(點選上方公眾號,可快速關註)
編譯: Python開發者 – 李趴趴要化身女超人,英文:Mario Corchero

對一名開發者來說最糟糕的情況,莫過於要弄清楚一個不熟悉的應用為何不工作。有時候,你甚至不知道系統執行,是否跟原始設計一致。
線上執行的應用就是黑盒子,需要被跟蹤監控。最簡單也最重要的方式就是記錄日誌。記錄日誌允許我們在開發軟體的同時,讓程式在系統執行時發出資訊,這些資訊對於我們和系統管理員來說都是有用的。
就像為將來的程式員寫程式碼檔案一樣,我們應該讓新軟體產生足夠的日誌供系統的開發者和管理員使用。日誌是關於應用執行狀態的系統檔案的關鍵部分。給軟體加日誌產生句時,要向給未來維護系統的開發者和管理員寫檔案一樣。
一些純粹主義者認為一個受過訓練的開發者使用日誌和測試的時候幾乎不需要互動除錯器。如果我們不能用詳細的日誌解釋開發過程中的應用,那麼當程式碼線上上執行的時候,解釋它們會變得更困難。
這篇文章介紹了 Python 的 logging 模組,包括它的設計以及針對更多複雜案例的適用方法。這篇文章不是寫給開發者的檔案,它更像是一個指導手冊,來說明 Python 的 logging 模板是如何搭建的,並且激發感興趣的人深入研究。
為什麼使用 logging 模組?
也許會有開發者會問,為什麼不是簡單的 print 陳述句呢? Logging 模組有很多優勢,包括:
-
多執行緒支援
-
透過不同級別的日誌分類
-
靈活性和可配置性
-
將如何記錄日誌與記錄什麼內容分離
最後一點,將我們記錄內容從記錄方式中真正分離,保證了軟體不同部分的合作。舉個例子,它允許一個框架或庫的開發者增加日誌並且讓系統管理員或負責執行配置的人員決定稍後應該記錄什麼。
Logging 模組中有什麼
Logging 模組完美地將它的每個部分的職責分離(遵循 Apache Log4j API 的方法)。讓我們看看一個日誌線是如何透過這個模組的程式碼,並且研究下它的不同部分。
記錄器(Logger)
記錄器是開發者經常互動的物件。那些主要的 API 說明瞭我們想要記錄的內容。
舉個記錄器的例子,我們可以分類請求發出一條資訊,而不用擔心它們是如何從哪裡被髮出的。
比如,當我們寫下 logger.info(“Stock was sold at %s”, price) 我們在頭腦中就有如下模組:
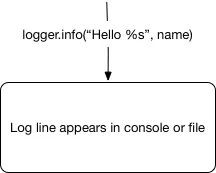
我們需要一條線。假設有些程式碼在記錄器中執行,讓這條線出現在控制檯或檔案中。但是在內部實際發生了什麼呢?
日誌記錄
日誌記錄是 logging 模組用來滿足所有需求資訊的包。它們包含了需要記錄日誌的地方、變化的字串、引數、請求的資訊佇列等資訊。
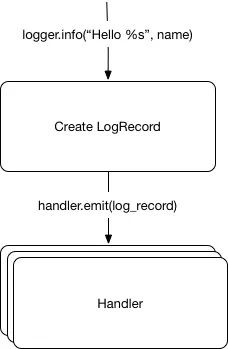
它們都是被記錄的物件。每次我們呼叫記錄器時,都會生成這些物件。但這些物件是如何序列化到流中的呢?透過處理器!
處理器
處理器將日誌記錄傳送給其他輸出終端,他們獲取日誌記錄並用相關函式中處理它們。
比如,一個檔案處理器將會獲取一條日誌記錄,並且把它新增到檔案中。
標準的 logging 模組已經具備了多種內建的處理器,例如:
多種檔案處理器(TimeRotated, SizeRotated, Watched),可以寫入檔案中
-
StreamHandler 輸出標的流比如 stdout 或 stderr
-
SMTPHandler 透過 email 傳送日誌記錄
-
SocketHandler 將日誌檔案傳送到流套接字
-
SyslogHandler、NTEventHandler、HTTPHandler及MemoryHandler等
目前我們有個類似於真實情況的模型:
大部分的處理器都在處理字串(SMTPHandler和FileHandler等)。或許你想知道這些結構化的日誌記錄是如何轉變為易於序列化的位元組的。
格式器
格式器負責將豐富的元資料日誌記錄轉換為字串,如果什麼都沒有提供,將會有個預設的格式器。
一般的格式器類由 logging 庫提供,採用模板和風格作為輸入。然後佔位符可以在一個 LogRecord 物件中宣告所有屬性。
比如:’%(asctime)s %(levelname)s %(name)s: %(message)s’ 將會生成日誌類似於 2017-07-19 15:31:13,942 INFO parent.child: Hello EuroPython.
請註意:屬性資訊是透過提供的引數對日誌的原始模板進行插值的結果。(比如,對於 logger.info(“Hello %s”, “Laszlo”) 這條資訊將會是 “Hello Laszlo”)
所有預設的屬性都可以在日誌檔案中找到。
好了,現在我們瞭解了格式器,我們的模型又發生了變化:

過濾器
我們日誌工具的最後一個物件就是過濾器。
過濾器允許對應該傳送的日誌記錄進行細粒度控制。多種過濾器能同時應用在記錄器和處理器中。對於一條傳送的日誌來說,所有的過濾器都應該透過這條記錄。
使用者可以宣告他們自己的過濾器作為物件,使用 filter 方法獲取日誌記錄作為輸入,反饋 True / False 作為輸出。
出於這種考慮,以下是當前的日誌工作流:

記錄器層級
此時,你可能會對大量複雜的內容和巧妙隱藏的模組配置印象深刻,但是還有更需要考慮的:記錄器分層。
我們可以透過 logging.getLogger() 建立一個記錄器。這條字元向 getLogger 傳遞了一個引數,這個引數可以透過使用圓點分隔元素來定義一個層級。
舉個例子,logging.getLogger(“parent.child”) 將會建立一個 “child” 的記錄器,它的父級記錄器叫做 “parent.” 記錄器是被 logging 模組管理的全域性物件,所以我們可以方便地在專案中的任何地方檢索他們。
記錄器的例子通常也被認為是渠道。層級允許開發者去定義渠道和他們的層級。
在日誌記錄被傳遞到所有記錄器內的處理器時,父級處理器將會進行遞迴處理,直到我們到達頂級的記錄器(被定義為一個空字串),或者有一個記錄器設定了 propagate = False。我們可透過更新的圖中看出:
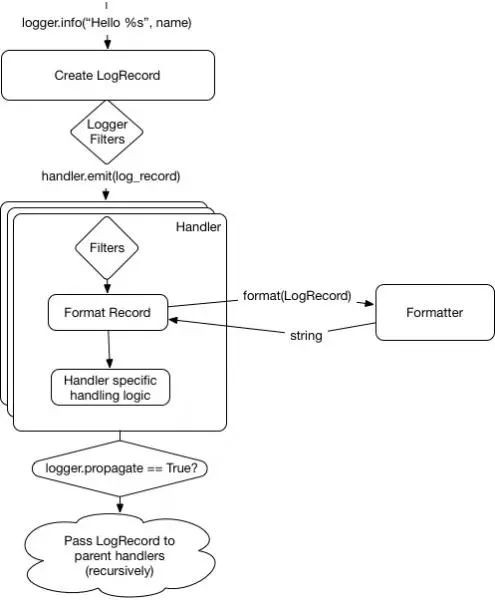
請註意父級記錄器沒有被呼叫,只有它的處理器被呼叫。這意味著過濾器和其他在記錄器類中的程式碼不會在父級中被執行。當我們在記錄器中增加過濾器時,這通常是個陷阱。
工作流小結
我們已經闡明過職責的劃分以及我們是如何微調日誌過濾。然而還是有兩個其他的屬性我們沒有提及:
-
記錄器可以是殘缺的,從而不允許任何記錄從這被髮出。
-
一個有效的層級可以同時在記錄器和處理器中被設定。
舉個例子,當一個記錄器被設定為 INFO 的等級,只有 INFO 等級及以上的才會被傳遞,同樣的規則適用於處理器。
基於以上所有的考慮,最後的日誌記錄的流程圖看起來像這樣:

如何使用日誌記錄模組
現在我們已經瞭解了 logging 模組的部分及設計,是時候去瞭解一個開發者是如何與它互動的了。以下是一個程式碼例子:
import logging
def sample_function(secret_parameter):
logger = logging.getLogger(__name__) # __name__=projectA.moduleB
logger.debug(“Going to perform magic with ‘%s'”, secret_parameter)
…
try:
result = do_magic(secret_parameter)
except IndexError:
logger.exception(“OMG it happened again, someone please tell Laszlo”)
except:
logger.info(“Unexpected exception”, exc_info=True)
raise
else:
logger.info(“Magic with ‘%s’ resulted in ‘%s'”, secret_parameter, result, stack_info=True)
它用模組 __name__ 建立了一個日誌記錄器。它會基於專案結構建立渠道和等級,正如 Pyhon 模組用圓點連線一樣。
記錄器變數取用記錄器的 “module” ,用 “projectA” 作為父級, “root” 作為父級的父級。
在第五行,我們看到如何執行呼叫去傳送日誌。我們可以用 debug 、 info 、error 或 critical 這些方法之一在合適的等級上去記錄日誌。
當記錄一條資訊時,除了模板引數,我們可以透過特殊的含義傳遞密碼引數,最有意思的是 exc_info 和 stack_info。它們將會分別增加關於當前異常和棧幀的資訊。為了方便起見,在記錄器物件中有一個方法異常,正如這個錯誤呼叫 exc_info=True 。
這些是如何使用記錄器模組的基礎,但是有些通常被認為是不良操作的做法同樣值得說明。
過度格式化字串
應該儘量避免使用 loggger.info(“string template {}”.format(argument)) ,可能的話儘量使用 logger.info(“string template %s”, argument)。 這是個更好的實踐,因為只有當日誌被髮送時,字串才會發生真正改變。當我們記錄的層級在 INFO 之上時,不這麼做會導致浪費週期,因為這個改變仍然會發生。
捕捉和格式化異常
通常,我們想記錄在抓取模組異常的日誌資訊,如果這樣寫會很直觀:
try:
…
except Exception as error:
logger.info(“Something bad happened: %s”, error)
但是這樣的程式碼會給我們顯示類似於 Something bad happened: “secret_key.” 的日誌行,這並不是很有用。如果我們使用 exc_info 作為事先說明,那麼它將會如下顯示:
try:
…
except Exception:
logger.info(“Something bad happened”, exc_info=True)
Something bad happened
Traceback (most recent call last):
File “sample_project.py”, line 10, in code
inner_code()
File “sample_project.py”, line 6, in inner_code
x = data[“secret_key”]
KeyError: ‘secret_key’
這不僅僅會包含異常的準確資源,同時也會包含它的型別。
設定記錄器
裝備我們的軟體很簡單,我們需要設定日誌棧,並且制定這些記錄是如何被髮出的。
以下是設定日誌棧的多種方法
基礎設定
這是至今最簡單的設定日誌記錄的方法。使用 logging.basicConfig(level=”INFO”) 搭建一個基礎的 StreamHandler ,這樣就會記錄在 INFO 上的任何東西,並且到控制檯以上的級別。以下是編寫基礎設定的一些引數:
| 引數 | 說明 | 舉例 |
| filename | 指定建立的檔案處理器,使用特定的檔案名,而不是流處理器 | /var/logs/logs.txt |
| format | 為處理器使用特定格式的字串 | “‘%(asctime)s %(message)s’” |
| datefmt | 使用特定的日期/時間格式 | “%H:%M:%S” |
| level | 為根記錄器等級設定特定等級 | “INFO” |
在設定簡單的指令碼上,這是簡單又使用的方法。
請註意, basicConfig 僅僅在執行的一開始可以這麼呼叫。如果你已經設定了你的根記錄器,呼叫 basicConfig 將不會奏效。
字典設定
所有元素的設定以及如何連線它們可以作為字典來說明。這個字典應當由不同的部分組成,包括記錄器、處理器、格式化以及一些基本的通用引數。
例子如下:
config = {
‘disable_existing_loggers’: False,
‘version’: 1,
‘formatters’: {
‘short’: {
‘format’: ‘%(asctime)s %(levelname)s %(name)s: %(message)s’
},
},
‘handlers’: {
‘console’: {
‘level’: ‘INFO’,
‘formatter’: ‘short’,
‘class’: ‘logging.StreamHandler’,
},
},
‘loggers’: {
”: {
‘handlers’: [‘console’],
‘level’: ‘ERROR’,
},
‘plugins’: {
‘handlers’: [‘console’],
‘level’: ‘INFO’,
‘propagate’: False
}
},
}
import logging.config
logging.config.dictConfig(config)
當被取用時, dictConfig 將會禁用所有執行的記錄器,除非 disable_existing_loggers 被設定為 false。這通常是需要的,因為很多模組宣告了一個全球記錄器,它在 dictConfig 被呼叫之前被匯入的時候將會實體化。
你可以檢視 schema that can be used for the dictConfig method(連結)。通常,這些設定將會儲存在一個 YAML 檔案中,並且從那裡設定。很多開發者會傾向於使用這種方式而不是使用 fileConfig(連結),因為它為定製化提供了更好的支援。
拓展 logging
幸虧設計了這種方式,拓展 logging 模組很容易。讓我們來看些例子:
logging JSON | 記錄 JSON
只要我們想要記錄,我們可以透過建立一種自定義格式化來記錄 JSON ,它會將日誌記錄轉化為 JSON 編碼的字串。
import logging
import logging.config
import json
ATTR_TO_JSON = [‘created’, ‘filename’, ‘funcName’, ‘levelname’, ‘lineno’, ‘module’, ‘msecs’, ‘msg’, ‘name’,‘pathname’, ‘process’, ‘processName’, ‘relativeCreated’, ‘thread’, ‘threadName’]
class JsonFormatter:
def format(self, record):
obj = {attr: getattr(record, attr)
for attr in ATTR_TO_JSON}
return json.dumps(obj, indent=4)
handler = logging.StreamHandler()
handler.formatter = JsonFormatter()
logger = logging.getLogger(__name__)
logger.addHandler(handler)
logger.error(“Hello”)
新增更多背景關係
在格式化中,我們可以指定任何日誌記錄的屬性。
我們可以透過多種方式增加屬性,在這個例子中,我們用過濾器來豐富日誌記錄。
import logging
import logging.config
GLOBAL_STUFF = 1
class ContextFilter(logging.Filter):
def filter(self, record):
global GLOBAL_STUFF
GLOBAL_STUFF += 1
record.global_data = GLOBAL_STUFF
return True
handler = logging.StreamHandler()
handler.formatter = logging.Formatter(“%(global_data)s %(message)s”)
handler.addFilter(ContextFilter())
logger = logging.getLogger(__name__)
logger.addHandler(handler)
logger.error(“Hi1”)
logger.error(“Hi2”)
這樣有效地在所有日誌記錄中增加了一個屬性,它可以透過記錄器。格式化會在日誌行中包含這個屬性。
請註意這會在你的應用中影響所有的日誌記錄,包含你可能用到以及你傳送日誌的庫和其他的框架。它可以用來記錄類似於在所有日誌行裡的一個獨立請求 ID ,去追蹤請求或者去新增額外的背景關係資訊。
從 Python 3.2 開始,你可以使用 setLogRecordFactory 去獲得所有日誌的建立記錄和增加額外的資訊。這個 extra attribute 和 LoggerAdapter class 或許同樣是有趣的。
緩衝日誌
有時候當錯誤發生時,我們想要排除日誌故障。建立一個緩衝的處理器,來記錄當錯誤發生時的最新故障資訊是一種可行的辦法。下麵的程式碼是個非人為策劃的例子:
import logging
import logging.handlers
class SmartBufferHandler(logging.handlers.MemoryHandler):
def __init__(self, num_buffered, *args, **kwargs):
kwargs[“capacity”] = num_buffered + 2 # +2 one for current, one for prepop
super().__init__(*args, **kwargs)
def emit(self, record):
if len(self.buffer) == self.capacity – 1:
self.buffer.pop(0)
super().emit(record)
handler = SmartBufferHandler(num_buffered=2, target=logging.StreamHandler(),flushLevel=logging.ERROR)
logger = logging.getLogger(__name__)
logger.setLevel(“DEBUG”)
logger.addHandler(handler)
logger.error(“Hello1”)
logger.debug(“Hello2”) # This line won’t be logged
logger.debug(“Hello3”)
logger.debug(“Hello4”)
logger.error(“Hello5”) # As error will flush the buffered logs, the two last debugs will be logged
更多資訊
這篇關於日誌記錄庫的靈活性和可配置性的介紹,目的在於證明它如何設計了分別的關註點的美學。它同樣為任何對 logging documentation 和 how-to guide 感興趣的人提供了一個堅實的基礎。雖然這篇文章對於 Python 日誌模組並不是一個綜合性的知道,但是這裡有一些針對於常見的問題的回答。
問:我的庫發送了一個“ no logger configured” 的警告
答:從 The Hitchhiker’s Guide to Python 查閱 how to configure logging in a library
問:如果一個記錄器沒有層級設定會怎麼樣?
答:記錄器的有效層級,會由它的父級遞迴定義。
問:我所有的日誌都在本地時間,我如何記錄在 UTC ?
答:格式化就是答案!你需要在你的格式化中設定 converter 屬性為通用的 UTC 時間。使用 converter = time.gmtime 。
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能
