(給資料分析與開發加星標,提升資料技能)
英文:Faizan Shaikh,翻譯:李文婧,轉自:資料派(ID:datapi)
引言
人類不會每聽到一個句子就對語言進行重新理解。看到一篇文章時,我們會根據之前對這些詞的理解來瞭解背景。我們將其定義為記憶力。
演演算法可以複製這種樣式嗎?神經網路(NN)是最先被想到的技術。但令人遺憾的是傳統的神經網路還無法做到這一點。 舉個例子,如果讓傳統的神經網路預測一個影片中接下來會發生什麼,它很難有精確的結果。
這就是迴圈神經網路(RNN)發揮作用的地方。迴圈神經網路在深度學習領域非常熱門,因此,學習迴圈神經網路勢在必行。迴圈神經網路在現實生活中的一些實際應用:
-
語音識別
-
機器翻譯
-
音樂創作
-
手寫識別
-
語法學習
在這篇文章中,我們首先對一個典型的迴圈神經網路模型的核心部分進行快速瀏覽。然後我們將設定問題陳述,最後我們將從零開始用Python構建一個迴圈神經網路模型解決這些問題陳述。
我們總是習慣用高階Python庫編寫迴圈神經網路。那為什麼還要從零開始編碼呢? 我堅信從頭學習是學習和真正理解一個概念的最佳方式。這就是我將在本教程中展示的內容。
本文假設讀者已對迴圈神經網路有基本的瞭解。如果您需要快速複習或希望學習迴圈神經網路的基礎知識,我建議您先閱讀下麵兩篇文章:
深度學習的基礎知識
https://www.analyticsvidhya.com/blog/2016/03/introduction-deep-learning-fundamentals-neural-networks/
迴圈神經網路簡介
https://www.analyticsvidhya.com/blog/2017/12/introduction-to-recurrent-neural-networks/
目錄
一、快速回顧:迴圈神經網路概念回顧
二、使用迴圈神經網路進行序列預測
三、使用Python構建迴圈神經網路模型
一、快速回顧:迴圈神經網路概念回顧
讓我們快速回顧一下迴圈神經網路的核心概念。我們將以一家公司的股票的序列資料為例。一個簡單的機器學習模型或人工神經網路可以根據一些特徵預測股票價格,比如股票的數量,開盤價值等。除此之外,該股票在之前的幾天和幾個星期的表現也影響著股票價格。對交易者來說,這些歷史資料實際上是進行預判的主要決定因素。
在傳統的前饋神經網路中,所有測試用例都被認為是獨立的。 在預測股價時,你能看出那不是一個合適的選擇嗎? 神經網路模型不會考慮之前的股票價格 – 這不是一個好想法!
面對時間敏感資料時,我們可以利用另一個概念 — 迴圈神經網路(RNN)!
典型的迴圈神經網路如下所示:
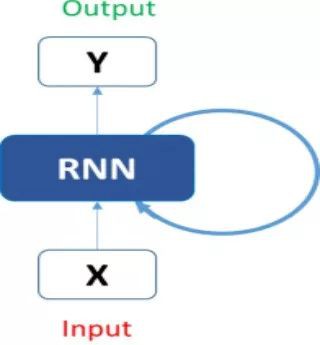
這剛開始看起來可能很嚇人。 但是如果我們展開來講,事情就開始變得更簡單:

現在,我們更容易想象出這些迴圈神經網路如何預測股票價格的走勢。這有助於我們預測當天的價格。這裡,有關時間t(h_t)的每個預測都需要依賴先前所有的預測和從它們那學習到的資訊。相當直截了當吧?
迴圈神經網路可以在很大程度上幫助我們解決序列處理問題。
文字是序列資料的另一個好例子。一旦給定文字之後,迴圈神經網路就可以預測出接下來將會出現的單詞或短語,這可將是非常有用的資產。我們希望我們的迴圈神經網路可以寫出莎士比亞的十四行詩!
現在,迴圈神經網路在涉及短或小的環境時非常棒。 但是為了能夠構建一個故事並記住它,我們的迴圈神經網路模型應該能理解序列背後的背景,就像人腦一樣。
二、使用迴圈神經網路進行序列預測
在本文中,我們將使用迴圈神經網路處理序列預測問題。對此最簡單的例子之一是正弦波預測。序列包含可見趨勢,使用啟髮式方式很容易解決。下麵就是正弦波的樣子:
我們首先從零開始設計一個迴圈神經網路解決這個問題。 我們的迴圈神經網路模型也應該得到很好地推廣,以便我們可以將其應用於其他序列問題。 我們將像這樣制定我們的問題:給定一個屬於正弦波的50個數字的序列,預測系列中的第51個數字。 是時候開啟你的Jupyter notebook(一個互動式筆記本,支援執行 40 多種程式語言)或你選擇的IDE(Integrated Development Environment,是一種程式設計軟體)!
三、使用Python編碼迴圈神經網路
第0步:資料準備
在做任何其他事情之前,資料準備是任何資料科學專案中不可避免的第一步。我們的網路模型期望資料是什麼樣的? 它將輸入長度為50的單個序列。所以輸入資料的形狀將是:
(number_of_records x length_of_sequence x types_of_sequences)
這裡,types_of_sequence是1,因為我們只有一種型別的序列—正弦波。
另一方面,每次記錄的輸出只有一個值。那就是輸入序列中的第51個值。 所以它的形狀將是:
(number_of_records x types_of_sequences) #where types_of_sequences is 1
讓我們深入研究這個程式碼。首先,匯入必要的庫:
%pylab inline
import math
建立像資料一樣的正弦波,我們將使用Python數學庫中的正弦函式:
sin_wave = np.array([math.sin(x) for x in np.arange(200)])
將剛剛生成的正弦波視覺化:
plt.plot(sin_wave[:50])

我們現在將在下麵的程式碼塊中建立資料:
X = []
Y = []
seq_len = 50
num_records = len(sin_wave) - seq_len
for i in range(num_records - 50):
X.append(sin_wave[i:i+seq_len])
Y.append(sin_wave[i+seq_len])
X = np.array(X)
X = np.expand_dims(X, axis=2)
Y = np.array(Y)
Y = np.expand_dims(Y, axis=1)
列印資料的形狀:
X.shape, Y.shape
((100, 50, 1), (100, 1))
請註意,我們迴圈(num_records – 50),是因為我們想要留出50條記錄作為驗證資料。現在我們可以建立這個驗證資料:
X_val = []
Y_val = []
for i in range(num_records - 50, num_records):
X_val.append(sin_wave[i:i+seq_len])
Y_val.append(sin_wave[i+seq_len])
X_val = np.array(X_val)
X_val = np.expand_dims(X_val, axis=2)
Y_val = np.array(Y_val)
Y_val = np.expand_dims(Y_val, axis=1)
第1步:為我們的迴圈神經網路模型建立架構
我們接來下的任務是將我們在迴圈神經網路模型中使用的所有必要變數和函式進行定義。我們的迴圈神經網路模型將接受輸入序列,透過100個單位的隱藏層處理它,並產生單值輸出:
learning_rate = 0.0001
nepoch = 25
T = 50 # length of sequence
hidden_dim = 100
output_dim = 1
bptt_truncate = 5
min_clip_value = -10
max_clip_value = 10
然後我們將定義網路的權重:
U = np.random.uniform(0, 1, (hidden_dim, T))
W = np.random.uniform(0, 1, (hidden_dim, hidden_dim))
V = np.random.uniform(0, 1, (output_dim, hidden_dim))
其中:
-
U是輸入和隱藏圖層之間權重的權重矩陣
-
V是隱藏層和輸出層之間權重的權重矩陣
-
W是迴圈神經網路層(隱藏層)中共享權重的權重矩陣
最後,我們將定義在隱藏層中使用S型函式:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
第2步:訓練模型
既然我們已經定義了模型,最後我們就可以繼續訓練我們的序列資料了。我們可以將訓練過程細分為更小的步驟,即:
步驟2.1:檢查訓練資料是否丟失
步驟2.1.1:前饋傳遞
步驟2.1.2:計算誤差
步驟2.2:檢查驗證資料是否丟失
步驟2.2.1前饋傳遞
步驟2.2.2:計算誤差
步驟2.3:開始實際訓練
步驟2.3.1:正推法
步驟2.3.2:反向傳遞誤差
步驟2.3.3:更新權重
我們需要重覆這些步驟直到資料收斂。 如果模型開始過擬合,請停止! 或者只是預先定義epoch的數量。
-
步驟2.1:檢查訓練資料是否丟失
我們將透過我們的迴圈神經網路模型進行正推法,並計算所有記錄的預測的平方誤差,以獲得損失值。
for epoch in range(nepoch):
# check loss on train
loss = 0.0
# do a forward pass to get prediction
for i in range(Y.shape[0]):
x, y = X[i], Y[i] # get input, output values of each record
prev_s = np.zeros((hidden_dim, 1)) # here, prev-s is the value of the previous activation of hidden layer; which is initialized as all zeroes
for t in range(T):
new_input = np.zeros(x.shape) # we then do a forward pass for every timestep in the sequence
new_input[t] = x[t] # for this, we define a single input for that timestep
mulu = np.dot(U, new_input)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
# calculate error
loss_per_record = (y - mulv)**2 / 2
loss += loss_per_record
loss = loss / float(y.shape[0])
-
步驟2.2:檢查驗證資料是否丟失
我們將對計算驗證資料的損失做同樣的事情(在同一迴圈中):
# check loss on val
val_loss = 0.0
for i in range(Y_val.shape[0]):
x, y = X_val[i], Y_val[i]
prev_s = np.zeros((hidden_dim, 1))
for t in range(T):
new_input = np.zeros(x.shape)
new_input[t] = x[t]
mulu = np.dot(U, new_input)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
loss_per_record = (y - mulv)**2 / 2
val_loss += loss_per_record
val_loss = val_loss / float(y.shape[0])
print('Epoch: ', epoch + 1, ', Loss: ', loss, ', Val Loss: ', val_loss)
你應該會得到以下輸出:
Epoch: 1 , Loss: [[101185.61756671]] , Val Loss: [[50591.0340148]]
…
…
-
步驟2.3:開始實際訓練
現在我們開始對網路進行實際訓練。在這裡,我們首先進行正推法計算誤差,然後使用逆推法來計算梯度並更新它們。讓我逐步向您展示這些內容,以便您可以直觀地瞭解它的工作原理。
-
步驟2.3.1:正推法
正推法步驟如下:
我們首先將輸入與輸入和隱藏層之間的權重相乘;
在迴圈神經網路層中新增權重乘以此項,這是因為我們希望獲取前一個時間步的內容;
透過sigmoid 啟用函式將其與隱藏層和輸出層之間的權重相乘;
在輸出層,我們對數值進行線性啟用,因此我們不會透過啟用層傳遞數值;
在字典中儲存當前圖層的狀態以及上一個時間步的狀態。
這是執行正推法的程式碼(請註意,它是上述迴圈的繼續):
# train model
for i in range(Y.shape[0]):
x, y = X[i], Y[i]
layers = []
prev_s = np.zeros((hidden_dim, 1))
dU = np.zeros(U.shape)
dV = np.zeros(V.shape)
dW = np.zeros(W.shape)
dU_t = np.zeros(U.shape)
dV_t = np.zeros(V.shape)
dW_t = np.zeros(W.shape)
dU_i = np.zeros(U.shape)
dW_i = np.zeros(W.shape)
# forward pass
for t in range(T):
new_input = np.zeros(x.shape)
new_input[t] = x[t]
mulu = np.dot(U, new_input)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
layers.append({'s':s, 'prev_s':prev_s})
prev_s = s
-
步驟2.3.2:反向傳播誤差
在前向傳播步驟之後,我們計算每一層的梯度,並反向傳播誤差。 我們將使用截斷反向傳播時間(TBPTT),而不是vanilla backprop(反向傳播的非直觀效應的一個例子)。這可能聽起來很複雜但實際上非常直接。
BPTT與backprop的核心差異在於,迴圈神經網路層中的所有時間步驟,都進行了反向傳播步驟。 因此,如果我們的序列長度為50,我們將反向傳播當前時間步之前的所有時間步長。
如果你猜對了,那麼BPTT在計算上看起來非常昂貴。 因此,我們不是反向傳播所有先前的時間步,而是反向傳播直到x時間步以節省計算能力。考慮這在概念上類似於隨機梯度下降,我們包括一批資料點而不是所有資料點。
以下是反向傳播誤差的程式碼:
# derivative of pred
dmulv = (mulv - y)
# backward pass
for t in range(T):
dV_t = np.dot(dmulv, np.transpose(layers[t]['s']))
dsv = np.dot(np.transpose(V), dmulv)
ds = dsv
dadd = add * (1 - add) * ds
dmulw = dadd * np.ones_like(mulw)
dprev_s = np.dot(np.transpose(W), dmulw)
for i in range(t-1, max(-1, t-bptt_truncate-1), -1):
ds = dsv + dprev_s
dadd = add * (1 - add) * ds
dmulw = dadd * np.ones_like(mulw)
dmulu = dadd * np.ones_like(mulu)
dW_i = np.dot(W, layers[t]['prev_s'])
dprev_s = np.dot(np.transpose(W), dmulw)
new_input = np.zeros(x.shape)
new_input[t] = x[t]
dU_i = np.dot(U, new_input)
dx = np.dot(np.transpose(U), dmulu)
dU_t += dU_i
dW_t += dW_i
dV += dV_t
dU += dU_t
dW += dW_t
-
步驟2.3.3:更新權重
最後,我們使用計算的權重梯度更新權重。 有一件事我們必須記住,如果不對它們進行檢查,梯度往往會爆炸。這是訓練神經網路的一個基本問題,稱為梯度爆炸問題。 所以我們必須將它們夾在一個範圍內,這樣它們就不會增長得太快。 我們可以這樣做:
if dU.max() > max_clip_value:
dU[dU > max_clip_value] = max_clip_value
if dV.max() > max_clip_value:
dV[dV > max_clip_value] = max_clip_value
if dW.max() > max_clip_value:
dW[dW > max_clip_value] = max_clip_value
if dU.min() < min_clip_value:
dU[dU < min_clip_value] = min_clip_value
if dV.min() < min_clip_value:
dV[dV < min_clip_value] = min_clip_value
if dW.min() < min_clip_value:
dW[dW < min_clip_value] = min_clip_value
# update
U -= learning_rate * dU
V -= learning_rate * dV
W -= learning_rate * dW
在訓練上述模型時,我們得到了這個輸出:
Epoch: 1 , Loss: [[101185.61756671]] , Val Loss: [[50591.0340148]]
Epoch: 2 , Loss: [[61205.46869629]] , Val Loss: [[30601.34535365]]
Epoch: 3 , Loss: [[31225.3198258]] , Val Loss: [[15611.65669247]]
Epoch: 4 , Loss: [[11245.17049551]] , Val Loss: [[5621.96780111]]
Epoch: 5 , Loss: [[1264.5157739]] , Val Loss: [[632.02563908]]
Epoch: 6 , Loss: [[20.15654115]] , Val Loss: [[10.05477285]]
Epoch: 7 , Loss: [[17.13622839]] , Val Loss: [[8.55190426]]
Epoch: 8 , Loss: [[17.38870495]] , Val Loss: [[8.68196484]]
Epoch: 9 , Loss: [[17.181681]] , Val Loss: [[8.57837827]]
Epoch: 10 , Loss: [[17.31275313]] , Val Loss: [[8.64199652]]
Epoch: 11 , Loss: [[17.12960034]] , Val Loss: [[8.54768294]]
Epoch: 12 , Loss: [[17.09020065]] , Val Loss: [[8.52993502]]
Epoch: 13 , Loss: [[17.17370113]] , Val Loss: [[8.57517454]]
Epoch: 14 , Loss: [[17.04906914]] , Val Loss: [[8.50658127]]
Epoch: 15 , Loss: [[16.96420184]] , Val Loss: [[8.46794248]]
Epoch: 16 , Loss: [[17.017519]] , Val Loss: [[8.49241316]]
Epoch: 17 , Loss: [[16.94199493]] , Val Loss: [[8.45748739]]
Epoch: 18 , Loss: [[16.99796892]] , Val Loss: [[8.48242177]]
Epoch: 19 , Loss: [[17.24817035]] , Val Loss: [[8.6126231]]
Epoch: 20 , Loss: [[17.00844599]] , Val Loss: [[8.48682234]]
Epoch: 21 , Loss: [[17.03943262]] , Val Loss: [[8.50437328]]
Epoch: 22 , Loss: [[17.01417255]] , Val Loss: [[8.49409597]]
Epoch: 23 , Loss: [[17.20918888]] , Val Loss: [[8.5854792]]
Epoch: 24 , Loss: [[16.92068017]] , Val Loss: [[8.44794633]]
Epoch: 25 , Loss: [[16.76856238]] , Val Loss: [[8.37295808]]
看起來不錯!是時候進行預測並繪製它們以獲得我們設計的視覺感受。
第3步:獲得預測
我們將透過訓練的權重利用正推法獲得預測:
preds = []
for i in range(Y.shape[0]):
x, y = X[i], Y[i]
prev_s = np.zeros((hidden_dim, 1))
# Forward pass
for t in range(T):
mulu = np.dot(U, x)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
preds.append(mulv)
preds = np.array(preds)
將這些預測與實際值一起繪製:
plt.plot(preds[:, 0, 0], 'g')
plt.plot(Y[:, 0], 'r')
plt.show()

這是有關培訓資料的。 我們怎麼知道我們的模型是不是過擬合? 這就是我們之前建立的驗證集發揮作用的時候:
preds = []
for i in range(Y_val.shape[0]):
x, y = X_val[i], Y_val[i]
prev_s = np.zeros((hidden_dim, 1))
# For each time step...
for t in range(T):
mulu = np.dot(U, x)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
preds.append(mulv)
preds = np.array(preds)
plt.plot(preds[:, 0, 0], 'g')
plt.plot(Y_val[:, 0], 'r')
plt.show()
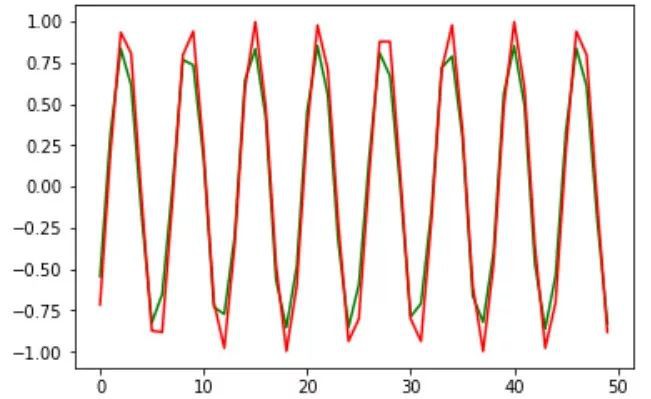
不錯。 預測看起來令人印象深刻。 驗證資料的均方根誤差分數也是可以接受的:
from sklearn.metrics import mean_squared_error
math.sqrt(mean_squared_error(Y_val[:, 0] * max_val, preds[:, 0, 0] * max_val))
0.127191931509431
總結
在處理序列資料時,我沒有足夠強調迴圈神經網路多麼有用。 我懇請大家學習並將其應用於資料集。 嘗試去解決NLP問題,看看是否可以找到解決方案。 如果您有任何疑問,可以隨時透過以下評論部分與我聯絡。
在本文中,我們學習瞭如何使用numpy庫從零開始建立迴圈神經網路模型。 您也可以使用像Keras或Caffe這樣的高階庫,但瞭解您正在實施的概念至關重要。
