
CIKM 2017

論文 | Hike: A Hybrid Human-Machine Method for Entity Alignmentin Large-Scale Knowledge Bases
連結 | https://www.paperweekly.site/papers/1528
解讀 | 羅丹,浙江大學碩士
1. Motivation
隨著語意網路的迅速發展,越來越多的大規模知識圖譜公開釋出,為了綜合使用多個來源的知識圖譜,首要步驟就是進行物體對齊(Entity Alignment)。
近年來,許多研究者提出了自動化的物體對齊方法,但是,由於知識圖譜資料的不均衡性,導致此類方法對齊質量較低,特別是召回率(Recall)。
因此,可考慮藉助於眾包平臺提升對齊效果,本文提出了一個人機協作的方法,對大規模知識圖譜進行物體對齊。
2. Framework
方法主要流程如圖所示:

首先,透過機器學習方法對知識庫進行粗略的物體對齊,然後分別將以對齊物體對(Matched Pairs)和未對齊物體對(Unmatched Pairs)放入眾包平臺,讓人進行判斷。
兩條流水線的步驟類似,主要包括四個部分:物體集劃分(Entity Partition)、建立偏序(Partial Order Construction)、問題選擇(Question Selection)、容錯處理(Error Tolerance)。
物體集劃分的目的是將同類的物體聚類到一個集合,物體對齊只在集合內部進行,集合之間不進行對齊操作。物體集劃分的依據是屬性,通常同一類物體的屬性是相似的。 偏序定義如下:

建立偏序的目的在於找出最具有推理期望(Inference Expectation)的物體對,偏序集實體如下:

其中,如果 P11 被判斷為 Unmatch,則所有偏序小於 P11 的節點都可以推斷為 unmatch。反之,如果 P45 被推斷為 Match,則所有偏序大於 P45 的節點都可以推斷為 Match。推理期望公式如下:

其中,pre 和 suc 分別表示前驅和後繼節點。
對於問題選擇,文章提出了兩個貪心演演算法,分別為一次選一個節點以及一次選多個節點。演演算法如下:


3. Experiment
資料集:Yago,DBPedia
對比方法:PARIS,PBA
眾包平臺:ChinaCrowds
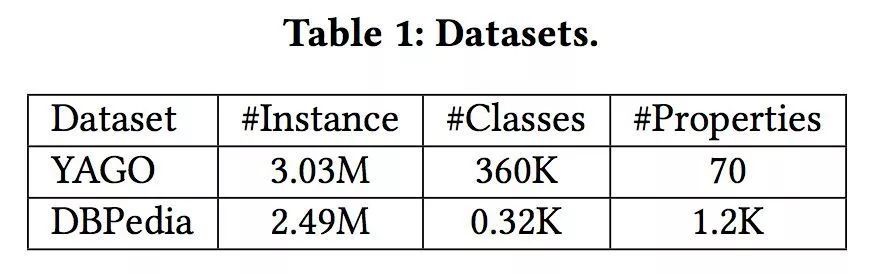
評估問題選擇方法:
可以看到,兩個貪心演演算法差別不大,但是比隨機選擇效能好。
評估問題集大小:

隨著問題集合的增加,較精確率、召回率、F 值均有提升。
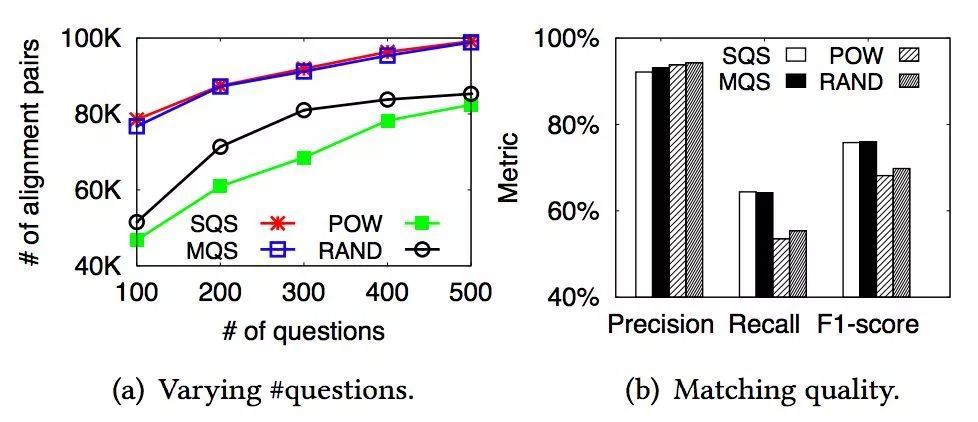
評估物體對齊結果:

實驗表明,各項評估指標具有提升,證實了人機協作的有效性,但是 MQS 演演算法複雜度太高,導致執行時間過長。
ACL 2017

論文 | Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix
連結 | https://www.paperweekly.site/papers/1529
解讀 | 王冠穎,浙江大學碩士
1. 動機
Distant supervision 是一種生成關係抽取訓練集的常用方法。它把現有知識庫中的三元組
但是這種匹配方式會產生很多噪音:比如三元組
其中前一句是我們想要的標註資料,後一句則是噪音資料(並不表示 born-in)。如何去除這些噪音資料,是一個重要的研究課題。
2. 前人工作
第一種方法是透過定義規則過濾掉一些噪音資料,缺點是依賴人工定義,並且被關係種類所限制。
另一種方法則是 Multi-instancelearning,把訓練陳述句分包學習,包內取平均值,或者用 attention 加權,可以中和掉包內的噪音資料。缺點是受限於 at-least-one-assumption:每個包內至少有一個正確的資料。
可以看出前人主要思路是『去噪』,即降低噪聲資料的印象。這篇文章提出用一個噪音矩陣來擬合噪音的分佈,即給噪音建模,從而達到擬合真實分佈的目的。
3. 模型
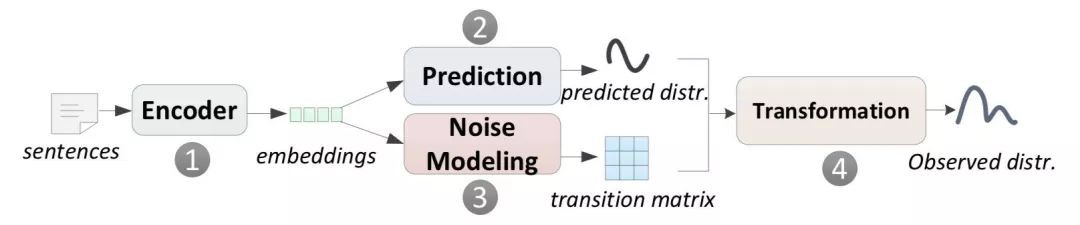
其中 1 和 2 是普通的關係抽取模型過程,3 和 4 是噪音擬合的過程。
transition matrix 是一個轉移矩陣,大小為 n * n,n 是關係種類的數目。T_ij 的元素的值是 p( j| i ),即該句子代表關係為 i,但被誤判為 j 的機率。 這樣我們就可以得到:
× =
其中,predicted 是我們想要的真實分佈,observed 是我們觀測到的噪音分佈,這樣就可以用噪音資料進行聯合訓練了。
3.1 全域性轉移矩陣 & 動態轉移矩陣
Global transition matrix 在關係層面上定義一個特定的轉移矩陣,比如:

屬於 A 關係的句子,被誤判為 B 關係的機率是恆定的。 Dynamic transition matrix 是在句子層面上定義的,即使同屬於 A 關係,a1 句子和 b1 句子被誤判成 B 關係的機率也不同。
比如下麵兩句話,帶有 old house 的被誤判成 born-in 的機率更大。

動態轉移矩陣更有優勢,粒度更細。
3.2 訓練方法
如果單純用 observed 的 loss,會出現問題,因為在初始化的時候,我們並不能保證 p 一定擬合真實分佈,轉移矩陣也沒有任何先驗資訊,容易收斂到區域性最優。
因此,文中用 curriculum learning 進行訓練:

trace 是轉移矩陣的跡,用於控制訓練過程中噪音的作用,是矩陣的正則項。在沒有噪音的情況下,矩陣是一個單位矩陣,跡較大,此時矩陣沒有效果。跡越小,矩陣施加的效果越明顯。
curriculum learning 的步驟:
初始階段,alpha 為 1,beta 取一個很大的值,只學習 p 分佈,讓 p 獲得關係判定的能力; 後續階段,逐漸減小 alpha 和 beta,強化矩陣的作用,學習噪音分佈 o,最後獲得真實的 p 分佈和噪音 o 分佈。
這樣透過調控過程,就可以避免學習出無意義的區域性最優值了。
3.3 先驗知識
可以給矩陣增加一些先驗知識,比如在 timeRE 的資料集上,根據時間粒度,對資料集進行可信度劃分,先訓練可信資料,再訓練噪音資料,這樣可以最佳化最終的訓練結果。
4. 實驗結果
作者在 timeRE 和 entityRE (NYT) 上均進行了訓練,取得了降噪的 state-of-art。具體分析結果可以參照論文。

AAAI 2017
論文 | Distant Supervision for Relation Extraction with Sentence-level Attention and Entity Descriptions
連結 | https://www.paperweekly.site/papers/179
解讀 | 劉兵,東南大學博士
1. 論文動機
關係抽取的遠端監督方法透過知識庫與非結構化文字對其的方式,自動標註資料,解決人工標註的問題。但是,現有方法存在無法選擇有效的句子、缺少物體知識的缺陷。
無法選擇有效的句子是指模型無法判斷關係實體對應的句子集(bag)中哪個句子是與關係相關的,在建模時能會將不是表達某種關係的句子當做表達這種關係的句子,或者將表達某種關係的句子當做不表達這種關係的句子,從而引入噪聲資料。
缺少物體知識是指,例如下麵的例句種,如果不知道 Nevada 和 Las Vegas 是兩座城市,則很難判斷他們知識是地理位置上的包含關係。
[Nevada] then sanctioned the sport , and the U.F.C. held its first show in [Las Vegas] in September 2001.
本文為了引入更豐富的資訊,從 Freebase 和 Wikipedia 頁面中抽取物體描述,借鑒表示學習的思想學習得到更好的物體表示,並提出一種句子級別的註意力模型。
本文提出的模型更好地實現註意力機制,有效降低噪聲句子的影響,效能上達到當前最優。
2. 論文貢獻
文章的貢獻有:
引入句子級別的註意力模型來選擇一個 bag 中的多個有用的句子,從而充分利用 bag 種的有用資訊;
使用物體描述來為關係預測和物體表達提供背景資訊;
實驗效果錶面,本文提出的方法是 state-of-the-art 的。
3. 論文方法
本文的方法包括三個部分:句子特徵提取、物體表示和 bag 特徵提取。
句子特徵提取模型結構如下圖(a)所示,模型流程如下:
使用詞向量和位置向量相連線作為單詞表示,句子的詞表示序列作為模型的輸入;
使用摺積神經網路對輸入層提取特徵,然後做 piecewise 較大池化,形成句子的特徵表示。

物體表示在詞向量的基礎上,使用物體描述資訊對向量表示進行調整,形成最終的物體向量表示。
模型主要思想是,使用 CNN 對物體的描述資訊進行特徵提取,得到的特徵向量作為物體的特徵表示,模型的訓練標的是使得物體的詞向量表示和從描述資訊得到的物體特徵表示盡可能接近。
Bag 特徵提取模型的關鍵在句子權重學習,在得到 bag 中每個句子的權重後,對 bag 中所有句子的特徵向量進行加權求和,得到 bag 的特徵向量表示。
模型中用到了類似 TransE 的物體關係表示的思想:e1+r=e2。使用(e2-e1)作為物體間關係資訊的表達,與句子特徵向量相拼接,進行後續的權重學習。
Bag 特徵提取模型如上圖(b)所示:
使用 bag 中的所有句子的特徵向量表示,結合 e2-e1方式得到的關係表示,作為模型的輸入;
利用權重學習矩陣,得到每個句子的權重;
對句子進行加權求和,得到 bag 的最終表示。
4. 實驗
文章在遠端監督常用的資料集(Rediel 2010)上,按照常規的遠端監督的實驗思路,分別進行了 heldout 和 manual 實驗。
Heldout 實驗即使用知識庫中已有的關係實體標註測試集,驗證模型的效能,結果如下麵的 Precision-Recall 圖所示,超過其他較好的方法。

Manual 實驗對知識庫中不存在的關係實體進行預測,然後使用人工標註預測結果的正確性,使用 top-K 作為評測指標,結果如下表所示,本文提出的方法也達到了當前較好的效果。

此外,實驗還透過 case study,研究了模型對於 bag 中每個句子的註意力分配效果,表明本模型可以有效地區分有用的句子和噪聲句子,且本文的引入物體描述可以使得模型得到更好的註意力分配。
IJCAI 2017

論文 | Dynamic Weighted Majority for Incremental Learning of Imbalanced Data Streams with Concept Drift
連結 | https://www.paperweekly.site/papers/1530
解讀 | 鄧淑敏,浙江大學 2017 級直博生
1. 論文動機
資料流中發生的概念漂移將降低線上學習過程的準確性和穩定性。如果資料流不平衡,檢測和修正概念漂移將更具挑戰性。目前已經對這兩個問題分別進行了深入的研究,但是還沒有考慮它們同時出現的情況。
在本文中,作者提出了一種基於塊的增量學習方法,稱為動態加權多數增量學習(DWMIL)來處理具有概念漂移和類不平衡問題的資料流。DWMIL 根據基分類器在當前資料塊上的效能,對基分類器進行動態加權,實現了一個整體框架。
2. Algorithm & Ensemble Framework
演演算法的輸入:在時間點 t 的資料 D^(t)={xi belongs to X,yi belongs to Y}, i=1,…,N, 刪除分類器的閾值 theta, 基分類器集合 H^(t-1)={H^(t-1)_1,…,H^(t-1)_m}, 基分類器的權重 w^(t-1), 基分類器的數量 m, 整合的規模大小 T。
Step 1:透過整合分類器對輸入的進行預測。

Step 2:計算當前輸入的資料塊在基分類器上的錯誤率 epsilon^t_j,並更新基分類器的權重。

Step 3:移除過時的分類器(權重值小於閾值 theta)並更新基分類器數量。

Step 4:構建新的分類器並對其初始化。

演演算法的輸出:更新的基分類器集合 H^(t), 基分類器的權重 W^(t),基分類器的數量 m,標的預測值 bar_y。
本文的演演算法如下圖所示:


3. Experiments
本文選取了 4 個合成、2 個真實的均具有概念漂移的資料集。並且在集合方法、自適應方法、主動漂移檢測方法中各選取了一個具有代表性的作為 baseline,分別是:Learn++.NIE(LPN)、Recursive Ensemble Approach (REA)、Class-Based ensemble for Class Evolution(CBCE),並與 Dynamic Weighted Majority (DWM) 也進行了比較。
對具有概念漂移的合成資料集和實際資料集的實驗表明,DWMIL 與現有技術相比,效能更好,計算成本更低。
4. Comparisons
與現有方法相比,其優點在於以下 4 點:
能夠使非偏移的資料流保持穩定,快速適應新的概念;
它是完全增量的,即不需要儲存以前的資料;
模型中保持有限數量的分類器以確保高效;
簡單,只需要一個閾值引數。
DWMIL 與 DWM 相比:
在學習資料流的過程中,DWMIL 和 DWM 都保留了一些分類器。但是,在決定是否建立一個新的分類器時,DWM 的依據是單個樣本的預測效能。如果資料不平衡,則樣本屬於多數類的機率比少數類的高得多,並且對多數類樣本錯誤分類的機率較低。
因此,DWM 在不平衡資料流上建立新分類器的機會很低。事實證明,它可能無法有效地適應新的概念。相比之下,DWMIL 為每個資料塊建立一個新的分類器,以及時學習新的概念。
在決定是否移除一個過時或低效的分類器時,DWM 中分類器的權重透過固定的引數β減少,並且在歸一化之後再次減小。
相反,DWMIL 根據效能降低了權重,沒有任何標準化。因此,如果當前概念與建立分類器的概念類似,則分類器可以持續更長時間來對預測做出貢獻。
DWMIL 與 Learn++ 相比:
Learn++ 和 DWMIL 都是為每個資料塊建立分類,並使用分類錯誤率來調整權重。
但是,關於降低在過去的資料塊上訓練的分類器的權重這一問題,Learn++ 使用了時間衰減函式 σ。這個 σ 取決於兩個自由引數:a 和 b,其中不同的值會產生不同的結果。在 DWMIL 中,減重僅取決於沒有自由引數的分類器的效能。
關於分類器權重的影響因素,在 Learn++ 中,權重不僅取決於當前資料塊,還取決於建立的分類器到當前資料塊的資料塊。在這種情況下,可能會產生偏差。
具體來說,如果一個分類器在其建立的資料塊上表現得非常好,它將在接下來幾個資料塊中持續獲得更高的權重。如果概念發生變化,那麼在舊概念上訓練的分類器的高權重將降低預測效果。
關於分類器的效能,Learn++ 會保留所有的分類器。如果資料流很長,累積的分類器會增加計算負擔,因為它需要評估當前分塊上所有過去的分類器的效能。相比之下,DWMIL 放棄了過時或無用的分類器來提高計算效率。
筆者認為,這篇文章的主要創新點在於:用資料塊的輸入代替傳統的單一樣本輸入,使得模型可以更快地對概念漂移作出反應;透過對分類器效能的檢測,動態調整它們的權重,並及時剔除過時或低效的分類器,使得模型比較高效。
AAAI 2018

論文 | Reinforcement Learning for Relation Classification from Noisy Data
連結 | https://www.paperweekly.site/papers/1260
解讀 | 周亞林,浙江大學碩士
1. 論文動機
Distant Supervision 是一種常用的生成關係分類訓練樣本的方法,它透過將知識庫與非結構化文字對齊來自動構建大量訓練樣本,減少模型對人工標註資料的依賴。
但是這樣標註出的資料會有很多噪音,例如,如果 Obama 和 United States 在知識庫中的關係是 BornIn,那麼“Barack Obama is the 44th President of the United States.”這樣的句子也會被標註為 BornIn 關係。
為了減少訓練樣本中的噪音,本文希望訓練一個模型來對樣本進行篩選,以便構造一個噪音較小的資料集。模型在對樣本進行篩選時,無法直接判斷每條樣本的好壞,只能在篩選完以後判斷整個資料集的質量,這種 delayed reward 的情形很適合用強化學習來解決。
2. 模型
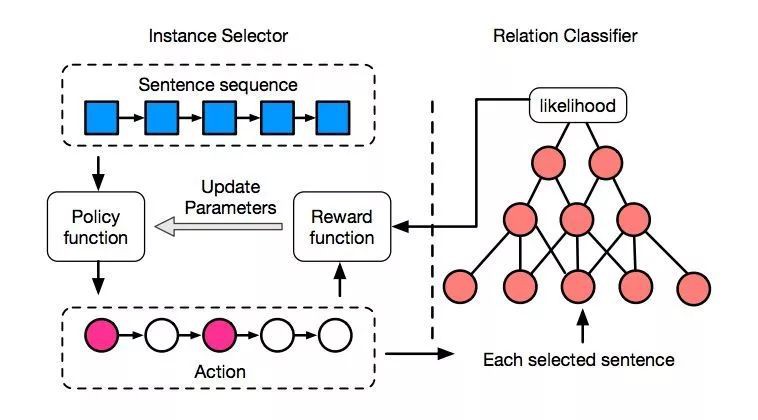
模型框架如圖所示,左邊是基於強化學習的 Instance Selector,右邊是經典的基於 CNN 的 Relation Classifier。
Instance Selector 根據 Policy function 對樣本逐個篩選,每個樣本都可以執行“選”或“不選”兩種 Action,篩選完以後會生成一個新的資料集。
我們用 Relation Classifier 來評估資料集的好壞,計算出一個 reward,再使用 policy gradient 來更新 Policy function 的引數,這裡的 reward 採用的是資料集中所有樣本的平均 likelihood。
為了得到更多的反饋,提高訓練效率,作者將樣本按照物體對分成一個個 bag,每次 Instance Selector 對一個 bag 篩選完以後,都會用 Relation Classifier 對這部分資料集進行評估,並更新 Policy function 的引數。
在所有 bag 訓練完以後,再用篩選出的所有樣本更新 Relation Classifier 的引數。 具體訓練過程如下:

3. 實驗
論文在 NYT 資料集上與目前主流的方法進行了比較,註意這裡是 sentence-level 的分類結果,可以看到該方法取得了不錯的效果。

論文分別在原始資料集和篩選以後的資料集上訓練了兩種模型,並用 held-out evaluation 進行評估,可以看出篩選以後的資料集訓練出了更好的關係分類模型。
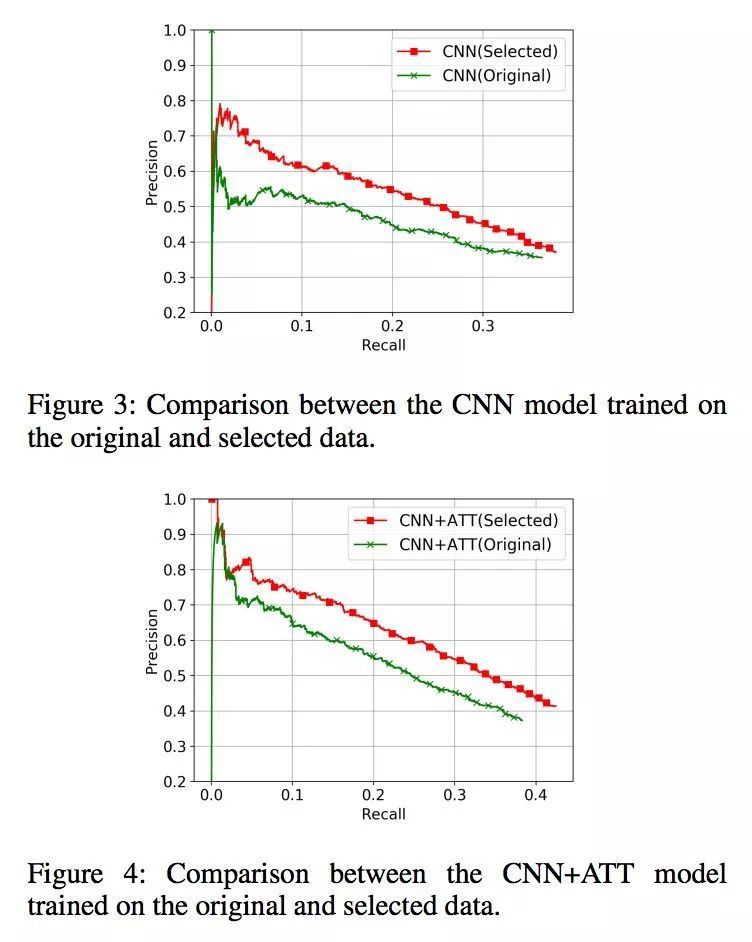
作者又比較了使用強化學習和 greedy selection 兩種篩選樣本的方法,強化學習的效果更好一些。

AAAI 2017

論文 | Leveraging Knowledge Bases in LSTMs for Improving Machine Reading
連結 | https://www.paperweekly.site/papers/1531
解讀 | 李娟,浙江大學博士生
這篇論文是今年發表在 ACL 的一篇文章,來自 CMU 的工作,提出透過更好地利用外部知識庫的方法解決機器閱讀問題。
由於傳統方法中用離散特徵表示知識庫的知識存在了特徵生成效果差而且特徵工程偏特定任務的缺點,本文選擇用連續向量表示方法來表示知識庫。
傳統神經網路端到端模型使得大部分背景知識被忽略,論文基於 BiLSTM 網路提出擴充套件網路 KBLSTM,結合 attention 機制在做任務時有效地融合知識庫中的知識。
論文以回答要不要加入 background knowledge,以及加入哪一些資訊兩部分內容為導向,並藉助以下兩個例子說明兩部分內容的重要性。
“Maigretleft viewers in tears.”利用背景知識和背景關係我們可以知道 Maigret 指一個電視節目,“Santiago is charged withmurder.”如果過分依賴知識庫就會錯誤地把它看成一個城市,所以根據背景關係判斷知識庫哪些知識是相關的也很重要。

KBLSTM(Knowledge-aware Bidirectional LSTMs)有三個要點:
檢索和當前詞相關的概念集合V(x_t)
attention 動態建模語意相關性
sentinel vector S_t 決定要不要加入 background knowledge
主要流程分兩條線:
1. 當考慮背景知識的時候就把 knowledge module 考慮進去;
2. 如果找不到和當前詞相關的概念則設定 m_t 為 0,直接把 LSTM 的 hidden state vector 作為最後的輸出。
後者簡單直接,這裡說明前者的結構。knowledge module 模組把 S_t、h_t、V(x_t) 作為輸入,得到每個候選知識庫概念相對於 h_t 的權重 α_t,由 S_t 和 h_t 得到 β_t 作為 S_t 的權重,最後加權求和得到 m_t 和 h_t 共同作為輸入求最後輸出,這裡透過找相關概念和相關權重決定加入知識庫的哪些知識。
論文用 WordNet 和 NELL 知識庫,在 ACE2005 和 OntoNotes 資料集上做了物體抽取和事件抽取任務。兩者的效果相對於以前的模型都有提升,且同時使用兩個知識庫比任選其一的效果要好。
來源:數盟
精彩活動
推薦閱讀
2017年資料視覺化的七大趨勢!
全球100款大資料工具彙總(前50款)
Q: 最近你還看過哪些優秀的論文?
歡迎留言與大家分享
請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:hzzy@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

