認證授權,作為服務的重要組成部分之一,在微服務/平臺化的背景下,迎來了新的挑戰。龐雜的業務應用 vs 精深的中臺服務,在許可權模型上有何異同?又該如何分而治之,且自洽呢?在鏈家網向貝殼找房平臺化的行程中,我們分別生產了”面向服務“和”面向使用者“兩套許可權服務,試圖打造一個立體的許可權系統。
聽了很多場Kubernetes的分享,深感大家貼近時代的潮流。今晚我拋磚引玉,來聊聊plain boring的許可權系統,看看能不能喚醒大家那些good old days:)
貝殼找房是基於原有鏈家網的技術能力,新推出的房產平臺服務。我們作為貝殼找房的基礎技術團隊,為業務系統提供了多個服務,比如使用者中心,儲存服務,圖片服務,400號碼服務等等。在對接各業務系統過程中,都面臨著同樣的問題:
-
身份標識:明確身份,我們才有能更精確而且有效地實現限流,融斷,配額等功能;
-
許可權分配:許可權控制是大多數業務發展到一定階段都需要面臨的問題,如何確保不同業務的資源隔離,並實現細粒度的控制許可權? 在單個服務中,這些問題看似簡單,在多個服務特別是微服務架構下被放大了。
我們期望有這麼一套系統,它能提供了統一的身份標識,進而提供可靠的認證機制,進而提供自助的許可權管理。我們可以把金鑰管理,介面簽名,許可權分發等等一系列問題拋之腦後,專註於自身服務。
剛好,我們當時使用著AWS的基礎服務,有一定的AWS IAM使用經驗。IAM的模型,十分契合我們的想法(或者說,我們已經被先入為主了)。但遺憾的是,IAM作為雲服務的基礎設施,是不對外提供服務的。
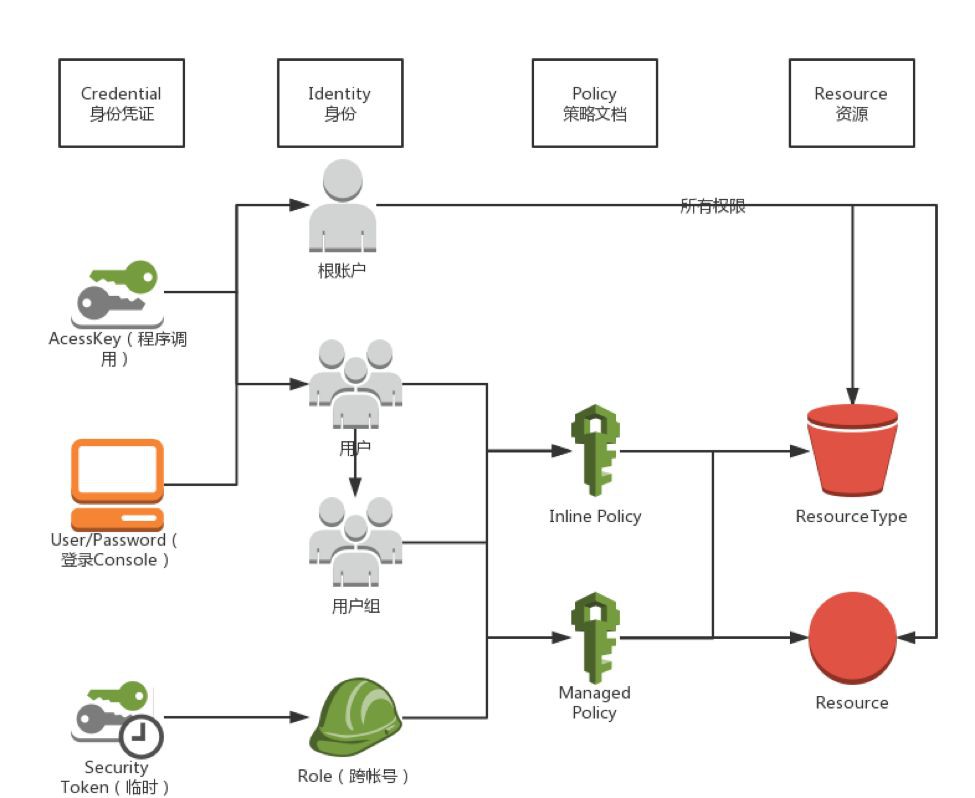
上圖是AWS IAM一個簡單的系統分解。對於不熟悉IAM的同學,可前往https://docs.aws.amazon.com/zh_cn/IAM/latest/UserGuide/intro-structure.html自行瞭解。
一開始,我們是強烈避免重覆造輪子的,我們將目光轉向了OpenStack的keystone,嘗試二次開發。但經過短暫的調研後發現,keystone是一個傳統的RBAC許可權模型;每個服務維護著自己的policy.json,配置無法產品化;維護Token,給無狀態的服務帶來了負擔。我們考慮到適配和理解層面上的阻抗,加之一定無法合併到上游的命運,無奈下放棄了這個方案。在沒有合適的候選方案下,我們做了心理建設,開始了自研的工作。
自研IAM比較好的情況是,在AWS IAM,阿裡雲RAM,騰訊雲CAM等體系教育下,整個客戶端的行為已經十分明確,服務端的業務行為基本能被倒推出來。唯一無從知曉的,是服務端的架構方式。
理想情況下,我認為效能最優的一個方案是:所有服務以一種語言實現,IAM的功能作為SDK的方式整合在服務之中,SDK依賴彈性伸縮的資料服務,輔以上層負載均衡依照AK將請求路由到不同的分割槽,以期保證效能的同時,達到更高的靈活度。
然而,我們根據我司的現實情況,做了一些不一樣的決策:
由於我司開發語言以Java和PHP為首,我們需要以介面的形式提供多語言的支援。
由於我們無法把控服務實現的質量,我們決定:服務無法拿到使用方的Secrect Key。這會導致認證和授權的捆綁,勢必不是最優解,但是我們能確保安全。
考慮到請求到服務,服務轉到IAM做鑒權的場景,我們認為跨服務的鑒權也是不合理的,故對鑒權請求也做了AK/SK加密:只有服務對應的IAM主體才能操作對應服務資源,實現了自舉。
我們選擇了Golang來實現IAM。服務到IAM的請求使用的是gRPC,透過grpc-gateway添加了HTTP介面的支援,方便測試。
由於Policy天生的複雜度,我們在落地MySQL的同時,按使用者和服務為最小粒度,以protobuf的形式全量儲存在Redis,然後拉取到BigCache做記憶體快取。最終在m3.2xlarge的機器上,QPS可達到 1W+,Latency控制在2ms之內。由於避免了額外IO,再加之每個請求2次加解密的需求,和Resource基於字串的匹配,導致CPU成為瓶頸。
由於考慮到了後續可能會開源,我們對RMDB,集中快取,事件通知等外部依賴都使用了interface,做成了可插拔的元件。(如果群裡有專利方面的大拿,還請不吝賜教,能否開源)
提個使用者體驗的小case,大家知道,由於許可權系統會大量使用快取,時效性一般不做嚴格保證。我們服務的記憶體級快取,最初設定成了5分鐘。在使用者使用時,這5分鐘的快取,也造成了很大的幹擾。我們發現,使用者改完後,都會親自測試下;等5分鐘後再試,使用體驗是反人類的。所以,我們認為對於許可權系統來說,時效性應該是秒級。我們加上基於Redis的事件通知機制後,基於控制檯的使用體驗一下子就好轉了。
在服務端接入的時候,造成很大困擾的是,IAM對Body的加簽設定。大家知道,基本上所有語言,HTTP Request Body都是流式設計,這意味著服務在做驗簽之前,要消費掉body,同時feed到sha256等hash演演算法內。這樣的話,業務邏輯和驗簽邏輯交織在一起,造成了耦合。我們萌發了自己定義加簽規範的念頭,將這個需求拆解成兩步:帶body的請求帶content-md5頭,IAM驗證頭資訊,服務可選驗證content-md5. 這就演化成了我們統一API簽名的專案,具體就不展開了。
當服務方接入IAM,常常需要一個思路上的轉化:服務方自己其實不是資源的擁有者!在IAM體系中,資源的擁有者是首次申請資源的根帳號,根帳號再將許可權切割出來分配給子使用者。服務方僅提供服務能力,在控制檯內不能對資源做任何管控,管控是由業務方自主完成的!
可以說,IAM很好的達到了我們對它的預期。但對服務來說,天生多租戶/平臺化的要求,導致了IAM推廣落地的難度,我們急需一個落地媒介,這就是服務目錄。
服務目錄作為鏈家網基礎服務部孵化的內部專案,類似雲服務WebConsole的統一入口,旨在降低溝通成本,提高使用體驗。
服務目錄提供了一個基於React的前端框架,和一個基於NodeJS的大前端,內嵌了多個服務面板。
服務目錄以IAM系統做身份認證,提供了統一的應用到服務間簽名SDK,以及服務端到IAM間SDK。
由於服務目錄有代理使用者操作的需求,我們給服務目錄的NodeJS大前端頒發了一個Super AK,由此AK發起的請求完全受信,做到了和IAM服務的打通。
我們期待服務目錄能夠盤活整個中臺服務體系,乃至有需求的業務應用,使服務逐步平臺化,產品化。
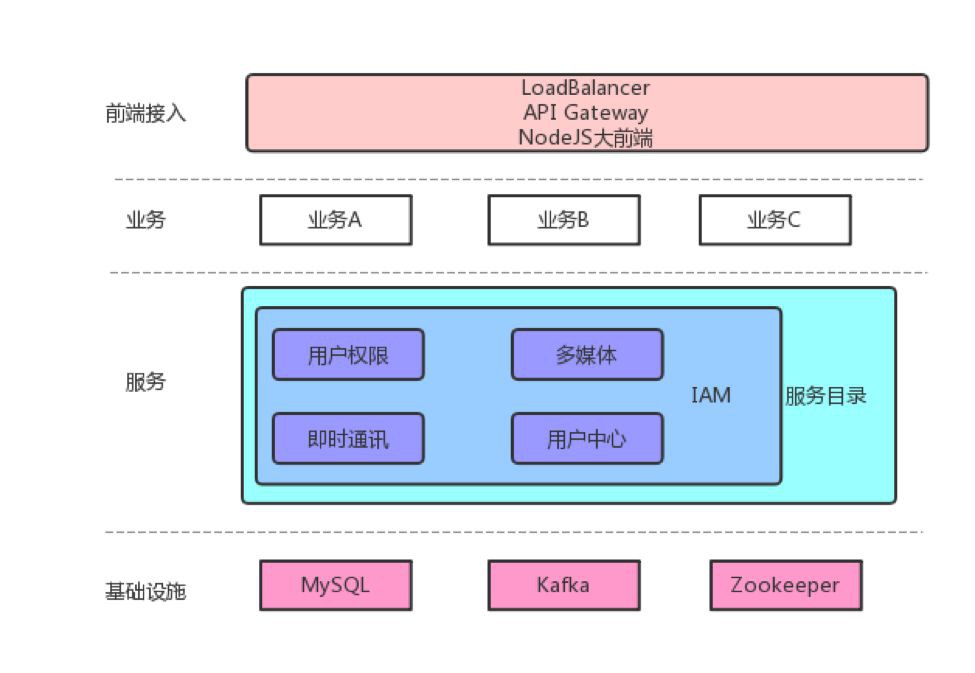
上圖是我們預期的整體架構。業務層負責對接具體的業務,其他所有層為其賦能;服務層提供業務無關的通用能力,但不直接參與到具體的業務實現;基礎設施層提供穩定可靠的儲存/計算等能力。業務到服務間透過IAM授權,使用者透過服務目錄管理資源。所有層都具有監控報警等基礎能力。
聊完業務和服務之間的許可權管控,我們來聊聊使用者和業務之間的許可權管理。
大家可能認為,這不是整合個Shiro生成幾張資料庫表的事兒嗎?誠然,這樣的確能滿足需求。
但是,當業務擴大到成百上千個,每個業務都去做許可權系統的CRUD及其對應的後臺頁面時,這就產生了巨大的浪費。如果再加上審批審計,批次匯入匯出,業務層控制元件開發等等一系列功能呢?再加上PM/運營人員的學習使用成本呢?
所以,統一的業務層使用者許可權體系仍然是有很大價值的。但如何做到能夠靈活地支援多個業務方?在業務方有需求的時候,能快速的響應,或者指導業務方自身完成,對我們來說,仍然是一個巨大的挑戰。
很有趣的是,在剛剛做完IAM主體開發後,我們立馬拿到了一個新的專案:重構使用者中心許可權服務。
我想每個網際網路公司都有一套自己的使用者中心,鏈家網的使用者中心是由使用者資訊,單點登陸,及許可權系統三部分組成。許可權系統發源於B端業務,初期很好地滿足了業務需求,但隨著業務的發展,新功能的新增,慢慢凸顯出一些矛盾:
-
許可權和使用者中心的程式碼,同一倉庫,耦合性高,缺乏獨立上線的能力。
-
使用者中心支援內網外使用者,而許可權系統只支援內網使用者。
-
許可權系統的多租戶支援是以每個table新增appid column實現的;租戶間容易相互幹擾,容易造成資料的不一致。
-
基於RMDB的API沒有做上層封裝,使用複雜;許可權資訊拉取,需要三個請求,導致效能低下。
-
時效性低:人員變動引起的許可權變化,得等到每晚凌晨跑批處理;角色的生效,也得手動跑批。
-
傳統頁面應用,沒有寫入介面。
-
資料安全問題,沒有堅持最小安全原則。
稍微鋪墊一下,跟IAM系統截然相反,使用者許可權系統,是基於RBAC許可權模型。
之前的同學在許可權點的維度上,創造性地附加了“約束”的概念。“約束”是一個KV的結構,描述了許可權點(功能許可權)對應的資料範圍。
使用方式為:業務接入方,在使用者登陸後,向我們拉取許可權資訊,快取在本地;之後所有的操作,即可透過角色資訊,許可權點串列,和許可權對應的資料約束,解釋出yes or no的結果。
所以,分析下來,“使用者許可權系統”實際上是一個垂直領域的,支援多租戶的CMS系統。
在使用者許可權系統中,約束是許可權點的擴充套件,那角色的擴充套件呢?使用者的擴充套件呢?
於是,我們新加入了幾個擴充套件點,方便業務各個維度的自定義需求:
-
Property屬性 作為角色的擴充套件,屬性有預定義的相關型別:如單選列舉,多選列舉,組織樹,自定義等等。租戶內角色屬性是一致的,租戶間角色屬性是多Schema的。
-
Extension約束 作為許可權點的擴充套件,約束也支援型別。約束需預先掛接到許可權點;角色新增許可權點時,約束以對應的控制元件渲染,同時可附加“不約束”和“為空”兩種狀態。
-
使用者有統一的UCID,但每個業務有不同的使用者屬性。我們支援多資料源使用者的同步,同步來的使用者屬性歸屬在資料源名字空間下,其他所有業務均可使用。使用者的屬性有一個很重要的作用,用來實現基於規則的自動系結,比如這樣的運算式:(user.sex == “M” && user.age > 30) || (user.orgCode contains “1111”) 。
在這裡,我想著重提一下”型別“,我認為這是一個很好的設計:它保證了底層資料的獨立性,穩定性;在上層以控制元件形態,指導自然人使用;對應用提供了meta資訊,指導SDK解釋含義。它將一個個無含義的KV,填充了血肉,貼近了業務。
我們把它實現成了一個DB級別隔離的多租戶系統,一個CQRS(讀寫模型分離)的系統,一個業務端 Multi-Schema的系統。
如上圖,後臺Luke使用的技術棧是NodeJS (TypeScript) / GraphQL (Apollo + Dataloader) / MongoDB (Mongoose);服務目錄的控制檯LukePanel的技術棧是ES6 / React / Apollo Client / AntDesign; Luke和LukePanel透過專案Chawbacca公用前後臺驗證邏輯;前臺Leia因為要支援Dubbo,選擇了Spring,提供了WebFlux API 和 Dubbo Facade,透過SpEL做許可權的實時計算。
從技術選型上可以看出,我們推崇合適的工具做合適的事情。TypeScript和GraphQL都給了我們很大的驚喜,透過Schema Stitch和JSON scalar,我們透明處理了DB隔離和MultiSchema,在保證工程質量的同時,確保了工程進度。
談到許可權的實時生效,我們可以改進之前的定時跑批,做到基於事件流的實時處理。然而,考慮到“潛在使用者掃清量大”和“掃清需加鎖序列執行”的問題,為保證時效性,我們並沒有選擇這種方案,而是選擇了“首次訪問時做實時計算“的實現方式,這樣可以篩選出真實使用者,事件處理只需要”無腦“清快取即可,而代價僅是計算支援一定的併發,且延遲不能太大。
比較好玩的是,所有許可權系統,第一件客戶始終是自己,透過自舉,給自己賦能,是一件很有樂趣的事兒。
今晚講了兩個許可權體系,希望能給大家一些啟發。在實現的過程中,我們收穫很多樂趣,我們也希望能把這兩個系統真正落地下來,產生應有的價值。希望大家多多指教!

Q:請問鏈家這個業務和服務之間的許可權管控,和Kubernetes中的RBAC實現有什麼區別呢?
A:Sorry,對Kubernetes的RBAC樣式不熟悉,但是我想都是基於同一個許可權模型,不會有太大差距。RBAC有RBAC1,2,3,4多個粒度,都是基於最基本的角色/許可權的擴充。我剛剛看了下檔案,看到了支援使用者組Group,resourceNames支援到了Row Based粒度,從功能上應該算完備了吧。
Q:為什麼選擇Golang作為後端的實現呢?有遇到什麼印象深刻的“坑”嗎?
A:因為我們team主推的語言是Go:)由於Golang,gRPC,Protobuf都是Google主推的專案,整合的體驗還是相當愉悅的。
我們實現的時候,遵循了社群的建議,Library over Framework(比如orm選擇了sqlx),沒有遇到太多的坑。
HTTP Content-Length / Host等Header實際上不在Headers物件裡,而是作為了request的基礎屬性,在我們實現簽名的時候被坑了一把。
HMac的Hashlib不支援Reset,我們無法放到sync.Pool中。因為加解密重度依賴此模組,我們不得以用type alias + internal包路徑hack了一把。
最後還有說好的dep要進官方,結果被Russ的vgo橫插了一把,感覺很怨念,又要切工具了。
本次培訓內容包括:容器介紹、容器網路、Kubernetes架構基礎介紹、安裝、設計理念、架構詳解、設計原則、常用物件、監控方案、Kubernetes高階設計和實現、微服務、實踐案例分享等,點選瞭解具體培訓內容。
長按二維碼向我轉賬
![]()
受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。