來自:illy安智 的部落格
https://my.oschina.net/u/1782938/blog/1812240
大資料時代,企業對於DBA也提出更高的需求。同時,NoSQL作為近幾年新崛起的一門技術,也受到越來越多的關註。本文將基於個推SRA孟顯耀先生所負責的DBA工作,和大資料運維相關經驗,分享兩大方向內容:一、公司在KV儲存上的架構演進以及運維需要解決的問題;二、對NoSQL如何選型以及未來發展的一些思考。
據官方統計,截止目前(2018年4月20日)NoSQL有225個解決方案,具體到每個公司,使用的都是其中很小的一個子集,下圖中藍色標註的產品是當前個推正在使用的。

NoSQL 的由來
1946年,第一臺通用計算機誕生。但一直到1970年RDMBS的出現,大家才找到通用的資料儲存方案。到21世紀,DT時代讓資料容量成為最棘手的問題,對此谷歌和亞馬遜分別提出了自己的NoSQL解決方案,比如谷歌於2006年提出了Bigtable。2009年的一次技術大會上,NoSQL一詞被正式提出,到現在共有225種解決方案。
NoSQL與RDMBS的區別主要在兩點:第一,它提供了無樣式的靈活性,支援很靈活的樣式變更;第二,可伸縮性,原生的RDBMS只適用於單機和小叢集。而NoSQL一開始就是分散式的,解決了讀寫和容量擴充套件性問題。以上兩點,也是NoSQL產生的根本原因。
實現分散式主要有兩種手段:副本(Replication)和分片(Sharding)。Replication能解決讀的擴充套件性問題和HA(高可用),但是無法解決讀和容量的擴充套件性。而Sharding可以解決讀寫和容量的擴充套件性。一般NoSQL解決方案都是將二者組合起來。
Sharding主要解決資料的劃分問題,主要有基於區間劃分(如Hbase的Rowkey劃分)和基於雜湊的劃分。為瞭解決雜湊分散式的單調性和平衡性問題,目前業內主要使用虛擬節點。後文所述的Codis也是用虛擬節點。虛擬節點相當於在資料分片和託管伺服器之間建立了一層虛擬對映的關係。
目前,大家主要根據資料模型和訪問方式進行NoSQL分類。
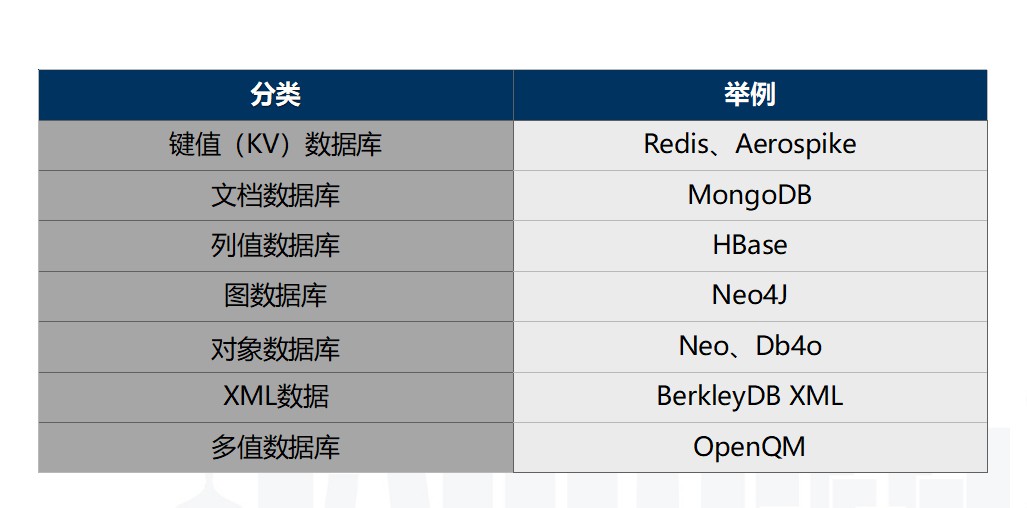
個推常用的幾種 NoSQL 解決方案
個推Redis系統規模如下圖。下麵介紹一下運維過程遇到的幾個問題。

首先是技術架構演進過程。個推以面向APP開發者提供訊息推送服務起家,在2012年之前,個推的業務量相對較小,當時我們用Redis做快取,用MySQL做持久化。在2012-2016年,隨著個推業務的高速發展,單節點已經無法解決問題。在MySQL無法解決高QPS、TPS的情況下,我們自研了Redis分片方案。
此外,我們還自研了Redis客戶端,用它來實現基本的叢集功能,支援自定義讀寫比例,同時對故障節點的監測和隔離、慢監控以及每個節點健康性進行檢查。但這種架構沒有過多考慮運維效率的問題,缺少運維工具。
當我們計劃完善運維工具的時候,發現豌豆莢團隊將Codis開源,給我們提供了一個不錯的選項。
個推 Codis+ 的優勢
Codis是proxy-based架構,支援原生客戶端,支援基於web的叢集操作和監控,並且也集成了Redis Sentinel。可以提高我們運維的工作效率,且HA也更容易落地。
但是在使用過程中,我們也發現一些侷限。因此我們提出了Codis+,即對Codis做一些功能增強。
第一、 採用2N+1副本方案,解決故障期間Master單點的問題。
第二、Redis準半同步。設定一個閾值,比如slave僅在5秒鐘之內可讀。
第三、資源池化。能透過類似HBase增加RegionServer的方式去進行資源擴容。
此外,還有機架感知功能和跨IDC的功能。Redis本身是為了單機房而設定的,沒有考慮到這些問題。
那麼,為什麼我們不用原生的rRedis cluster?這裡有三個原因:一、原生的叢集,它把路由轉發的功能和實際上的資料管理功能耦合在一個功能裡,如果一個功能出問題就會導致資料有問題;二、在大叢集時,P2P的架構達到一致性狀態的過程比較耗時,codis是樹型架構,不存在這個問題。三、叢集沒有經過大平臺的背書。
此外,關於Redis,我們最近還在看一個新的NoSQL方案Aerospike,我們對它的定位是替換部分叢集Redis。Redis的問題在於資料常駐記憶體,成本很高。我們期望利用Aerospike減少TCO成本。Aerospike有如下特性:
一、Aerospike資料可以放記憶體,也可以放SSD,並對SSD做了最佳化。
二、資源池化,運維成本繼續降低。
三、支援機架感知和跨IDC的同步,但這屬於企業級版本功能。
目前我們內部現在有兩個業務在使用Aerospike,實測下來,發現單臺物理機搭載單塊Inter SSD 4600,可以達到接近10w的QPS。對於容量較大,但QPS要求不高的業務,可以選擇Aerospike方案節省TCO。
在NoSQL演進的過程中,我們也遇到一些運維方面的問題。
標準化安裝
我們共分了三個部分:OS標準化、Redis檔案和目錄標準、Redis引數標準化,全部用saltstack + cmdb實現;
擴容和縮容
在技術架構不斷演進過程中,擴容和縮容的難度也在變低,原因之一在於codis緩解了一部分問題。當然,如果選擇Aerospike,相關操作就會非常輕鬆。
做好監控,降低運維成本
大部分的運維同學都應該認真閱讀《SRE:Google運維揭秘》,它在理論層面和實踐層面提出了很多非常有價值的方法論,強烈推薦。
個推 Redis 監控複雜性
三種叢集架構:自研、codis2和codis3,這三種架構採集資料的方式並不相同。
三類監控物件:叢集、實體、主機,需要有元資料維護邏輯關係,併在全域性做聚合。
三種個性化配置:個推的Redis叢集,有的叢集需要有多副本,有的不需要。有的節點允許滿做快取,有的節點不允許滿。還有持久化策略,有的不做持久化,有的做持久化,有的做持久化+異地備份,這些業務特點對我們監控靈活性提出很高的要求。
Zabbix是一個非常完備的監控系統,約三年多的時間裡,我都把它作為主要的監控系統平臺。但是它有兩個缺陷:一是它使用MySQL作為後端儲存,TPS有上限;二是不夠靈活。比如:一個叢集放在一百臺機器上,要做聚合指標,就很困難。
小米的open-falcon解決了這個問題,但是也會產生一些新問題。比如告警函式很少,不支援字串,有時候會增加手工的操作等等。後來我們對它進行功能性補充,便沒有遇到大的問題。
下圖是個推運維平臺。

第一個是IT硬體資源平臺,主要維護主機維度的物理資訊。比如說主機在哪個機架上接的哪個交換機,在哪個機房的哪一個樓層等等,這是做機架感知和跨IDC等等的基礎。
第二個是CMDB,這個是維護主機上的軟體資訊,主機上裝了哪些實體,實體屬於哪些叢集,我們用了哪些埠,這些叢集有什麼個性化的引數配置,包括告警機制不一樣,全是透過CMDB實現。CMDB的資料消費方包含grafana監控系統和監控採集程式,採集程式由我們自己開發。這樣CMDB資料會活起來。如果只是一個靜態資料沒有消費方,資料就會不一致。
grafana監控系統聚合了多個IDC資料,我們運維每天只需看一下大屏就夠了。
Slatstack,用於實現自動化釋出,實現標準化並提高工作效率。
採集程式是我們自行研發的,針對公司的業務特點定製化程度很高。還有ELK(不用logstach,用filebeat)做日誌中心。
透過以上這些,我們搭建出個推整個監控體系。
下麵講一下搭建過程中遇到的幾個坑。
一、主從重置,會導致主機節點壓力爆增,主節點無法提供服務。
主從重置有很多原因。
Redis版本低,主從重置的機率很高。Redis3主從重置的機率比Redis2大大減少,Redis4支援節點重啟以後也能增量同步,這是Redis本身進行了很多改進。
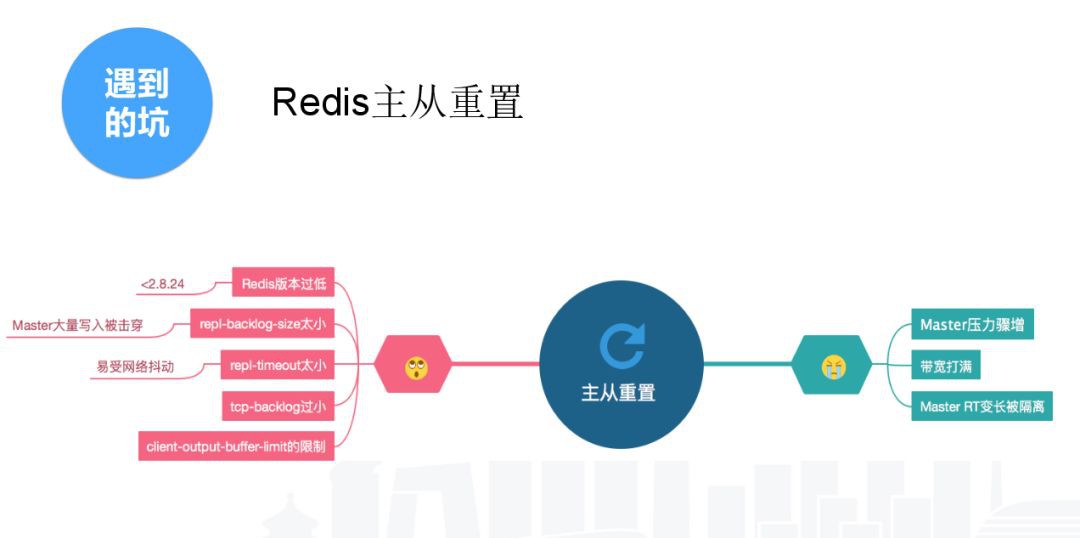
我們現在主要使用的是2.8.20,屬於比較容易能產生主從重置。
Redis的主從重置一般是觸發瞭如下條件中的一個。
1、repl-backlog-size太小,預設是1M,如果你有大量的寫入,很容易擊穿這個緩衝區;2、repl-timeout,Redis主從預設每十秒鐘ping一次,60秒鐘ping不推就會主從重置,原因可能是網路抖動、總節點壓力過大,無法響應這個包等;3、tcp-baklog,預設是511。作業系統的預設是限制到128,這個可以適度提高,我們提高到2048,這個能對網路丟包現象進行一定容錯。
以上都是導致主從重置的原因,主從重置的後果很嚴重。Master壓力爆增無法提供服務,業務就把這個節點定為不可用。響應時間變長 Master所在所有主機的節點都會受到影響。
二、節點過大,部分是人為原因造成的。
第一是拆分節點的效率較低,遠遠慢於公司業務量的增長。此外,分片太少。我們的分片是500個,codis是1024,codis原生是16384個,分片太少也是個問題。如果做自研的分散式方案,大家一定要把分片數量,稍微設大一點,避免業務發展超過你預期的情況。節點過大之後,會導致持久化的時間增長。我們30G的節點要持久化,主機剩餘記憶體要大於30G,如果沒有,你用Swap導致主機持久化時間大幅增長。一個30G的節點持久化可能要4個小時。負載過高也會導致主從重置,引起連鎖反應。

關於我們遇到的坑,接下來分享幾個實際的案例。
第一個案例是一次主從重置。這個情況是在春節前兩天出現的,春節前屬於訊息推送業務高峰期。我們簡單還原一下故障場景。首先是大規模的訊息下發導致負載增加;然後,Redis Master壓力增大,TCP包積壓,OS產生丟包現象,丟包把Redis主從ping的包給丟了,觸發了repl-timeout 60秒的閾值,主從就重置了。同時由於節點過大,導致Swap和IO飽和度接近100%。解決的方法很簡單,我們先把主從斷開。故障原因首先是引數不合理,大都是預設值,其次是節點過大讓故障效果進行放大。
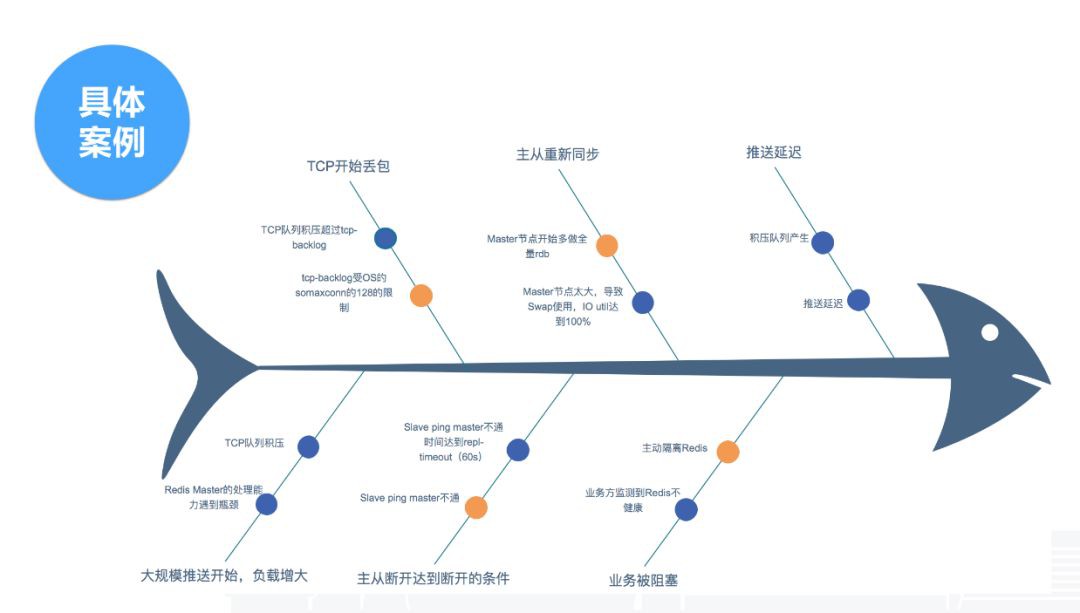
第二個案例是codis最近遇到的一個問題。這是一個典型的故障場景。一臺主機掛掉後,codis開啟了主從切換,主從切換後業務沒有受影響,但是我們去重新接主從時發現接不上,接不上就報了錯。這個錯也不難查,其實就是引數設定過小,也是由於預設值導致。Slave從主節點拉資料的過程中,新增資料留在Master緩衝區,如果Slave還沒拉完,Master緩衝區就超過上限,就會導致主從重置,進入一個死迴圈。

基於這些案例,我們整理了一份最佳實踐。

一、配置CPU親和。Redis是單機點的結構,不親和會影響CPU的效率。
二、節點大小控制在10G。
三、主機剩餘記憶體最好大於最大節點大小+10G。主從重置需要有同等大小的記憶體,這個一定要留夠,如果不留夠,用了Swap,就很難重置成功。
四、儘量不要用Swap。500毫秒響應一個請求還不如掛掉。
五、tcp-backlog、repl-backlog-size、repl-timeout適度增大。
六、Master不做持久化,Slave做AOF+定時重置。
最後是個人的一些思考和建議。選擇適合自己的NoSQL,選擇原則有五點:
1、業務邏輯。首先要瞭解自身業務特點,比如是KV型就在KV裡面找;如果是圖型就在圖型裡找,這樣範圍一下會減少70%-80%。
2、負載特點,QPS、TPS和響應時間。在選擇NoSQL方案時,可以從這些指標去衡量,單機在一定配置下的效能指標能達到多少?Redis在主機足夠剩餘情況下,單臺的QPS40-50萬是完全OK的。
3、資料規模。資料規模越大,需要考慮的問題就越多,選擇性就越小。到了幾百個TB或者PB級別,幾乎沒太多選擇,就是Hadoop體系。
4、運維成本和可不可監控,能否方便地進行擴容、縮容。
5、其它。比如有沒有成功案例,有沒有完善的檔案和社群,有沒有官方或者企業支援。可以讓別人把坑踩過之後我們平滑過去,畢竟自己踩坑的成本還是蠻高的。
結語:關於NoSQL的釋義,網路上曾有一個段子:從1980年的know SQL,到2005年的Not only SQL,再到今日的No SQL!網際網路的發展伴隨著技術概念的更新與相關功能的完善。而技術進步的背後,則是每一位技術人的持續的學習、周密的思考與不懈的嘗試。
●編號334,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
