
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @duinodu。本文提出了一種端到端的、從問題出發的、多因素註意力網路,用來完成基於檔案的問題回答任務。這個模型可以從多個句子中收集分散的證據,用於答案的生成。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:杜敏,華中科技大學碩士生,研究方向為樣式識別與智慧系統。
■ 論文 | A Question-Focused Multi-Factor Attention Network for Question Answering
■ 連結 | https://www.paperweekly.site/papers/1597
■ 原始碼 | https://github.com/nusnlp/amanda
研究背景
基於閱讀理解的回答問題系統中,機器需要透過理解一段文字,回答給定的一個問題。 從 2013 年到 2017 年出現了各種問題回答的資料集(NewsQA,TriviaQA, SearchQA, SQuAD…)。
大多數已有的解決方法,關註在問題和段落的關係(passage-question interaction),透過尋找相似的背景關係來抽取文字作為答案。
這類方法有兩點不足:
1. 不能透過多個句子合成答案所需要的材料,所以在很多開放 QA 資料集上表現不好。
2. 沒有顯式地關註問題-答案的型別資訊,而實際上,問題-答案的型別在 QA 中很重要。
本文提出了一種端到端的、從問題出發的、多因素註意力網路,用來完成基於檔案的問題回答任務。這個模型可以從多個句子中收集分散的證據,用於答案的生成。
問題的數學描述
QA 任務描述如下: 給定一組(文字 P,問題 Q),需要從文字 P 中抽取一個文字塊(text span),作為問題的回答。
文字 P 表示為 (P1,P2,…PT),問題 Q 表示為 (Q1,Q2,…QU),T 和 U 分別是文字和問題的單詞數。要回答問題,也就是要找到 b,e,其中 1≤b≤e≤T,輸出的回答也就是 (Pb,Pb+1,…Pe)。
從上面的數學描述可以發現,這種 QA 給出的回答,只能是文字中出現的單詞和句子,不能產生新的單詞作為回答。
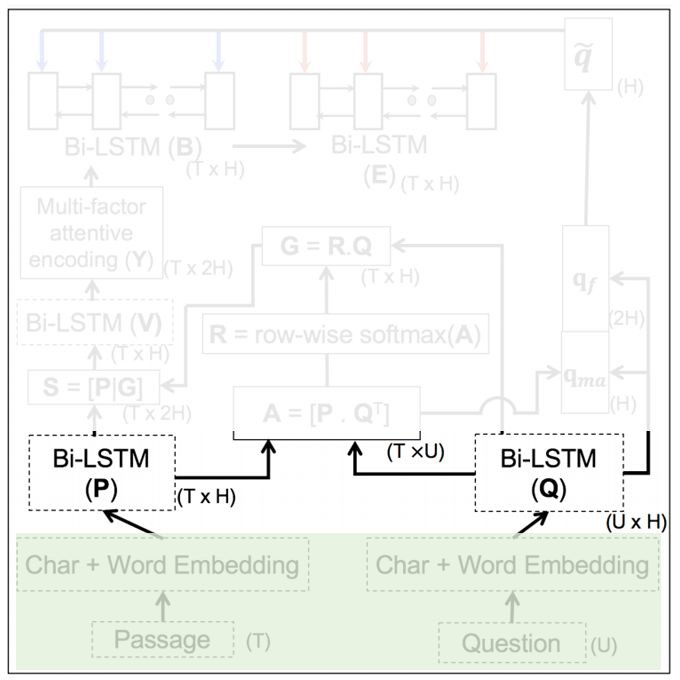
論文模型
模型有一些複雜,我們一點一點理解。
1. Word-level Embedding
幾乎所有的 NLP 問題,第一步都是做 embedding。本文采取兩種 embedding 方法:
-
GloVe(Word)
-
CNN-based(Char):把兩種方式產生的 embedding vector 拼接起來,產生單詞級的 embedding。圖中有兩列,分別表示對文字 P 和問題 Q 都進行相同處理。

這一部分的輸出是 TxH 和 UxH 的矩陣,T 和 U 表示文字和問題的長度,H 表示單詞對應的向量長度。
2. Sequence-level Encoding
第一步僅僅是對單個單詞的處理,還需要在句子級進行處理。對序列資料建模的常見工具:LSTM,所以這部分主要是 LSTM,而且是 BiLSTM。
輸出是分別是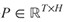 和
和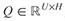 ,H 也是 BiLSTM 中隱含節點的個數。
,H 也是 BiLSTM 中隱含節點的個數。
3. Cartesian Similarity-based Attention Layer
本質上就是一個點積操作,目的是尋找 P 和 Q 中相似的部分。

 ,
, 表示,文字的第 i 個單詞,和問題的第 j 個單詞的相關性。能這樣做的原因是因為第一步做了 embedding。
表示,文字的第 i 個單詞,和問題的第 j 個單詞的相關性。能這樣做的原因是因為第一步做了 embedding。
這個矩陣從列看過去,就能找到文字中哪些地方最可能出現答案,也就是應該註意的地方,所以 A 也叫註意力矩陣(attention matrix)。當然這個矩陣也可以從行看過去,就能找到問題中哪些詞是關鍵詞,第 4 步就是這樣做的。
4. Question-dependent Passage Encoding
用 A 從 Q 中取出問題中值得關註的詞 G,把 G 加入到 P 中再做一次 LSTM 得到 V。由於 V 的計算過程考慮了 Q,所以把 V 叫做 question-dependent passage word encoding vector。

5. Multi-factor Attentive Encoding
這部分的標的,是從文字中,把和問題相關的部分突顯出來。

輸入是 ,輸出
,輸出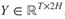 。現在要對整個文字建模,這個文字的特點是很長(long context),一般的 RNN 或者 LSTM 難以勝任這樣的任務,這裡採用一種基於張量變換的方法。
。現在要對整個文字建模,這個文字的特點是很長(long context),一般的 RNN 或者 LSTM 難以勝任這樣的任務,這裡採用一種基於張量變換的方法。

如果把 W 去掉,這個式子很好理解,V 的每一行代表一個的單詞,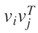 可以計算出兩個單詞的相關程度,然後再引入一個可訓練的引數 W,使得這個相關性的計算可訓練。還不夠,再讓這個計算重覆多次,取最大值,最後再歸一化。後面的實驗找到最佳 m 取值為 3 或 4。本文標題中的 Multi-factor 就是指這個 m。
可以計算出兩個單詞的相關程度,然後再引入一個可訓練的引數 W,使得這個相關性的計算可訓練。還不夠,再讓這個計算重覆多次,取最大值,最後再歸一化。後面的實驗找到最佳 m 取值為 3 或 4。本文標題中的 Multi-factor 就是指這個 m。
F̃ 是註意力權重,用它和 V 相乘,就能挑出需要註意哪些單詞了。
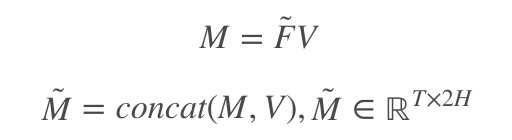
這裡可以認為是一種殘差結構,concat(x, f(x))。在網路結構設計時使用這種設計的好處是,如果 f 損害了 x 的表達性,旁路的 x 依然可以使用,這樣的網路更健壯。
還差一步,文中說,為了控制 M̃ 的影響,用 M̃ 和控制因子按元素相乘。這個控制因子是用一個一層的前饋神經網路計算得到。這裡面又有類似殘差的想法。
6. Question-focused Attentional Pointing
前面做了那麼多工作,都是為了得到 ,它表示文字每個單詞和問題以及和文字中其他詞的相關程度。最後要做的,是如何得到答案。這一步,再次使用了 question,所以叫做 question-focused。
,它表示文字每個單詞和問題以及和文字中其他詞的相關程度。最後要做的,是如何得到答案。這一步,再次使用了 question,所以叫做 question-focused。
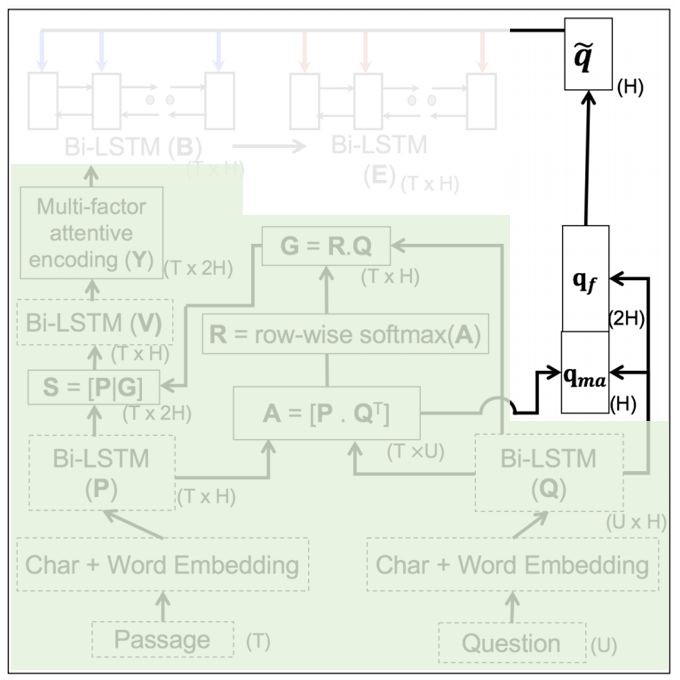
用註意力權重 A 找到 Q 中的關鍵詞 qma。再把問題的問句型別考慮進來,所謂的問句型別,指的是(what, who, how, when, which, where, why)裡面的哪個,如果都沒有,就取前兩個單詞,這樣計算得到 qf,然後把兩個 q 拼接,用神經元融合一下,這裡的神經元融合指的是 sigmoid 或 tanh(xW+b)。
最後,用兩個 BiLSTM 尋找最終要找的 b 和 e。

實驗
對比實驗
本文在 NewsQA,TriviaQA 和 SearchQA 資料集上進行對比實驗,實驗證明本文模型均比其他方法的效果好。
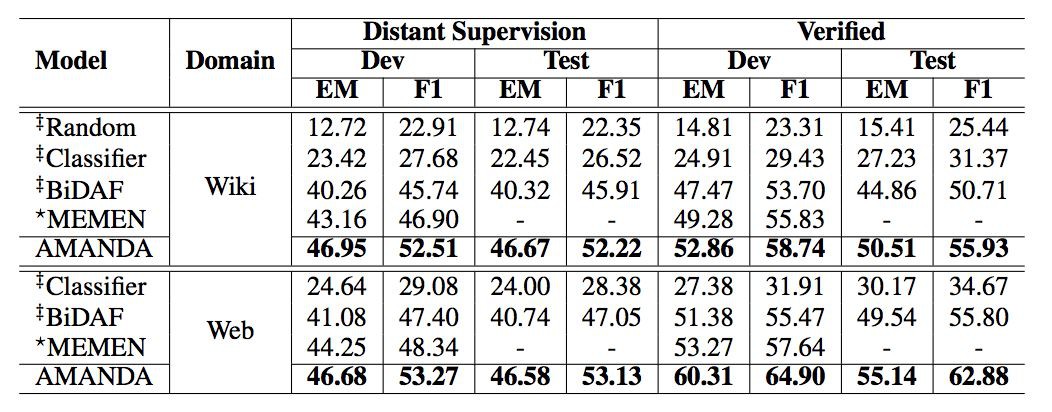
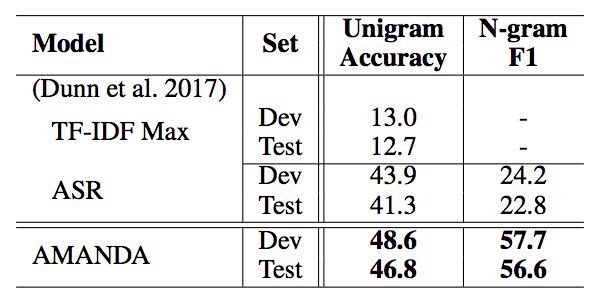
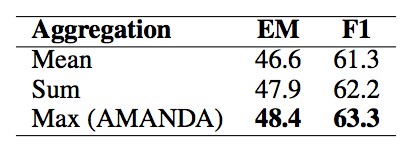
分析實驗
用實驗分析並驗證模型的每一個部分對結果的影響。



個人評價
本文模型真的有些複雜,有很多網路設計方法是值得學習的:
-
concat + 神經元融合
-
反覆使用“殘差”來設計網路
-
網路中引入張量
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文