來自:Hollis(微訊號:hollischuang) hollischuang.com/archives/1983 原文:blog.takipi.com/the-top-100-java-libraries-in-2017-based-on-259885-source-files/
一年的時間就這麼匆匆過去了,就好像像我們昨天才剛剛從GitHub上分析了2016年的Top Java類庫一樣。今年,我們在資料檢索方面採用了Google的BigQuery,來得到更精確的結果。
譯者註:BigQuery 是 Google 專門面向資料分析需求設計的一種全面託管的 PB 級低成本企業資料倉庫。該服務讓開發者可以使用Google的架構來執行SQL陳述句對超級大的資料庫進行操作。BigQuery 可在幾秒內掃描 1 TB 的資料,在幾分鐘內掃描 1 PB 的資料。
首先,我們按照star數排名,從GitHub上拉取了前1000份Java程式碼倉庫,然後過濾掉Android專案,剩下477個純Java專案。
我們基於這477個純Java專案進行了分析。我們去重之後統計了所有的類庫的import。更深入的關於統計方法的介紹在文章底部。
廢話不多說,讓我們來看看2017年最受歡迎的Java類庫都有哪些?今年又是誰穩坐第一的寶座。
一
最受歡迎的前20個Java類庫
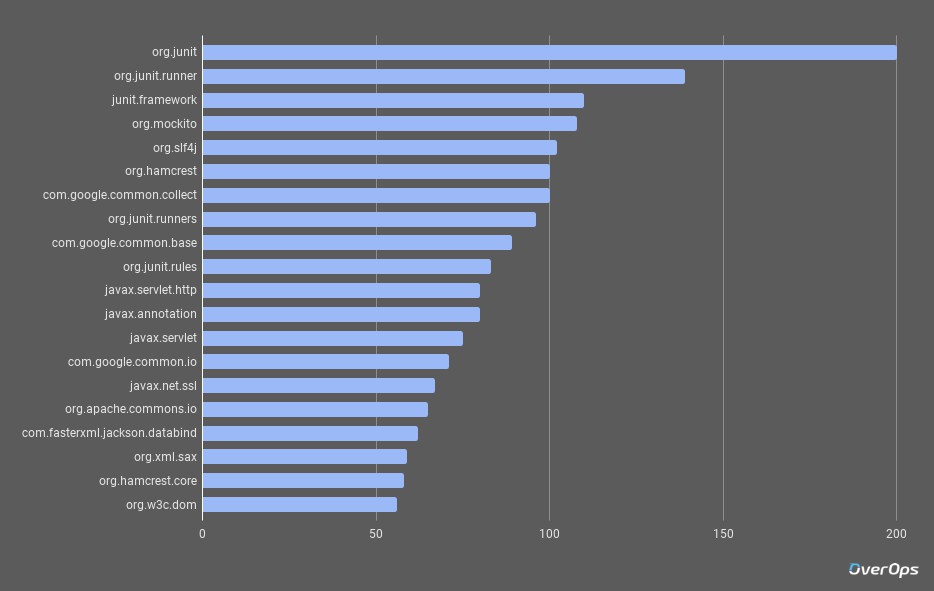 和去年一樣,排名第一的類庫,依舊是
和去年一樣,排名第一的類庫,依舊是JUnit。基於它擴充套件的 JUnit Runner 佔據第二名的位置,甚至是較舊的 junit.framework 此次也在第三名的位置。也就是說JUnit包攬了前三甲。
Mockito,這個開源的mock測試框架排名第四。
譯者註:Mockito 是一個強大的用於 Java 開發的模擬測試框架, 透過 Mockito 我們可以建立和配置 Mock 物件, 進而簡化有外部依賴的類的測試.
Java中的日誌組建 slf4j 位列第五。這從某個側面體現出目前的開發人員對日誌還是比較情有獨鐘的。同時也看得出Java開發人員對於 java.util.logging 庫的使用率較低。我們也曾經分析過Java開發者使用日誌的一些習慣和偏好。整理在eBook中。
Hamcrest類庫排名的上升,說明瞭開發人員確實是需要更好的測試環境。
譯者註:Hamcrest是一個協助編寫用Java語言進行軟體測試的框架。它支援建立自定義的斷言匹配器(assertion matchers)(名稱“Hamcrest”即為“matchers”的異位構詞),允許宣告式定義匹配規則。這些匹配器在單元測試框架(例如JUnit和jMock)中有用。
分析排名在前幾名的類庫我們發現,測試對於寫出更好的程式碼是十分重要的。這也就說明瞭一個事實,出現線上問題是開發者最不想看到的,所以我們會想盡一切辦法去避免他的發生。(這部分還有一些關於作者網站的廣告,我就不翻譯了。)
Google的Guava類庫排名第 7。 最受歡迎的JSON類庫是Jackson 。 榜單第20名,是一個新晉類庫:org.w3c.dom 。它提供了一系列操作DOM的介面。
一
其他值得我們註意的類庫
縱觀前100名,我們發現Spring 有很好的表現。以下8個類庫進入前100 :
#57 – org.springframework.beans.factory.annotation
#60 – org.springframework.context
#65 – org.springframework.context.annotation
#66 – org.springframework.stereotype
#68 – org.springframework.util
#81 – org.springframework.test.context.junit4
#85 – org.springframework.beans.factory
#91 – org.springframework.web.bind.annotation除了Spring之外,Apache的類庫也有廣泛的應用:
#16 – org.apache.commons.io
#22 – org.apache.http
#24 – org.apache.commons.lang
#25 – org.apache.http.impl.client
#30 – org.apache.http.client
#33 – org.apache.http.client.methods
#34 – org.apache.log4j
#35 – org.apache.commons.codec.binary
#45 – org.apache.commons.lang3
#53 – org.apache.http.entity
#61 – org.apache.http.util
#64 – org.apache.commons.logging
#75 – org.apache.http.message
#88 – org.apache.zookeeper
#95 – org.apache.hadoop.conf
#98 – org.apache.http.client.config
#100 – org.apache.http.client.utils譯者註:看到apache類庫有這麼好的表現,筆者比較開心。筆者一直崇尚不要重覆製造輪子,我們日常開發中可能用到的一些方法在apache的類庫中具有最佳實現。比如處理IO流、處理集合等。
在今年的排名中,AssertJ較去年有明顯的提升,它為 Java 提供了流式斷言(Fluent assertions)。今年它攀升至 50 名。
我們在榜單中也發現了 javax.script和 org.apache.http.client.utils這兩個指令碼API。
指令碼API供那些希望在其 Java 應用程式中執行用指令碼語言編寫的程式的應用程式程式設計人員使用。
一
分析方法
文章開通我們提及過,今年我們使用Google的BigQuery來處理資料。我們透過GitHub提供的API拉取了1000份倉庫程式碼。在過濾掉Android、Arduino和一些過時的倉庫後,我們還剩餘259,885份Java源檔案。我們對同一個倉庫中使用的類庫進行去重後,還剩餘25,788份類庫。
我們實際是怎麼做的呢?
首先,我們建立一個倉庫表,用來儲存star數排名靠前的哪些類庫,命名為java_top_repos_filtered:
SELECT
full_name
FROM
java_top_repos_1000
WHERE NOT ((LOWER(full_name) CONTAINS 'android') OR
(LOWER(full_name) CONTAINS 'arduino'))
AND ((description IS null) OR
(NOT ((LOWER(description) CONTAINS 'android') OR
(LOWER(description) CONTAINS 'arduino') OR
(LOWER(description) CONTAINS 'deprecated'))));現在,我們有了排名靠前的類庫的名字,然後我們把他們都拉取下來:
SELECT
repo_name,
content
FROM
[bigquery-public-data:github_repos.contents] AS contents
INNER JOIN
(
SELECT
id,
repo_name
FROM
[bigquery-public-data:github_repos.files] AS files
INNER JOIN
java_top_repos_filtered AS top_repos
ON
files.repo_name = top_repos.full_name
WHERE
path LIKE '%.java'
) AS files_filtered
ON
contents.id = files_filtered.id;至此,我們有了每個專案的原始碼,我們就要把去重後的import的陳述句過濾出來,然後在提取包名稱。
SELECT
package,
COUNT(*) count
FROM
( //extract package name (exclude last point of data) and group with repo name (to count each package once per repo)
SELECT
REGEXP_EXTRACT(import_line, r' ([a-z0-9\._]*)\.') package,
repo_name
FROM
( //extract only 'import' code lines from *.java files
SELECT
SPLIT(content, '\n') import_line,
repo_name
FROM
java_relevant_data
HAVING
LEFT(import_line, 6) = 'import'
)
GROUP BY
package,
repo_name
)
GROUP BY
package
ORDER BY
count DESC;最後,我們再進行一次過濾,確保沒有Android, Arduino、過時的或者Java提供的原生的類庫。
SELECT
*
FROM
java_top_package_count
WHERE
NOT ((LEFT(package, 5) = 'java.') OR
(LOWER(package) CONTAINS 'android'))
ORDER BY
count DESC;至此,你就得到了一份2017年排名Top 100的Java類庫的串列了。
一
最後的一點想法
一個主要的結論是:那些2016年受歡迎的類庫,在2017年依舊受歡迎。這也說明,這些類庫背後的開發者、團隊或者公司都在努力的使這些類庫更好。
這也意味著,如果你打算開始寫自己的Java專案,或者日常的開發中,我們的電子錶格可以提供一些好的建議。這些排名靠前的類庫是不錯的選擇。
附錄:Top 100 Java Libraries
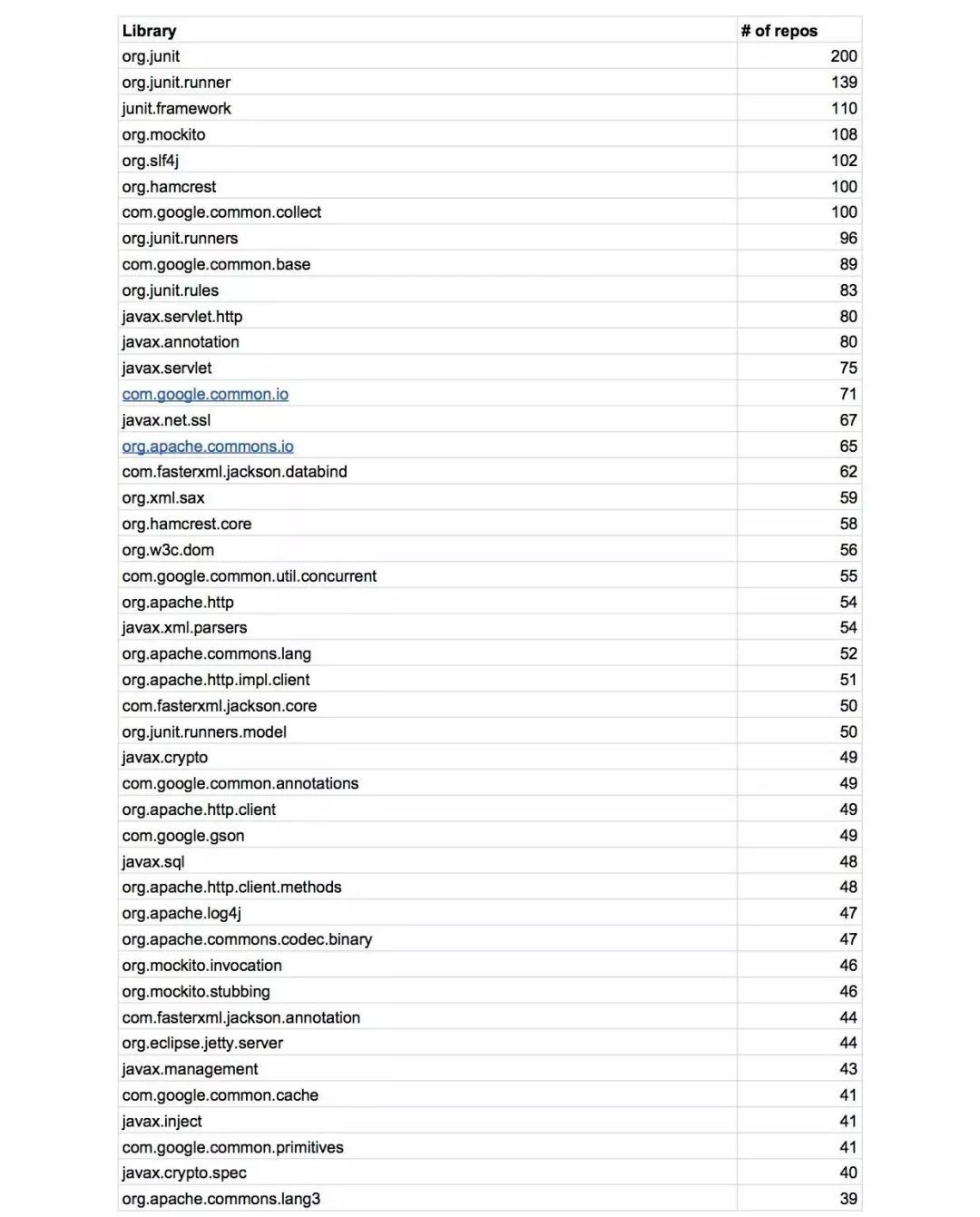
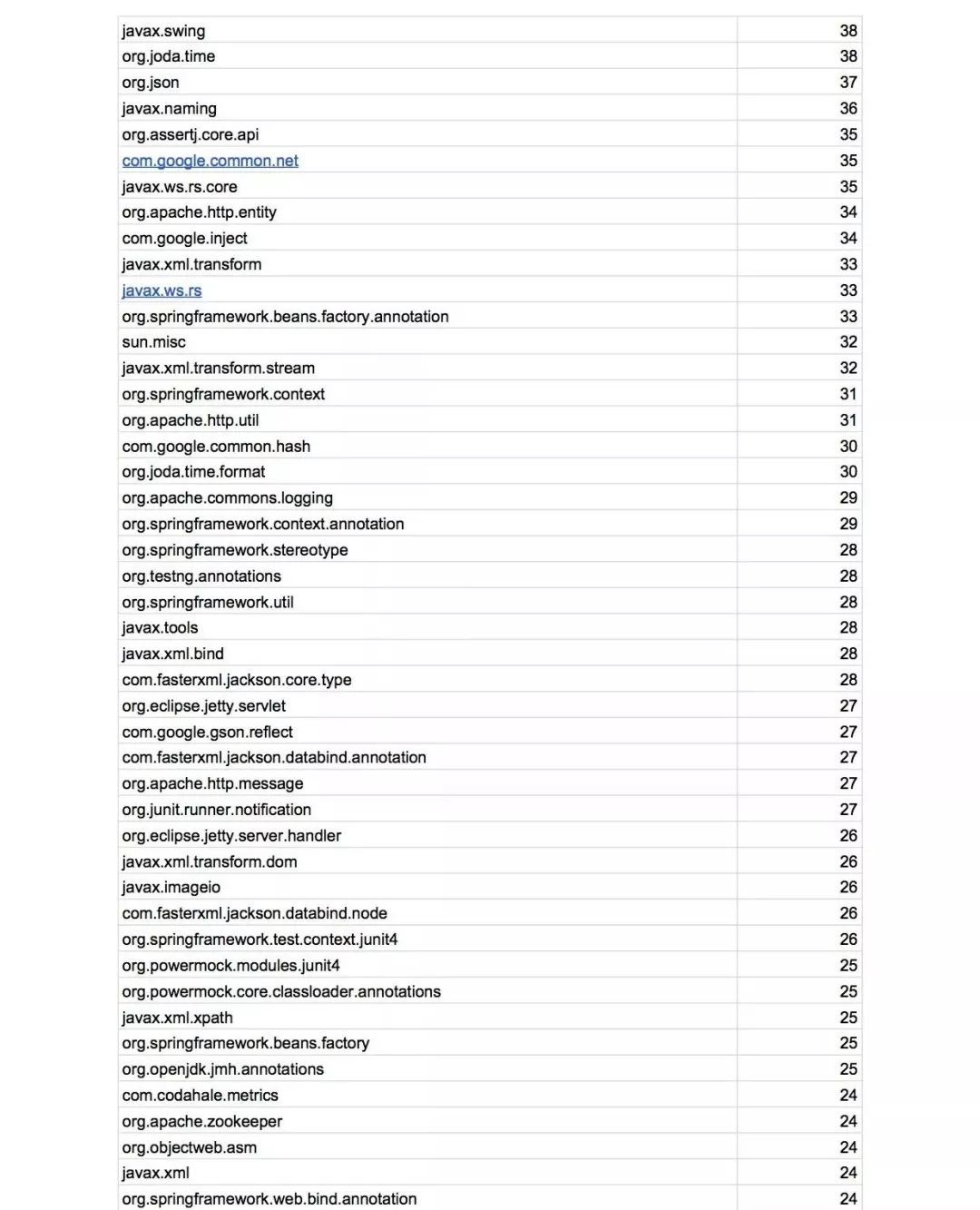

相關閱讀
2016年排名Top 100的Java類庫——在分析了47,251個依賴之後得出的結論
●本文編號595,以後想閱讀這篇文章直接輸入595即可
●輸入m獲取到文章目錄

Python程式設計
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
