
導讀:隨著機器學習的興起,Python 逐步成為了「最受歡迎」的語言。它簡單易用、邏輯明確並擁有海量的擴充套件包,因此其不僅成為機器學習與資料科學的首選語言,同時在網頁、資料爬取可科學研究等方面成為不二選擇。此外,很多入門級的機器學習開發者都是跟隨大流選擇 Python,但到底為什麼要選擇 Python 就是本文的核心內容。
來源:機器之心(ID:almosthuman2014)編譯
參與:卓匯源、思源

本教程的目的是讓你相信兩件事:首先,Python 是一種非常棒的程式語言;其次,如果你是一名科學家,Python 很可能值得你去學習。本教程並非想要說明 Python 是一種萬能的語言;相反,作者明確討論了在幾種情況下,Python 並不是一種明智的選擇。本教程的目的只是提供對 Python 一些核心特徵的評論,並闡述作為一種通用的科學計算語言,它比其他常用的替代方案(最著名的是 R 和 Matlab)更有優勢。
本教程的其餘部分假定你已經有了一些程式設計經驗,如果你非常精通其他以資料為中心的語言(如 R 或 Matlab),理解本教程就會非常容易。本教程不能算作一份關於 Python 的介紹,且文章重點在於為什麼應該學習 Python 而不是怎樣寫 Python 程式碼(儘管其他地方有大量的優秀教程)。
00 概述
Python 是一種廣泛使用、易於學習、高階、通用的動態程式語言。這很令人滿意,所以接下來分開討論一些特徵。
01 Python(相對來說)易於學習
程式設計很難,因此從絕對意義上來說,除非你已經擁有程式設計經驗,否則程式語言難以學習。但是,相對而言,Python 的高階屬性(見下一節)、語法可讀性和語意直白性使得它比其他語言更容易學習。例如,這是一個簡單 Python 函式的定義(故意未註釋),它將一串英語單詞轉換為(crummy)Pig Latin:
def pig_latin(text):
''' Takes in a sequence of words and converts it to (imperfect) pig latin. '''
word_list = text.split(' ')
output_list = []
for word in word_list:
word = word.lower()
if word.isalpha():
first_char = word[0]
if first_char in 'aeiou':
word = word + 'ay'
else:
word = word[1:] + first_char + 'yay'
output_list.append(word)
pygged = ' '.join(output_list)
return pygged
以上函式事實上無法生成完全有效的 Pig Latin(假設存在「有效 Pig Latin」),但這沒有關係。有些情況下它是可行的:
test1 = pig_latin("let us see if this works")
print(test1)
拋開 Pig Latin 不說,這裡的重點只是,出於幾個原因,程式碼是很容易閱讀的。首先,程式碼是在高階抽象中編寫的(下麵將詳細介紹),因此每行程式碼都會對映到一個相當直觀的操作。這些操作可以是「取這個單詞的第一個字元」,而不是對映到一個沒那麼直觀的低階操作,例如「為一個字元預留一個位元組的記憶體,稍後我會傳入一個字元」。
其次,控制結構(如,for—loops,if—then 條件等)使用諸如「in」,「and」和「not」的簡單單詞,其語意相對接近其自然英語含義。
第三,Python 對縮排的嚴格控制強加了一種使程式碼可讀的規範,同時防止了某些常見的錯誤。
第四,Python 社群非常強調遵循樣式規定和編寫「Python 式的」程式碼,這意味著相比使用其他語言的程式員而言,Python 程式員更傾向於使用一致的命名規定、行的長度、程式設計習慣和其他許多類似特徵,它們共同使別人的程式碼更易閱讀(儘管這可以說是社群的一個特徵而不是語言本身)。
02 Python 是一種高階語言
與其他許多語言相比,Python 是一種相對「高階」的語言:它不需要(並且在許多情況下,不允許)使用者擔心太多底層細節,而這是其他許多語言需要去處理的。
例如,假設我們想建立一個名為「my_box_of_things」的變數當作我們所用東西的容器。我們事先不知道我們想在盒子中保留多少物件,同時我們希望在新增或刪除物件時,物件數量可以自動增減。所以這個盒子需要佔據一個可變的空間:在某個時間點,它可能包含 8 個物件(或「元素」),而在另一個時間點,它可能包含 257 個物件。
在像 C 這樣的底層語言中,這個簡單的要求就已經給我們的程式帶來了一些複雜性,因為我們需要提前宣告盒子需要佔據多少空間,然後每次我們想要增加盒子需要的空間時,我需要明確建立一個佔據更多空間的全新的盒子,然後將所有東西複製到其中。
相比之下,在 Python 中,儘管在底層這些過程或多或少會發生(效率較低),但我們在使用高階語言編寫時並不需要擔心這一部分。從我們的角度來看,我們可以建立自己的盒子並根據喜好新增或刪除物件:
# Create a box (really, a 'list') with 5 things# Create
my_box_of_things = ['Davenport', 'kettle drum', 'swallow-tail coat', 'table cloth', 'patent leather shoes']
print(my_box_of_things)
['Davenport', 'kettle drum', 'swallow-tail coat', 'table cloth', 'patent leather shoes']
# Add a few more things
my_box_of_things += ['bathing suit', 'bowling ball', 'clarinet', 'ring']
# Maybe add one last thing
my_box_of_things.append('radio that only needs a fuse')
# Let's see what we have...
print(my_box_of_things)更一般來說,Python(以及根據定義的其他所有高階語言)傾向於隱藏需要在底層語言中明確表達的各種死記硬背的宣告。這使得我們可以編寫非常緊湊、清晰的程式碼(儘管它通常以降低效能為代價,因為內部不再可訪問,因此最佳化變得更加困難)。
例如,考慮從檔案中讀取純文字這樣看似簡單的行為。對於與檔案系統直接接觸而傷痕纍纍的開發者來說,從概念上看似乎只需要兩個簡單的操作就可以完成:首先開啟一個檔案,然後從其中讀取。實際過程遠不止這些,並且比 Python 更底層的語言通常強制(或至少是鼓勵)我們去承認這一點。例如,這是在 Java 中從檔案中讀取內容的規範(儘管肯定不是最簡潔的)方法:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class ReadFile {
public static void main(String[] args) throws IOException{
String fileContents = readEntireFile("./foo.txt");
}
private static String readEntireFile(String filename) throws IOException {
FileReader in = new FileReader(filename);
StringBuilder contents = new StringBuilder();
char[] buffer = new char[4096];
int read = 0;
do {
contents.append(buffer, 0, read);
read = in.read(buffer);
} while (read >= 0);
return contents.toString();
}
}你可以看到我們不得不做一些令人苦惱的事,例如匯入檔案讀取器、為檔案中的內容建立一個快取,以塊的形式讀取檔案塊並將它們分配到快取中等等。相比之下,在 Python 中,讀取檔案中的全部內容只需要如下程式碼:
# Read the contents of "hello_world.txt"
text = open("hello_world.txt").read()
當然,這種簡潔性並不是 Python 獨有的;還有其他許多高階語言同樣隱藏了簡單請求所暗含的大部分令人討厭的內部過程(如,Ruby,R,Haskell 等)。但是,相對來說比較少有其他語言能與接下來探討的 Python 特徵相媲美。
03 Python 是一種通用語言
根據設計,Python 是一種通用的語言。也就是說,它旨在允許程式員在任何領域編寫幾乎所有型別的應用,而不是專註於一類特定的問題。在這方面,Python 可以與(相對)特定領域的語言進行對比,如 R 或 PHP。這些語言原則上可用於很多情形,但仍針對特定用例進行了明確最佳化(在這兩個示例中,分別用於統計和網路後端開發)。
Python 通常被親切地成為「所有事物的第二個最好的語言」,它很好地捕捉到了這樣的情緒,儘管在很多情況下 Python 並不是用於特定問題的最佳語言,但它通常具有足夠的靈活性和良好的支援性,使得人們仍然可以相對有效地解決問題。
事實上,Python 可以有效地應用於許多不同的應用中,這使得學習 Python 成為一件相當有價值的事。因為作為一個軟體開發人員,能夠使用單一語言實現所有事情,而不是必鬚根據所執行的專案在不同語言和環境間進行切換,是一件非常棒的事。
1. 標準庫
透過瀏覽標準庫中可用的眾多模組串列,即 Python 直譯器自帶的工具集(沒有安裝第三方軟體包),這可能是最容易理解 Python 通用性的方式。若考慮以下幾個示例:
-
os: 系統操作工具
-
re:正則表達
-
collections:有用的資料結構
-
multiprocessing:簡單的並行化工具
-
pickle:簡單的序列化
-
json:讀和寫 JSON
-
argparse:命令列引數解析
-
functools:函式化程式設計工具
-
datetime:日期和時間函式
-
cProfile:分析程式碼的基本工具
這張串列乍一看並不令人印象深刻,但對於 Python 開發者來說,使用它們是一個相對常見的經歷。很多時候用谷歌搜尋一個看似重要甚至有點深奧的問題,我們很可能找到隱藏在標準庫模組內的內建解決方案。
2. JSON,簡單的方法
例如,假設你想從 web.JSON 中讀取一些 JSON 資料,如下所示:
data_string = '''
[
{
"_id": "59ad8f86450c9ec2a4760fae",
"name": "Dyer Kirby",
"registered": "2016-11-28T03:41:29 +08:00",
"latitude": -67.170365,
"longitude": 130.932548,
"favoriteFruit": "durian"
},
{
"_id": "59ad8f8670df8b164021818d",
"name": "Kelly Dean",
"registered": "2016-12-01T09:39:35 +08:00",
"latitude": -82.227537,
"longitude": -175.053135,
"favoriteFruit": "durian"
}
]
'''
我們可以花一些時間自己編寫 json 解析器,或試著去找一個有效讀取 json 的第三方包。但我們很可能是在浪費時間,因為 Python 內建的 json 模組已經能完全滿足我們的需要:
import json
data = json.loads(data_string)
print(data)
'''
[{'_id': '59ad8f86450c9ec2a4760fae', 'name': 'Dyer Kirby', 'registered': '2016-11-28T03:41:29 +08:00', 'latitude': -67.170365, 'longitude': 130.932548, 'favoriteFruit': 'durian'}, {'_id': '59ad8f8670df8b164021818d', 'name': 'Kelly Dean', 'registered': '2016-12-01T09:39:35 +08:00', 'latitude': -82.227537, 'longitude': -175.053135, 'favoriteFruit': 'durian'}]
請註意,在我們能於 json 模組內使用 loads 函式前,我們必須匯入 json 模組。這種必須將幾乎所有功能模組明確地匯入名稱空間的樣式在 Python 中相當重要,且基本名稱空間中可用的內建函式串列非常有限。
許多用過 R 或 Matlab 的開發者會在剛接觸時感到惱火,因為這兩個包的全域性名稱空間包含數百甚至上千的內建函式。但是,一旦你習慣於輸入一些額外字元,它就會使程式碼更易於讀取和管理,同時命名衝突的風險(R 語言中經常出現)被大大降低。
3. 優異的外部支援
當然,Python 提供大量內建工具來執行大量操作並不意味著總需要去使用這些工具。可以說比 Python 豐富的標準庫更大的賣點是龐大的 Python 開發者社群。多年來,Python 一直是世界上最流行的動態程式語言,開發者社群也貢獻了眾多高質量的安裝包。
如下 Python 軟體包在不同領域內提供了被廣泛使用的解決方案(這個串列在你閱讀本文的時候可能已經過時了!):
-
Web 和 API 開發:flask,Django,Falcon,hug
-
爬取資料和解析文字/標記: requests,beautifulsoup,scrapy
-
自然語言處理(NLP):nltk,gensim,textblob
-
數值計算和資料分析:numpy,scipy,pandas,xarray
-
機器學習:scikit-learn,Theano,Tensorflow,keras
-
影象處理:pillow,scikit-image,OpenCV
-
作圖:matplotlib,seaborn,ggplot,Bokeh
-
等等
Python 的一個優點是有出色的軟體包管理生態系統。雖然在 Python 中安裝包通常比在 R 或 Matlab 中更難,這主要是因為 Python 包往往具有高度的模組化和/或更多依賴於系統庫。但原則上至少大多數 Python 的包可以使用 pip 包管理器透過命令提示符安裝。更複雜的安裝程式和包管理器,如 Anaconda 也大大減少了配置新 Python 環境時產生的痛苦。
04 Python 是一種(相對)快速的語言
這可能令人有點驚訝:從錶面上看,Python 是一種快速語言的說法看起來很愚蠢。因為在標準測試時,和 C 或 Java 這樣的編譯語言相比,Python 通常會卡頓。毫無疑問,如果速度至關重要(例如,你正在編寫 3D 圖形引擎或執行大規模的流體動力學模擬實驗),Python 可能不會成為你最優選擇的語言,甚至不會是第二好的語言。
但在實際中,許多科學家工作流程中的限制因素不是執行時間而是開發時間。一個花費一個小時執行但只需要 5 分鐘編寫的指令碼通常比一個花費 5 秒鐘執行但是需要一個禮拜編寫和除錯的指令碼更合意。
此外,正如我們將在下麵看到的,即使我們所用的程式碼都用 Python 編寫,一些最佳化操作通常可以使其執行速度幾乎與基於 C 的解決方案一樣快。實際上,對大多數科學家家來說,基於 Python 的解決方案不夠快的情況並不是很多,而且隨著工具的改進,這種情況的數量正在急劇減少。
1. 不要重覆做功
軟體開發的一般原則是應該盡可能避免做重覆工作。當然,有時候是沒法避免的,並且在很多情況下,為問題編寫自己的解決方案或建立一個全新的工具是有意義的。但一般來說,你自己編寫的 Python 程式碼越少,效能就越好。有以下幾個原因:
-
Python 是一種成熟的語言,所以許多現有的包有大量的使用者基礎並且經過大量最佳化。例如,對 Python 中大多數核心科學庫(numpy,scipy,pandas 等)來說都是如此。
-
大多數 Python 包實際上是用 C 語言編寫的,而不是用 Python 編寫的。對於大多數標準庫,當你呼叫一個 Python 函式時,實際上很大可能你是在執行具有 Python 介面的 C 程式碼。這意味著無論你解決問題的演演算法有多精妙,如果你完全用 Python 編寫,而內建的解決方案是用 C 語言編寫的,那你的效能可能不如內建的方案。例如,以下是執行內建的 sum 函式(用 C 編寫):
# Create a list of random floats
import random
my_list = [random.random() for i in range(10000)]
# Python's built-in sum() function is pretty fast
%timeit sum(my_list)
47.7 µs ± 4.5 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
從演演算法上來說,你沒有太多辦法來加速任意數值串列的加和計算。所以你可能會想這是什麼鬼,你也許可以用 Python 自己寫加和函式,也許這樣可以封裝內建 sum 函式的開銷,以防它進行任何內部驗證。嗯……並非如此。
def ill_write_my_own_sum_thank_you_very_much(l):
s = 0
for elem in my_list:
s += elem
return s
%timeit ill_write_my_own_sum_thank_you_very_much(my_list)
331 µs ± 50.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
至少在這個例子中,執行你自己簡單的程式碼很可能不是一個好的解決方案。但這不意味著你必須使用內建 sum 函式作為 Python 中的效能上限!由於 Python 沒有針對涉及大型輸入的數值運算進行最佳化,因此內建方法在加和大型串列時是表現次優。
在這種情況下我們應該做的是提問:「是否有其他一些 Python 庫可用於對潛在的大型輸入進行數值分析?」正如你可能想的那樣,答案是肯定的:NumPy 包是 Python 的科學生態系統中的主要成分,Python 中的絕大多數科學計算包都以某種方式構建在 NumPy 上,它包含各種能幫助我們的計算函式。
在這種情況下,新的解決方案是非常簡單的:如果我們將純 Python 串列轉化為 NumPy 陣列,我們就可以立即呼叫 NumPy 的 sum 方法,我們可能期望它應該比核心的 Python 實現更快(技術上講,我們可以傳入一個 Python 串列到 numpy.sum 中,它會隱式地將其轉換為陣列,但如果我們打算復用該 NumPy 陣列,最好明確地轉化它)。
import numpy as np
my_arr = np.array(my_list)
%timeit np.sum(my_arr)
7.92 µs ± 1.15 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each)
因此簡單地切換到 NumPy 可加快一個數量級的串列加和速度,而不需要自己去實現任何東西。
2. 需要更快的速度?
當然,有時候即使使用所有基於 C 的擴充套件包和高度最佳化的實現,你現有的 Python 程式碼也無法快速削減時間。在這種情況下,你的下意識反應可能是放棄並轉化到一個「真正」的語言。並且通常,這是一種完全合理的本能。但是在你開始使用 C 或 Java 移植程式碼前,你需要考慮一些不那麼費力的方法。
3. 使用 Python 編寫 C 程式碼
首先,你可以嘗試編寫 Cython 程式碼。Cython 是 Python 的一個超集(superset),它允許你將(某些)C 程式碼直接嵌入到 Python 程式碼中。Cython 不以編譯的方式執行,相反你的 Python 檔案(或其中特定的某部分)將在執行前被編譯為 C 程式碼。實際的結果是你可以繼續編寫看起來幾乎完全和 Python 一樣的程式碼,但仍然可以從 C 程式碼的合理引入中獲得效能提升。特別是簡單地提供 C 型別的宣告通常可以顯著提高效能。
以下是我們簡單加和程式碼的 Cython 版本:
# Jupyter extension that allows us to run Cython cell magics
%load_ext Cython
The Cython extension is already loaded. To reload it, use:
%reload_ext Cython
%%%%cythoncython
defdef ill_write_my_own_cython_sum_thank_you_very_muchill_write (list arr):
cdef int N = len(arr)
cdef float x = arr[0]
cdef int i
for i in range(1 ,N):
x += arr[i]
return x
%timeit ill_write_my_own_cython_sum_thank_you_very_much(my_list)
227 µs ± 48.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
關於 Cython 版本有幾點需要註意一下。首先,在你第一次執行定義該方法的單元時,需要很少的(但值得註意的)時間來編譯。那是因為,與純粹的 Python 不同,程式碼在執行時不是逐行解譯的;相反,Cython 式的函式必須先編譯成 C 程式碼才能呼叫。
其次,雖然 Cython 式的加和函式比我們上面寫的簡單的 Python 加和函式要快,但仍然比內建求和方法和 NumPy 實現慢得多。然而,這個結果更有力地說明瞭我們特定的實現過程和問題的本質,而不是 Cython 的一般好處;在許多情況下,一個有效的 Cython 實現可以輕易地將執行時間提升一到兩個數量級。
4. 使用 NUMBA 進行清理
Cython 並不是提升 Python 內部效能的唯一方法。從開發的角度來看,另一種更簡單的方法是依賴於即時編譯,其中一段 Python 程式碼在第一次呼叫時被編譯成最佳化的 C 程式碼。近年來,在 Python 即時編譯器上取得了很大進展。也許最成熟的實現可以在 numba 包中找到,它提供了一個簡單的 jit 修飾器,可以輕易地結合其他任何方法。
我們之前的示例並沒有強調 JITs 可以產生多大的影響,所以我們轉向一個稍微複雜點的問題。這裡我們定義一個被稱為 multiply_randomly 的新函式,它將一個一維浮點數陣列作為輸入,並將陣列中的每個元素與其他任意一個隨機選擇的元素相乘。然後它傳回所有隨機相乘的元素和。
讓我們從定義一個簡單的實現開始,我們甚至都不採用向量化來代替隨機相乘操作。相反,我們簡單地遍歷陣列中的每個元素,從中隨機挑選一個其他元素,將兩個元素相乘並將結果分配給一個特定的索引。如果我們用基準問題測試這個函式,我們會發現它執行得相當慢。
import numpy as np
def multiply_randomly_naive(l):
n = l.shape[0]
result = np.zeros(shape=n)
for i in range(n):
ind = np.random.randint(0, n)
result[i] = l[i] * l[ind]
return np.sum(result)
%timeit multiply_randomly_naive(my_arr)
25.7 ms ± 4.61 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
在我們即時編譯之前,我們應該首先自問是否上述函式可以用更加符合 NumPy 形式的方法編寫。NumPy 針對基於陣列的操作進行了最佳化,因此應該不惜一切代價地避免使用迴圈操作,因為它們會非常慢。幸運的是,我們的程式碼非常容易向量化(並且易於閱讀):
def multiply_randomly_vectorized(l):
n = len(l)
inds = np.random.randint(0, n, size=n)
result = l * l[inds]
return np.sum(result)
%timeit multiply_randomly_vectorized(my_arr)
234 µs ± 50.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
在作者的機器上,向量化版本的執行速度比迴圈版本的程式碼快大約 100 倍。迴圈和陣列操作之間的這種效能差異對於 NumPy 來說是非常典型的,因此我們要在演演算法上思考你所做的事的重要性。
假設我們不是花時間重構我們樸素的、緩慢的實現,而是簡單地在我們的函式上加一個修飾器去告訴 numba 庫我們要在第一次呼叫它時將函式編譯為 C。字面上,下麵的函式 multiply_randomly_naive_jit 與上面定義的函式 multiply_randomly_naive 之間的唯一區別是 @jit 修飾器。當然,4 個小字元是沒法造成那麼大的差異的。對吧?
import numpy as np
from numba import jit
@jit
def multiply_randomly_naive_jit(l):
n = l.shape[0]
result = np.zeros(shape=n)
for i in range(n):
ind = np.random.randint(0, n)
result[i] = l[i] * l[ind]
return np.sum(result)
%timeit multiply_randomly_naive_jit(my_arr)
135 µs ± 22.4 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
令人驚訝的是,JIT 編譯版本的樸素函式事實上比向量化的版本跑得更快。
有趣的是,將 @jit 修飾器應用於函式的向量化版本(將其作為聯絡留給讀者)並不能提供更多幫助。在 numba JIT 編譯器用於我們的程式碼之後,Python 實現的兩個版本都以同樣的速度執行。因此,至少在這個例子中,即時編譯不僅可以毫不費力地為我們提供類似 C 的速度,而且可以避免以 Python 式地去最佳化程式碼。
這可能是一個相當有力的結論,因為(a)現在 numba 的 JIT 編譯器只改寫了 NumPy 特徵的一部分,(b)不能保證編譯的程式碼一定比解譯的程式碼執行地更快(儘管這通常是一個有效的假設)。
這個例子真正的目的是提醒你,在你宣稱它慢到無法去實現你想要做的事之前,其實你在 Python 中有許多可用的選擇。值得註意的是,如 C 整合和即時編譯,這些效能特徵都不是 Python 獨有的。Matlab 最近的版本自動使用即時編譯,同時 R 支援 JIT 編譯(透過外部庫)和 C ++ 整合(Rcpp)。
05 Python 是天生面向物件的
即使你正在做的只是編寫一些簡短的指令碼去解析文字或挖掘一些資料,Python 的許多好處也很容易領會到。在你開始編寫相對大型的程式碼片段前,Python 的最佳功能之一可能並不明顯:Python 具有設計非常優雅的基於物件的資料模型。事實上,如果你檢視底層,你會發現 Python 中的一切都是物件。甚至函式也是物件。當你呼叫一個函式的時候,你事實上正在呼叫 Python 中每個物件都執行的 __call__ 方法:
def double(x):
return x*2
# Lists all object attributes
dir(double)
['__annotations__',
'__call__',
'__class__',
'__closure__',
'__code__',
'__defaults__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__get__',
'__getattribute__',
'__globals__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__kwdefaults__',
'__le__',
'__lt__',
'__module__',
'__name__',
'__ne__',
'__new__',
'__qualname__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__']事實上,因為 Python 中的一切都是物件,Python 中的所有內容遵循相同的核心邏輯,實現相同的基本 API,並以類似的方式進行擴充套件。物件模型也恰好非常靈活:可以很容易地定義新的物件去實現有意思的事,同時仍然表現得相對可預測。也許並不奇怪,Python 也是編寫特定領域語言(DSLs)的一個絕佳選擇,因為它允許使用者在很大程度上多載和重新定義現有的功能。
魔術方法
Python 物件模型的核心部分是它使用「魔術」方法。這些在物件上實現的特殊方法可以更改 Python 物件的行為——通常以重要的方式。魔術方法(Magic methods)通常以雙下劃線開始和結束,一般來說,除非你知道自己在做什麼,否則不要輕易篡改它們。但一旦你真的開始改了,你就可以做些相當了不起的事。
舉個簡單的例子,我們來定義一個新的 Brain 物件。首先,Barin 不會進行任何操作,它只會待在那兒禮貌地發獃。
class Brain(object):
def __init__(self, owner, age, status):
self.owner = owner
self.age = age
self.status = status
def __getattr__(self, attr):
if attr.startswith('get_'):
attr_name = attr.split('_')[1]
if hasattr(self, attr_name):
return lambda: getattr(self, attr_name)
raise AttributeError
在 Python 中,__init__ 方法是物件的初始化方法——當我們嘗試建立一個新的 Brain 實體時,它會被呼叫。通常你需要在編寫新類時自己實現__init__,所以如果你之前看過 Python 程式碼,那__init__ 可能看起來就比較熟悉了,本文就不再贅述。
相比之下,大多數使用者很少明確地實現__getattr__方法。但它控制著 Python 物件行為的一個非常重要的部分。具體來說,當使用者試圖透過點語法(如 brain.owner)訪問類屬性,同時這個屬性實際上並不存在時,__getattr__方法將會被呼叫。此方法的預設操作僅是引發一個錯誤:
# Create a new Brain instance
brain = Brain(owner="Sue", age="62", status="hanging out in a jar")
print(brain.owner)
---------------------------------------------------------------------------sue
print(brain.gender)---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)-136-52813a6b3567> in ()
----> 1 print(brain.gender)-133-afe64c3e086d> in __getattr__(self, attr)
12 if hasattr(self, attr_name):
13 return lambda: getattr(self, attr_name)
---> 14 raise AttributeError
AttributeError:
重要的是,我們不用忍受這種行為。假設我們想建立一個替代介面用於透過以「get」開頭的 getter 方法從 Brain 類的內部檢索資料(這是許多其他語言中的常見做法),我們當然可以透過名字(如 get_owner、get_age 等)顯式地實現 getter 方法。但假設我們很懶,並且不想為每個屬性編寫一個顯式的 getter。
此外,我們可能想要為已經建立的 Brains 類新增新的屬性(如,brain.foo = 4),在這種情況下,我們不需要提前為那些未知屬性建立 getter 方法(請註意,在現實世界中,這些是為什麼我們接下來要這麼做的可怕理由;當然這裡完全是為了舉例說明)。我們可以做的是,當使用者請求任意屬性時,透過指示 Brain 類的操作去改變它的行為。
在上面的程式碼片段中,我們的 __getattr__ 實現首先檢查了傳入屬性的名稱。如果名稱以 get_ 開頭,我們將檢查物件內是否存在期望屬性的名稱。如果確實存在,則傳回該物件。否則,我們會引發錯誤的預設操作。這讓我們可以做一些看似瘋狂的事,比如:
print(brain.get_owner())其他不可思議的方法允許你動態地控制物件行為的其他各種方面,而這在其他許多語言中你沒法做到。事實上,因為 Python 中的一切都是物件,甚至數學運運算元實際上也是對物件的秘密方法呼叫。
例如,當你用 Python 編寫運算式 4 + 5 時,你實際上是在整數物件 4 上呼叫 __add__,其引數為 5。如果我們願意(並且我們應該小心謹慎地行使這項權利!),我們能做的是建立新的特定領域的「迷你語言」,為通用運運算元註入全新的語意。
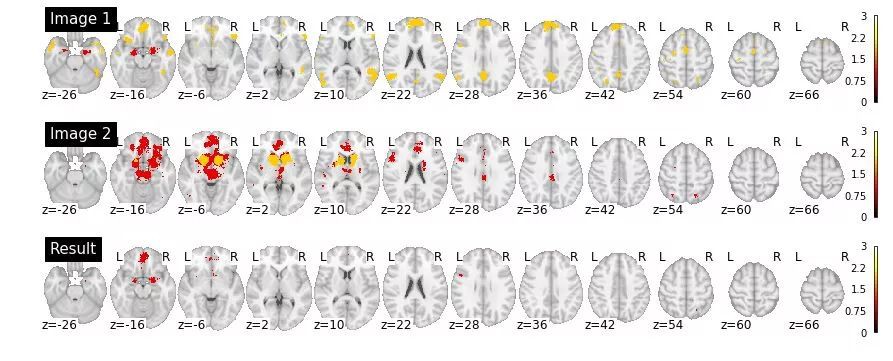
舉個簡單的例子,我們來實現一個表示單一 Nifti 容積的新類。我們將依靠繼承來實現大部分工作;只需從 nibabel 包中繼承 NiftierImage 類。我們要做的就是定義 __and__ 和 __or__ 方法,它們分別對映到 & 和 | 運運算元。看看在執行以下幾個單元前你是否搞懂了這段程式碼的作用(可能你需要安裝一些包,如 nibabel 和 nilearn)。
from nibabel import Nifti1Image
from nilearn.image import new_img_like
from nilearn.plotting import plot_stat_map
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
class LazyMask(Nifti1Image):
''' A wrapper for the Nifti1Image class that overloads the & and | operators
to do logical conjunction and disjunction on the image data. '''
def __and__(self, other):
if self.shape != other.shape:
raise ValueError("Mismatch in image dimensions: %s vs. %s" % (self.shape, other.shape))
data = np.logical_and(self.get_data(), other.get_data())
return new_img_like(self, data, self.affine)
def __or__(self, other):
if self.shape != other.shape:
raise ValueError("Mismatch in image dimensions: %s vs. %s" % (self.shape, other.shape))
data = np.logical_or(self.get_data(), other.get_data())
return new_img_like(self, data, self.affine)img1 = LazyMask.load('image1.nii.gz')
img2 = LazyMask.load('image2.nii.gz')
result = img1 & img2fig, axes = plt.subplots(3, 1, figsize=(15, 6))
p = plot_stat_map(img1, cut_coords=12, display_mode='z', title='Image 1', axes=axes[0], vmax=3)
plot_stat_map(img2, cut_coords=p.cut_coords, display_mode='z', title='Image 2', axes=axes[1], vmax=3)
p = plot_stat_map(result, cut_coords=p.cut_coords, display_mode='z', title='Result', axes=axes[2], vmax=3)
06 Python 社群
我在這裡提到的 Python 的最後一個特徵就是它優秀的社群。當然,每種主要的程式語言都有一個大型的社群致力於該語言的開發、應用和推廣;關鍵是社群內的人是誰。
一般來說,圍繞程式語言的社群更能反映使用者的興趣和專業基礎。對於像 R 和 Matlab 這樣相對特定領域的語言來說,這意味著為語言貢獻新工具的人中很大一部分不是軟體開發人員,更可能是統計學家、工程師和科學家等等。當然,統計學家和工程師沒什麼不好。例如,與其他語言相比,統計學家較多的 R 生態系統的優勢之一就是 R 具有一系列統計軟體包。
然而,由統計或科學背景使用者所主導的社群存在缺點,即這些使用者通常未受過軟體開發方面的訓練。因此,他們編寫的程式碼質量往往比較低(從軟體的角度看)。專業的軟體工程師普遍採用的最佳實踐和習慣在這種未經培訓的社群中並不出眾。例如,CRAN 提供的許多 R 包缺少類似自動化測試的東西——除了最小的 Python 軟體包之外,這幾乎是聞所未聞的。
另外在風格上,R 和 Matlab 程式員編寫的程式碼往往在人與人之間的一致性方面要低一些。結果是,在其他條件相同的情況下,用 Python 編寫軟體往往比用 R 編寫的程式碼具備更高的穩健性。雖然 Python 的這種優勢無疑與語言本身的內在特徵無關(一個人可以使用任何語言(包括 R、Matlab 等)編寫出極高質量的程式碼),但仍然存在這樣的情況,強調共同慣例和最佳實踐規範的開發人員社群往往會使大家編寫出更清晰、更規範、更高質量的程式碼。
07 結論
Python 太棒了。
原文連結:
https://github.com/neurohackweek/python-for-scientists/blob/master/Programming%20in%20Python.ipynb

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單 | 乾貨
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 高考 | 福利
猜你想看
-
pandas創始人手把手教你利用Python進行資料分析(思維導圖)
Q: 人生苦短,你用Python了嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

