來自:不該相遇在秋天
連結:http://www.cnblogs.com/fengyumeng/p/9888148.html
慢查詢日誌 開啟撒網樣式
開啟了MySQL慢查詢日誌之後,MySQL會自動將執行時間超過指定秒數的SQL統統記錄下來,這對於搜羅線上慢SQL有很大的幫助。
SHOW VARIABLES LIKE ‘slow%’
以我剛安裝的mysql5.7為例 查詢結果是這樣子的:

slow_launch_time:表示如果建立執行緒花費了比這個值更長的時間,slow_launch_threads 計數器將增加
slow_query_log:是否開啟慢查詢日誌 ON開啟,OFF關閉 預設沒有開啟
slow_query_log_file:日誌儲存路徑
SHOW VARIABLES LIKE ‘long%’

long_query_time:達到多少秒的sql就記錄日誌
客戶端可以用set設定變數的方式讓慢查詢開啟,但是個人不推薦,因為真實操作起來會有一些問題,比如說,重啟MySQL後就失效了,或者是開啟了慢查詢,我又去改變數值,它就不生效了。
編輯MySQL的配置檔案:
vim /etc/my.cnf
加入如下三行:
slow_query_log=ON
slow_query_log_file=/var/lib/mysql/localhost–centos–slow.log
long_query_time=3
我這裡設定的是3秒
重啟MySQL
systemctl restart mysqld;
伺服器開一個監控:
tail -f /var/lib/mysql/localhost-centos-slow.log
客戶端走一條SQL:
SELECT SLEEP(3)
此時發現sql已經被記錄到日誌裡了。(有時候不一定,我看到很多部落格講的是超過指定秒數,但我實驗得出的結果是達到指定秒數)
EXPLAIN 點對點分析
explain是一個神奇的命令,可以檢視sql的具體的執行計劃。
以一條聯查sql為例:
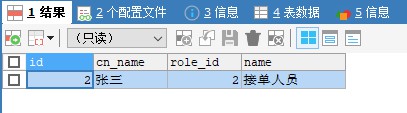
SELECT a.id,a.cn_name,a.role_id,r.name
FROM tb_usr_admins a
INNER JOIN tb_base_roles r ON r.id=a.role_id
WHERE a.cn_name=“接單人員”
查詢結果是:
加上explain命令來執行:
EXPLAIN
SELECT a.id,a.cn_name,a.role_id,r.name
FROM tb_usr_admins a
INNER JOIN tb_base_roles r ON r.id=a.role_id
WHERE a.cn_name=“接單人員”
查詢結果是:

這就是這條SQL的執行計劃,下麵來說明一下這個執行計劃怎麼看
id:代表優先順序 id值越大,越先執行,id值相同,從上往下執行。(比如示例的這條sql的執行計劃,就是先執行第一行,再執行第二行)
select_type:表示select型別 取值如下
- simple 簡單表 即不使用表連線或者子查詢
- primary 包含union或者子查詢的主查詢 即外層的查詢
- union UNION中的第二個或者後面的查詢陳述句
- subquery 一般子查詢中的子查詢被標記為subquery,也就是位於select串列中的查詢
- derived 派生表 該臨時表是從子查詢派生出來的
- 等等
type:表示MySQL在表中查詢資料的方式,或者叫訪問型別,以下對於type取值的說明 從上往下效能由最差到最好
- all:全表掃描,MySQL遍歷全表來找到匹配的行
- index:索引全掃描,MySQL遍歷掙個索引來查詢匹配的行
- range:索引範圍掃描,常見於、>=、between等運運算元
- ref:使用非唯一索引或唯一索引的字首掃描,傳回匹配的單行資料
- eq_ref:類似ref,區別就在於使用的索引是唯一索引,簡單來說,就是多表連線中使用primary key或者unique index作為關聯條件。
- const/system:單表中最多有一個匹配行,查詢起來非常迅速,常見於根據primary key或者唯一索引unique index進行的單表查詢
- null:mysql不用訪問表或者索引,直接就能夠得到查詢的結果,例如select 1+2 as result。
possible_keys:表示查詢時可能使用的索引
key:表示實際使用的索引
key_len:使用到索引欄位的長度
rows:掃描數量
Extra:執行情況的說明和描述,包含不適合在其他列中顯示但是對執行計劃非常重要的額外資訊,常用取值如下:
- Using index:直接訪問索引就取到了資料,高效能的表現。
- Using where:直接在主鍵索引上過濾資料,必帶where子句,而且用不上索引
- Using index condition:先條件過濾索引,再查資料,
- Using filesort:使用了外部檔案排序 只要見到這個 就要最佳化掉
- Using temporary:建立了臨時表來處理查詢 只要見到這個 也要儘量最佳化掉
最佳化爭議無數的count()
統計列與統計行?
COUNT()是一個特殊的函式,有兩種不同的作用,它可以統計某個列值的數量,也可以統計行數。
在統計列值的時候要求列值是非空的,也就是不統計null。
當我們統計行的時候,常見的是COUNT(*),這種情況下,萬用字元*並不會像我們猜想的那樣擴充套件成所有的列,實際上,它會忽略所有的列而直接統計所有的行數
解密MyiSAM的‘快’
這是一個容易產生誤解的事情:MyiSAM的count()函式總是非常快。
不過它是有前提條件的,條件是沒有任何where條件的count(*)才非常快,因為此時無須實際的去計算表的行數,mysql可以利用儲存引擎的特性直接獲得這個值,如果mysql知道某列不可能有null值,那麼mysql內部會將count(列)運算式最佳化為count(*)。
當統計帶有where條件的查詢,那麼mysql的count()和其他儲存引擎就沒有什麼不同了。
COUNT(1)、COUNT(*)、COUNT(列)
(先提前申明,本人是在innodb庫裡做的實驗。)
1.count(1)和count(*)直接就是統計主鍵,他們兩個的效率是一樣的。如果刪除主鍵,他們都走全表掃描。
2.如果count(列)中的欄位是索引的話,count(列)和count(*)一樣快,否則count(列)走全表掃描。
最佳化order by 陳述句
MySQL的排序方式
最佳化order by陳述句就不得不瞭解mysql的排序方式。
1、第一種透過有序索引傳回資料,這種方式的extra顯示為Using Index,不需要額外的排序,操作效率較高。
2、第二種是對傳回的資料進行排序,也就是通常看到的Using filesort,filesort是透過相應的排序演演算法,將資料放在sort_buffer_size系統變數設定的記憶體排序區中進行排序,如果記憶體裝載不下,它就會將磁碟上的資料進行分塊,再對各個資料塊進行排序,然後將各個塊合併成有序的結果集。
filesort的最佳化
瞭解了MySQL排序的方式,最佳化標的就清晰了:儘量減少額外的排序,透過索引直接傳回有序資料。where條件和order by使用相同的索引。
1、建立合適的索引減少filesort的出現。
2、查詢時儘量只使用必要的欄位,select 具體欄位的名稱,而不是select * 選擇所有欄位,這樣可以減少排序區的使用,提高SQL效能。
最佳化group by 陳述句
為什麼order by後面不能跟group by ?
事實上,MySQL在所有的group by 後面隱式的加了order by ,也就是說group by陳述句的結果會預設進行排序。
如果你要在order by後面加group by ,那結果執行的SQL是不是這樣:select * from tb order by … group by … order by … ? 這不是搞笑嗎?
禁止排序
既然知道問題了,那麼就容易優化了,如果查詢包括group by但又不關心結果集的順序,而這種預設排序又導致了需要檔案排序,則可以指定order by null 禁止排序。
例如:
select * from tb group by name order by null;
最佳化limit 分頁
一個非常常見又非常頭痛的場景:‘limit 1000,20’。
這時MySQL需要查詢1020條記錄然後只傳回最後20條,前面的1000條都將被拋棄,這樣的代價非常高。如果所有頁面的訪問頻率都相同,那麼這樣的查詢平均需要訪問半個表的資料。
第一種思路 在索引上分頁
在索引上完成分頁操作,最後根據主鍵關聯回原表查詢所需要的其他列的內容。
例如:
SELECT * FROM tb_user LIMIT 1000,10
可以最佳化成這樣:
SELECT * FROM tb_user u
INNER JOIN (SELECT id FROM tb_user LIMIT 1000,10) AS b ON b.id=u.id
第二種思路 將limit轉換成位置查詢
這種思路需要加一個引數來輔助,標記分頁的開始位置:
SELECT * FROM tb_user WHERE id > 1000 LIMIT 10
最佳化子查詢
子查詢,也就是查詢中有查詢,常見的是where後面跟一個括號裡面又是一條查詢sql
盡可能的使用join關聯查詢來代替子查詢。
當然 這不是絕對的,比如某些非常簡單的子查詢就比關聯查詢效率高,事實效果如何還要看執行計劃。
只能說大部分的子查詢都可以最佳化成Join關聯查詢。
改變執行計劃
提高索引優先順序
use index 可以讓MySQL去參考指定的索引,但是無法強制MySQL去使用這個索引,當MySQL覺得這個索引效率太差,它寧願去走全表掃描。。。
SELECT * FROM tb_user USE INDEX (user_name)
註意:必須是索引,不能是普通欄位,(親測主鍵也不行)。
忽略索引
ignore index 可以讓MySQL忽略一個索引
SELECT * FROM tb_user IGNORE INDEX (user_name) WHERE user_name=”張學友”
強制使用索引
使用了force index 之後 儘管效率非常低,MySQL也會照你的話去執行
SELECT * FROM tb_user FORCE INDEX (user_name) WHERE user_name=”張學友”
個人分享
檢視執行計劃時建議依次觀察以下幾個要點:
1、SQL內部的執行順序。
2、檢視select的查詢型別。
3、實際有沒有使用索引。
4、Extra描述資訊
PS:一定要養成檢視執行計劃的習慣,這個習慣非常重要。
●編號445,輸入編號直達本文
●輸入m獲取文章目錄

運維
更多推薦《25個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
