作者丨黃澄楷
研究方向丨多媒體資訊檢索/內容理解
本文是發表在 MM18 上的一篇跨模態檢索文章,作者提出了一種採用綜合保持距離的自編碼器(CDPAE)的新穎方法,用以解決無監督的跨模態檢索任務。


之前的無監督方法大部分使用屬於相同物件的跨模態空間的成對錶示距離進行度量學習。但是,除了成對距離之外,作者還考慮了從跨媒體空間提取的異構表示距離,以及從屬於不同物件的單個媒體空間提取的齊次表示距離,從而達到了更高的檢索精度。
研究動機
雖然先前的無監督跨模態檢索方法已經有了不錯的表現,但是仍然有兩個問題叩待解決,第一,如何減少特徵中冗餘的噪聲的負面影響。

▲ 背景中的SIFT特徵會影響Cat影象的檢索
第二,如何直接使用不同物件的表示(representation)來表達它們之間的關係(relationship)。

即在大多數非監督方法中,不考慮虛線的關係。這兩個問題在無監督跨模態檢索的研究中涉及的較少。
研究方法
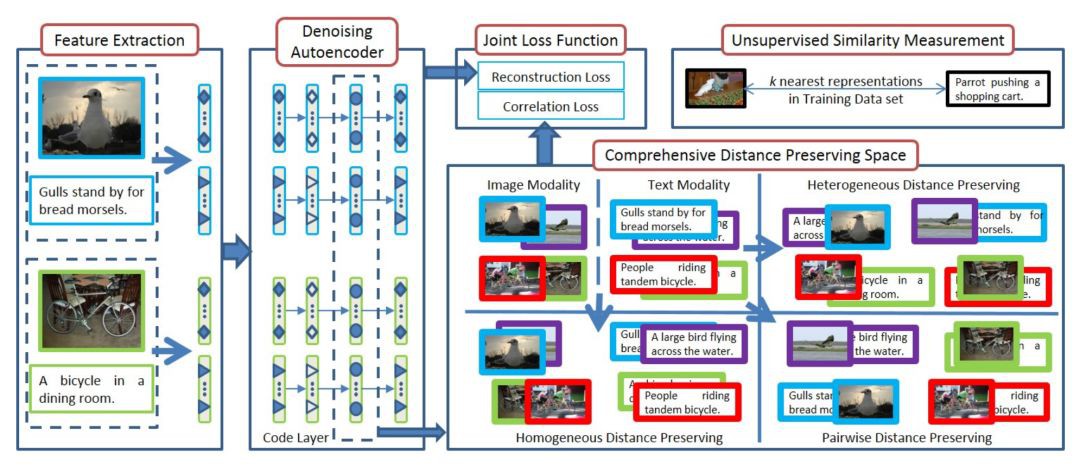
上圖就是作者提出的 CDPAE 的框架結構圖,總體上看,CDPAE 包含四個並行的去噪編碼器,並定義了綜合的保距公共空間,其中根據輸入保留三種距離,然後使用聯合損失函式將自編碼器的重構損失和相關損失結合起來。最後,還提出了一種無監督跨模態相似度的度量方法。
具體來看,CDPAE 包含四個部分:去噪編碼器、綜合保距空間、聯合損失函式和無監督跨模態相似度測量,由於資料集的限制,本文與大部分其他跨模態檢索任務一樣,只進行圖文互搜的實驗。接下來分別對每個部分進行介紹。
1. CDPAE 的第一部分由四個去噪編碼器組成,其中兩個提取影象相關的特徵,另外兩個與文字特徵相關,去噪的自編碼器負責相同的模態,它們共享相同的引數,因此相同模態的表示也具有相同的轉換。
在具體的訓練迭代中,從兩個物件中提取的兩種樣式之間的四種表示形式用作輸入。如:圖中海鷗圖、描述海鷗圖的文字、腳踏車圖、描述腳踏車的文字作為輸入。
在去噪自動編碼器中,將固定數量的輸入分量隨機設定為零,其餘的保持不變。該方法模擬了從輸入端去除冗餘噪聲的過程;因此,它減少了冗餘噪聲的負面影響。此外,歸零過程可以看作是一種資料擴充的過程,它加強了從不同模態中提取的表示中區域性結構之間的聯絡。
去噪自編碼器的重構損失定義為:
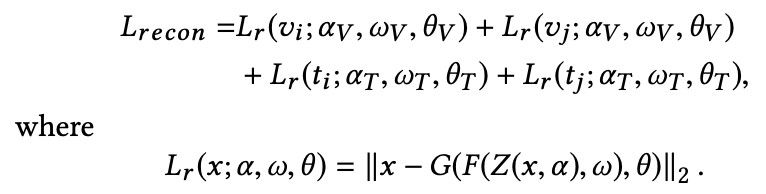
V={v} 代表的是影象的資料集,T={t} 代表的是對應的文字資料集,根據之前提到的輸入方法,使用自編碼器從提取兩組來自兩個物件對應的特徵(影象文字對特徵),(vi,ti)–>(海鷗圖的影象特徵和文字特徵)和 (vj,tj)–>(腳踏車的影象特徵和文字特徵),av,wv,θv 表達的是影象自編碼器的引數,at,wt,θt 代表的是文字自編碼器的引數,Z(*) 是隨機置零過程,F(*) 是編碼過程,G(*) 是解碼過程。
2. 第二部分是綜合保距空間的構造:CDPAE 使用餘弦距離來測量相同模態空間中的特徵相似性。測量的公式:

在綜合保距空間中有三種距離:成對距離、異質距離、齊次距離,分別給出定義:
a. 成對距離的損失:
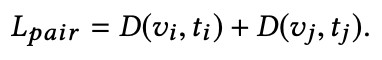
就是其他無監督跨模態檢索都考慮的距離。其中 D 為:

這個距離的作用是:成對的距離會導致公共空間,其中屬於相同物件的不同模態的表示會聚在一起(海鷗的影象文字聚在一起、腳踏車的影象文字聚在一起)。
b. 異質距離的損失:

反映了不同物件在不同模態中的表示之間的關係,這裡度量的時候限制它們與原始模態空間相對應的物件之間的距離一致。
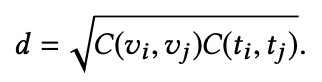
c. 齊次距離的損失:

齊次距離反映的是同一模態下來自不同物件的表示之間的關係,因為每次迭代中,都計算相同兩個物件之間的異質與齊次距離,所以設定它們的值相同。
所以綜合的保距空間如下:
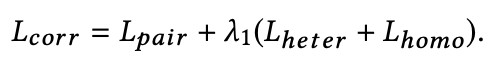
3. 然後又使用了一種聯合損失函式,同時計算去噪自編碼器的重構損失和綜合保距公共空間的相關損失:
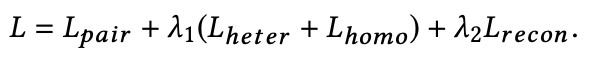
4. 最後作者又提出了一種新型的無監督跨模態相似度度量方法,在公共空間中,訓練資料集中變換後的特徵之間的距離通常會比測試資料中的距離更具有可信度。
所以講兩個特徵之間的相似性定義為基於 KNN 分類器的邊緣機率,該分類器用於對訓練樣本中的每個模態的表示進行分類,兩種表示的相似性可以定義為:

註意:這裡的 pi/qj 分別是影象模態/文字模態的 top k 近鄰樣本(這裡的 top k 近鄰樣本不區分模態)。同時,假設兩個表示之間的距離反映了它們屬於同一語意範疇的可能性,因此,如果訓練資料集中的兩種表示形式成對對應的話,它的可能性就是 1,否則:

D 採用的是餘弦相似距離,取值範圍是 0~1,距離越小,對應的表示屬於同一類別可能性就越大,進一步,去定義一個測試樣本表示與其 k 個最近的訓練資料屬於同一個類別的條件機率為:
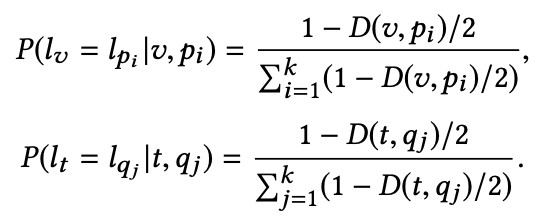
實驗結果
作者在 Wikipedia,NUS-WIDE-10k,Pascal Sentence 以及 XMedia 資料集上進行了實驗:

圖表顯示傳回的是 MAP@50 的結果,加 * 的是有監督的方法,三角形代表的是半監督的方法,剩下的都是無監督方法。另外,作者還用 t-SNE 可視化了綜合保距空間的資料分佈:
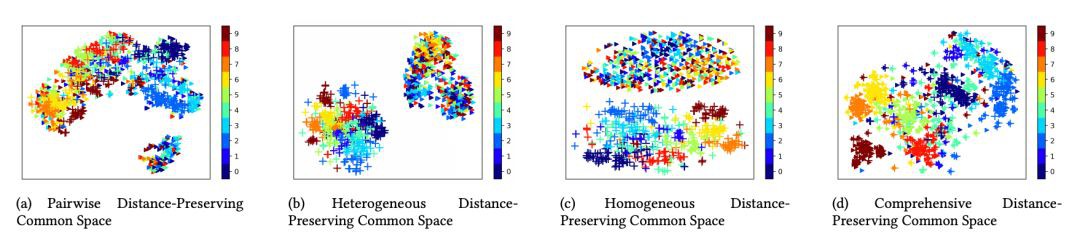
上圖顯示的是 Wikipedia-Multiple 資料集中不同公共空間的 t-SNE 視覺化。可以看出,在成對保持距離的公共空間中,影象和文字的表徵往往是混合的。然而,來自相同類別的表示並沒有得到令人滿意的聚類,這就是傳統無監督跨模態檢索只使用的距離。
在異質的保距離公共空間中,影象和文字的表徵就有明顯的區別,這是因為模內距離遠小於模間距離。此外,在相同距離保持的公共空間中,來自相同模態的表示按其各自的類別聚在一起。
在綜合的保距離公共空間中,影象和文字的變換表示達到了最佳的方式分佈。大量具有相同語意標簽的表示形式被聚集在一起,而與它們的模態型別無關。這表明,綜合保距離公共空間具有其他三種保距離公共空間的優點,對於跨模態檢索任務是非常有效的。
結論與點評
與之前的無監督跨模態檢索方法相比,本文最大的亮點在於引入了不同物件在不同模態間的距離以及不同物件在相同模態間的距離,就是文中提出的學習到的一個綜合保距空間,這是之前大部分跨模態檢索方法沒有考慮到的。
然後利用聯合損失函式將距離的損失函式與自編碼器重構損失一起訓練,達到一個很好的效果,與目前所有的無監督跨模態檢索方法相比,平均效能高出 12.5%,與半監督與有監督方法相比,在多個資料集上表現也有前三的水平。
