
導讀:快利用python構建一個屬於你自己的推薦系統吧,手把手教學,夠簡單夠酷炫。在此之前讀者需要對pandas和numpy等資料分析包有所瞭解。
作者:Derrick Mwiti
譯者:Elaine
來源:雲棲社群(ID:yunqiinsight)
01 什麼是推薦系統?
推薦系統的目的是透過發現資料集中的樣式,為使用者提供與之最為相關的資訊。當你訪問Netflix的時候,它也會為你推薦電影。音樂軟體如Spotify及Deezer也使用推薦系統進行音樂推薦。
下圖說明瞭推薦系統是如何在電子商務網站的背景關係中工作的。

兩名使用者都在某電商網站購買了A、B兩種產品。當他們產生購買這個動作的時候,兩名使用者之間的相似度便被計算了出來。其中一名使用者除了購買了產品A和B,還購買了C產品,此時推薦系統會根據兩名使用者之間的相似度會為另一名使用者推薦專案C。
02 推薦系統的主要分類
目前,主流的推薦系統包括基於內容的推薦以及協同過濾推薦。協同過濾簡單來說就是根據使用者對物品或者資訊的偏好,發現物品或者內容本身的相關性,或者是發現使用者的相關性,然後再基於這些關聯性進行推薦。
舉個簡單的例子,如果要向個使用者推薦一部電影,那麼一定是基於他/她的朋友對這部電影的喜愛。基於協同過濾的推薦又可以分為兩類:啟髮式推薦演演算法(Memory-based algorithms)及基於模型的推薦演演算法(Model-based algorithms)。啟髮式推薦演演算法易於實現,並且推薦結果的可解釋性強。啟髮式推薦演演算法又可以分為兩類:
-
基於使用者的協同過濾(User-based collaborative filtering):主要考慮的是使用者和使用者之間的相似度,只要找出相似使用者喜歡的物品,並預測標的使用者對對應物品的評分,就可以找到評分最高的若干個物品推薦給使用者。舉個例子,Derrick和Dennis擁有相似的電影喜好,當新電影上映後,Derick對其表示喜歡,那麼就能將這部電影推薦給Dennis。
-
基於專案的協同過濾(Item-based collaborative filtering):主要考慮的是物品和物品之間的相似度,只有找到了標的使用者對某些物品的評分,那麼就可以對相似度高的類似物品進行預測,將評分最高的若干個相似物品推薦給使用者。舉個例子,如果使用者A、B、C給書籍X,Y的評分都是5分,當使用者D想要買Y書籍的時候,系統會為他推薦X書籍,因為基於使用者A、B、C的評分,系統會認為喜歡Y書籍的人在很大程度上會喜歡X書籍。
基於模型的推薦演演算法利用矩陣分解,有效的緩解了資料稀疏性的問題。矩陣分解是一種降低維度的方法,對特徵進行提取,提高推薦準確度。基於模型的方法包括[決策樹]()、基於規則的模型、貝葉斯方法和潛在因素模型。
基於內容的推薦系統會使用到元資料,例如流派、製作人、演員、音樂家等來推薦電影或音樂。如果有人看過並喜歡範·迪塞爾主演的《速度與激情》,那麼系統很有可能將他主演的另一部電影《無限戰爭》推薦給這些使用者。同樣,你也可以從某些藝術家那裡得到音樂推薦。基於內容的推薦的思想是:如果你喜歡某樣東西,你很可能會喜歡與之相似的東西。
03 資料集
我們將使用到MovieLes資料集,該資料集是關於電影評分的,由明尼蘇達大學的Grouplens研究小組整理,分為1M, 10M, 20M三個規格。Movielens還有一個網站,可以註冊,撰寫評論並獲取電影推薦。若不想用此資料集,你也可以從Dataquest的資料資源中找到更多用於各種資料科學任務的資料集。
推薦系統構建
我們將使用movielens構建一個基於專案相似度的推薦系統,首先匯入pandas和numpy。

接下來利用pandas中的read_csv()對資料進行載入。資料集中的資料以tab進行分隔,我們需要設定sep = t來指定字元的分隔符號,然後透過names引數傳入列名。

接下來,檢查正在處理的資料。

相比只知道電影的ID,能看到它們的標題更為方便。接下來,下載電影的標題並將它們整合到資料集中。

因為item_id列是相同的,我們便可以在此列上對資料進行合併。

每列釋義如下:
-
User_id:使用者ID
-
Item_id:電影ID
-
Rating:使用者給電影的評分,介於1到5分之間
-
Timestamp:對電影進行評分的時間點
-
Title:電影標題
使用description或info命令,可以得到資料集的簡要描述,以幫助我們更好的理解資料集。

透過上一步,可以知道電影的平均分為3.52,最高為5分。
接下來構建一個包含每部電影的平均評分和被評分次數的dataframe,用來計算電影間的相關性。相關性是一種統計度量,用來表示兩個或多個變數在一起波動的程度,電影之間的相關係數越高,越相似。
在本例中,我們將使用皮爾遜相關係數,它的變化範圍為-1到1。當相關係數為1時,為完全正相關;當相關係數為-1時,為完全負相關;相關係數越接近於0,相關度越弱。利用pandas 中的groupby功能建立dataframe,按標題列對資料集進行分組,並計算每部電影的平均分。

接下來計算每部電影被評分的次數,觀察它與電影平均評分之間的關係。一部5分的電影很可能只有一個使用者評分。從統計學上來說,把它視為5分電影是不合理的。
因此,在構建推薦系統時,我們需要為評分次數設定一個閾值。使用pandas中的 groupby功能建立number_of_ratings列,按title列進行分組,然後使用count函式計算每部電影的被評分次數。之後,使用head()函式檢視新的dataframe。

利用pandas中的繪圖功能繪製直方圖,視覺化評分分佈。

從中可以看出,多數電影的分值在2.5到4分之間。接下來將以同樣的方式對number_of_ratings進行視覺化。

從直方圖中可以清楚地看出大多數電影都只有較少的評分,那些評分次數多的電影都擁有較高的知名度。
接下來探索電影評分和被評分次數之間的關係。使用seaborn繪製散點圖,透過jointplot()函式實現。

從圖中可以看出電影的平均評分和被評分次數之間呈正相關關係。圖表顯示,一部電影的評分越高,平均分也就越高。在為每部電影的評分設定閾值時,這一點尤其重要。
接下來構建基於專案的推薦系統。我們需要將資料集轉換為一個矩陣,以電影標題為列,以user_id為索引,以評分為值。之後會得到一個dataframe,其中列是movie標題,行是user_id。每列代表所有使用者對所有電影的評分。若評分為NaN(Not a Number),則表示使用者沒有對某一部電影進行評分。矩陣被用來計算電影之間的相關性。使用pandas中的 pivot_table建立電影矩陣。

接下來,使用pandas中的 sort_values工具,設定升序為false,以便從評分最高的電影中進行選擇,然後使用head()函式檢視分數前10的電影。

假設某使用者看過《空軍一號》和《超時空接觸》,我們想根據觀看歷史向該使用者推薦電影。透過計算這兩個電影和資料集中其他電影的之間的相關性,尋找與之最為相似的電影,為使用者進行推薦。首先,用movie_matrix中的電影評分建立一個dataframe。

Dataframe中包含user_id和對應使用者給這兩個電影的評分。利用如下程式碼進行檢視。

使用pandas中的corwith功能計算兩個dataframe物件的行或列的兩兩相關關係,從而得出每部電影與《空軍一號》電影之間的相關性。

可以看到,《空軍一號》與《直到有你》之間的相關性是0.867,表明這兩部電影有很強的相似性。

接下來,計算《超時空接觸》和其他電影之間的相關性。程式與上面相同。

透過計算,我們發現《超時空接觸》和《直到有你》之間的相關性更強,為0.904。

由於只有部分使用者對部分電影進行了評分,導致矩陣中有許多缺失的值。為了使結果看起來更有吸引力,我們將刪除null值並將correlation results轉化為dataframe。
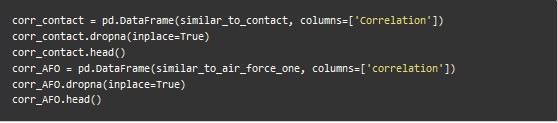
透過上述步驟,計算出了與《超時空接觸》和《空軍一號》最為相似的電影。然而,有些電影被評價的次數很低,最終可能僅僅因為一兩個人給了5分而被推薦。設定閾值可解決這個問題。從之前的直方圖中我們看到評分次數從100急劇下降,於是我們將閾值設為100,不過你可以根據自己的需求進行調整。接下來,利用number_of_ratings列將兩個dataframe連線起來。

獲取並檢視前10部最為相關的電影。

由於閾值不同,結果也會有所不同。在設定閾值後,與《空軍一號》最相似的電影是《獵殺紅色十月》,相關係數為0.554。
接下來獲取並檢視與《超時空接觸》最為相關的前10部電影。

《超時空接觸》最相似的電影是《費城》,相關係數為0.446,被評分次數為137。根據此結果,我們可以向喜歡《超時空接觸》的使用者推薦串列中的電影。
04 改進
本文所構建的推薦系統可以透過基於記憶的協同過濾方法進行改進。我們可以將資料集劃分為訓練集和測試集,使用諸如餘弦相似度之類的方法來計算電影之間的相似度。還可以透過建立基於模型的協同過濾系統,更好地處理可伸縮性和稀疏性問題。同時也可以利用如均方根誤差(RMSE)之類的方法對模型進行評估。
除此之外,當所處理的資料量十分龐大時,還可以結合深度學習構建推薦系統。自動編碼器和受限的Boltzmann機器也常用於構建高階推薦系統。
本文由阿裡云云棲社群組織翻譯,文章原標題:How to build a Simple Recommender System in Python

據統計,99%的大咖都完成了這個神操作
▼
更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 你被別人的推薦系統安利過什麼廣告?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

