
來源:高效運維
ID:greatops
前言
之前在實習時,聽了 OOM 的分享之後,就對 Linux 核心記憶體管理充滿興趣,但是這塊知識非常龐大,沒有一定積累,不敢寫下,擔心誤人子弟,所以經過一個一段時間的積累,對核心記憶體有一定瞭解之後,今天才寫下這篇部落格,記錄以及分享。
【OOM – Out of Memory】記憶體上限溢位
記憶體上限溢位的解決辦法:
1、等比例縮小圖片
2、對圖片採用軟取用,及時進行 recycle( ) 操作。
3、使用載入圖片框架處理圖片,如專業處理圖片的 ImageLoader 圖片載入框架,還有XUtils 的 BitMapUtils 來處理。
這篇文章主要是分析了單個行程空間的記憶體佈局與分配,是從全域性的視角分析下核心對記憶體的管理;
下麵主要從以下方面介紹 Linux 記憶體管理:
-
行程的記憶體申請與分配;
-
記憶體耗盡之後 OOM;
-
申請的記憶體都在哪?
-
系統回收記憶體;
1、行程的記憶體申請與分配
之前有篇文章介紹 hello world 程式是如何載入記憶體以及是如何申請記憶體的,我在這,再次說明下:同樣,還是先給出行程的地址空間,我覺得對於任何開發人員這張圖是必須記住的,還有一張就是操作 disk ,memory 以及 cpu cache 的時間圖。
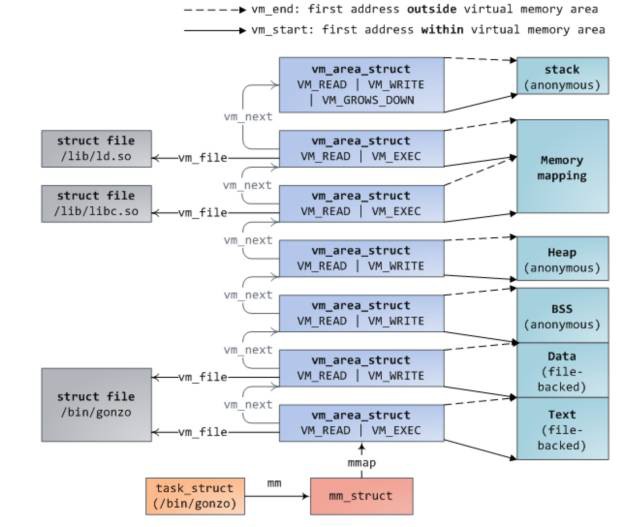
當我們在終端啟動一個程式時,終端行程呼叫 exec 函式將可執行檔案載入記憶體,此時程式碼段,資料段,bbs 段,stack 段都透過 mmap 函式對映到記憶體空間,堆則要根據是否有在堆上申請記憶體來決定是否對映。
exec 執行之後,此時並未真正開始執行行程,而是將 cpu 控制權交給了動態連結庫裝載器,由它來將該行程需要的動態連結庫裝載進記憶體。之後才開始行程的執行,這個過程可以透過 strace 命令跟蹤行程呼叫的系統函式來分析。

這是我上篇部落格認識 pipe 中的程式,從這個輸出過程,可以看出和我上述描述的一致。
當第一次呼叫 malloc 申請記憶體時,透過系統呼叫 brk 嵌入到核心,首先會進行一次判斷,是否有關於堆的 vma,如果沒有,則透過 mmap 匿名對映一塊記憶體給堆,並建立 vma 結構,掛到 mm_struct 描述符上的紅黑樹和連結串列上。
然後回到使用者態,透過記憶體分配器(ptmaloc,tcmalloc,jemalloc)演演算法將分配到的記憶體進行管理,傳回給使用者所需要的記憶體。
如果使用者態申請大記憶體時,是直接呼叫 mmap 分配記憶體,此時傳回給使用者態的記憶體還是虛擬記憶體,直到第一次訪問傳回的記憶體時,才真正進行記憶體的分配。
其實透過 brk 傳回的也是虛擬記憶體,但是經過記憶體分配器進行切割分配之後(切割就必須訪問記憶體),全都分配到了物理記憶體
當行程在使用者態透過呼叫 free 釋放記憶體時,如果這塊記憶體是透過 mmap 分配,則呼叫 munmap 直接傳回給系統。
否則記憶體是先傳回給記憶體分配器,然後由記憶體分配器統一返還給系統,這就是為什麼當我們呼叫 free 回收記憶體之後,再次訪問這塊記憶體時,可能不會報錯的原因。
當然,當整個行程退出之後,這個行程佔用的記憶體都會歸還給系統。
2、記憶體耗盡之後OOM
在實習期間,有一臺測試機上的 mysql 實體經常被 oom 殺死,OOM(out of memory)即為系統在記憶體耗盡時的自我拯救措施,他會選擇一個行程,將其殺死,釋放出記憶體,很明顯,哪個行程佔用的記憶體最多,即最可能被殺死,但事實是這樣的嗎?
今天早上去上班,剛好碰到了一起 OOM,突然發現,OOM 一次,世界都安靜下來了,哈哈,測試機上的 redis 被殺死了。

OOM 關鍵檔案 oom_kill.c,裡面介紹了當記憶體不夠時,系統如何選擇最應該被殺死的行程,選擇因素有挺多的,除了行程佔用的記憶體外,還有行程執行的時間,行程的優先順序,是否為 root 使用者行程,子行程個數和佔用記憶體以及使用者控制引數 oom_adj 都相關。
當產生 oom 之後,函式 select_bad_process 會遍歷所有行程,透過之前提到的那些因素,每個行程都會得到一個 oom_score 分數,分數最高,則被選為殺死的行程。
我們可以透過設定 /proc/

這是核心關於這個oom_adj調整值的定義,最大可以調整為15,最小為-16,如果為-17,則該行程就像買了vip會員一樣,不會被系統驅逐殺死了,因此,如果在一臺機器上有跑很多伺服器,且你不希望自己的服務被殺死的話,就可以設定自己服務的 oom_adj 為-17。
當然,說到這,就必須提到另一個引數 /proc/sys/vm/overcommit_memory,man proc 說明如下:

意思就是當 overcommit_memory 為0時,則為啟髮式oom,即當申請的虛擬記憶體不是很誇張的大於物理記憶體,則系統允許申請,但是當行程申請的虛擬記憶體很誇張的大於物理記憶體,則就會產生 OOM。
例如只有8g的物理記憶體,然後 redis 虛擬記憶體佔用了24G,物理記憶體佔用3g,如果這時執行 bgsave,子行程和父行程共享物理記憶體,但是虛擬記憶體是自己的,即子行程會申請24g的虛擬記憶體,這很誇張大於物理記憶體,就會產生一次OOM。
當 overcommit_memory 為1時,則永遠都允許 overmemory 記憶體申請,即不管你多大的虛擬記憶體申請都允許,但是當系統記憶體耗盡時,這時就會產生oom,即上述的redis例子,在 overcommit_memory=1 時,是不會產生oom 的,因為物理記憶體足夠。
當 overcommit_memory 為2時,永遠都不能超出某個限定額的記憶體申請,這個限定額為 swap+RAM* 繫數(/proc/sys/vm/overcmmit_ratio,預設50%,可以自己調整),如果這麼多資源已經用光,那麼後面任何嘗試申請記憶體的行為都會傳回錯誤,這通常意味著此時沒法執行任何新程式
以上就是 OOM 的內容,瞭解原理,以及如何根據自己的應用,合理的設定OOM。
3、系統申請的記憶體都在哪?
我們瞭解了一個行程的地址空間之後,是否會好奇,申請到的物理記憶體都存在哪了?可能很多人覺得,不就是物理記憶體嗎?
我這裡說申請的記憶體在哪,是因為物理記憶體有分為cache和普通物理記憶體,可以透過 free 命令檢視,而且物理記憶體還有分 DMA,NORMAL,HIGH 三個區,這裡主要分析cache和普通記憶體。
透過第一部分,我們知道一個行程的地址空間幾乎都是 mmap 函式申請,有檔案對映和匿名對映兩種。
3.1 共享檔案對映
我們先來看下程式碼段和動態連結庫對映段,這兩個都是屬於共享檔案對映,也就是說由同一個可執行檔案啟動的兩個行程是共享這兩個段,都是對映到同一塊物理記憶體,那麼這塊記憶體在哪了?我寫了個程式測試如下:

我們先看下當前系統的記憶體使用情況:

當我在本地新建一個1G的檔案:
dd if=/dev/zero of=fileblock bs=M count=1024
然後呼叫上述程式,進行共享檔案對映,此時記憶體使用情況為:

我們可以發現,buff/cache 增長了大概1G,因此我們可以得出結論,程式碼段和動態連結庫段是對映到核心cache中,也就是說當執行共享檔案對映時,檔案是先被讀取到 cache 中,然後再對映到使用者行程空間中。
3.2 私有檔案對映段
對於行程空間中的資料段,其必須是私有檔案對映,因為如果是共享檔案對映,那麼同一個可執行檔案啟動的兩個行程,任何一個行程修改資料段,都將影響另一個行程了,我將上述測試程式改寫成匿名檔案對映:

在執行程式執行,需要先將之前的 cache 釋放掉,否則會影響結果
echo 1 >> /proc/sys/vm/drop_caches
接著執行程式,看下記憶體使用情況:

從使用前和使用後對比,可以發現 used 和 buff/cache 分別增長了1G,說明當進行私有檔案對映時,首先是將檔案對映到 cache 中,然後如果某個檔案對這個檔案進行修改,則會從其他記憶體中分配一塊記憶體先將檔案資料複製至新分配的記憶體,然後再在新分配的記憶體上進行修改,這也就是寫時複製。
這也很好理解,因為如果同一個可執行檔案開啟多個實體,那麼核心先將這個可執行的資料段對映到 cache,然後每個實體如果有修改資料段,則都將分配一個一塊記憶體儲存資料段,畢竟資料段也是一個行程私有的。
透過上述分析,可以得出結論,如果是檔案對映,則都是將檔案對映到 cache 中,然後根據共享還是私有進行不同的操作。
3.3 私有匿名對映
像 bbs 段,堆,棧這些都是匿名對映,因為可執行檔案中沒有相應的段,而且必須是私有對映,否則如果當前行程 fork 出一個子行程,那麼父子行程將會共享這些段,一個修改都會影響到彼此,這是不合理的。
ok,現在我把上述測試程式改成私有匿名對映

這時再來看下記憶體的使用情況

我們可以看到,只有 used 增加了1G,而 buff/cache 並沒有增長;說明,在進行匿名私有對映時,並沒有佔用 cache,其實這也是有道理,因為就只有當前行程在使用這塊這塊記憶體,沒有必要佔用寶貴的 cache。
3.4 共享匿名對映
當我們需要在父子行程共享記憶體時,就可以用到 mmap 共享匿名對映,那麼共享匿名對映的記憶體是存放在哪了?我繼續改寫上述測試程式為共享匿名對映 。

這時來看下記憶體的使用情況:

從上述結果,我們可以看出,只有buff/cache增長了1G,即當進行共享匿名對映時,這時是從 cache 中申請記憶體,道理也很明顯,因為父子行程共享這塊記憶體,共享匿名對映存在於 cache,然後每個行程再對映到彼此的虛存空間,這樣即可操作的是同一塊記憶體。
4、系統回收記憶體
當系統記憶體不足時,有兩種方式進行記憶體釋放,一種是手動的方式,另一種是系統自己觸發的記憶體回收,先來看下手動觸發方式。
4.1 手動回收記憶體
手動回收記憶體,之前也有演示過,即
echo 1 >> /proc/sys/vm/drop_caches
我們可以在 man proc 下麵看到關於這個的簡介

從這個介紹可以看出,當 drop_caches 檔案為1時,這時將釋放 pagecache 中可釋放的部分(有些 cache 是不能透過這個釋放的),當 drop_caches 為2時,這時將釋放 dentries 和 inodes 快取,當 drop_caches 為3時,這同時釋放上述兩項。
關鍵還有最後一句,意思是說如果 pagecache 中有臟資料時,操作 drop_caches 是不能釋放的,必須透過 sync 命令將臟資料掃清到磁碟,才能透過操作 drop_caches 釋放 pagecache。
ok,之前有提到有些pagecache是不能透過drop_caches釋放的,那麼除了上述提檔案對映和共享匿名對映外,還有有哪些東西是存在pagecache了?
4.2 tmpfs
我們先來看下 tmpfs ,tmpfs 和 procfs,sysfs 以及 ramfs 一樣,都是基於記憶體的檔案系統,tmpfs 和 ramfs 的區別就是 ramfs 的檔案基於純記憶體的,和 tmpfs 除了純記憶體外,還會使用 swap 交換空間,以及 ramfs 可能會把記憶體耗盡,而 tmpfs 可以限定使用記憶體大小,可以用命令 df
-T -h 檢視系統一些檔案系統,其中就有一些是 tmpfs,比較出名的是目錄 /dev/shm
tmpfs 檔案系統源檔案在核心原始碼 mm/shmem.c,tmpfs實現很複雜,之前有介紹虛擬檔案系統,基於 tmpfs 檔案系統建立檔案和其他基於磁碟的檔案系統一樣,也會有 inode,super_block,identry,file 等結構,區別主要是在讀寫上,因為讀寫才涉及到檔案的載體是記憶體還是磁碟。
而 tmpfs 檔案的讀函式 shmem_file_read,過程主要為透過 inode 結構找到 address_space 地址空間,其實就是磁碟檔案的 pagecache,然後透過讀偏移定位cache 頁以及頁內偏移。
這時就可以直接從這個 pagecache 透過函式 __copy_to_user 將快取頁內資料複製到使用者空間,當我們要讀物的資料不pagecache中時,這時要判斷是否在 swap 中,如果在則先將記憶體頁 swap
in,再讀取。
tmpfs 檔案的寫函式 shmem_file_write,過程主要為先判斷要寫的頁是否在記憶體中,如果在,則直接將使用者態資料透過函式__copy_from_user複製至核心pagecache中改寫老資料,並標為 dirty。
如果要寫的資料不再記憶體中,則判斷是否在swap 中,如果在,則先讀取出來,用新資料改寫老資料並標為臟,如果即不在記憶體也不在磁碟,則新生成一個 pagecache 儲存使用者資料。
由上面分析,我們知道基於 tmpfs 的檔案也是使用 cache 的,我們可以在/dev/shm上建立一個檔案來檢測下:

看到了吧,cache 增長了1G,驗證了 tmpfs 的確使用的 cache 記憶體。
其實 mmap 匿名對映原理也是用了 tmpfs,在 mm/mmap.c->do_mmap_pgoff 函式內部,有判斷如果 file 結構為空以及為 SHARED 對映,則呼叫 shmem_zero_setup(vma) 函式在 tmpfs 上用新建一個檔案

這裡就解釋了為什麼共享匿名對映記憶體初始化為0了,但是我們知道用 mmap 分配的記憶體初始化為0,就是說 mmap 私有匿名對映也為0,那麼體現在哪了?
這個在 do_mmap_pgoff 函式內部可沒有體現出來,而是在缺頁異常,然後分配一種特殊的初始化為0的頁。
那麼這個 tmpfs 佔有的記憶體頁可以回收嗎?

也就是說 tmpfs 檔案佔有的 pagecache 是不能回收的,道理也很明顯,因為有檔案取用這些頁,就不能回收。
4.3 共享記憶體
posix 共享記憶體其實和 mmap 共享對映是同一個道理,都是利用在 tmpfs 檔案系統上新建一個檔案,然後再對映到使用者態,最後兩個行程操作同一個物理記憶體,那麼 System V 共享記憶體是否也是利用 tmpfs 檔案系統了?
我們可以跟蹤到下述函式

這個函式就是新建一個共享記憶體段,其中函式
shmem_kernel_file_setup
就是在 tmpfs 檔案系統上建立一個檔案,然後透過這個記憶體檔案實現行程通訊,這我就不寫測試程式了,而且這也是不能回收的,因為共享記憶體ipc機制生命週期是隨內核的,也就是說你建立共享記憶體之後,如果不顯示刪除的話,行程退出之後,共享記憶體還是存在的。
之前看了一些技術部落格,說到 Poxic 和 System
V 兩套 ipc 機制(訊息佇列,訊號量以及共享記憶體)都是使用 tmpfs 檔案系統,也就是說最終記憶體使用的都是 pagecache,但是我在原始碼中看出了兩個共享記憶體是基於 tmpfs 檔案系統,其他訊號量和訊息佇列還沒看出來(有待後續考究)。
posix 訊息佇列的實現有點類似與 pipe 的實現,也是自己一套 mqueue 檔案系統,然後在 inode 上的 i_private 上掛上關於訊息佇列屬性 mqueue_inode_info,在這個屬性上,核心2.6時,是用一個陣列儲存訊息,而到了4.6則用紅黑樹了儲存訊息(我下載了這兩個版本,具體什麼時候開始用紅黑樹,沒深究)。
然後兩個行程每次操作都是操作這個 mqueue_inode_info 中的訊息陣列或者紅黑樹,實現行程通訊,和這個 mqueue_inode_info 類似的還有 tmpfs 檔案系統屬性shmem_inode_info 和為epoll服務的檔案系統 eventloop,也有一個特殊屬性struct
eventpoll,這個是掛在 file 結構的 private_data 等等。
說到這,可以小結下,行程空間中程式碼段,資料段,動態連結庫(共享檔案對映),mmap 共享匿名對映都存在於 cache 中,但是這些記憶體頁都有被行程取用,所以是不能釋放的,基於 tmpfs 的 ipc 行程間通訊機制的生命週期是隨核心,因此也是不能透過 drop_caches 釋放。
雖然上述提及的cache不能釋放,但是後面有提到,當記憶體不足時,這些記憶體是可以 swap out 的。
因此 drop_caches 能釋放的就是當從磁碟讀取檔案時的快取頁以及某個行程將某個檔案對映到記憶體之後,行程退出,這時對映檔案的的快取頁如果沒有被取用,也是可以被釋放的。
4.4 記憶體自動釋放方式
當系統記憶體不夠時,作業系統有一套自我整理記憶體,並盡可能的釋放記憶體機制,如果這套機制不能釋放足夠多的記憶體,那麼只能 OOM 了。
之前在提及 OOM 時,說道 redis 因為 OOM 被殺死,如下:

第二句後半部分,
total-vm:186660kB, anon-rss:9388kB, file-rss:4kB
把一個行程記憶體使用情況,用三個屬性進行了說明,即所有虛擬記憶體,常駐記憶體匿名對映頁以及常駐記憶體檔案對映頁。
其實從上述的分析,我們也可以知道一個行程其實就是檔案對映和匿名對映:
-
檔案對映:程式碼段,資料段,動態連結庫共享儲存段以及使用者程式的檔案對映段;
-
匿名對映:bbs段,堆,以及當 malloc 用 mmap 分配的記憶體,還有mmap共享記憶體段;
其實核心回收記憶體就是根據檔案對映和匿名對映來進行的,在 mmzone.h 有如下定義:

LRU_UNEVICTABLE 即為不可驅逐頁 lru,我的理解就是當呼叫 mlock 鎖住記憶體,不讓系統 swap out 出去的頁串列。
簡單說下 linux 核心自動回收記憶體原理,內核有一個 kswapd 會週期性的檢查記憶體使用情況,如果發現空閑記憶體定於 pages_low,則 kswapd 會對 lru_list 前四個 lru 佇列進行掃描,在活躍連結串列中查詢不活躍的頁,並新增不活躍連結串列。
然後再遍歷不活躍連結串列,逐個進行回收釋放出32個頁,知道 free
page 數量達到 pages_high,針對不同的頁,回收方式也不一樣。
當然,當記憶體水平低於某個極限閾值時,會直接發出記憶體回收,原理和 kswapd 一樣,但是這次回收力度更大,需要回收更多的記憶體。
檔案頁:
-
如果是臟頁,則直接回寫進磁碟,再回收記憶體。
-
如果不是臟頁,則直接釋放回收,因為如果是io讀快取,直接釋放掉,下次讀時,缺頁異常,直接到磁碟讀回來即可,如果是檔案對映頁,直接釋放掉,下次訪問時,也是產生兩個缺頁異常,一次將檔案內容讀取進磁碟,另一次與行程虛擬記憶體關聯。
匿名頁:
因為匿名頁沒有回寫的地方,如果釋放掉,那麼就找不到資料了,所以匿名頁的回收是採取 swap out 到磁碟,併在頁表項做個標記,下次缺頁異常在從磁碟 swap in 進記憶體。
swap 換進換出其實是很佔用系統IO的,如果系統記憶體需求突然間迅速增長,那麼cpu 將被io佔用,系統會卡死,導致不能對外提供服務,因此係統提供一個引數,用於設定當進行記憶體回收時,執行回收 cache 和 swap 匿名頁的,這個引數為:

意思就是說這個值越高,越可能使用 swap 的方式回收記憶體,最大值為100,如果設為0,則盡可能使用回收 cache 的方式釋放記憶體。
5、總結
這篇文章主要是寫了 linux 記憶體管理相關的東西:
首先是回顧了行程地址空間;
其次當行程消耗大量記憶體而導致記憶體不足時,我們可以有兩種方式:第一是手動回收 cache;另一種是系統後臺執行緒 swapd 執行記憶體回收工作。
最後當申請的記憶體大於系統剩餘的記憶體時,這時就只會產生 OOM,殺死行程,釋放記憶體,從這個過程,可以看出系統為了騰出足夠的記憶體,是多麼的努力啊。
作者:羅道文的私房菜
原文連結:http://luodw.cc/2016/08/13/linux-cache/
《Linux雲端計算及運維架構師高薪實戰班》2018年05月14日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
