隨著深度學習演演算法在影象領域中的成功運用,學術界的目光重新回到神經網路上;而隨著 AlphaGo 在圍棋領域製造的大新聞,全科技界的目光都聚焦在“深度學習”、“神經網路”這些關鍵詞上。
與大眾的印象不完全一致的是,神經網路演演算法並不算是十分高深晦澀的演演算法;相對於機器學習中某一些數學味很強的演演算法來說,神經網路演演算法甚至可以算得上是“簡單粗暴”。
只是,在神經網路的訓練過程中,以及演演算法的實際運用中,存在著許多困難,和一些經驗,這些經驗是比較有技巧性的。
有道雲筆記不久前更新的檔案掃描功能中使用了神經網路演演算法。本文試圖以檔案掃描演演算法中所運用的神經網路演演算法為線索,聊一聊神經網路演演算法的原理,以及其在工程中的應用。
背景篇

首先介紹一下什麼是檔案掃描功能。檔案掃描功能希望能在使用者拍攝的照片中,識別出文件所在的區域,進行拉伸(比例還原),識別出其中的文字,最終得到一張乾凈的圖片或是一篇帶有格式的文字版筆記。實現這個功能需要以下這些步驟:
1. 識別檔案區域
將檔案從背景中找出來,確定檔案的四個角;
2. 拉伸檔案區域,還原寬高比
根據檔案四個角的坐標,根據透視原理,計算出檔案原始寬高比,並將檔案區域拉伸還原成矩形。這是所有步驟中唯一具有解析演演算法的步驟;
3. 色彩增強
根據檔案的型別,選擇不同的色彩增強方法,將檔案圖片的色彩變得乾凈清潔;
4. 佈局識別
理解檔案圖片的佈局,找出檔案的文字部分;
5. OCR
將圖片形式的“文字”識別成可編碼的文字;
6. 生成筆記
根據檔案圖片的佈局,從 OCR 的結果中生成帶有格式的筆記。

在上述這些步驟中,“拉伸檔案區域”和“生成筆記”是有解析演演算法或明確規則的,不需要機器學習處理。剩下的步驟中都含有機器學習演演算法。其中“檔案區域識別”和“OCR”這兩個步驟我們是採用深度神經網路演演算法來完成的。
之所以在這兩個步驟選擇深度神經網路演演算法,是考慮到其他演演算法很難滿足我們的需求:
· 場景複雜,淺層學習很難很好的學習推廣;
同時,深度神經網路的一些難點在這兩個步驟中相對不那麼困難。
· 屬於深度神經網路演演算法所擅長的影象和時序領域;
· 能夠獲取到大量的資料。能夠對這些資料進行明確的標註。
接下來的內容中,我們將展開講講“檔案區域識別”步驟中的神經網路演演算法。
演演算法篇
檔案區域識別中使用的神經網路演演算法主要是全摺積網路(FCN)[1]。在介紹 FCN 前,首先簡單介紹一下 FCN 的基礎,摺積神經網路(這裡假設讀者對人工神經網路有最基本的瞭解)。
摺積神經網路(CNN, Convolutional Neural Networks)
摺積神經網路(CNN)早在 1962 年就被提出[2],而目前最廣泛應用的結構大概是 LeCun 在 1998 年提出的[3]。
CNN 和普通神經網路一樣,由輸入、輸出層和若干隱層組成。CNN 的每一層並不是一維的,而是有(長, 寬, 通道數)三個維度,例如輸入層為一張 rgb 圖片,則其輸入層三個維度分別是(圖片高度, 圖片寬度, 3)。
與普通神經網路相比,CNN 有如下特點:
1. 第 n 層的某個節點並不和第 n-1 層的所有節點相關,只和它空間位置附近的(n-1層)節點相關;
2. 同一層中,所有節點共享權值;
3. 每隔若干層會有一個池化(pool)層,其功能是按比例縮小這一層的長和寬(通常是減半)。常用的 pool 方法有區域性極大值(Max)和區域性均值(Mean)兩種。
透過加入若干 pool 層,CNN 中隱層的長和寬不斷縮小。當長寬縮小到一定程度(通常是個位數)的時候,CNN 在頂部連線上一個傳統的全連線(Fully connected)神經網路,整個網路結構就搭建完成了。
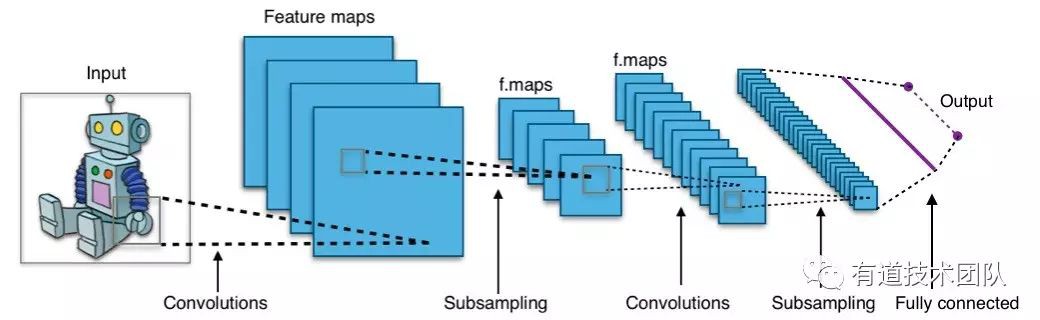
CNN 之所以能夠有效,在於它利用了影象中的一些約束。
特點 1 對應著影象的局域相關性(影象上右上角某點跟遠處左下角某點關係不大);特點 2 對應著影象的平移不變性(影象右上角的形狀,移動到左下角仍然是那個形狀);特點 3 對應著影象的放縮不變性(影象縮放後,資訊丟失的很少)。
這些約束的加入,就好比物理中”動量守恆定理“這類發現。守恆定理能讓物體的運動可預測,而約束的加入能讓識別過程變得可控,對訓練資料的需求降低,更不容易出現過擬合。
全摺積網路(FCN, Fully Convolutional Networks)
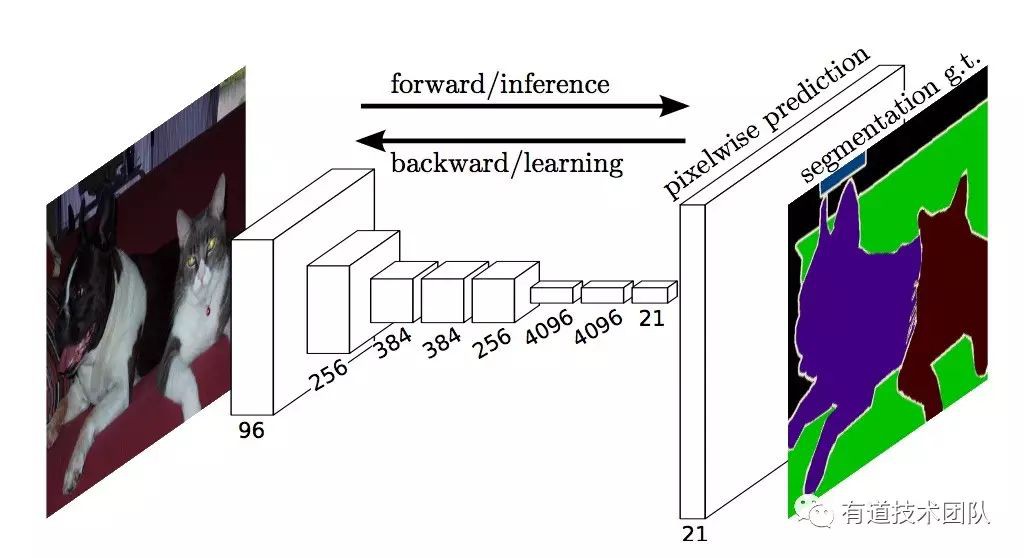
全摺積網路 (FCN) 是 CNN 基礎上發展起來的演演算法。與 CNN 不同,FCN 要解決這樣的問題:影象的識別標的不是影象級的標簽,而是畫素級的標簽。例如:
1. 影象分割需要將影象根據語意分割成若干類別,其中每一個畫素都對應著一個分類結果;
2. 邊緣檢測需要將影象中的邊緣部分和非邊緣部分分隔開來,其中每一個畫素都對應著“邊緣”或“非邊緣”(我們面對的就屬於這類問題)。
3. 影片分割將影象分割用在連續的影片影象中。
在 CNN 中,pool 層讓隱層的長寬縮小,而 FCN 面對的是完整長寬的標簽,如何處理這對矛盾呢?
一個辦法是不使用 pool 層,讓每一個隱層的長寬都等於完整的長寬。
這樣做的缺點是,一來計算量相當大,尤其是當運算進行到 CNN 的較高層,通道數達到幾百上千的時候;二來不使用 pool 層,摺積就始終是在局域進行,這樣識別的結果沒有利用到全域性資訊。
另一個辦法是轉置摺積(convolution transpose),可以理解為反向操作的 pool 層,或者上取樣層,將隱層透過插值放縮回原來的長寬。這正是 FCN 採用的辦法。
當然,由於 CNN 的最後一個隱層的長寬很小,基本上只有全域性資訊,如果只對該隱層進行上取樣,則區域性細節就都丟失了。
為此,FCN 會對 CNN 中間的幾個隱層進行同樣的上取樣,由於中間層放縮的程度較低,保留了較多的區域性細節,因而上取樣的結果也會包含較多的局域資訊。
最後,將幾個上取樣的結果綜合起來作為輸出,這樣就能比較好的平衡全域性和局域資訊。

整個 FCN 的結構如上圖所示。FCN 去掉了 CNN 在頂部連線的全連線層,在每個轉置摺積層之前都有一個分類器,將分類器的輸出上取樣(轉置摺積),然後相加。

上圖是我們實驗中真實產生的上取樣結果。可以看到,層級較低的隱層保留了很多圖片細節,而層級較高的隱層對全域性分佈理解的比較好。將二者綜合起來,得到了既包含全域性資訊,又沒有丟失局域資訊的結果。
轉置摺積(convolution transpose)
上文中出現的“轉置摺積”是怎樣實現的呢?顧名思義,轉置摺積也是一種摺積操作,只不過是將 CNN 中的摺積操作的 Input 和 Output 的大小反轉了過來。
https://github.com/vdumoulin/conv_arithmetic
以上專案中提供了一系列轉置摺積的圖示,不過我個人認為更符合原意的轉置摺積的圖示如下圖:
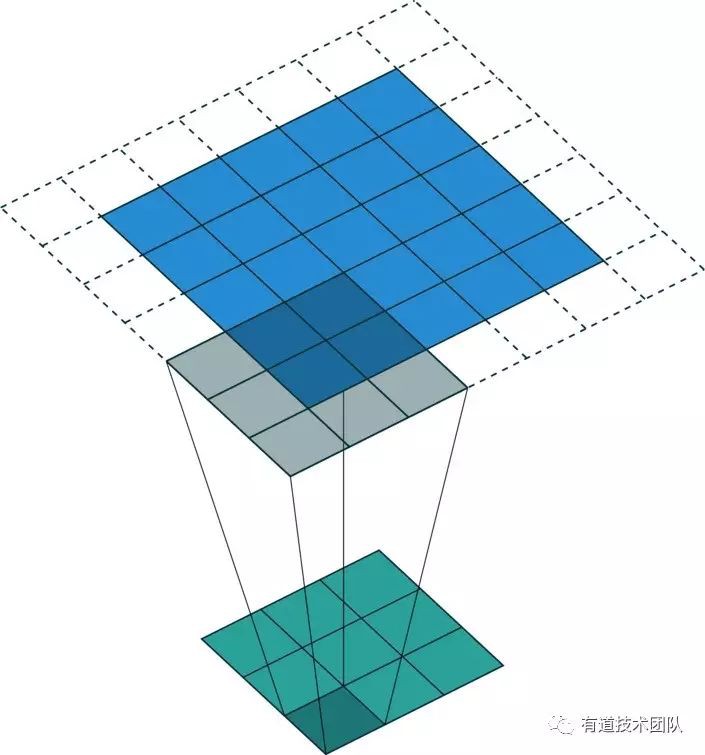
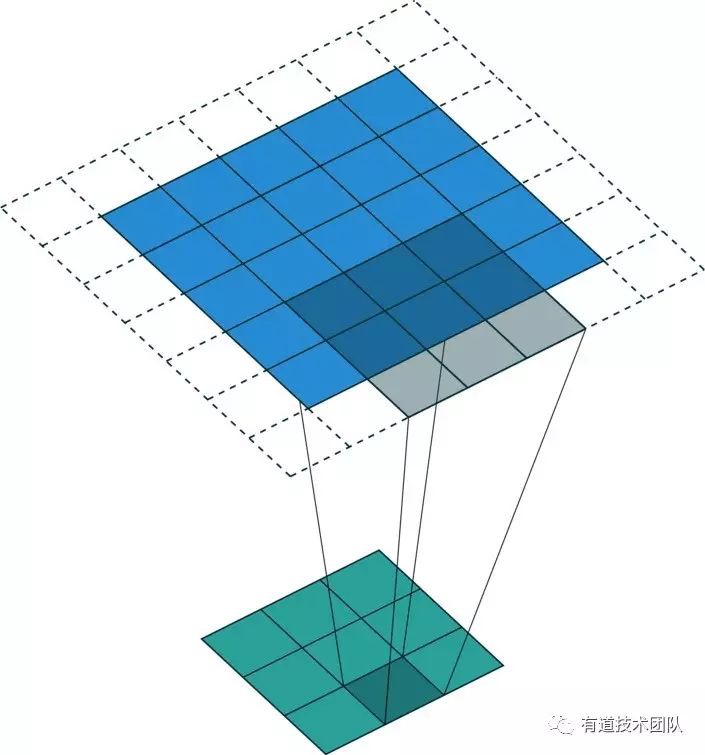
與 conv_arithmetric 提供的圖示對比,可以看出上圖只是摺積示意圖的上下翻轉。在實際運算中,Input 層的某個節點數值會(以摺積核為權重)加權相加到與該節點相關的每一個 Output 層節點上。
從維度上來看,如果記摺積核的高、寬為 H 和 W,Input 層的 channel 數為 C,Output 層的 channel 數為 O,那麼一次正向摺積的輸入節點數為 H * W * C,輸出節點數為 O;而一次轉置摺積運算的輸入節點數為 C ,輸出節點數為 H * W * O。
改進的 cross entropy 損失函式
在邊緣識別問題中,每一個畫素都對應著“邊緣-非邊緣”中的某一類。於是,我們可以認為每一個畫素都是一個訓練樣本。
這會帶來一個問題:通常圖片中的邊緣要遠少於非邊緣,於是兩類樣本的數量懸殊。在樣式識別問題中,類別不平衡會造成很多不可控的結果,是要極力避免的。
通常面對這種情況,我們會採用對少樣本類別進行重覆取樣(過取樣),或是基於原樣本的空間分佈產生人工資料。然而在本問題中,由於同一張圖中包含很多樣本,這兩種常用的方法都不能進行。該怎麼解決樣本數量懸殊問題呢?
2015 年 ICCV 上的一篇論文[4]提出了名為 HED 的邊緣識別模型,試著用改變損失函式(Loss Function)的定義來解決這個問題。我們的演演算法中也採用了這種方法。
首先我們概述一下 CNN 常用的 cross entropy 損失函式。在二分類問題裡,cross entropy 的定義如下:

這裡 l 為損失值,n 為樣本數,k 表示第幾個樣本,Q 表示標簽值,取值為 0 或者 1,p 為分類器計算出來的”該樣本屬於類別 1 “的機率,在 0 到 1 之間。
這個函式雖然看起來複雜,但如果對它取指數(L=exp(-l)),會發現這是全部樣本均預測正確的機率。比如樣本集的標簽值分別為 (1, 1, 0, 1, 1, 0, …),則:

這裡 L 是似然函式,也就是全部樣本均預測正確的機率。
HED 使用了加權的 cross entropy 函式。例如,當標簽 0 對應的樣本極少時,加權 cross entropy 函式定義為:
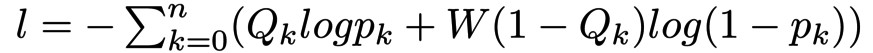
這裡 W 為權重,需要大於 1。不妨設 W = 2,此時考慮似然函式:

可見類別為 0 的樣本在似然函式中重覆出現了,比重因此而增加。透過這種辦法,我們雖然不能實際將少樣本類別的樣本數目擴大,卻透過修改損失函式達到了基本等價的效果。
資料篇
檔案區域識別中用到的神經網路演演算法就介紹到這裡了,接下來聊一聊我們為訓練這個神經網路所構建的資料集。
資料篩選
為了訓練神經網路模型,我們標註了樣本容量為五萬左右的資料集。然而這些資料集中存在大量的壞資料,需要對資料進行進一步篩選。
五萬左右的資料集,只憑人工來進行篩選成本太高了。好在根據網路的自由度等一些經驗判斷,我們的網路對資料集的大小要求尚沒有那麼高,資料集還算比較富足,可以允許一部分好的資料被錯篩掉。
基於這一前提,我們人工標註了一個小訓練集(500 張),訓練了一個 SVM 分類器來自動篩選資料。這個分類器只能判斷圖片中是否含有完整的檔案,且分類效果並不特別強。
不過,我們有選擇性的強調了分類器分類的準確率,而對其召回率要求不高。換而言之,這個分類器可以接受把含有檔案的圖片錯分成了不含檔案的圖片,但不能接受把不含檔案的圖片分進了含有檔案的圖片這一類中。
依靠這個分類器,我們將五萬左右的資料集篩選得到了一個九千左右的較小資料集。再加上人工篩選,最終剩下容量為八千左右的,質量有保證的資料集。
實現篇
在模型訓練中,我們使用 tensorflow 框架[5]進行模型訓練。我們的最終標的是在移動端(手機端)實現檔案區域識別功能,而移動端與桌面端存在著一些區別:
1. 移動端的運算能力全方位的弱於桌面端;
2. 頻寬和功耗端限制,決定了移動端的顯示卡尤其弱於桌面端的獨顯;
3. 移動端有 ios 和 Android 兩個陣營,它們對密集運算的最佳化 API 各不相同,程式碼很難通用;
4. 移動端對檔案體積敏感。
這些區別使得我們不能直接將模型移植到移動端,而需要對它們做一些最佳化,保證其執行效率。最佳化的思路大致有兩種:
1. 選擇合適的神經網路框架,盡可能用上晶片的加速技術;
2. 壓縮模型,在不損失精度的前提下減小模型的計算開銷和檔案體積。
神經網路框架的選擇
目前比較流行的神經網路框架包括 tensorflow, caffe[6], mxnet[7] 等,它們大多數都有相應的移動端框架。所以直接使用這些移動端框架是最方便的選擇。
例如我們使用 tensorflow 框架進行模型訓練,那麼直接使用移動端 tensorflow 框架,就能省去模型轉換的麻煩。
有的時候,我們可能不需要一個大而全的神經網路框架,或者對執行效率要求特別高。此時我們可以考慮一個底層一些的框架,在此基礎上實現自己的需求。
這方面的例子有 Eigen[8],一個常用的矩陣運算庫;NNPACK[9],效率很高的神經網路底層庫,等等。如果程式碼中已經集成了 OpenCV[10],也可以考慮用其中的運算 API。
如果對執行效率要求很高,也可以考慮使用移動端的異構計算框架,將除 CPU 以外的 GPU、DSP 的運算能力也加入進來。
這方面可以考慮的框架有 ios 端的 metal[11],跨平臺的 OpenGL[12] 和 Vulkan[13],Android 端的 renderscript[14]。

模型壓縮
模型壓縮最簡單的方法就是去調節網路模型中各個可調的超引數,這裡的超引數的例子有:網路總層數、每一層的 channel 數、每一個摺積的 kernel 寬度 等等。
在一開始訓練的時候,我們會選擇有一定冗餘的超引數去訓練,確保不會因為某個超引數太小而成為網路效果的瓶頸。
在模型壓縮的時候,則可以把這些冗餘“擠掉”,即在不明顯降低識別準確率的前提下,逐步嘗試調小某個超引數。
在調節的過程中,我們發現網路總層數對識別效果的影響較大;相對而言,每一層的 channel 數的減小對識別效果的影響不大。
除了簡單的調節超引數外,還有一些特別為移動端設計的模型結構,採用這些模型結構能顯著的壓縮模型。這方面的例子有 SVD Network[15], SqueezeNet[16], Mobilenets[17]等,這裡就不細說了。
最終效果
經過神經網路框架定製、模型壓縮後,我們的模型大小被壓縮到 1M 左右,在效能主流的手機(iphone 6, 小米 4 或配置更好的手機)上能達到 100ms 以內識別一張圖片的速度,且識別精度基本沒有受到影響。應該說移植是很成功的。
總結
在兩三年之前,神經網路演演算法在大家的眼裡只適用於運算能力極強的伺服器,似乎跟手機沒有什麼關聯。
然而在近兩三年,出現了一些新的趨勢:一是隨著神經網路演演算法的成熟,一部分學者將研究興趣放在了壓縮神經網路的計算開銷上,神經網路模型可以得到壓縮;二是手機晶片的運算能力飛速發展,尤其是 GPU,DSP 運算能力的發展。伴隨這一降一升,手機也能夠得著神經網路的運算需求了。
“基於神經網路的檔案掃描”功能得以實現,實在是踩在了無數前人的肩膀上完成的。從這個角度來說,我們這一代的研發人員是幸運的,能夠實現一些我們過去不敢想象的東西,未來還能實現更多我們今天不能想象的東西。
參考文獻
1. Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3431-3440).
2. Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology, 160(1), 106-154.
3. LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
4. Xie, S., & Tu, Z. (2015). Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1395-1403).
5. https://www.tensorflow.org/
6. http://caffe.berkeleyvision.org/
7. http://mxnet.io/
8. http://eigen.tuxfamily.org/index.php?title=Main_Page
9. https://github.com/Maratyszcza/NNPACK
10. http://opencv.org/
11. https://developer.apple.com/metal/
12. https://www.opengl.org/
13. https://www.khronos.org/vulkan/
14. https://developer.android.com/guide/topics/renderscript/compute.html
15. Denton, E. L., Zaremba, W., Bruna, J., LeCun, Y., & Fergus, R. (2014). Exploiting linear structure within convolutional networks for efficient evaluation. In Advances in Neural Information Processing Systems (pp. 1269-1277).
16. Iandola, F. N., Han, S., Moskewicz, M. W., Ashraf, K., Dally, W. J., & Keutzer, K. (2016). SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv preprint arXiv:1602.07360.
17. Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., … & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。


