去年的這個時候小編透過兩個月的複習拿到了阿裡巴巴的 offer,有一些運氣,也有一些心得,藉著跳槽季來臨特此分享出來。
簡單梳理一下我的複習思路,同時也希望和大家一起交流討論,一起學習,如果不對之處歡迎指正一起學習。本文即是複習思路,亦可當做學習思路。
我大致把 JAVA 的複習分為如下幾個方向。
JVM;
排序演演算法和 Java 集合&工具類;
多執行緒和併發包;
儲存相關:Redis 、Elastic Search、MySQL;
框架:Spring,SpringMVC,Spring Boot
分散式:Dubbo;
設計樣式;
下麵簡單說一下如何複習上面的知識,首先明確,小編不會講解具體的知識點,而是一個思路,縱觀網際網路上面的帖子、文章誤人子弟的多一些,所以就不誤人子弟了,而是推薦分析出知識點然後以看書為主。畢竟書是多方校對權威出版的讀物。
JVM
JVM 是每一個開發人員必備的技能,推薦看國內比較經典的 JVM 書籍,裡麵包含JVM的記憶體介面,類的載入機制等基礎知識,是不是覺得這些在面試中似曾相識?所以對於 JVM 方面的知識的鞏固與其在網上看一些零零碎碎的文章不如啃一下這本書。《深入理解 Java 虛擬機器:JVM 高階特性與最佳實踐(第 2 版)》,當然瞭如果你的英文好強烈推薦看 Oracle 最新釋出的 JAVA 虛擬機器規範。在啃書的時候切記不能圖快,你對知識的積累不是透過看書的數量來決定,而是看書的深度。所以在看每一章節的時候看到不懂的要配合網上的文章理解,並且需要看幾篇文章理解,因為一篇文章很可能是錯誤的,小編認為文章的可信度順序
自建域名>*.github.io>SF>簡書=部落格園>CSDN>轉載
排序演演算法和 Java 集合、工具類
這一個分類是每一個人必須掌握的並熟練使用的,那麼為什麼我把他們放在一起呢?
因為工具和集合類都源於演演算法,在準備演演算法複習之前你要理解,為什麼要必考演演算法。正式因為排序演演算法和我們程式設計息息相關。舉兩個“慄子”。
你可以看一下Collections 中的mergeSort和sort 方法,你會發現 mergeSort 就是歸併排序的實現,而 sort 方法結合了歸併排序和插入排序,這樣使得 sort 方法最差O(NlogN)最好可以達到O(N)的效果。那麼只有你自己理解了排序方法的實現,才能更好的使用 JAVA 中的集合類啊?
第二個“慄子”,大家都聽聞過 TopN 問題吧,經常在面試中遇到請寫一下 TopN 的實現,說到演演算法它就是一個大頂堆,說到 JAVA 它是一個 PriorityQueue 的實現,那麼你理解了 TopN 問題,知道他的時間複雜度,優缺點了,那麼是不是就可以熟練運用 JAVA 的工具類寫更高效的程式了?
之所以排序演演算法和 JAVA 集合&工具類 一樣重要是因為它們和我們每天的程式設計息息相關。面試官總是問排序演演算法也不是在難為你,而是在考察你的程式設計功底。所以你需要對著排序演演算法和基本的演演算法配合 JAVA 的集合類、工具類仔細的研究一番,這樣才能更深入的理解他們的關聯關係。
多執行緒和併發包
多執行緒和併發包,重要性就不累述了,直接說一下學習方法。你首先要理解多執行緒不僅僅是 Thread 和 Runnable 那麼簡單,整個併發包下麵的工具都是在為多執行緒服務。對於多執行緒的學習切不可看幾篇面試文章,或者幾個關鍵字 CountDownLatch,Lock 巴拉巴拉就以為理解了多執行緒的精髓,小編整理了一個大圖
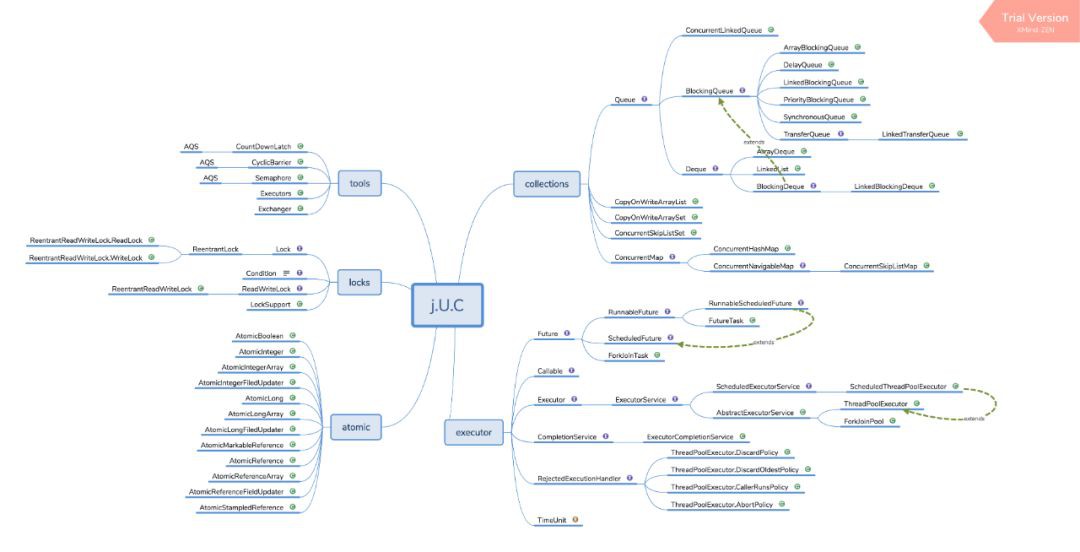
你需要針對這個大圖或者自己梳理一個大圖,對裡面的類各個擊破,他們的使用場景,優缺點。當然你需要配合原始碼看,原始碼就是大圖裡面的每一個原始碼,和上面講的 JVM 一樣,不要著急馬上看完,而是看懂每一個地方是為什麼。看的差不多你就會發現,其實他和 JAVA 集合類、工具類密不可分。那麼自然把它列為重要知識點的原因不言而喻。
Redis、MySQL、ElasticSearch
儲存相關相關都是我們平時常用的工具,Redis,MySQL,ElasticSearch。它的知識點分為兩方面,一方面是你平時使用過程中積累的經驗,另一方面是你對其的深入理解。所以對這個地方的建議就是透過書籍來鞏固技術知識, 《Redis設計與實現 (資料庫技術叢書)》,《高效能 MySQL》,《ElasticSearch 權威指南》這三本書不一定是該領域最好的書籍,但是如果你吃透了,對於你對知識的理解和程式的設計必定有很大幫助。書裡面的內容太多,還是舉兩個“慄子”。
第一個“慄子”,使用 Redis 切不可只用他當做 key-value 快取資料庫。小編瞭解到它的5種基本型別中一種型別叫做 sorted set。sorted set 裡 items 內容大於 64 的時候同時使用了 hash 和 skiplist 兩種設計實現。這也會為了排序和查詢效能做的最佳化。新增和刪除都需要修改 skiplist,所以複雜度為 O(log(n))。 但是如果僅僅是查詢元素的話可以直接使用 hash,其複雜度為 O(1) ,其他的 range 操作複雜度一般為 O(log(n)),當然如果是小於 64 的時候,因為是採用了 ziplist 的設計,其時間複雜度為 O(n)。這樣以後查詢和更新閱讀都變得簡單,那是不是可以用其實現 TopN 的需求呢?這樣類似的需求就不需要你查資料,再在記憶體裡面計算和操作了。比如我們簡單的周排行,月排行都可以考慮使用這個資料結構實現,當然並不一定這是最好的解決方案,而是提供了一種解題思路。
另一個“慄子”,PriorityQueue 是優先佇列我們上文已經瞭解,那麼 ElasticSearch 的 query 也是用的優先佇列分別在每一個分片上面獲取,然後再合併優先佇列你瞭解嗎?這個“慄子”告訴我們其實演演算法是想通的,你理解一個便可以舉一反三觸類旁通。
框架
一談框架就想起來 Spring,一說 Spring 就想起來 IOC,AOP。因為大家都在用這個框架,所以對於框架也不需要看一些其他的,直接就深入瞭解一下 Spring 就可以了。透過上面的敘述你已經瞭解了小編的思路,看什麼都要看他的實現原理,所以直接推薦你一本書《Spring 技術內幕》然後對著自己現有的 Spring 專案 Debug,從請求的流轉梳理知識點。Spring 出來這麼久大家對基本的知識已經瞭然於胸,重要的是看其解決問題的思路和原理,慄子又來了。
比如需要實現在 Bean 剛剛初始化的時候做一些操作,是不是需要使用InitializingBean?那麼具體怎麼使用,它的原理是什麼,Spring Bean 的生命週期是什麼樣子,透過具體的使用場景逐步展開說明。這樣複習效果會更好一些,然後再逐步的思考每一個知識點裡面涉及的更多的知識點,比如 AOP 裡面的 Proxy 都是基於什麼原理實現,有什麼優缺點。
分散式
這是一個老生常談的話題,也是這幾年比較火的話題,說起分散式就一定和 Dubbo 有關係,但是不能僅僅就理解到 Dubbo。首先我們需要思考它解決的問題,為什麼要引入 Dubbo 這個概念。隨著業務的發展、使用者量的增長,系統數量增多,呼叫依賴關係也變得複雜,為了確保系統高可用、高併發的要求,系統的架構也從單體時代慢慢遷移至服務SOA時代,應運而生的 Dubbo 出現了,它作為 RPC 的出現使得我們搭建微服務專案變得簡單,但是我們不僅僅要思考 Dubbo帶來的框架支撐。同時需要思考服務的冪等、分散式事務、服務之間的 Trace 定位、分散式日誌、資料對賬、重試機制等,與此同時考慮 MQ 對系統的解耦和壓力的分擔、資料庫分散式部署和分庫分表、限流、熔斷等機制。所以最終總結是不僅僅要看 Dubbo 的使用、原理同時還要思考上下游和一些系統設計的問題,這塊相對的知識點較多,可以針對上面丟擲來的點各個擊破。
設計樣式
設計樣式很多,但是常用的就幾種,這個地方可以分兩個地方準備。
-
學以致用,設計樣式不是背出來的,而是用出來了。平時多註意思考當前專案的設計,是否可以套用設計樣式,當然必須先理解每一個設計樣式存在的意義。
-
在現有框架中思考設計樣式的體現,上面已經講過框架怎麼學習,用 Spring 距離,它裡面用了超過9種設計樣式,你都知道用到哪裡了嗎?如果不知道,試著把他們找出來,同時思考為什麼這麼設計,全部找到以後,基本的設計樣式的用法和原理你也就都理解了。

