我是知乎技術中臺工程師,負責知乎儲存相關的元件。我的分享主要基於三個,第一,簡單介紹一下Kafka在知乎的應用,第二,為什麼做基於Kubernetes的Kafka平臺。第三,我們如何去實現基於Kubernetes的kafka平臺。
Kafka在知乎的應用
Kafka是一個非常優秀的訊息或者資料流的元件,在知乎承載了日誌、資料收集、訊息佇列等服務,包括執行的DEBUG日誌關鍵性日誌。比如我們在瀏覽知乎的時候,有些使用者行為或者內容特徵,會透過我們這個平臺做資料的流失處理。
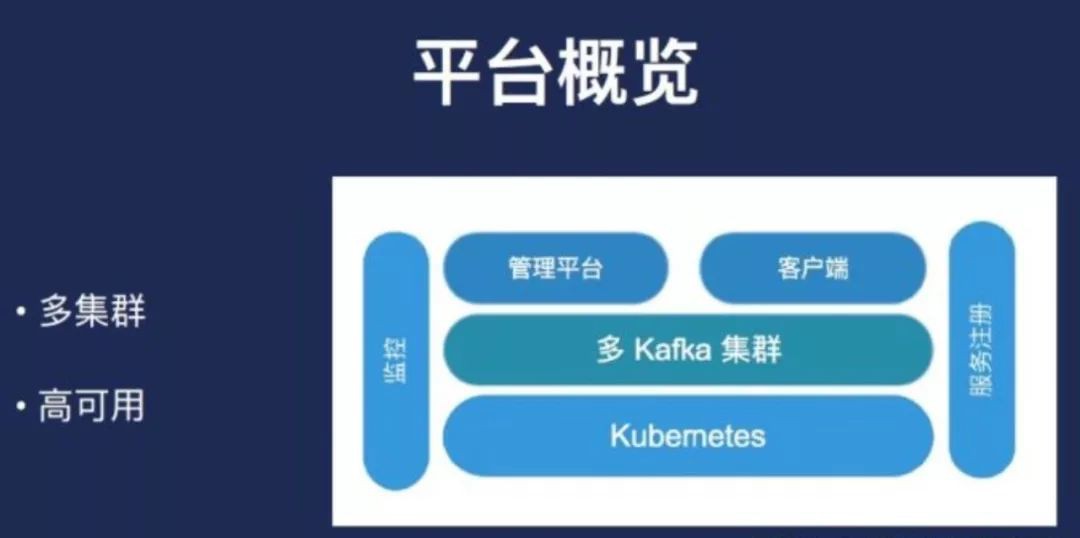
關於Kafka實現對訊息服務。簡單地來說,我關註的A使用者,是不是應該基於關註使用者行為上做很多事情,而是應該關註更多的訊息佇列。我們平臺現在部署有超過有40個Kafka叢集,這些叢集都是獨立的。另外叢集內部有超過一千個topic,我們有接近兩千的Broker數量。
平臺從上線到現在已經執行接近兩年,承載的資料量都是百TB級別。對於公司內部的平臺來說,我們必須要保證高可用。平臺架構底層是Broker管理,而上層是抽象出來的。關於平臺管理,建立topic、建立分割槽,或做故障處理。叢集對業務對來說,必須是無感狀態。
為什麼採用Kubernetes?
在早期的時候,知乎的Kafka只是一個單叢集,在大家使用率不高,資料量增長不爆炸的時候,單叢集還OK,但是有天發現有一個Broker掛了,所有業務同時爆炸,這時候才發現其實是一條路走下去是不行的。因為不管是業務也好,日誌也好,發訊息也罷,都會依賴我們這個單一的叢集。對於Kafka來,我們開發中有一個的Top的概念,每個topic都代表了不同的業務的場景,因此我們業務場景在內部要做分級,不重要的資料及重要的資料,我們如何做拆分。另外一方面,我們的業務怎麼能於Kafka做深度耦合?我們發現,我們的日誌裡topic有很多型別,第一種是日誌,剩下的是資料和訊息。為此我們需要把Kafka叢集在內部要做成多叢集的方式,從而根據我們top做出劃分。

比如一個A業務,每天有上百幾十T的資料,是不是可以申請一個新的Broker,新的叢集,別的資料並不會和新的資料攙和到一起,那這樣就會遇到一個問題,伺服器資源怎麼去使用?如何去分配?早期部署的時候肯定單機部署,暫定我用一臺伺服器,一臺伺服器暫定4T容量,這樣部署一個訊息任務是不是有點浪費?如何提升資源利用率,如歌從單機上部署更多的Broker,如何將影響降到最低?在實踐過程中,磁碟其實是Kafka一個繞不開的問題。
另一個問題是磁碟持久化的問題,在磁碟寫入量劇增的情況下,我們如何去處理磁碟也是一個非常大的難題。既然Broker可以做到不影響,那麼我們在物理層面是否可以將磁碟分開?接下來就是伺服器部署問題了,我們採用了騰訊雲的黑石伺服器,提供12個單磁碟介面,對管理這塊是我們非常好的!
底層伺服器搞定了,接下來是上層服務,這塊該怎麼做呢?知乎前期是自研了一個Kafka管理平臺,但是非常難用,新同事來了都需要從程式碼方面開始瞭解,所以我們決定使用Kubernetes。
Kafka on Kubernetes
首先解決問題設計Kafka容器,無非就是四個問題——記憶體,CPU,網路和儲存。另外一個問題是我們怎麼實現具體排程Kafka容器。

CPU是比較難以預估的,因為根據資訊型別不同,對於記憶體和CPU消耗是不同的,Kafka本身是不依賴於CPU。但是在實際使用中還是有些問題的,比如Kafka不適合做批次,假如延遲很高,如何保證每一條訊息都確切的投放過去,難道是把Brokers收得很小?這時候會造成一個什麼問題?CPU會高,但是很這種問題我們可以透過調高CPU來解決。如果不出現這種大流量的話,一般記憶體是不會超過八個G的。

另外網路方面就是我們對外服務,採用的是一種獨立的內網ip方式,比如我每一個Broker都有一個獨立的ip,實際上因為我們的單機上會部署很多容器,所以每個都有IP,並且將這個ip註冊在內網DNS上面,這樣照好處是對於使用者來說,不需要知道具體容器的ip。這個是網路又有一個很好的方式——可以做單機的多ip網路設計,至少可以滿足我們的需求,這是容器方面的設計。預設支援的磁碟的掛載方式是HostParh Volume,這種方式是最優的,因為Kafka在本地磁碟效能最好的,而且能夠充分利用到本地的這種高效的檔案快取,我們本身的磁碟效能也是非常棒的,至少我可以滿足我的需求。
因此我們就應該是本地的目錄一個cosplay,也就到K2起來之後是給他的,請求的配置掛載到伺服器的磁碟,黑色框是我們的一個容器,開發目錄指向的藍色框是伺服器上的一個磁碟或者伺服器上的目錄。雖然我們的叢集看來就是這個樣子的,每一個方塊代表網上有很多的部署的Broker。業務上面可以反過來看,每個藍色的地方代表Broker。
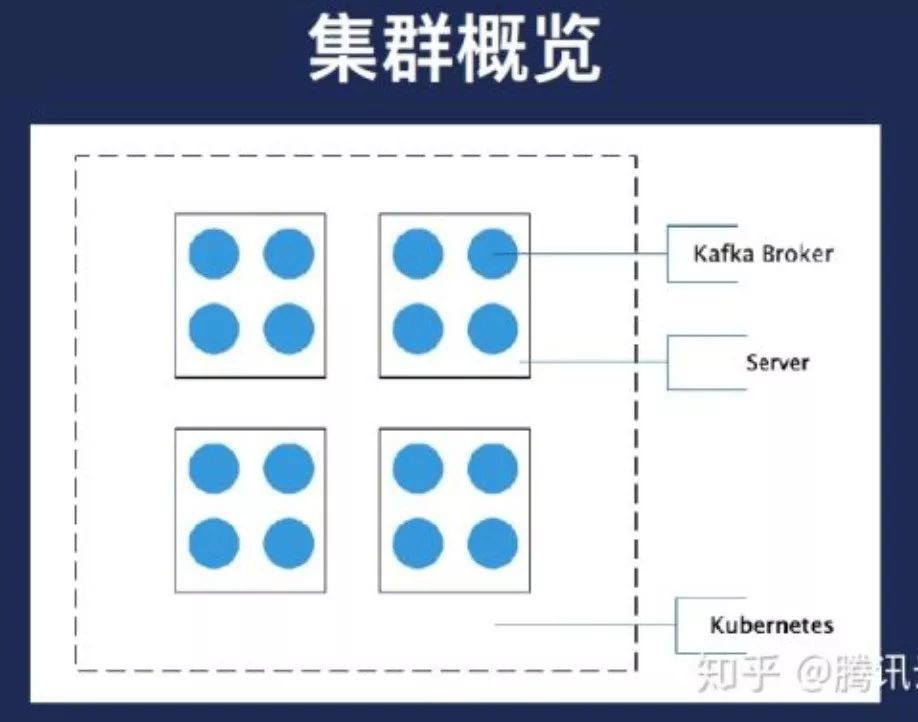
第一,CPU和記憶體並不是問題,網路其實已過測試過的,伺服器網路是二世紀的20G頻寬,每個盤我們經過測試,是有一點幾個G效能,即便把每個盤所有人都跑滿,其實這是災難情況,他只有不會超過20個G,因此我們不在考慮範圍之內,我們考慮的是磁碟的高可用標的,讓單個叢集的Broker在節點要儘量做到分散。
第二是節點上的儲存使用儘量均勻。
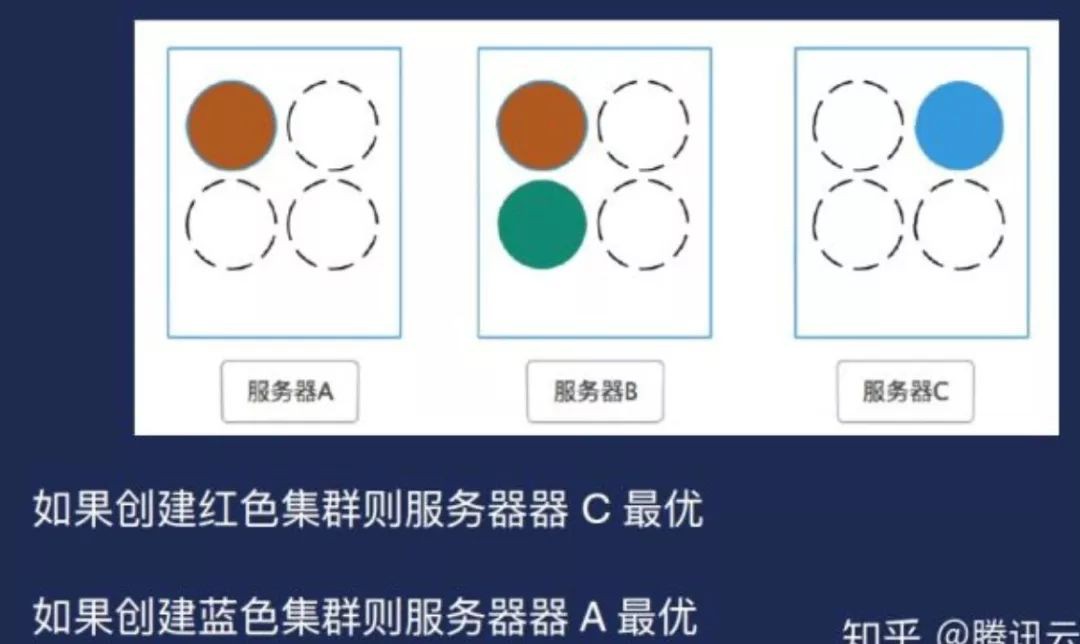
演演算法是根據伺服器磁碟狀態計算分數,分數高者被排程。另外就是磁碟的使用情況,如果有更多的可用盤,我們傾向於把Broker掛在了上面。其實它用了一個簡單的方式,假設建立一個紅色叢集,實際上A和C都可以,但C是最優的,因為C上面的Broker數比較少。如果要建立一個藍色叢集,那顯然是A是最優的。另外,在實際使用情況下要更複雜,因為得考慮到分片的高可用。按照演演算法去實現會遇到了一個實際性的問題——用HostPat是有很大侷限性,一致性不好,比如需要去管理要排程的節點,因為如果用class的話需要去註冊一個本身選擇的word,或者其實我是不知道被調到哪個節點上。另外主機上要去掛載的目錄其實是沒有人管理的。這是我們遇到的問題,當時我們希望是既要利用到HostPath,只有掛在本地的磁碟這種特性來提高我們的效能管理。
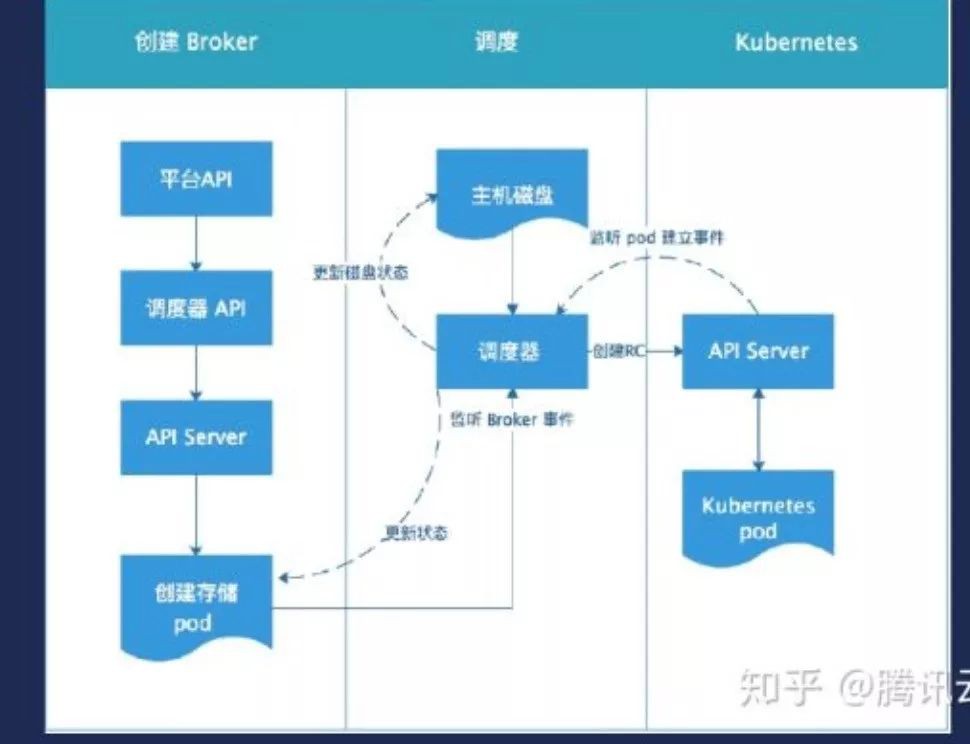
而且我要能夠選出合理節點,並且能夠管理到這個儲存。因此我們在當時對Kubernetes做改造,實現磁碟和排程器的演演算法,可以實現實時更新磁碟資訊。但是實現方式是透過假設建立實體.

本地磁碟管理
如果Broker已經在裝置上建立起來,磁碟也被用了,那如何去管理它?事實上磁碟管理只能進入第三方的Agent。

故障處理和提升資源利用時會預留空間,比如為了快速處理故障不做簽署,首先就是成本太高,現在做的是快速恢復,因此我們會預留1到2個盤,即快速處理盤,因此只要把軟體指向這個容器,就可以馬上啟用,並且不會有太大的網路開銷。另外就是在主機層面,即把分片在主機層面是做分開,做到高可用。

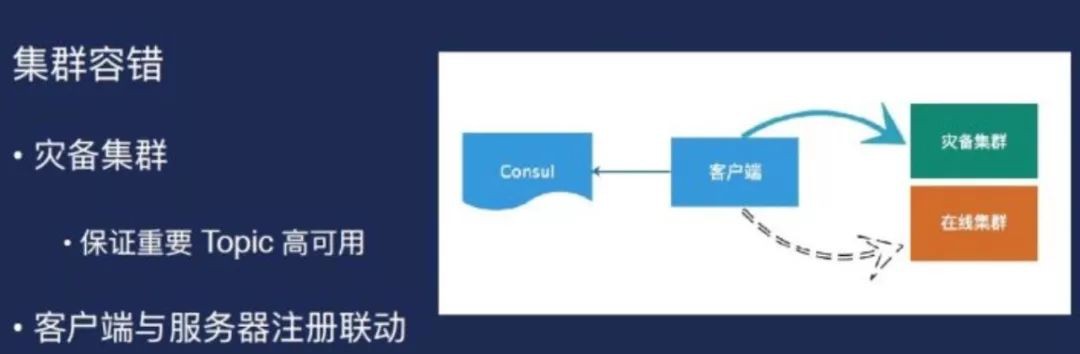
但我們遇到一個問題——需要把客戶端統一,因為技術平臺化。那如何把客戶端做到統一?我們的看這裡,客戶端可以去讀Consul資訊,檢查topic是不是有用。還有個好處是,如果做遷移的時候,因為事情使了很多方,生產和消費方式是很多的,而且一般流程是先於生產方,消費方就過來,大家可能有業務,可能大家如果按照這種註冊方式的話,其實遷移過程是可以同步的。在這個地方更改資訊,整個這個生產所生產的消費,都可以感受到,就是另外就是易用性會提高。且用這種方式有好處是有一個叢集比如我整個叢集全部斷掉了,雖然事沒發生過,但是作為一個備用的方式的話,我們會有一個災備叢集把所有的客戶端都可以直接遷移過去。
瞭解更多詳情,請戳下麵的連結:
[1] 知乎基於Kubernetes的Kafka平臺的設計和實現.pdf http://link.zhihu.com/?target=https%3A//ask.qcloudimg.com/draft/1184429/vz545uds4s.pdf
