來自:Linux中國,譯者:Chang Liu
linux.cn/article-9895-1.html
原文:https://linuxhandbook.com/cut-command/
cut 命令是用來從文字檔案中移除“某些列”的經典工具。在本文中的“一列”可以被定義為按照一行中位置區分的一系列字串或者位元組,或者是以某個分隔符為間隔的某些域。
先前我已經介紹瞭如何使用 AWK 命令。在本文中,我將解釋 linux 下 cut 命令的 4 個本質且實用的例子,有時這些例子將幫你節省很多時間。

Linux 下 cut 命令的 4 個實用示例
假如你想,你可以觀看下麵的影片,影片中解釋了本文中我列舉的 cut 命令的使用例子。
-
https://www.youtube.com/PhE_cFLzVFw
1、 作用在一系列字元上
當啟用 -c 命令列選項時,cut 命令將移除一系列字元。
和其他的過濾器類似, cut 命令不會直接改變輸入的檔案,它將複製已修改的資料到它的標準輸出裡去。你可以透過重定向命令的結果到一個檔案中來儲存修改後的結果,或者使用管道將結果送到另一個命令的輸入中,這些都由你來負責。
假如你已經下載了上面影片中的示例測試檔案,你將看到一個名為 BALANCE.txt 的資料檔案,這些資料是直接從我妻子在她工作中使用的某款會計軟體中匯出的:

上述檔案是一個固定寬度的文字檔案,因為對於每一項資料,都使用了不定長的空格做填充,使得它看起來是一個對齊的串列。
這樣一來,每一列資料開始和結束的位置都是一致的。從 cut 命令的字面意思去理解會給我們帶來一個小陷阱:cut 命令實際上需要你指出你想保留的資料範圍,而不是你想移除的範圍。所以,假如我只需要上面檔案中的 ACCOUNTNUM 和 ACCOUNTLIB 列,我需要這麼做:
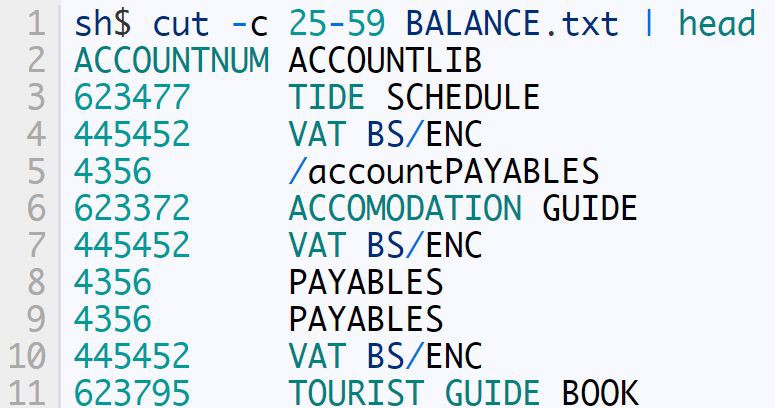
範圍如何定義?
正如我們上面看到的那樣, cut 命令需要我們特別指定需要保留的資料的範圍。所以,下麵我將更正式地介紹如何定義範圍:對於 cut 命令來說,範圍是由連字元(-)分隔的起始和結束位置組成,範圍是基於 1 計數的,即每行的第一項是從 1 開始計數的,而不是從 0 開始。範圍是一個閉區間,開始和結束位置都將包含在結果之中,正如它們之間的所有字元那樣。如果範圍中的結束位置比起始位置小,則這種運算式是錯誤的。作為快捷方式,你可以省略起始或結束值,正如下麵的表格所示:

cut 命令允許你透過逗號分隔多個範圍,下麵是一些示例:
# 保留 1 到 24 之間(閉區間)的字元
cut –c –24 BALANCE.txt
# 保留 1 到 24(閉區間)以及 36 到 59(閉區間)之間的字元
cut –c –24,36–59 BALANCE.txt
# 保留 1 到 24(閉區間)、36 到 59(閉區間)和 93 到該行末尾之間的字元
cut –c –24,36–59,93– BALANCE.txt
cut 命令的一個限制(或者是特性,取決於你如何看待它)是它將 不會對資料進行重排。所以下麵的命令和先前的命令將產生相同的結果,儘管範圍的順序做了改變:
cut –c 93–,–24,36–59 BALANCE.txt
你可以輕易地使用 diff 命令來驗證:
diff –s <(cut –c –24,36–59,93– BALANCE.txt)
<(cut –c 93–,–24,36–59 BALANCE.txt)
Files /dev/fd/63 and /dev/fd/62 are identical
類似的,cut 命令 不會重覆資料:
# 某人或許期待這可以第一列三次,但並不會……
cut –c –10,–10,–10 BALANCE.txt | head –5
ACCDOC
4
4
4
5
值得提及的是,曾經有一個提議,建議使用 -o 選項來去除上面提到的兩個限制,使得 cut 工具可以重排或者重覆資料。但這個提議被 POSIX 委員會拒絕了,“因為這類增強不屬於 IEEE P1003.2b 草案標準的範圍”。
據我所知,我還沒有見過哪個版本的 cut 程式實現了上面的提議,以此來作為擴充套件,假如你知道某些例外,請使用下麵的評論框分享給大家!
2、 作用在一系列位元組上
當使用 -b 命令列選項時,cut 命令將移除位元組範圍。
咋一看,使用字元範圍和使用位元組沒有什麼明顯的不同:
sh$ diff –s <(cut –b –24,36–59,93– BALANCE.txt)
<(cut –c –24,36–59,93– BALANCE.txt)
Files /dev/fd/63 and /dev/fd/62 are identical
這是因為我們的示例資料檔案使用的是 US-ASCII 編碼(字符集),使用 file -i 便可以正確地猜出來:
sh$ file –i BALANCE.txt
BALANCE.txt: text/plain; charset=us–ascii
在 US-ASCII 編碼中,字元和位元組是一一對應的。理論上,你只需要使用一個位元組就可以表示 256 個不同的字元(數字、字母、標點符號和某些符號等)。實際上,你能表達的字元數比 256 要更少一些,因為字元編碼中為某些特定值做了規定(例如 32 或 65 就是控制字元)。即便我們能夠使用上述所有的位元組範圍,但對於儲存種類繁多的人類手寫符號來說,256 是遠遠不夠的。所以如今字元和位元組間的一一對應更像是某種例外,並且幾乎總是被無處不在的 UTF-8 多位元組編碼所取代。下麵讓我們看看如何來處理多位元組編碼的情形。
作用在多位元組編碼的字元上
正如我前面提到的那樣,示例資料檔案來源於我妻子使用的某款會計軟體。最近好像她升級了那個軟體,然後呢,匯出的文字就完全不同了,你可以試試和上面的資料檔案相比,找找它們之間的區別:

上面的標題欄或許能夠幫助你找到什麼被改變了,但無論你找到與否,現在讓我們看看上面的更改過後的結果:

我毫無刪減地複製了上面命令的輸出。所以可以很明顯地看出列對齊那裡有些問題。
對此我的解釋是原來的資料檔案只包含 US-ASCII 編碼的字元(符號、標點符號、數字和沒有發音符號的拉丁字母)。
但假如你仔細地檢視經軟體升級後產生的檔案,你可以看到新匯出的資料檔案保留了帶發音符號的字母。例如現在合理地記錄了名為 “ALNÉENRE” 的公司,而不是先前的 “ALNEENRE”(沒有發音符號)。
file -i 正確地識別出了改變,因為它報告道現在這個檔案是 UTF-8 編碼 的。
sh$ file –i BALANCE–V2.txt
BALANCE–V2.txt: text/plain; charset=utf–8
如果想看看 UTF-8 檔案中那些帶發音符號的字母是如何編碼的,我們可以使用 [hexdump][12],它可以讓我們直接以位元組形式檢視檔案:
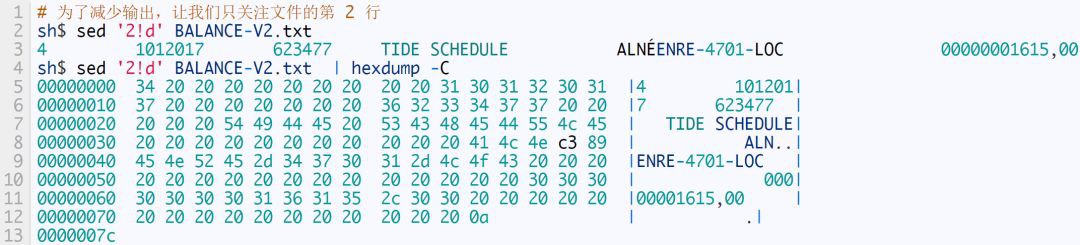
在 hexdump 輸出的 00000030 那行,在一系列的空格(位元組 20)之後,你可以看到:
-
字母 A 被編碼為 41,
-
字母 L 被編碼為 4c,
-
字母 N 被編碼為 4e。
但對於大寫的帶有註音的拉丁大寫字母 E (這是它在 Unicode 標準中字母 É 的官方名稱),則是使用 2 個位元組 c3 89 來編碼的。
這樣便出現問題了:對於使用固定寬度編碼的檔案, 使用位元組位置來表示範圍的 cut 命令工作良好,但這並不適用於使用變長編碼的 UTF-8 或者 Shift JIS 編碼。這種情況在下麵的 POSIX 標準的非規範性摘錄 中被明確地解釋過:
先前版本的 cut 程式將位元組和字元視作等同的環境下運作(正如在某些實現下對退格鍵
和製表鍵 的處理)。在針對多位元組字元的情況下,特別增加了 -b 選項。
嘿,等一下!我並沒有在上面“有錯誤”的例子中使用 ‘-b’ 選項,而是 -c 選項呀!所以,難道不應該能夠成功處理了嗎!?
是的,確實應該:但是很不幸,即便我們現在已身處 2018 年,GNU Coreutils 的版本為 8.30 了,cut 程式的 GNU 版本實現仍然不能很好地處理多位元組字元。取用 GNU 檔案 的話說,-c 選項“現在和 -b 選項是相同的,但對於國際化的情形將有所不同[…]”。需要提及的是,這個問題距今已有 10 年之久了!
另一方面,OpenBSD 的實現版本和 POSIX 相吻合,這將歸功於當前的本地化(locale)設定來合理地處理多位元組字元:

正如期望的那樣,當使用 -b 選項而不是 -c 選項後, OpenBSD 版本的 cut 實現和傳統的 cut 表現是類似的:

3、 作用在域上
從某種意義上說,使用 cut 來處理用特定分隔符隔開的文字檔案要更加容易一些,因為只需要確定好每行中域之間的分隔符,然後複製域的內容到輸出就可以了,而不需要煩惱任何與編碼相關的問題。
下麵是一個用分隔符隔開的示例文字檔案:

你可能知道上面檔案是一個 CSV 格式的檔案(它以逗號來分隔),即便有時候域分隔符不是逗號。例如分號(;)也常被用來作為分隔符,並且對於那些總使用逗號作為 十進位制分隔符的國家(例如法國,所以上面我的示例檔案中選用了他們國家的字元),當匯出資料為 “CSV” 格式時,預設將使用分號來分隔資料。另一種常見的情況是使用 tab 鍵 來作為分隔符,從而生成叫做 tab 分隔的值 的檔案。最後,在 Unix 和 Linux 領域,冒號 (:) 是另一種你能找到的常見分隔符號,例如在標準的 /etc/passwd 和 /etc/group 這兩個檔案裡。
當處理使用分隔符隔開的文字檔案格式時,你可以向帶有 -f 選項的 cut 命令提供需要保留的域的範圍,並且你也可以使用 -d 選項來指定分隔符(當沒有使用 -d 選項時,預設以 tab 字元來作為分隔符):

處理不包含分隔符的行
但要是輸入檔案中的某些行沒有分隔符又該怎麼辦呢?很容易地認為可以將這樣的行視為只包含第一個域。但 cut 程式並 不是 這樣做的。
預設情況下,當使用 -f 選項時,cut 將總是原樣輸出不包含分隔符的那一行(可能假設它是非資料行,就像表頭或註釋等):
sh$ (echo “# 2018-03 BALANCE”; cat BALANCE.csv) > BALANCE–WITH–HEADER.csv
sh$ cut –f 6,7 –d‘;’ BALANCE–WITH–HEADER.csv | head –5
# 2018-03 BALANCE
DEBIT;CREDIT
00000001615,00;
00000000323,00;
;00000001938,00
使用 -s 選項,你可以做出相反的行為,這樣 cut 將總是忽略這些行:
sh$ cut –s –f 6,7 –d‘;’ BALANCE–WITH–HEADER.csv | head –5
DEBIT;CREDIT
00000001615,00;
00000000323,00;
;00000001938,00
00000001333,00;
假如你好奇心強,你還可以探索這種特性,來作為一種相對隱晦的方式去保留那些只包含給定字元的行:
# 保留含有一個 `e` 的行
sh$ printf “%s
“ {mighty,bold,great}–{condor,monkey,bear} | cut –s –f 1– –d‘e’
改變輸出的分隔符
作為一種擴充套件, GNU 版本實現的 cut 允許透過使用 –output-delimiter 選項來為結果指定一個不同的域分隔符:
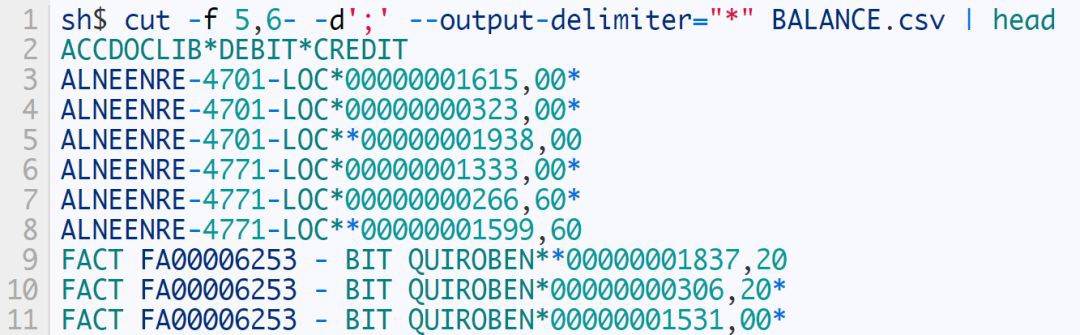
需要註意的是,在上面這個例子中,所有出現域分隔符的地方都被替換掉了,而不僅僅是那些在命令列中指定的作為域範圍邊界的分隔符。
4、 非 POSIX GNU 擴充套件
說到非 POSIX GNU 擴充套件,它們中的某些特別有用。特別需要提及的是下麵的擴充套件也同樣對位元組、字元或者域範圍工作良好(相對於當前的 GNU 實現來說)。
–complement:
想想在 sed 地址中的感嘆符號(!),使用它,cut 將只儲存沒有被匹配到的範圍:

–zero-terminated (-z):
使用 NUL 字元 來作為行終止符,而不是 新行newline字元。當你的資料包含 新行字元時, -z 選項就特別有用了,例如當處理檔案名的時候(因為在檔案名中新行字元是可以使用的,而 NUL 則不可以)。
為了展示 -z 選項,讓我們先做一點實驗。首先,我們將建立一個檔案名中包含換行符的檔案:
bash$ touch $‘EMPTY
FILE
WITH FUNKY
NAME’.txtbash$ ls –1 *.txt
BALANCE.txt
BALANCE–V2.txt
EMPTY?FILE?WITH FUNKY?NAME.txt
現在假設我想展示每個 *.txt 檔案的前 5 個字元。一個想當然的解決方法將會失敗:
sh$ ls –1 *.txt | cut –c 1–5
BALAN
BALAN
EMPTY
FILE
WITH
NAME.
你可能已經知道 ls 是為了方便人類使用而特別設計的,並且在一個命令管道中使用它是一個反樣式(確實是這樣的)。所以讓我們用 find 來替換它:
sh$ find . –name ‘*.txt’ –printf “%f
“ | cut –c 1–5BALAN
EMPTY
FILE
WITH
NAME.
BALAN
上面的命令基本上產生了與先前類似的結果(儘管以不同的次序,因為 ls 會隱式地對檔案名做排序,而 find 則不會)。
在上面的兩個例子中,都有一個相同的問題,cut 命令不能區分 新行 字元是資料域的一部分(即檔案名),還是作為最後標記的 新行 記號。但使用 NUL 位元組()來作為行終止符就將排除掉這種混淆的情況,使得我們最後可以得到期望的結果:
# 我被告知在某些舊版的 `tr` 程式中需要使用 “ 而不是 “ 來代表 NUL 字元(假如你需要這種改變請讓我知曉!)
sh$ find . –name ‘*.txt’ –printf “%f” | cut –z –c 1–5| tr ” ‘
‘BALAN
EMPTY
BALAN
透過上面最後的例子,我們就達到了本文的最後部分了,所以我將讓你自己試試 -printf 後面那個有趣的 “%f” 引數或者理解為什麼我在管道的最後使用了 tr 命令。
使用 cut 命令可以實現更多功能
我只是列舉了 cut 命令的最常見且在我眼中最基礎的使用方式。你甚至可以將它以更加實用的方式加以運用,這取決於你的邏輯和想象。
●編號567,輸入編號直達本文
●輸入m獲取文章目錄

運維
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
