來自:部落格園,作者:閃客sun
https://www.cnblogs.com/flashsun/p/7744466.html
一直不知道效能最佳化都要做些什麼,從哪方面思考,直到最近接手了一個公司的小專案,可謂麻雀雖小五臟俱全。讓我這個程式設計小白學到了很多效能最佳化的知識,或者說一些思考方式。真的感受到任何一點效率的損失放大一定倍數時,將會是天文數字。最初我的程式計算下來需要跑2個月才能跑完,經過2周不斷地調整架構和細節,將效能提升到了4小時完成。
很多心得體會,希望和大家分享,也希望多多批評指正,共同進步。
一、專案描述
我將公司的專案內容抽象,大概是要做這樣一件事情:
1、資料庫A中有2000萬條使用者資料;
2、將資料庫A中的使用者讀出,為每條使用者生成guid,並儲存到資料庫B中;
3、同時在資料庫A中生成關聯表;

專案要求為:
1、將使用者存入資料庫B的過程需要呼叫sdk的註冊介面,不允許直接操作jdbc進行插入;
2、資料要求可恢復:再次執行要跳過已成功的資料;出錯的資料要進行持久化以便下次可以選擇恢復該部分資料;
3、資料要保證一致性:在不出錯的情況下,資料庫B的使用者必然一一對應資料庫A的關聯表。如果出錯,那麼正確的資料加上記錄下來的出錯資料後要保證一致性;
4、速度要盡可能塊:共2000萬條資料,在保證正確性的前提下,至多一天內完成;
二、第一版:面向過程——2個月
特徵:面向過程、單一執行緒、不可拓展、極度耦合、逐條插入、資料不可恢復

最初的一版簡直是匯聚了一個專案的所有缺點。整個流程就是從A庫讀出一條資料,立刻做處理,然後呼叫介面插入B庫,然後在拼一個關聯表的sql陳述句,插入A庫。沒有計數器,沒有錯誤資訊處理。這樣下來的程式碼最終預測2000萬條資料要處理2個月。如果中間哪怕一條資料出錯,又要重新再來2個月。簡直可怕。
這個流程圖就等同於廢話,是完全基於面向過程的思想,整個程式碼就是在一個大main方法裡寫的,實際業務流程完全等同於程式碼的流程。思考起來簡單,但實現和維護起來極為困難,程式碼結構冗長混亂。而且幾乎是不可擴充套件的。暫且不談程式碼的設計美觀,它的效率如此低下主要有一下幾點:
1、每一條資料的速度受制於整個鏈條中最慢的一環。試想假如有一條A庫插入關聯表的資料卡住了,等待將近1分鐘(誇張了點),那這一分鐘jvm完全就在傻等,它完全可以繼續進行之前的兩步。正如你等待雞蛋煮熟的過程中可以同時去做其他的事一樣。
2、向B庫插入使用者需要呼叫sdk(HTTP請求)介面,那每一次呼叫都需要建立連線,等待響應,再釋放連結。正如你要給朋友送一箱蘋果,你分成100次每次只送一個,時間全搭載路上了。
三、第二版:面向物件——21天
特徵:面向物件、單一執行緒、可拓展、略微耦合、批次插入、資料可恢復
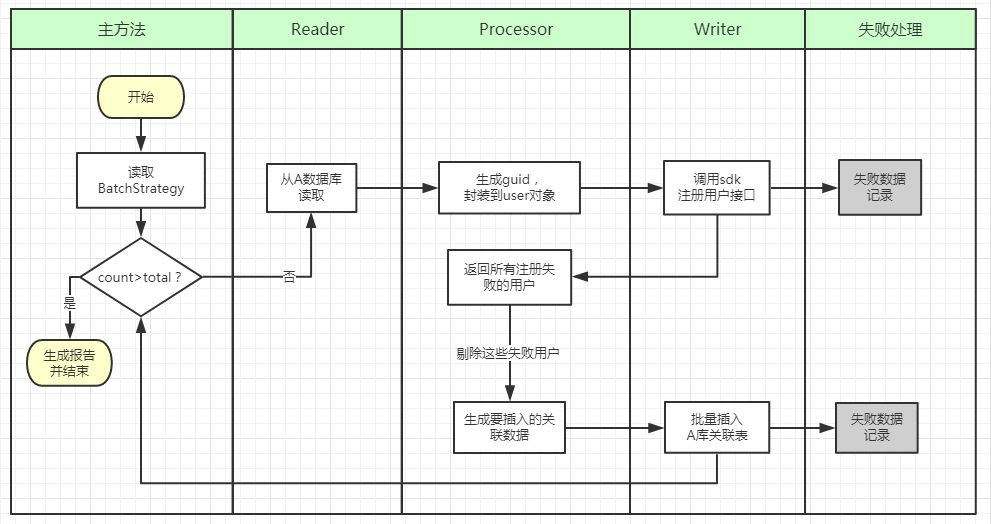
3.1、架構設計
根據第一版設計的問題,第二版有了一些改進。當然最明顯的就是從面向過程的思想轉變為面向物件。
我將整個過程抽離出來,分配給不同的物件去處理。這樣,我所分配的物件時這樣的:
1、一個配置物件:BatchStrategy。負責從配置檔案中讀取本次任務的策略並傳遞給執行者,配置包括基礎配置如總條數,每次批次查詢的數量,每次批次插入的數量。還有一些資料源方面的,如來源表的表名、列名、等,這樣如果換成其他資料庫的類似匯入,就能供透過配置進行拓展了。
2、三個執行者:整個執行過程可以分成三個部分:讀資料–處理資料–寫資料,可以分別交給三個物件Reader,Processor,Writer進行。這樣如果某一處邏輯變了,可以單獨進行改變而不影響其他環節。
3、一個失敗資料處理類:ErrorHandler。這樣每當有資料出現異常時,便把改資料扔給這個類,在這給類中進行寫入日誌,或者其他的處理辦法。在一定程度上將失敗資料的處理解耦。
這種設計很大程度上解除了耦合,尤其是失敗資料的處理基本上完全解耦。但由於整個執行過程仍然是需要有一個main來分別呼叫三個物件處理任務,因此三者之間還是沒有完全解耦,main部分的邏輯依然是面向過程的思想,比較複雜。即使把main中執行的邏輯抽出一個service,這個問題依然沒有解決。
3.2、效率問題
由於將第一版的逐條插入改為批次插入。其中sdk介面部分是批次傳入一組資料,減少了http請求的次數。生成關聯表的部分是用了jdbc batch操作,將之前逐條插入的excute改為excuteBatch,效率提升很明顯。這兩部分批次帶來的效率提升,將原本需要兩個月時間的程式碼,提升到了21天,但依然是天文數字。
可以看出,本次效率提升僅僅是在減少http請求次數,最佳化sql的插入邏輯方面做出來努力,但依然沒有解決第一版的一個致命問題,就是一次迴圈的速度依然受制於整個鏈條中最慢的一環,三者沒有解耦也可以從這一點看出,在其他兩者沒有將工作做完時,就只能傻等,這是效率損失最嚴重的地方了。
四、第三版:完全解耦(佇列+多執行緒)——3天
特徵:面向物件、多執行緒、可拓展、完全解耦、批次插入、資料可恢復。
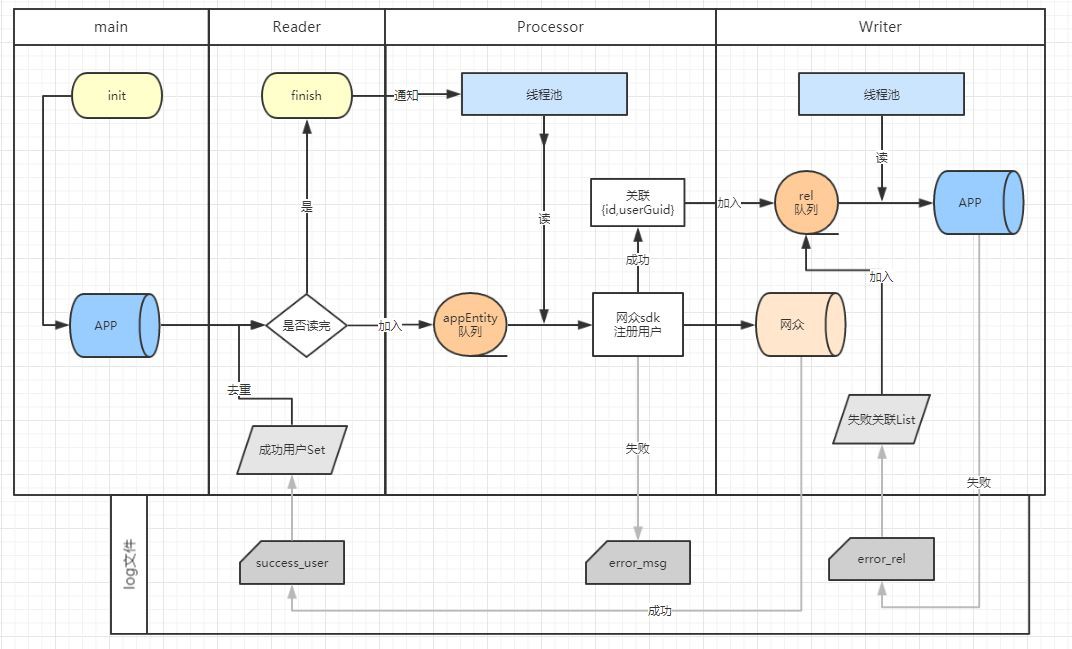
4.1、架構設計
該版並沒有程式碼實現,但確是過度到下一版的重要思考過程,故記錄在次。這一版本較上一版的重大改進之處有兩點:佇列和多執行緒。
佇列:其中佇列的使用使上一版未完全解耦的執行類之間,實現了完全解耦,將同步過程變為非同步,同時也是多執行緒能夠使用的前提。Reader做的事就是讀取資料,並放入佇列,至於它的下一個環節Processor如何處理佇列的資料,它完全不用理會,這時便可以繼續讀取資料。這便做到了完全解耦,處理佇列的資料也能夠使用多執行緒了。
多執行緒:Processor和Writer所做的事情,就是讀取自身佇列中的資料,然後處理。只不過Processor比Writer還承擔了一個往下一環佇列裡放資料的過程。此處的佇列用的是多執行緒安全佇列ConcurrentLinkedQueue。因此可以肆無忌憚地使用多執行緒來執行這兩者的任務。由於各個環節之間的完全解耦,某一環上的偶爾卡主並不再影響整個過程的進度,所以效率提升不知一兩點。
還有一點就是資料的可恢復性在這個設計中有了保障,成功過的使用者被儲存起來以便再次執行不會衝突,失敗的關聯表資料也被記錄下來,在下次執行時Writer會先將這一部分加入到自己的佇列裡,整個資料的正確性就有了一個不是特別完善的方案,效率也有了可觀的提升。
4.2、效率問題
雖然效率從21天提升到了3天,但我們還要思考一些問題。實際在執行的過程中發現,Writer所完成的資料總是緊跟在Processor之後。這就說明Processor的處理速度要慢於Writer,因為Processor插入資料庫之前還要走一段註冊使用者的業務邏輯。這就有個問題,當上一環的速度慢過下一環時,還有必要進行批次的操作麼?答案是不需要的。試想一下,如果你在生產線上,你的上一環2秒鐘處理一個零件,而你的速度是1秒鐘一個。這時即使你的批次處理速度更快,從系統最優的角度考慮,你也應該來一個零件就馬上處理,而不是等積攢到100個再批次處理。
還有一個問題是,我們從未考慮過Reader的效能。實際上我用的是limit操作來批次讀取資料庫,而mysql的limit是先全表查再擷取,當起始位置很大時,就會越來越慢。0-1000萬還算輕鬆,但1000萬到2000萬簡直是“寸步難行”。所以最終效率的瓶頸反而落到了讀庫操作上。
五、第四版:高度抽象(一鍵啟動)——4小時
特徵:面向介面、多執行緒、可拓展、完全解耦、批次或逐條插入、資料可恢復、最佳化查詢的limit操作
5.1、架構的思考
優雅的程式碼應該是整潔而美妙,不應是冗長而複雜的。這一版將會設計出簡潔度如第一版,而效能和拓展性超越所有版本的架構。
透過總結前三版特徵,我發現不論是Reader,Processor,Writer,都有共同的特徵:啟動任務、處理任務、結束任務。而Reader和Processor又有一個共同的可以向下一道工序傳遞資料,通知下一道工序資料傳遞結束的功能。他們就像生產線上的一個個工序,相互關聯而又各自獨立地執行著。每一道工序都可以啟動,瘋狂地處理任務,直到上一道工序通知結束為止。而第一個發起通知結束的便是Reader,之後便一個通知下一個,直到整個工序停止,這個過程就是美妙的。

因此我們可以將這三者都看做是Job,除了Reader外又都有與上一道工序互動的能力(其實Reader的上一道工序就是資料庫),因此便有瞭如下的介面設計。
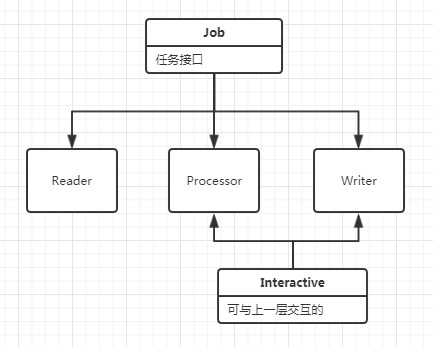
1 /**
2 * 工作步驟介面.
3 */
4 public interface Job {
5 void init();
6 void start();
7 void stop();
8 void finish();
9 }
1 /**
2 * 可互動的(傳入,通知結束).
3 */
4 public interface Interactive {
5
6 /**
7 * 開放與外界互動的通道
8 */
9 void openInteract();
10
11 /**
12 * 接收外界傳來的資料
13 * @param t
14 */
15 void receive(T t);
16
17 /**
18 * 關閉互動的通道
19 */
20 void closeInteract();
21
22 /**
23 * 是否處於可互動的狀態
24 * @return true可互動的 false不可互動的活已關閉互動狀態
25 */
26 boolean isInteractive();
27
28 } 有了這樣的介面設計,不論實現類具體怎麼寫,主方法已經可以寫出了,變得異常整潔有序。
只提煉主幹部分,去掉了一些細枝末節,如日誌輸出、時間記錄等。
1 public static void main(String[] args) {
2
3 Job reader = Reader.getInstance();
4 Job processor = Processor.getInstance();
5 Job writer = Writer.getInstance();
6
7 reader.init();
8 processor.init();
9 writer.init();
10
11 start(reader, processor, processor, processor, writer, writer);
12
13 }
14
15 private static void start(Job... jobs){
16 for (Job job:jobs) {
17 Thread thread = new Thread(new Runnable() {
18 @Override
19 public void run() {
20 job.start();
21 }
22 });
23 thread.start();
24 }
25 } 下來就是具體實現類的問題了,這裡實現類主要實現的是三個功能:
1、接收上一環的資料:屬於Interactive介面的receive方法的實現,基於之前的設計,即是物件中有一個ConcurrentLinkedQueue型別的屬性,用來接收上一環傳來的資料。
2、處理資料並傳遞給下一環:在每一個(有下一環的)物件屬性中,放入下一環的物件。如Reader中要有Processor物件,Processor要有Writer,一旦有資料需要加入下一環的佇列,呼叫其receiive方法即可。
3、告訴下一環我結束了:本任務結束時,呼叫下一環物件的closeInteractive方法。而每個物件判斷自身結束的方法視情況而定,比如Reader結束的條件是批次讀取的資料超過了一開始設定的total,說明資料讀取完畢,可以結束。而Processor結束的條件是,它被上一環通知了結束,並且從自己的佇列中poll不出東西了,證明應該結束,結束後再通知下一環節。這樣整個工序就安全有序地退出了。不過由於是多執行緒,所以Processor不能貿然通知Writer結束訊號,需要在Processor內部弄一個計數器,只有計數器達到預期的數量的那個執行緒的Processor,才能發起結束通知。
5.2、效率問題:
正如上一版提出的,Processor的處理速度要慢於Writer,所以Writer並不需要用batch去處理資料的插入,該成逐條插入反而是提高效能的一種方式。
大資料量limit操作十分耗時,由於測試部分只是在前幾百萬條測試,所以還是大大低估了效率的損失。在後幾百萬條可以說每一次limit的讀取都寸步難行。考慮到這個問題,我選去了唯一一個有索引並且稍稍易於排序的欄位“使用者的手機號”,(不想吐槽它們設計表的時候居然沒有自增id。。。),每次全表將手機號排序,再limit查詢。查詢之後將最後一條的手機號儲存起來,成為當前讀取的最後一條資料的一個標識。下次再limit操作就可以從這個手機號之後開始查詢了。這樣每次查詢不論從哪裡開始,速度都是一樣的。雖然前面部分的資料速度與之前的方案相比慢了不少,但卻完美解決了大資料量limit操作的超長等待時間,預防了危險的發生。
至此,專案架構再次簡潔起來,但同第一版相比,已經不是同一級別的簡潔了。
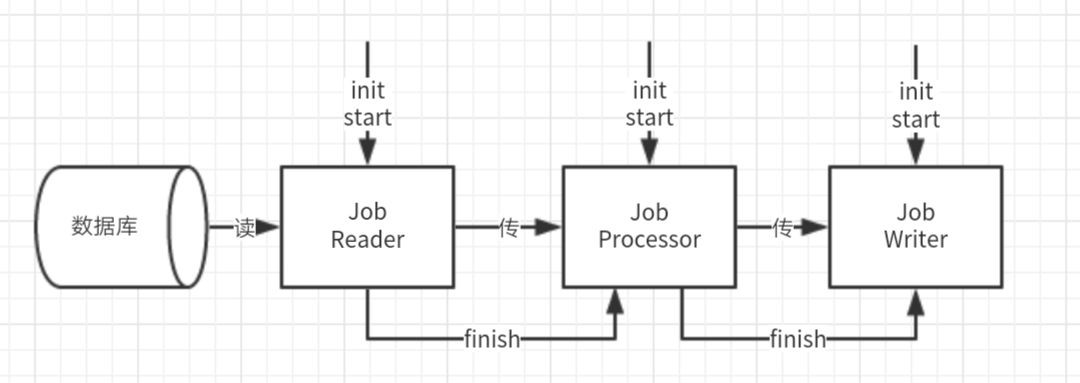
六、關於繼續最佳化的思考
1、Reader部分是單執行緒在處理,由於讀取是從資料庫中,並不是佇列中,因此設計成多執行緒有些麻煩,但並不是不可,這裡是最佳化點
2、日誌部分佔有很大一部分比例,2000萬條讀、處理、寫就要有至少6000萬次日誌輸出。如果設計成非同步處理,效率會提升不少。
這就是我本次專案最佳化的心得體會,還望各位大神予以指點。因為程式碼是公司為了避嫌,就不發到github了,感興趣的大神可以私聊。
備註:文中繪圖工具使用的是ProcessOn!
●編號752,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
