
Kubernetes已在容器編排之戰中取勝,未來很可能會成為“多雲”之上的標準層,進而為分散式系統的分發和執行帶來根本性的改變,而其自身則會慢慢變得像Linux Kernel一樣,成為一種系統底層的支撐,不再引人註目。
原文的標題是The Gravity of Kuberrnetes,但是從內容上看,更像是近些年流行的“XXX is dead. Long live XXX.”的風格,所以在翻譯標題的時候我們惡搞了一下。
-
透過Kubernetes,分散式系統工具將擁有網路效應。每當人們為Kubernetes製作出的新的工具,都會讓所有其它工具更完善。因此,這進一步鞏固了Kubernetes的標準地位。
-
雲提供商並非可替換的商品。不同的雲提供的服務會變得越來越獨特和不同。如果可以訪問不同的雲提供商提供的不同服務,那麼企業將因此受益。
-
當多節點應用與單節點應用一樣可靠時,我們將看到定價模型的變化。
-
這就是為什麼我會被Kubernetes洗腦的原因。它是跨越異構系統的一個標準層。
-
將來,我們會像討論編譯器和作業系統核心一樣討論Kubernetes。 Kubernetes將會是低層級的管路系統,而不在普通應用開發人員的視野之內。
Kubernetes已成為部署分散式應用的標準方式。
在不遠的將來,任何新成立的網際網路公司都將用到Kubernetes,無論其是否意識到這點。許多舊應用也正在遷移到Kubernetes。
在Kubernetes之前,特定的分散式系統平臺還沒有一個標準。正如Linux是針對單個節點的標準的伺服器側作業系統那樣,Kubernetes已成為編排應用節點的標準方式。
透過Kubernetes,分散式系統工具將擁有網路效應。每當人們為Kubernetes製作出新的工具,都會讓所有其它工具更完善。因此,這進一步鞏固了Kubernetes的標準地位。

谷歌、微軟、亞馬遜和IBM都有自己的Kubernetes即服務產品,這讓我們在大型雲提供商之間切換基礎設施變得更加簡單。我們將很有可能看到Digital Ocean、Heroku和其它長尾型雲提供商開始提供受管理的和託管Kubernetes服務。

標準讓開發者可以對軟體的執行方式抱有一定的預期。如果一個開發者為某個標準化平臺構建了某個東西,他可以評估出該軟體的標的市場總規模。
如果你用JavaScript寫了一個程式,你會知道它將會在所有人的瀏覽器中執行。如果你給iOS創作了一個遊戲,你會知道每個有iPhone的人都可以下載它。如果你構建了一個工具來分析.NET中的垃圾收集,你會知道大量的Windows開發者會遇到記憶體問題,所以他們會購買你的軟體。
標準化的專有平臺可以給平臺提供者創造大量的利潤。1995年,Windows這個很好的平臺讓微軟能夠以100美元的價格售出一個只是紙盒子裝著的光碟。2018年,iPhone這個很好的平臺讓蘋果能夠從平臺所有的應用銷售額中拿走30%。
比如,你的iPhone應用無法在Kindle Fire上執行。我不能在Facebook Messenger(臉書信使)上使用你的Snapchat增強現實貼紙。我最喜歡的數字音訊工作站[1]只能在Windows上使用,所以我不得不使用Windows電腦來製作音樂。
當開發者們見到這種分裂時,他們會抱怨。他們會聯想到貪婪的資本家,這些資本家為了賺錢,不惜犧牲軟體的質量。開發者們會想:“為什麼人們不能和諧共處?”為什麼我們不能讓所有東西開放和免費?
開發者們還會想:“我們不需要專有標準。我們可以擁有開放標準。

Apache的增長,Apache是LAMP(Linux、 Apache、MySQL和PHP)堆疊的一部分
Linux就曾發生過這樣的事。現在,大多數新的服務側應用都在使用Linux。但曾經有一段時間,人們對此有爭議。見上圖的左側遠端部分。
最近,我們還看到了一個更新的開放標準:Docker。Docker給了我們一個開放、標準化的打包、部署和分佈單個節點的方法。這極其有價值!但在Docker解決的所有大問題之中,有個新的問題非常突出,那就是我們應該如何將這些節點編排到一起?
畢竟,你的應用肯定不只是單個節點。你知道自己希望部署一個Docker容器,但是容器應該如何相互通訊呢?你如何向上擴充套件容器實體呢?你如何在容器實體之間路由流量呢?
在Docker流行之後,一大批開源專案和專有平臺紛紛出現,以解決容器編排的問題。
Mesos、Docker Swarm和Kubernetes均提供了不同的抽象來管理容器。Amazon ECS提供了一個專有的受管的服務,它可以為AWS使用者提供Docker容器的安裝和擴充套件服務。
有些開發者並未採用任何編排平臺,而是使用BASH、Puppet、Chef和其它工具來為他們的部署編寫指令碼。
無論一個開發者是否使用編排平臺或者指令碼來部署容器,Docker都可以加快開發,並且讓開發者和運營之間更加和諧。

隨著愈來愈多的開發者使用Docker來部署容器,編排平臺的重要性日益突出。容器對於分散式系統的重要性就如同物件對於面向物件程式的重要性那樣[2]。所有人都希望使用容器平臺,但是眾多平臺之間存在著競爭,很難看出哪個平臺會最終勝出,所以這可能會是持續十多年的競爭,就如iOS和安卓的競爭那樣。
這樣的競爭正在製造分裂。這並不是因為流行的編排框架是專有的(Swarm、Kubernetes和Mesos都是開源的),而是因為每個容器編排社群都已經在自己的系統上投入了太多資金。
所以,從2013到2016年,Docker使用者一直有種隱憂。選擇容器編排框架就像一次豪賭,如果你選擇了錯誤的編排系統,這就好像你開了一家影像店,卻選擇了高畫質DVD,而不是藍光光碟[3]。

集裝箱(container)船傾覆的圖片從不過時。圖片來源:Huffington的帖子
容器編排的戰爭給人感覺就像是一場贏家贏得一切的戰爭。
正如在所有戰爭中那樣,總是有一層霧,讓我們很難看透彼此。在我報道容器編排之戰時,我曾用一條條播客記錄我和容器編排專家的談話,其中,我會問到這樣的問題,“那麼,哪一個容器編排系統會贏?”
我一直這麼做,直到某個我十分景仰之人告訴我問這樣的問題一點也沒有意思,還不如評估一下不同編排商之間的技術權衡。
迴首過去,我後悔自己被不同容器編排商之間的戰爭的故事所吸引。
當有關容器編排商的辯論如火如荼時,甚至是我這樣的記者也被這樣的情緒激發,並且認為這將是一場與派系鬥爭有關的故事時,那些最聰明的人大多數卻正在進行著平靜和科學的談論。
容器編排之戰並非是一場派系鬥爭,而更多的是觀點和開發者工程學之間的差異。

好吧,或許容器編排之戰並不只是觀點之間的差異。因為這個領域將會創造大量財富。我們現在談論的是與數十億市值的老組織如銀行、電信公司和保險公司之間的合同,這些組織正在逐步向雲遷移。
如果你正在幫助電信公司遷移到正確的平臺,那麼你的業務會很好。但如果你擁護了錯誤的平臺,最終你只會得到一倉庫的高畫質DVD。
衝突最嚴重的時間大約是2016年底,那時有關於Docker可能出現分歧的傳言,原因是因為Docker公司想改變Docker標準,以更好地適配其容器編排系統Docker Swarm[4]。但即使在那時,做一個樂觀者仍然是明智的。
具有毀滅性的創新會帶來痛苦,但它是一個進步的標誌。在爭取容器編排統治地位的鬥爭中,出現了許許多多的毀滅性創新。
但在2016底迷霧消散之後,Kubernetes成了明顯的獲勝者。
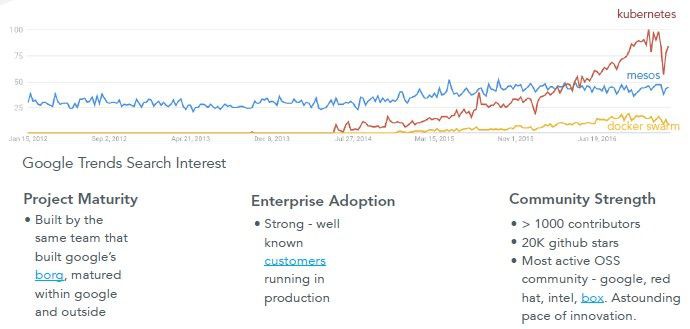
今天,隨著Kubernetes成為保險的選擇,CIO們對在企業中採用容器編排感到更安全了,這也讓廠商更願意投入到Kubernetes專用的工具中,並且把這些工具銷售給這些CIO。
-
開源開發者正在朝同樣的方向前進,並且為他們能構建的東西感到興奮。
-
大公司(無論是新還是老)都在逐漸採用Kubernetes。
-
大型雲提供商也準備好迎接低成本的Kubernetes即服務。
-
監控、日誌記錄、安全和合規軟體廠商也極為激動,因為他們能更加容易地預測自己要整合的底層軟體堆疊了。
今天,盈利最多的專有後端開發者基礎設施提供商就是亞馬遜AWS雲服務。開發者並不憎恨AWS,因為AWS是創新和具備使能性的,並且便宜。如果你在AWS花了很多錢,那說明你的生意很好。
透過AWS,開發者不會感到90年代時的主導專有平臺所給人的那種被鎖定的感覺。但仍然有一些鎖定感。一旦你深深地紮根於AWS的生態系統中,並使用如DynamoDB、Amazon Elastic Container Service(彈性容器服務)、或Amazon Kinesis服務時,你會發現你很難再脫離亞馬遜。
然而,由於Kubernetes為基礎設施創造的是一個開放、共有的層,所以理論上,將你的Kubernetes叢集從一個雲提供商處”遷移到“另一個提供商那裡是可行的。
如果你決定遷移你的應用,你需要重寫應用的部分元件來停止使用亞馬遜特定的服務(如亞馬遜S3)。例如,如果你想要一個可以在任何雲上執行的S3替代品,你可以配置一個帶Rook[5]的Kubernetes叢集,並使用與你在S3上使用的相同API 來儲存物件到Rook上。
這是一個很好的選項,但是我還從未聽說過誰真正地將他們的應用從雲中遷走,除了Dropbox[6]之外,但他們的遷移是如此宏大,以至於耗費了2年半的時間[7]。
當然,除了Dropbox之外,肯定還有其他人也在亞馬遜S3上投入了很多錢,雖然他們也想創造自己的物件儲存,但是遷移會非常費力。

Kubernetes可以被用於遷移應用,但更可能會用於在不同的雲之中提供相似的操作層
在不遠的將來,Kubernetes或許不會成為一個廣泛用於應用遷移的工具。更可能的情況是Kubernetes將會成為一個無所不在的控制平面,企業可以在多個雲上使用它。
NodeJS便是一個有用的類比。為什麼人們喜歡NodeJS的伺服器側應用?這並不一定是因為NodeJS是最快的web伺服器,而是因為人們喜歡在客戶端和伺服器上使用相同的語言。NodeJS可以讓你在客戶端和伺服器節點切換,而無需切換語言,同樣,Kubernetes也能讓你在不同的雲之間切換,而無需改變運營方式。
在每個雲上,你都會有一些定製的應用程式碼,它們由Kubernetes執行,並且與那個雲提供的受管服務進行互動。
企業希望多雲化,部分是因為容災的考慮,但還因為訪問不同雲上的受管服務有實際的好處。
一個新出現的樣式是將基礎設施分佈於AWS(用於使用者流量)和Google Cloud(用於資料工程)上。Thumbtack[8]公司正在使用此樣式:
在Thumbtack,位於AWS的生產基礎設施負責處理使用者請求。事務日誌將從AWS推送到Google Cloud,併在那裡進行資料工程。在Google Cloud上,事務記錄在Cloud PubSub中排隊。Cloud PubSub是一個資訊佇列服務。這些事務會從佇列裡被抽出,並儲存在BigQuery中,BigQuery是一個儲存和查詢大量資料的系統。
BigQuery充當編排機器學習任務時的資料池,以便人們從中抽取資料。這些機器學習任務是在Cloud Dataproc中執行的,Cloud Dataproc是一個執行Apache Spark的服務。在Google Cloud上訓練好一個模型之後,這個模型會被部署到AWS側,然後處理使用者流量。在Google Cloud側,這些不同的受管服務的編排是由Apache Airflow完成的。Apache Airflow是一個開源工具。Thumbtack在Google Cloud上管理自己時,需要Apache Airflow。
今天,Thumbtack用AWS來處理使用者請求,並用Google Cloud來進行PubSub中的資料工程和排隊。Thumbtack在谷歌中訓練其機器學習模型,並將它們部署到AWS中。
這就是今天我們常見的現象。Thumbtack最終或許還會將Google Cloud用於面向使用者的服務。

越來越多的公司將逐漸遷移至多個雲,而且它們當中的某些公司會在每個雲上管理獨立的Kubernetes叢集。
你可能在谷歌上有一個GKE Kubernetes叢集來編排BigQuery、Cloud PubSub和Google Cloud ML之間的負載,而且你可能會有一個Amazon EKS叢集來編排DynamoDB、 Amazon Aurora和你的生產NodeJS應用之間的負載。
雲提供商並非可替換的商品。不同的雲提供的服務會變得越來越獨特和不同。如果可以訪問不同的雲提供商提供的不同服務,那麼企業將因此受益。
Google BigQuery 等 AWS Redshift服務十分流行,因為它們給了你強大、可擴充套件和多節點的工具,而且API還簡單。開發者經常選擇這些受管服務,因為它們是如此好用。
針對單個節點的付費工具並不常見。我不需要給NodeJS、React或Ruby on Rails付費。
針對單個節點的工具比針對分散式系統的工具用起來更容易。相比於在我的筆記本上執行Ruby on Rails應用來說,在許多伺服器上部署Hadoop難多了。然而,有了Kubernetes後,這一切都將改變。
如果你正在使用Kubernetes,你可以使用一個名叫Helm的分散式系統包管理器。它就好比是用於Kubernetes應用的npm。如果你正在使用Kubernetes,無論你使用的是哪個雲提供商,你都可以用Helm來輕鬆安裝一個複雜的多節點應用。
Helm幫助你管理Kubernetes應用。Helm Charts幫助你定義、安裝和升級Kubernetes應用,無論它們有多複雜。Charts很容易建立、進行版本控制、共享和釋出,所以請開始使用Helm吧,停止複製-貼上的瘋狂舉動。
一個用於分散式系統的包管理器。不可思議!讓我們看看我們能安裝的東西。

未列出的還有WordPress、Jenkins和Kafka
分散式系統配置很難,不信就去問問配置過Kafka叢集的人。Helm將使安裝Kafka像在你的MacBook上安裝新版Photoshop那樣簡單。 而且你可以在任何雲上這麼做。
在Helm之前,最接近分散式系統軟體包管理器(就我所知道的)的東西是AWS[9]或Azure[10]或Google Cloud Launcher[11]上的應用市場。在這裡,我們再次看到了專有軟體如何導致分裂。在Helm之前,沒有任何一個標準的、與平臺無關的一鍵安裝Kafka的方法。
你可以在AWS、Google或Azure上找到一鍵安裝Kafka的方法。 但是,這些安裝中的每個都必須獨立編寫,以供每個特定的雲提供商使用。 而要在Digital Ocean上安裝Kafka,則需要遵循這個10步教程[12]。
Helm是一個在任何Kubernetes實體上分佈多節點軟體的跨平臺系統。 你可以在任何雲提供商那裡或你自己的硬體上使用已安裝有Helm的應用。 你可以輕鬆安裝Apache Spark或Cassandra系統。眾所周知,它們都是難以設定和操作的。
Helm是Kubernetes的包管理器,但它看起來也像是Kubernetes應用商店的雛形。 有了應用商店,你就可以出售用於Kubernetes的軟體。
你可以銷售Cloudera Hadoop,Databricks Spark和Confluent Kafka等分散式系統平臺的企業版。 或者難以安裝的Prometheus等新型監控系統和Cassandra等多節點資料庫。
也許你甚至可以銷售像Zendesk這樣的更高階的消費級軟體。
自主託管Zendesk的想法聽起來很瘋狂,但是有人的確可以構建它,並以專有二進位制檔案的形式出售,以固定費用而不是訂閱進行收費。 如果我向你出售價值99美元的Zendesk-for-Kubernetes,並且你可以在AWS上的Kubernetes叢集上輕鬆執行它,那麼你將在工單軟體上節省大量支援費用。
企業經常執行自己的WordPress來管理公司的部落格。 Zendesk的軟體比WordPress更複雜嗎? 我不這麼認為,但比起管理自己的部落格軟體,企業更害怕管理自己的Help Desk軟體。
我經營了一家非常小的公司,但我訂閱了很多不同的軟體即服務工具。 包括一個昂貴的WordPress主機,一個用於廣告銷售的昂貴的CRM軟體,和用於通訊簡報的MailChimp。 我支付這些服務是因為它們超級可靠和安全,而且它們也是複雜的多節點應用。 我不想在自己的機房裡執行它們。我也不想自己管理它們。 當我的簡報傳送失敗時,我不想自己排除技術故障。 我不想執行太多的軟體[13]。
我在單機軟體上的開銷往往要便宜得多,因為我不需要把它們作為服務購買。 我用來寫音樂的軟體有一次性的固定成本。 Photoshop有一次性固定成本。 我支付電費來執行我的電腦,但除此之外,我不需要持續的資本支出才能執行Photoshop。
當多節點應用與單節點應用一樣可靠時,我們將看到定價模型的變化。
也許有一天我可以購買Zendesk-for-Kubernetes。 Zendesk-for-Kubernetes將會給我提供我需要的所有東西——它將啟動一個電子郵件伺服器,它會給我一個網路前端來管理工單。 如果出現任何問題,我可以在需要支援時支付費用。

Zendesk是一個非常棒的服務,但如果它有一個固定的定價樣式,那將會更好。
藉助Kubernetes,部署和管理分散式應用程式變得更加容易。 藉助Helm,將這些應用程式分發給其他使用者變得更加容易。 但是開發分散式系統還是相當困難的。
這是Brendan Burns最近所作的一篇CloudNative Con / KubeCon主題演講的焦點,那個演講的題目為“構建新工具、樣式和範例來讓分散式系統開發更加大眾化的工作實在太難了[14]”。

Brendan在發言中提出了一個名為Metaparticle的專案。 Metaparticle是雲原生開發的標準庫,其標的是實現分散式系統的大眾化。 Brendan在對Metaparticle的介紹[15]中寫道:
雲原生開發是定製且複雜的,而且僅限於少數專家開發人員。 Metaparticle透過在熟悉的程式語言中引入一系列實用程式來改變這種狀況,這些實用程式符合開發人員當前的處境,並使他們能夠使用熟悉的語言開始開發雲原生系統。
Metaparticle建立在Kubernetes原語的基礎上,而且它使分散式協調更容易。 Metaparticle提供獨立於語言的模組,用於鎖定和主選舉,並把這些模組作為熟悉的程式語言中易於使用的抽象。
經過幾十年的分散式系統研究和應用,我們如何構建這些系統的樣式已經顯現。 我們需要一種方法來鎖定一個變數,這樣兩個節點便不能以非確定性的方式寫入該變數。 我們需要一種方法來做主選舉,以便在主節點死亡時,其他節點可以選擇一個新節點來編排系統。
今天,我們使用etcd和ZooKeeper這樣的工具來幫助我們進行主選舉和鎖定,而這些工具都有接入成本。
Brendan用ZooKeeper的例子來說明這一點。Hadoop和Kafka都使用ZooKeeper來做主選舉。 你需要花費大量的時間和精力來學習如何操作ZooKeeper。 在構建Hadoop和Kafka的過程中,這些專案的創始工程師設計的系統可以與ZooKeeper協作,共同來維護一個主節點。
如果我正在編寫一個系統來執行分散式MapReduce,我希望不考慮節點故障和競爭條件。 Brendan的想法是將這些問題推到一個標準的庫中,從而讓下一個開發人員為多節點應用程式提出新想法更加容易。
重要的元點:使用Metaparticle的前提是使用Kubernetes。 Metaparticle是一個語言層級的抽象,它是建立在對底層(分散式)作業系統的假設之上的。這再一次使我們回到了標準這一話題。 如果每個人都在同一個分散式作業系統上,我們可以對我們專案的下游使用者做出更大的假設。
這就是為什麼我會被Kubernetes洗腦的原因。 它是跨越異構系統的一個標準層。
功能即服務(通常稱為“無伺服器”功能)是一種功能強大且價格低廉的抽象,開發人員可以與Kubernetes一同使用它,在Kubernetes之上使用它,或者在某些情況下,單獨使用它。
讓我們快速回顧無伺服器應用程式的現狀,然後考慮無伺服器和Kubernetes之間的關係。
功能即服務旨在部署、執行和擴充套件開發人員的單個呼叫。 在你呼叫無伺服器功能之前,你的功能並沒有在任何地方執行 – 所以你並未使用任何資源,除了儲存原始程式碼的資料庫以外。 當你把一個功能作為服務呼叫時,你的叢集將負責排程和執行該功能。
你不必考慮啟動一臺新機器並監控該機器,或者在機器閑置時停機。 你只需告訴叢集你想要執行一個功能,然後叢集將執行它並傳回結果。
在部署無伺服器功能時,功能程式碼實際上並未被部署。 你的程式碼將以純文字形式儲存於資料庫中。 當你呼叫這個功能時,你的程式碼將從資料庫入口中取出,載入到一個Docker容器中並執行。

來自https://medium.com/openwhisk/uncovering-themagic-how-serverless-platforms-really-work-3cb127b05f71的圖表
AWS Lambda在2014年開創了“功能即服務[17]”的理念。 從那以後,開發人員一直在思考各種用例。 有關開發人員如何使用無伺服器的完整串列,請參見CNCF無伺服器工作組建立的共享Google檔案(本文釋出時檔案為34頁)[18]。
從我在《軟體工程日報》上的交談中來看,這些作為服務的功能至少有兩個明顯的應用例子:

為了建立一個功能即服務(FaaS)平臺,雲提供商提供了一個名為呼叫者(invokers)的Docker容器叢集。 這些呼叫者等待得到調配給他們的大塊程式碼。 當你要求你的程式碼執行的時候,你必須等待一段時間用於將程式碼載入到呼叫者並執行。 這個等待便是“冷啟動”的問題。
冷啟動問題是你決定在FaaS上執行部分應用時必須做的折衷之一。 你不需為沒有進行任何工作的伺服器的執行時間付費 – 但是當你想呼叫功能時,你必須等待程式碼被調配給一個呼叫者。
在AWS上,會為AWS Lambda的請求指定呼叫者。 在Microsoft Azure上,會為Azure Functions請求指定呼叫者。 在Google Cloud上,會為Google Cloud Functions保留呼叫者。
對於大多數開發人員來說,使用AWS、Microsoft、Google或IBM的“功能即服務”平臺都可以。 因為成本低,冷啟動問題對於大多數應用來說不成問題。 但是一些開發者會想要更低的成本。 或者他們可能希望編寫自己的排程器,該排程器會定義如何將程式碼排程到呼叫者容器上。 這些開發人員可以推出自己的無伺服器平臺。
像Kubeless這樣的開源FaaS專案可以讓你在Kubernetes之上配置你自己的無伺服器叢集。 你可以定義自己的呼叫者池。 你可以確定如何按照計劃排程容器。 你可以決定如何解決你的叢集的冷啟動問題。
Kubernetes的開源FaaS只是一種資源排程器。 它們只是Kubernetes之上的其他自定義排程器的預覽。 開發人員總是在構建新的排程器,以便在這些排程器之上構建更高效的服務。
那麼,在Kubernetes之上還有哪些其他型別的排程器? 那麼,正如他們所說,未來已經到來,但這些排程器只能作為一個AWS受管服務被提供。
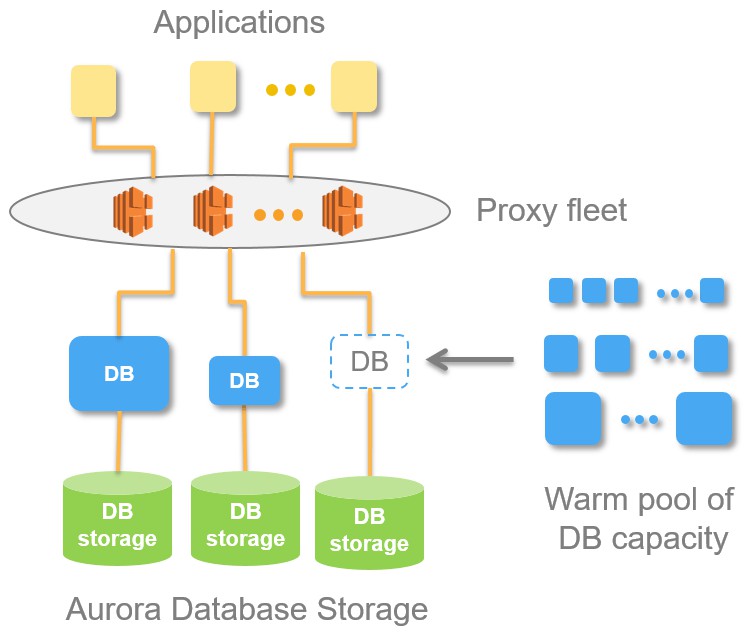
AWS有一項名為Amazon Aurora Serverless的新服務,它是一種自動擴充套件儲存和計算的資料庫。 來自Jeff Barr關於AWS Serverless Aurora的帖子[20]:
當建立Aurora資料庫實體時,你可以選擇所需的實體大小,並可以選擇使用讀副本提高讀取吞吐量。 如果你的處理需求或查詢速率發生變化,你可以選擇修改實體大小或根據需要更改讀副本的數量。 這個模型在工作負載可預測、並且請求速率和處理需求在一定範圍內的環境下執行得非常好。
在某些情況下,工作負載可能是間歇性的和/或不可預知的,並且可能每天或每週只能出現持續幾分鐘或幾小時的突發請求。 閃電銷售、不頻繁的或一次性的事件、線上遊戲、報告工作負載(小時或每天),開發/測試和全新的應用都符合該條件。 做出適當的容量規劃可能需要做很多工作;穩定地付費可能是不明智的。
由於儲存和處理是分開的,因此可以將規模一直縮小到零並僅支付儲存費用。 我覺得這真的很好,而且我期望它可以帶來新型的瞬時應用程式的出現。 擴充套件只需要幾秒鐘,並基於一池子“熱”資源之上進行構建,這些資源急切地渴望滿足你的要求。
AWS可以構建這樣的東西,我們並不感到驚訝,但是很難想象它會成為一個開源專案——直到Kubernetes出現。任何開發人員都可以在Kubernetes之上構建的這類系統。
如果你想在Kubernetes之上構建自己的無伺服器資料庫,則需要解決一些排程問題。 網路、儲存、日誌記錄、緩衝和快取需要不同的資源層級。 對於每個不同的資源層,你需要定義資源如何按照需求進行擴充套件和縮減。
就像Kubeless為功能程式碼的一小部分提供排程器一樣,我們可能會看到其他自定義排程器被人們用作更大應用的構建塊。
一旦你真正建立你的無伺服器資料庫,也許你可以把它賣到Helm 應用程式商店,一次性購買它只需要99美元。
我希望,透過一些Kubernetes的歷史和對未來的猜測,你能享受這次旅程。
2018年已經開始,這些將是我們今年想要探索的一些領域:
-
人們如何管理在Kubernetes上機器學習模型的部署? 我們和Matt Zeiler一起做了一個展示[21],他討論了這個問題,聽起來很複雜。
-
Kubernetes是否用於無人駕駛汽車? 如果是這樣,你是否部署了一個叢集來管理整個汽車?
-
Kubernetes 物聯網部署是什麼樣的? 在具有間歇性網路連線的一組裝置上執行Kubernetes是否有意義?
-
用Kubernetes構建的新的基礎設施產品和開發工具有哪些? 什麼是新的商業機會?
Kubernetes是構建現代應用後端的絕佳工具——但它仍然只是一個工具。
如果Kubernetes完成其使命,它最終會消失,成為背景。 將來,我們會像討論編譯器和作業系統核心一樣討論Kubernetes。Kubernetes將會是低層級的管路系統,而不在普通應用開發人員的視野之內。
對但在那成為現實之前,我們仍會對Kubernetes繼續報道。
-
https://www.image-line.com/flstudio/
-
https://youtu.be/gCQfFXSHSxw?t=611
-
https://en.wikipedia.org/wiki/High-definition_optical_disc_format_war
-
https://softwareengineeringdaily.com/2016/10/03/docker-fork-with-alex-williams-and-joab-jackson/
-
https://rook.io
-
https://softwareengineeringdaily.com/2016/05/17/dropboxs-magic-pocket-james-cowling/
-
https://www.wired.com/2016/03/epic-story-dropboxs-exodus-amazon-cloud-empire/
-
https://softwareengineeringdaily.com/2017/11/28/thumbtack-infrastructure-with-nate-kupp/
-
https://aws.amazon.com/marketplace
-
https://aws.amazon.com/marketplace
-
https://cloud.google.com/launcher/
-
https://www.digitalocean.com/community/tutorials/how-to-install-apache-kafka-on-ubuntu-14-04
-
https://softwareengineeringdaily.com/2017/11/20/run-less-software-with-rich-archbold/
-
https://www.youtube.com/watch?v=gCQfFXSHSxw
-
https://metaparticle.io/posts/welcome-to-metaparticle/
-
https://www.softwaredaily.com/#/post/5a251d5f0cbcbe0004c932e1
-
https://aws.amazon.com/cn/blogs/aws/run-code-cloud/
-
https://docs.google.com/document/d/1UjW8bt5O8QBgQRILJVKZJej_IuNnxl20AJu9wA8wcdI/edit#heading=h.yiaul8is1ki
-
https://softwareengineeringdaily.com/2017/08/04/serverless-startup-with-yan-cui/
-
https://aws.amazon.com/cn/blogs/aws/in-the-works-amazon-aurora-serverless/
-
https://softwareengineeringdaily.com/2017/05/10/convolutional-neural-networks-with-matt-zeiler/
原文連結:https://softwareengineeringdaily.com/2018/01/13/the-gravity-of-kubernetes/
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
