(點選上方公眾號,可快速關註)
來源:koala bear,
wsfdl.com/algorithm/2017/01/28/理解一致性雜湊.html
簡介
為瞭解決分散式 web 中的熱點問題,David Karger 於 1997 年提出 一致性雜湊(Consistent Hashing),論文請見 Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web(較難理解)。一致性雜湊廣泛的運用於多種分散式系統中,如 memcache/redis,gluster file system, zookooper 等。
-
Swift: Building a Consistent Hashing Ring
-
Cassandra: Consistent Hashing in Cassandra
-
Redis/Memcache: Memcache的一致性hash演演算法使用
-
…
論文地址
https://www.akamai.com/es/es/multimedia/documents/technical-publication/consistent-hashing-and-random-trees-distributed-caching-protocols-for-relieving-hot-spots-on-the-world-wide-web-technical-publication.pdf
本文主要介紹一致性雜湊的原理。
原理
去中心與水平擴充套件
以 web 為例,cache 節點(如 Redis, Memcache)廣泛用於 web 中,以提升效能。隨著 web 規模擴大,單個節點無論是從效能上還是容量上都無法支撐大規模的業務,所以需要用多個節點以提升效能和容量。
在多個節點下,給定某個 object,客戶端如何知道它儲存在哪個節點呢?最簡單的做法是選取某個節點做為元資料伺服器,記錄每個 object 存放的節點,每次訪問該 object 時,客戶端首先訪問元資料伺服器,獲取其所存放的節點,最後從該節點獲取 object。元資料伺服器需要維護所有 object 的位置資訊,並且每次訪問 object 都需要先訪問元資料伺服器,如此,元資料伺服器容易成為效能和容量的瓶頸,不利於大規模擴充套件。
1. Fetch +—————–+
client ————-> | Metadata Server | bottleneck
Location +—————–+
2. Access +—————–+
————-> | Cache Server X |
Cache Server +—————–+
去中心化的系統最大優點之一就是易水平擴充套件,那是否有辦法可以去除上述元資料伺服器呢。答案是肯定的,比如計算 object 的 hash 值,然後均勻的分佈到各個節點上。
hash(object) mod N 其中 N 為節點數目
但是如果某個節點宕機,剔除宕機節點後數目為 N – 1,此時對映關係變為:
hash(object) mod (N – 1)
另外,可能由於負載過高,需要新增一個節點,此時對映關係為:
hash(object) mod (N + 1)
無論是增加還是減少節點,都有可能會改變對映關係,造成大量請求的 miss。那是否能避免大量的 miss 呢?答案也是肯定的,一致性雜湊解決了節點增減造成大量 hash 重定位的問題。
原理與增刪節點
一致性雜湊的原理如下:
-
將每個節點(node)對映到數值空間 [0, 2^32 – 1],對映的規則可為 IP、hostname 等。
-
將每個 object 對映到數值空間 [0, 2^32 – 1]。
-
對於某個 object,對於所有滿足 hash(node) <= hash(object) 的節點,選擇 hash(node) 最大的節點存放 object。如果沒有滿足上述條件的節點,選擇 hash(node) 最小的節點存放該 object,如下圖。
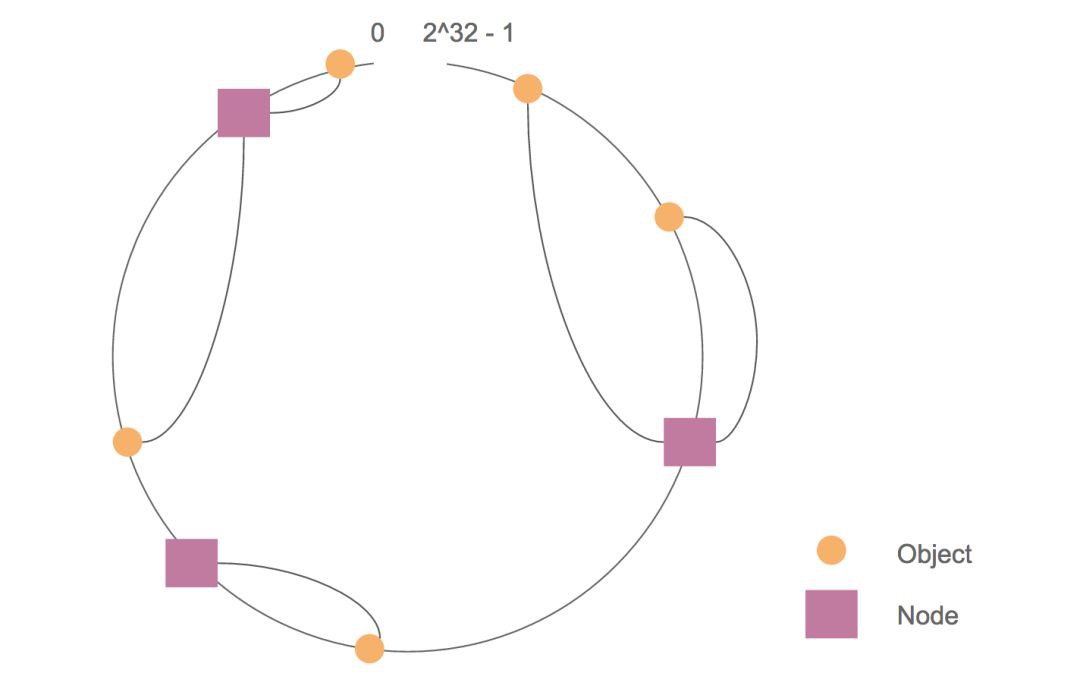
當某個節點宕機時,僅有該節點的物件被重雜湊到相鄰節點上。

與此類似,當新增一個節點時,僅有一個節點的部分 object 需要重雜湊。

虛節點與平衡性
節點的位置是由自身雜湊值決定的,它們的分佈並非均勻,特別當節點數目很少時,容易造成 object 的分佈不均勻,即平衡性低,例如:
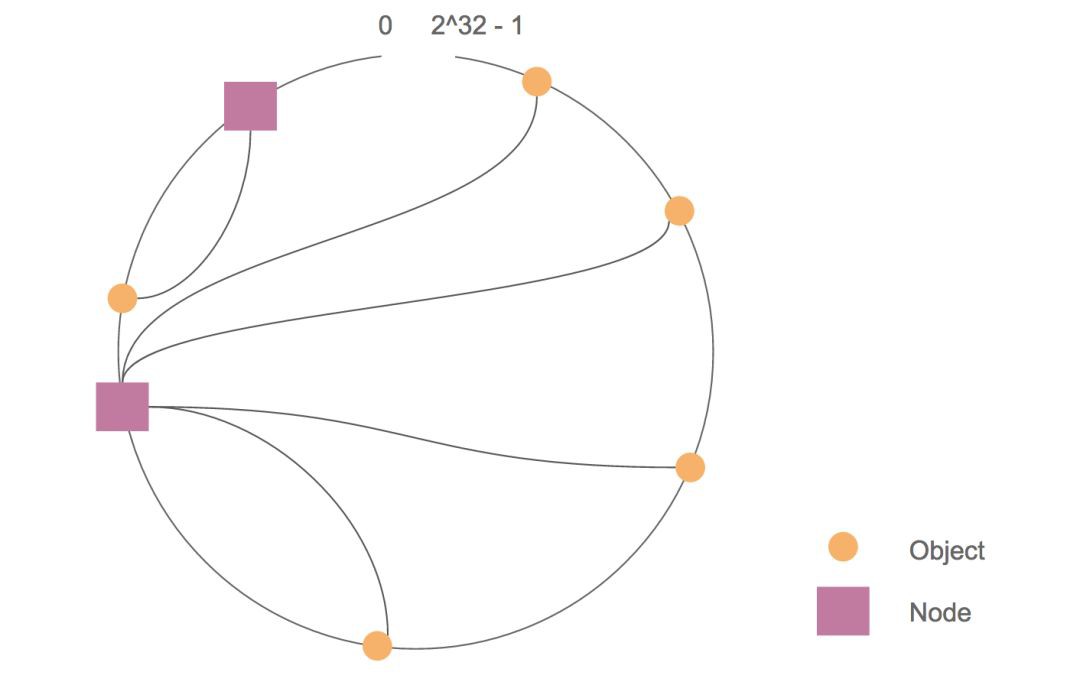
為瞭解決這個問題,我們引入虛擬節點,虛擬節點實際上是物理節點的複製品,一個物理節點包含多個虛擬節點,我們將這些虛擬節點對映到數值空間 [0, 2^32 – 1],對於某個 object,我們根據上節步驟計算該 object 存放的虛擬節點,進而得出物理節點。如下圖共有 2 個物理節點,每個物理節點有三個虛擬機器節點。當虛擬節點越多,虛擬節點的位置分佈越均勻,相應的,對映到物理節點的 object 數目也越均勻,提高了平衡性。
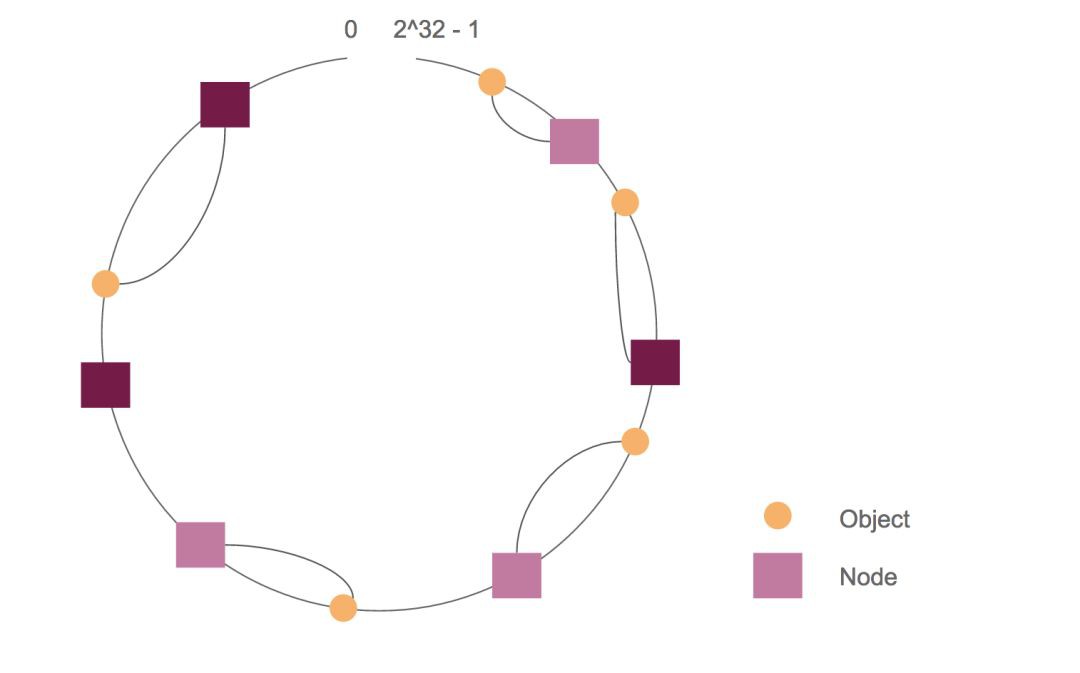
總結
透過一致性雜湊,客戶端可以在本地計算 object 的存放位置,去除了中心節點,使得系統容易水平擴充套件,便於按需提升/降低整體的容量和效能,同時避免了每次增刪節點造成大量雜湊重定位的問題,最大化的減少了資料遷移。為使 object 能夠盡可能均衡的分散在各個節點上,一致性雜湊引入了虛節點,以提高平衡性。
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

