以Kubernetes為代表的容器編排工具在應用開發部署領域起正發揮著顛覆性的變革作用。隨著微服務架構的發展,從開發人員的角度來看,應用邏輯架構與基礎設施架構之間開始解耦,這意味著開發者能夠將精力更多集中在軟體構建以及價值交付身上。
Kubernetes的作用,在於對其管理的物理伺服器進行抽象。在Kubernetes的幫助下,我們可以描述並使用所需要的記憶體與計算容量的總和,而不再關註底層基礎設施架構。
當管理Docker映象的時候,Kubernetes也讓實際應用變的十分便捷靈活。在利用Kubernetes進行容器架構的應用部署時,管理員們將在無需修改底層程式碼的前提下將其部署在任何位置——包括公有雲、混合雲乃至私有雲。
雖然Kubernetes在擴充套件性、便攜性與管理性等方面的表現都相當給力,但截至目前,它仍然不支援儲存狀態。與之對應的是,如今的大多數應用都是有狀態的——換言之,要求在一定程度上配合外部儲存資源。
Kubernetes架構本身非常靈的,能夠根據開發者的需求、規範以及實際負載情況,對容器進行隨意建立與撤銷。此外,Pod和容器還具有自我修複與複製能力。因此從本質上講,它們的生命週期普遍非常短暫。
但是,現有持久儲存解決方法無法支援動態的應用場景,而持久化儲存也無法滿足動態建立與撤銷的需求。
當我們需要將有狀態應用部署到其它基礎架構平臺,或者另一家內部或混合雲供應商的環境中時,可移植性低下無疑將成為我們面臨的巨大挑戰。更具體地講,持久化儲存解決方案往往會鎖定於特定雲服務供應商,而無法靈活完成轉移。
另外,雲原生應用中的儲存機制也相當複雜、難於理解。Kubernetes中的不少儲存術語極易混淆,其中包含著複雜的含義與微妙的變化。再有,在原生Kubernetes、開源框架以及託管與付費服務之間還存在著諸多選項,這極大增加了開發人員在做出決定之前的考量與試驗成本。
我們首先從最簡單的場景出發,即在Kubernetes當中部署一套資料庫。具體流程包括:選擇一套符合需求的資料庫,讓它在本地磁碟上執行,然後將其作為新的工作負載部署到叢集當中。但是,由於資料庫中存在的一些固有屬性,這種方式往往無法帶來符合預期的效果。
容器本身是基於無狀態原則進行構建的,憑藉這一天然屬性,我們才能如此輕鬆地啟動或撤銷容器環境。由於不存在需要儲存及遷移的資料,叢集也就不需要同磁碟讀寫這類密集型操作系結在一起了。
但對於資料庫,其狀態必須隨時儲存。如果以容器方式部署在叢集當中的資料庫不需要進行遷移,或者不需要頻繁開關,那麼其基本屬性就相當於一種物理儲存裝置。在理想情況下,使用資料的容器應該與該資料庫處於同一Pod當中。
當然,這並不是說將資料庫部署在容器中的作法不可取。在某些應用場景下,這樣的設計完全能夠滿足需求。舉例來說,在測試環境或者處理非生產級資料時,由於總體資料量很小,將資料庫納入叢集完全沒有問題。
但在實際生產中,開發人員往往需要仰仗於外部儲存機制。
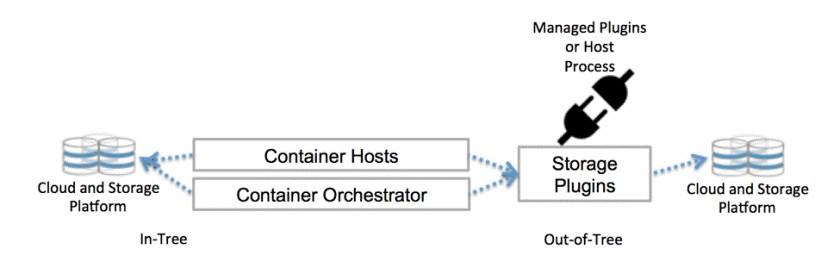
Kubernetes到底是如何與儲存資源彼此通訊的?其利用的是控制層介面。這些介面負責將Kubernetes與外部儲存相對接。接入Kubernetes的外部儲存解決方案被稱為“捲外掛(Volume Plugins)”。正是有了捲外掛的存在,儲存資源才得以抽象化並實現可移植性。
以前,捲外掛一般由核心Kubernetes程式碼庫進行構建、連結、編譯以及裝載。這樣就極大的限制了開發人員的發揮空間,同時也帶來了額外的維護開銷。因此,專案維護人員們決定在Kubernete的程式碼庫上增加一些新的儲存功能。
隨著CSI以及Flexvolume的引入,捲外掛如今可以在叢集中直接部署,而完全無需更改程式碼庫。
原生Kubernetes如何處理儲存資源?它提供一系列管理儲存選項:除了臨時選項之外,還包括持持久捲(Persistent Volumes),持久捲宣告(Persistent Volume Claims),儲存類(Storage Classes)乃至StatefulSets等持久儲存形式。似乎有點亂,下麵我們就對其進行一一解釋。
持久捲是由管理員負責配置的儲存單元,它們獨立於任何單一Pod之外,因此不受Pod生命週期的影響。
另一方面,持久捲宣告是對儲存資源——也就是持久捲——的需求。有了持久捲宣告,我們就可以將儲存與特定的節點系結在一起使用。
使用靜態儲存時,管理員根據預估對持久捲進行預配置,這些持久捲將被手動系結到具有明確持久捲宣告的特定Pod上。
實際上,靜態定義的持久捲並不能適應Kubernetes的可移植特性,因為儲存資源具有對環境的依賴性——例如AWS EBS或者GCE Persistent Disk。另外,手動系結還需要根據不同供應商的儲存方案修改YAML檔案。
在資源分配方面,靜態配置實際上也違背了Kubernetes的設計原則。後者的CPU與記憶體並非事先被分配好系結在Pod或者容器上,而是以被動態形式進行分配。
動態分配則依靠儲存類來實現。叢集管理員不需要預先手動建立持久捲,而是建立類似於模板的檔案。當開發人員製作持久捲宣告時,只需要根據實際需求建立一套模板並附加至Pod即可。
透過簡單的說明,相信大家已經瞭解了原生Kubernetes對外部儲存資源的使用方式。當然,這裡僅僅做出概括,實際使用場景中還有更多其它因素需要考量。
下麵來看容器儲存介面(簡稱CSI)。CSI是由CNCF儲存工作組建立的統一標準,旨在定義一個標準的容器儲存介面,從而使儲存驅動程式能夠在任意容器架構下正常起效。
CSI規範目前已經在Kubernetes中得到普及,大量驅動外掛被預先部署在Kubernetes叢集內供開發人員使用。如此一來,我們就可以利用Kubernetes上的CSI捲來訪問與CSI相容的開放儲存捲。
CSI的引入,意味著儲存資源能夠作為Kubernetes叢集上的另一種工作負載實現容器化以及部署。
目前,圍繞雲原生技術湧現出大量工具與專案。但作為生產場景中的一大突出問題,我們往往很難在雲原生架構中選擇最合適的開源專案。換言之,解決方案選項太多,反而令儲存需求變得更難解決。
從人氣角度來看,目前最流行的儲存專案當數Ceph與Rook。
Ceph是一種動態託管、橫向擴充套件的分散式儲存叢集。Ceph面向儲存資源提供一種邏輯抽象機制,其設計理念包括無單點故障、自管理以及軟體定義等特性。Ceph可以面向同一套儲存叢集分別提供塊儲存、物件儲存以及檔案儲存的對應介面。
Ceph架構相當複雜的,其中使用到大量的底層技術,例如RADOS、librados、RADOSGW、RDB、CRUSH演演算法,外加monitor、OSD以及MDS等功能性元件。這裡我們先不談它的底層架構,關鍵在於Ceph屬於一種分散式儲存叢集,這使得擴充套件更便利、能夠在不犧牲效能的前提下消除單點故障,且提供涵蓋物件儲存、塊儲存以及檔案儲存的統一儲存體系。
很明顯,Ceph與雲原生環境彼此相容的,我們也可以利用多種方法部署一套Ceph叢集,譬如使用Ansible。我們可以部署一套Ceph叢集,並使用CSI與持久捲宣告來提供指向Kubernetes叢集的介面。
另一個有趣且頗具人氣的專案是Rook,這是一項旨在將Kubernetes與Ceph融合起來的技術方案。從本質上講,它將計算節點和儲存節點放進了同一個叢集當中。
Rook是一種雲原生編排器,並對Kubernetes做出擴充套件。Rook允許使用者將Ceph放置在容器內,同時提供捲管理邏輯以立足Kubernetes之上實現Ceph的可靠執行。Rook還使本應由叢集管理員操作的多種任務完成了自動化實現,其中包括部署、引導、配置、擴充套件以及負載均衡等等。
Rook可以像Kubernetes一樣使用yaml檔案來部署Ceph叢集。這種檔案以高階宣告的形式存在,負責為叢集管理員提供所需要的全部內容。
Rook在叢集啟動完成後,即開始進行實時監控。Rook將以操作端或者控制端的姿態確保yaml檔案中所宣告的狀態始終正常。Rook執行在一套協調的邏輯迴圈中,該迴圈將觀察執行狀態並根據檢測到的異常採取響應。
Rook自身不具備持久狀態,也不需要單獨管理。這,才是真正與Kubernetes設計原則相符的儲存資源管理方案。
Rook憑藉著將Ceph與Kubernetes協同起來的強大能力,成為目前最受歡迎的雲原生儲存解決方案。Rook專案已經在GitHub上獲得近4000顆星,1600多萬次的下載,並吸引到100多名貢獻者。
作為CNCF認可的第一個儲存專案,Rook現在已經進入孵化階段。
對於實際應用層面出現的任何問題,最重要的自然是判斷需求、設計系統或者選擇適當的工具。同樣的道理也適用於雲原生環境。雖然具體問題非常複雜,但也必然會出現大量工具方案嘗試解決。隨著雲原生世界的持續發展,我們可以肯定,新的解決方案將不斷湧現。未來,一切都會更加美好!
原文連結:https://softwareengineeringdaily.com/2019/01/11/why-is-storage-on-kubernetes-is-so-hard/
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。