
Python爬蟲為什麼受歡迎
如果你仔細觀察,就不難發現,懂爬蟲、學習爬蟲的人越來越多,一方面,網際網路可以獲取的資料越來越多,另一方面,像 Python這樣的程式語言提供越來越多的優秀工具,讓爬蟲變得簡單、容易上手。
利用爬蟲我們可以獲取大量的價值資料,從而獲得感性認識中不能得到的資訊,比如:
知乎:爬取優質答案,為你篩選出各話題下最優質的內容。
淘寶、京東:抓取商品、評論及銷量資料,對各種商品及使用者的消費場景進行分析。
安居客、鏈家:抓取房產買賣及租售資訊,分析房價變化趨勢、做不同區域的房價分析。
拉勾網、智聯:爬取各類職位資訊,分析各行業人才需求情況及薪資水平。
雪球網:抓取雪球高回報使用者的行為,對股票市場進行分析和預測。
爬蟲是入門Python最好的方式,沒有之一。Python有很多應用的方向,比如後臺開發、web開發、科學計算等等,但爬蟲對於初學者而言更友好,原理簡單,幾行程式碼就能實現基本的爬蟲,學習的過程更加平滑,你能體會更大的成就感。
掌握基本的爬蟲後,你再去學習Python資料分析、web開發甚至機器學習,都會更得心應手。因為這個過程中,Python基本語法、庫的使用,以及如何查詢檔案你都非常熟悉了。
對於小白來說,爬蟲可能是一件非常複雜、技術門檻很高的事情。比如有人認為學爬蟲必須精通 Python,然後哼哧哼哧系統學習 Python 的每個知識點,很久之後發現仍然爬不了資料;有的人則認為先要掌握網頁的知識,遂開始 HTMLCSS,結果入了前端的坑,瘁……
但掌握正確的方法,在短時間內做到能夠爬取主流網站的資料,其實非常容易實現,但建議你從一開始就要有一個具體的標的。
在標的的驅動下,你的學習才會更加精準和高效。那些所有你認為必須的前置知識,都是可以在完成標的的過程中學到的。這裡給你一條平滑的、零基礎快速入門的學習路徑。
1.學習 Python 包並實現基本的爬蟲過程
2.瞭解非結構化資料的儲存
3.學習scrapy,搭建工程化爬蟲
4.學習資料庫知識,應對大規模資料儲存與提取
5.掌握各種技巧,應對特殊網站的反爬措施
6.分散式爬蟲,實現大規模併發採集,提升效率
– ❶ –
學習 Python 包並實現基本的爬蟲過程
大部分爬蟲都是按“傳送請求——獲得頁面——解析頁面——抽取並儲存內容”這樣的流程來進行,這其實也是模擬了我們使用瀏覽器獲取網頁資訊的過程。
Python中爬蟲相關的包很多:urllib、requests、bs4、scrapy、pyspider 等,建議從requests+Xpath 開始,requests 負責連線網站,傳回網頁,Xpath 用於解析網頁,便於抽取資料。
如果你用過 BeautifulSoup,會發現 Xpath 要省事不少,一層一層檢查元素程式碼的工作,全都省略了。這樣下來基本套路都差不多,一般的靜態網站根本不在話下,豆瓣、糗事百科、騰訊新聞等基本上都可以上手了。
當然如果你需要爬取非同步載入的網站,可以學習瀏覽器抓包分析真實請求或者學習Selenium來實現自動化,這樣,知乎、時光網、貓途鷹這些動態的網站也可以迎刃而解。
– ❷ –
瞭解非結構化資料的儲存
爬回來的資料可以直接用檔案形式存在本地,也可以存入資料庫中。
開始資料量不大的時候,你可以直接透過 Python 的語法或 pandas 的方法將資料存為csv這樣的檔案。
當然你可能發現爬回來的資料並不是乾凈的,可能會有缺失、錯誤等等,你還需要對資料進行清洗,可以學習 pandas 包的基本用法來做資料的預處理,得到更乾凈的資料。
– ❸ –
學習 scrapy,搭建工程化的爬蟲
掌握前面的技術一般量級的資料和程式碼基本沒有問題了,但是在遇到非常複雜的情況,可能仍然會力不從心,這個時候,強大的 scrapy 框架就非常有用了。
scrapy 是一個功能非常強大的爬蟲框架,它不僅能便捷地構建request,還有強大的 selector 能夠方便地解析 response,然而它最讓人驚喜的還是它超高的效能,讓你可以將爬蟲工程化、模組化。
學會 scrapy,你可以自己去搭建一些爬蟲框架,你就基本具備爬蟲工程師的思維了。
– ❹ –
學習資料庫基礎,應對大規模資料儲存
爬回來的資料量小的時候,你可以用檔案的形式來儲存,一旦資料量大了,這就有點行不通了。所以掌握一種資料庫是必須的,學習目前比較主流的 MongoDB 就OK。
MongoDB 可以方便你去儲存一些非結構化的資料,比如各種評論的文字,圖片的連結等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。
因為這裡要用到的資料庫知識其實非常簡單,主要是資料如何入庫、如何進行提取,在需要的時候再學習就行。
– ❺ –
掌握各種技巧,應對特殊網站的反爬措施
當然,爬蟲過程中也會經歷一些絕望啊,比如被網站封IP、比如各種奇怪的驗證碼、userAgent訪問限制、各種動態載入等等。
遇到這些反爬蟲的手段,當然還需要一些高階的技巧來應對,常規的比如訪問頻率控制、使用代理IP池、抓包、驗證碼的OCR處理等等。
往往網站在高效開發和反爬蟲之間會偏向前者,這也為爬蟲提供了空間,掌握這些應對反爬蟲的技巧,絕大部分的網站已經難不到你了。
– ❻ –
分散式爬蟲,實現大規模併發採集
爬取基本資料已經不是問題了,你的瓶頸會集中到爬取海量資料的效率。這個時候,相信你會很自然地接觸到一個很厲害的名字:分散式爬蟲。
分散式這個東西,聽起來很恐怖,但其實就是利用多執行緒的原理讓多個爬蟲同時工作,需要你掌握 Scrapy + MongoDB + Redis 這三種工具。
Scrapy 前面我們說過了,用於做基本的頁面爬取,MongoDB 用於儲存爬取的資料,Redis 則用來儲存要爬取的網頁佇列,也就是任務佇列。
所以有些東西看起來很嚇人,但其實分解開來,也不過如此。當你能夠寫分散式的爬蟲的時候,那麼你可以去嘗試打造一些基本的爬蟲架構了,實現一些更加自動化的資料獲取。
你看,這一條學習路徑下來,你已然可以成為老司機了,非常的順暢。所以在一開始的時候,儘量不要系統地去啃一些東西,找一個實際的專案(開始可以從豆瓣、小豬這種簡單的入手),直接開始就好。
因為爬蟲這種技術,既不需要你係統地精通一門語言,也不需要多麼高深的資料庫技術,高效的姿勢就是從實際的專案中去學習這些零散的知識點,你能保證每次學到的都是最需要的那部分。
當然唯一麻煩的是,在具體的問題中,如何找到具體需要的那部分學習資源、如何篩選和甄別,是很多初學者面臨的一個大問題。
不過不用擔心,我們準備了一門非常系統的爬蟲課程,除了為你提供一條清晰的學習路徑,我們甄選了最實用的學習資源以及龐大的主流爬蟲案例庫。短時間的學習,你就能夠很好地掌握爬蟲這個技能,獲取你想得到的資料。

經過短時間的學習,不少同學都取得了從0到1的進步,能夠寫出自己的爬蟲,爬取大規模資料。
如果你希望在短時間內學會爬蟲,少走彎路
掃描下方二維碼加入課程
限時優惠 ¥299(原價399)

– 高效的學習路徑 –
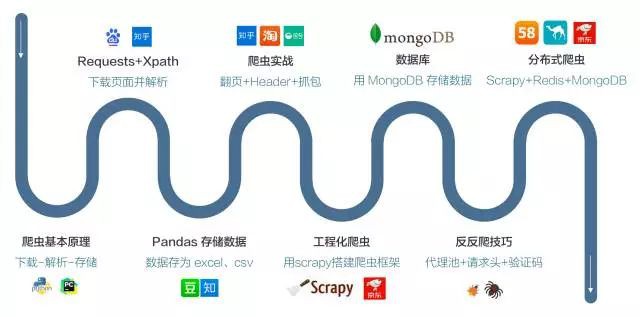
一上來就講理論、語法、程式語言是非常不合理的,我們會直接從具體的案例入手,透過實際的操作,學習具體的知識點。我們為你規劃了一條系統的學習路徑,讓你不再面對零散的知識點。
說點具體的,比如我們會直接用 lxml+Xpath取代 BeautifulSoup 來進行網頁解析,減少你不必要的檢查網頁元素的操作,多種工具都能完成的,我們會給你最簡單的方法,這些看似細節,但可能是很多人都會踩的坑。
《Python爬蟲:入門+進階》大綱
第一章:Python 爬蟲入門
1、什麼是爬蟲
網址構成和翻頁機制
網頁原始碼結構及網頁請求過程
爬蟲的應用及基本原理
2、初識Python爬蟲
Python爬蟲環境搭建
建立第一個爬蟲:爬取百度首頁
爬蟲三步驟:獲取資料、解析資料、儲存資料
3、使用Requests爬取豆瓣短評
Requests的安裝和基本用法
用Requests 爬取豆瓣短評資訊
一定要知道的爬蟲協議
4、使用Xpath解析豆瓣短評
解析神器Xpath的安裝及介紹
Xpath的使用:瀏覽器複製和手寫
實戰:用 Xpath 解析豆瓣短評資訊
5、使用pandas儲存豆瓣短評資料
pandas 的基本用法介紹
pandas檔案儲存、資料處理
實戰:使用pandas儲存豆瓣短評資料
6、瀏覽器抓包及essay-headers設定(案例一:爬取知乎)
爬蟲的一般思路:抓取、解析、儲存
瀏覽器抓包獲取Ajax載入的資料
設定essay-headers 突破反爬蟲限制
實戰:爬取知乎使用者資料
7、資料入庫之MongoDB(案例二:爬取拉勾)
MongoDB及RoboMongo的安裝和使用
設定等待時間和修改資訊頭
實戰:爬取拉勾職位資料
將資料儲存在MongoDB中
補充實戰:爬取微博移動端資料
8、Selenium爬取動態網頁(案例三:爬取淘寶)
動態網頁爬取神器Selenium搭建與使用
分析淘寶商品頁面動態資訊
實戰:用Selenium 爬取淘寶網頁資訊
第二章:Python爬蟲之Scrapy框架
1、爬蟲工程化及Scrapy框架初窺
html、css、js、資料庫、http協議、前後臺聯動
爬蟲進階的工作流程
Scrapy元件:引擎、排程器、下載中介軟體、專案管道等
常用的爬蟲工具:各種資料庫、抓包工具等
2、Scrapy安裝及基本使用
Scrapy安裝
Scrapy的基本方法和屬性
開始第一個Scrapy專案
3、Scrapy選擇器的用法
常用選擇器:css、xpath、re、pyquery
css的使用方法
xpath的使用方法
re的使用方法
pyquery的使用方法
4、Scrapy的專案管道
Item Pipeline的介紹和作用
Item Pipeline的主要函式
實戰舉例:將資料寫入檔案
實戰舉例:在管道里過濾資料
5、Scrapy的中介軟體
下載中介軟體和蜘蛛中介軟體
下載中介軟體的三大函式
系統預設提供的中介軟體
6、Scrapy的Request和Response詳解
Request物件基礎引數和高階引數
Request物件方法
Response物件引數和方法
Response物件方法的綜合利用詳解
第三章:Python爬蟲進階操作
1、網路進階之谷歌瀏覽器抓包分析
http請求詳細分析
網路面板結構
過濾請求的關鍵字方法
複製、儲存和清除網路資訊
檢視資源發起者和依賴關係
2、資料入庫之去重與資料庫
資料去重
資料入庫MongoDB
第四章:分散式爬蟲及實訓專案
1、大規模併發採集——分散式爬蟲的編寫
分散式爬蟲介紹
Scrapy分散式爬取原理
Scrapy-Redis的使用
Scrapy分散式部署詳解
2、實訓專案(一)——58同城二手房監控
3、實訓專案(二)——去哪兒網模擬登陸
4、實訓專案(三)——京東商品資料抓取
– 每課都有學習資料 –
你可能收集了以G計的的學習資源,但儲存後從來沒開啟過?我們已經幫你找到了最有用的那部分,並且用最簡單的形式描述出來,幫助你學習,你可以把更多的時間用於練習和實踐。
考慮到各種各樣的問題,我們在每一節都準備了課後資料,包含四個部分:
1.課程重點筆記,詳細闡述重點知識,幫助你理解和後續快速複習;
2.預設你是小白,補充所有基礎知識,哪怕是軟體的安裝與基本操作;
3.課內外案例提供參考程式碼學習,讓你輕鬆應對主流網站爬蟲;
4.超多延伸知識點和更多問題的解決思路,讓你有能力去解決實際中遇到的一些特殊問題。


某節部分課後資料
– 超多案例,改寫主流網站 –
課程中提供了目前最常見的網站爬蟲案例:豆瓣、百度、知乎、淘寶、京東、微博……每個案例在課程影片中都有詳細分析,老師帶你完成每一步操作。
另外,我們還會補充比如小豬、鏈家、58同城、網易雲音樂、微信好友等案例,提供思路與程式碼。
多次的模仿和練習之後,你可以很輕鬆地寫出自己的爬蟲程式碼,並能夠輕鬆爬取這些主流網站的資料。

– 技能拓展:反爬蟲及資料儲存、處理 –
懂得基本的爬蟲是遠遠不夠的,所以我們會用實際的案例,帶你瞭解一些網站的反爬蟲措施,並且用具體的技術繞過限制。比如非同步載入、IP限制、essay-headers限制、驗證碼等等,這些比較常見的反爬蟲手段,你都可以很好地規避。
工程化的爬蟲、及分散式爬蟲技術,讓你有獲取大規模資料的可能。除了爬蟲的內容,你還將瞭解資料庫(Mongodb)、pandas 的基本知識,幫你儲存爬取的資料,同時可以對資料進行管理和清洗,你可以獲得更乾凈的資料,以便後續的分析和處理。
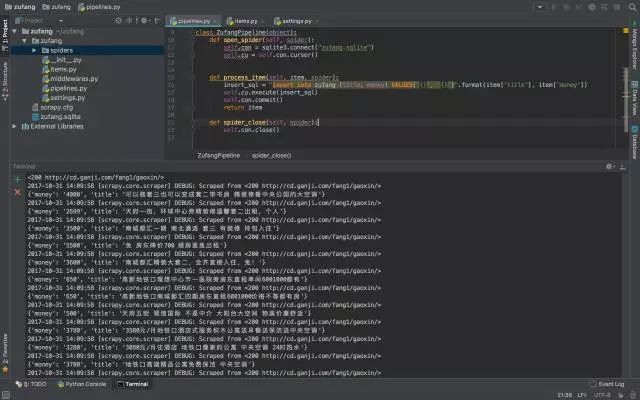
用 Scrapy 爬取租房資訊

爬取拉勾招聘資料並用 MongoDB 儲存
除了經驗豐富、帶你一步步實操的課程老師之外,DC學院還建立了提升效率的學習群,助教老師會在群裡及時解答學員每一個疑問。同時,你還可以跟一群未來優秀的爬蟲工程師,分享經驗、程式碼、資料,探討爬蟲和資料分析技術。
【課程資訊】
「 課程名稱 」
Python 爬蟲:入門+進階
「 學習週期 」
建議每週至少學習8小時,一個月爬取大規模資料
「 上課形式 」
錄播課程,可隨時開始上課,反覆觀看
「 面向人群 」
零基礎的小白,負基礎的小白白
「 答疑形式 」
學習群老師隨時答疑,即便是最初級的問題
「 課程資料 」
重點筆記、操作詳解、參考程式碼、課後拓展
「 課程案例 」
爬取豆瓣短評、圖書、電影資料
爬取知乎使用者、回答資料
爬取淘寶、京東商品資料
爬取拉勾職位資料
爬取去哪兒旅遊景點資料
爬取58同城二手房資料
公眾號專屬優惠,限額底價
¥299(原價¥399),限前100名
長按下方二維碼,立即去搶
課程諮詢、免費試看,請加入下方群聊
若群滿,加Alice微信:datacastle2017

哦,對了,我們給每個按要求完成學習的同學
準備了DC學院的學習證書

每個證書編號對應一個獨立身份資訊
點選閱讀原文立即獲取爬蟲技能
