儲存、遠端安裝、複製的管理。
3. 狀態機
-
StateMachine:使用者核心邏輯的實現,核心是
onApply(Iterator)方法, 應用透過Node#apply(task)提交的日誌到業務狀態機; -
FSMCaller:封裝對業務 StateMachine 的狀態轉換的呼叫以及日誌的寫入等,一個有限狀態機的實現,做必要的檢查、請求合併提交和併發處理等。
4. 複製
-
Replicator:用於 Leader 向 Followers 複製日誌,也就是 Raft 中的 AppendEntries 呼叫,包括心跳存活檢查等;
-
ReplicatorGroup:用於單個 Raft group 管理所有的 replicator,必要的許可權檢查和派發。
5. RPC:RPC 模組用於節點之間的網路通訊
-
RPC Server:內建於 Node 內的 RPC 伺服器,接收其他節點或者客戶端發過來的請求,轉交給對應服務處理;
-
RPC Client:用於向其他節點發起請求,例如投票、複製日誌、心跳等。
6. KV Store:KV Store 是各種 Raft 實現的一個典型應用場景,SOFAJRaft 中包含了一個嵌入式的分散式 KV 儲存實現(SOFAJRaft-RheaKV)。
SOFAJRaft Group
單個節點的 SOFAJRaft-node 是沒什麼實際意義的,下麵是三副本的 SOFAJRaft 架構圖:
SOFAJRaft Multi Group
單個 Raft group 是無法解決大流量的讀寫瓶頸的,SOFAJRaft 自然也要支援 multi-raft-group。

SOFAJRaft 實現細節解析之高效的線性一致讀
什麼是線性一致讀? 所謂線性一致讀,一個簡單的例子就是在 t1 的時刻我們寫入了一個值,那麼在 t1 之後,我們一定能讀到這個值,不可能讀到 t1 之前的舊值 (想想 Java 中的 volatile 關鍵字,說白了線性一致讀就是在分散式系統中實現 Java volatile 語意)。

如上圖 Client A、B、C、D 均符合線性一致讀,其中 D 看起來是 stale read,其實並不是,D 請求橫跨了 3 個階段,而讀可能發生在任意時刻,所以讀到 1 或 2 都行。
重要:接下來的討論均基於一個大前提,就是業務狀態機的實現必須是滿足線性一致性的,簡單說就是也要具有 Java volatile 的語意。
1. 要實現線性一致讀,首先我們簡單直接一些,是否可以直接從當前 Leader 節點讀?
-
仔細一想,這顯然行不通,因為你無法確定這一刻當前的 “Leader” 真的是 Leader,比如在網路分割槽的情況下,它可能已經被推翻王朝卻不自知。
2. 最簡單易懂的實現方式:同 “寫” 請求一樣,“讀” 請求也走一遍 Raft 協議 (Raft Log)
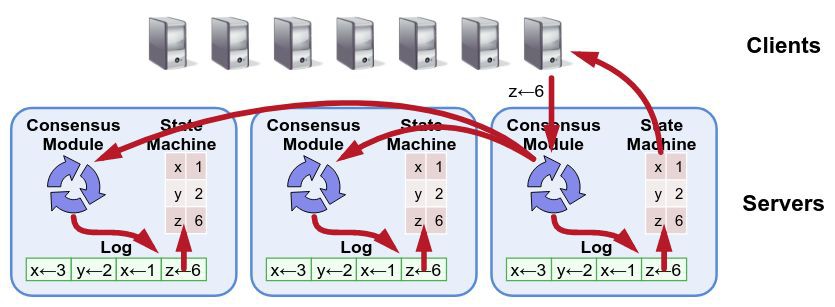
本圖出自《Raft: A Consensus Algorithm for Replicated Logs》
-
這一定是可以的,但效能上顯然不會太出色,走 Raft Log 不僅僅有日誌落盤的開銷,還有日誌複製的網路開銷,另外還有一堆的 Raft “讀日誌” 造成的磁碟佔用開銷,這在讀比重很大的系統中通常是無法被接受的。
3. ReadIndex Read
-
這是 Raft 論文中提到的一種最佳化方案,具體來說:
-
Leader 將自己當前 Log 的 commitIndex 記錄到一個 Local 變數 ReadIndex 裡面;
-
接著向 Followers 發起一輪 heartbeat,如果半數以上節點傳回了對應的 heartbeat response,那麼 Leader 就能夠確定現在自己仍然是 Leader (證明瞭自己是自己);
-
Leader 等待自己的狀態機執行,直到 applyIndex 超過了 ReadIndex,這樣就能夠安全的提供 Linearizable Read 了,也不必管讀的時刻是否 Leader 已飄走 (思考:為什麼等到 applyIndex 超過了 ReadIndex 就可以執行讀請求?);
-
Leader 執行 read 請求,將結果傳回給 Client。
-
透過 ReadIndex,也可以很容易在 Followers 節點上提供線性一致讀:
-
Follower 節點向 Leader 請求最新的 ReadIndex;
-
Leader 執行上面前 3 步的過程(確定自己真的是 Leader),並傳回 ReadIndex 給 Follower;
-
Follower 等待自己的 applyIndex 超過了 ReadIndex;
-
Follower 執行 read 請求,將結果傳回給 Client。(SOFAJRaft 中可配置是否從 Follower 讀取,預設不開啟)
-
ReadIndex小結:
-
相比較於走 Raft Log 的方式,ReadIndex 省去了磁碟的開銷,能大幅度提升吞吐,結合 SOFAJRaft 的 batch + pipeline ack + 全非同步機制,三副本的情況下 Leader 讀的吞吐可以接近於 RPC 的吞吐上限;
-
延遲取決於多數派中最慢的一個 heartbeat response,理論上對於降低延時的效果不會非常顯著。
4. Lease Read
-
Lease Read 與 ReadIndex 類似,但更進一步,不僅省去了 Log,還省去了網路互動。它可以大幅提升讀的吞吐也能顯著降低延時。
-
基本的思路是 Leader 取一個比 election timeout 小的租期(最好小一個數量級),在租約期內不會發生選舉,這就確保了 Leader 不會變,所以可以跳過 ReadIndex 的第二步,也就降低了延時。可以看到 Lease Read 的正確性和時間是掛鉤的,因此時間的實現至關重要,如果時鐘漂移嚴重,這套機制就會有問題。
-
實現方式:
-
定時 heartbeat 獲得多數派響應,確認 Leader 的有效性 (在 SOFAJRaft 中預設的 heartbeat 間隔是 election timeout 的十分之一);
-
在租約有效時間內,可以認為當前 Leader 是 Raft Group 內的唯一有效 Leader,可忽略 ReadIndex 中的 heartbeat 確認步驟(2);
-
Leader 等待自己的狀態機執行,直到 applyIndex 超過了 ReadIndex,這樣就能夠安全的提供 Linearizable Read 了 。
在 SOFAJRaft 中發起一次線性一致讀請求的程式碼展示:
// KV 儲存實現線性一致讀public void readFromQuorum(String key, AsyncContext asyncContext) {// 請求 ID 作為請求背景關係傳入byte[] reqContext = new byte[4];Bits.putInt(reqContext, 0, requestId.incrementAndGet());// 呼叫 readIndex 方法, 等待回呼執行this.node.readIndex(reqContext, new ReadIndexClosure() {public void run(Status status, long index, byte[] reqCtx) {if (status.isOk()) {try {// ReadIndexClosure 回呼成功,可以從狀態機讀取最新資料傳回// 如果你的狀態實現有版本概念,可以根據傳入的日誌 index 編號做讀取asyncContext.sendResponse(new ValueCommand(fsm.getValue(key)));} catch (KeyNotFoundException e) {asyncContext.sendResponse(GetCommandProcessor.createKeyNotFoundResponse());}} else {// 特定情況下,比如發生選舉,該讀請求將失敗asyncContext.sendResponse(new BooleanCommand(false, status.getErrorMsg()));}}});}
SOFAJRaft 應用場景?
-
Leader 選舉;
-
分散式鎖服務,比如 Zookeeper,在 SOFAJRaft 中的 RheaKV 模組提供了完整的分散式鎖實現;
-
高可靠的元資訊管理,可直接基於 SOFAJRaft-RheaKV 儲存;
-
分散式儲存系統,如分散式訊息佇列、分散式檔案系統、分散式塊系統等等。
使用案例
-
RheaKV:基於 SOFAJRaft 實現的嵌入式、分散式、高可用、強一致的 KV 儲存類庫。
-
AntQ Streams QCoordinator:使用 SOFAJRaft 在 Coordinator 叢集內做選舉、使用 SOFAJRaft-RheaKV 做元資訊儲存等功能。
-
Schema Registry:高可靠 schema 管理服務,類似 kafka schema registry,儲存部分基於 SOFAJRaft-RheaKV。
-
SOFA 服務註冊中心元資訊管理模組:IP 資料資訊註冊,要求寫資料達到各個節點一致,並且在少數派節點掛掉時保證不影響資料正常儲存。
實踐
一、基於 SOFAJRaft 設計一個簡單的 KV Store

二、基於 SOFAJRaft 的 RheaKV 的設計

功能名詞
PD
-
全域性的中心總控節點,負責整個叢集的排程,不需要自管理的叢集可不啟用 PD (一個 PD 可管理多個叢集,基於 clusterId 隔離)。
Store
-
叢集中的一個物理儲存節點,一個 Store 包含一個或多個 Region。
Region
-
最小的 KV 資料單元,每個 Region 都有一個左閉右開的區間 [startKey, endKey), 可根據請求流量/負載/資料量大小等指標自動分裂以及自動副本搬遷。
特點
-
嵌入式
-
強一致性
-
自驅動
-
自診斷、 自最佳化、自決策
以上幾點(尤其2、3) 基本都是依託於 SOFAJRaft 自身的功能來實現,詳細介紹請參考 SOFAJRaft 檔案 。
致謝
感謝 braft、etcd、tikv 貢獻了優秀的 Raft 實現,SOFAJRaft 受益良多。
招聘
螞蟻金服中介軟體團隊持續在尋找對於基礎中介軟體(如訊息、資料中介軟體以及分散式計算等)以及下一代高效能面向實時分析的時序資料庫等方向充滿熱情的小夥伴加入,有意者請聯絡 boyan@antfin.com。
參考資料
-
SOFAJRaft 原始碼:
https://github.com/alipay/sofa-jraft
-
SOFAJRaft 詳細檔案:
https://github.com/alipay/sofa-jraft/wiki
-
Raft:
https://raft.github.io
-
Raft paper:
https://raft.github.io/raft.pdf
-
Raft: A Consensus Algorithm for Replicated Logs:
https://raft.github.io/slides/raftuserstudy2013.pdf
-
Paxos/Raft 分散式一致性演演算法原理剖析及其在實戰中的應用:
https://github.com/hedengcheng/tech/tree/master/distributed
-
braft 檔案:
https://github.com/brpc/braft/blob/master/docs/cn/raft_protocol.md
-
線性一致性和 Raft:
https://pingcap.com/blog-cn/linearizability-and-raft
-
Strong consistency models:
https://aphyr.com/posts/313-strong-consistency-models
-
etcd raft 設計與實現《一》:
https://zhuanlan.zhihu.com/p/51063866
-
Metrics:
https://metrics.dropwizard.io/4.0.0/getting-started.html
-
Jepsen:
https://github.com/jepsen-io/jepsen
-
Benchmark:
https://github.com/alipay/sofa-jraft/wiki/Benchmark-%E6%95%B0%E6%8D%AE

長按關註,獲取分散式架構乾貨
歡迎大家共同打造 SOFAStack https://github.com/alipay

