

分散式系統,尤其是分散式儲存系統,需要解決的兩個最主要的問題即資料分片和資料冗餘,下圖形象生動地解釋了其概念和區別:

圖片來源於:http://book.mixu.net/distsys/intro.html
其中資料A、B即屬於資料分片,原始資料被拆分成兩個正交子集分佈在兩個節點上。而資料集C屬於資料冗餘,同一份完整的資料在兩個節點都有儲存。當然,在實際的分散式系統中,資料分片和資料冗餘一般都是共存的。
本文主要討論資料分片的三個問題:
-
如何做資料分片,即如何將資料對映到節點上;
-
資料分片的特徵值,即按照資料中的哪一個屬性(欄位)來分片;
-
資料分片的元資料的管理,如何保證元資料伺服器的高效能、高可用,如果是一組伺服器,如何保證強一致性。
所謂分散式系統,就是利用多個獨立的計算機來解決單個節點(計算機)無法處理的儲存、計算問題,這是非常典型的分而治之的思想。每個節點只負責原問題(即整個系統需要完成的任務)的一個子集,可是原問題如何拆分到多個節點?在分散式儲存系統中,任務的拆分即資料分片。
資料分片(segment,fragment,shard,partition),就是按照一定的規則,將資料集劃分成相互獨立、正交的資料子集,然後將資料子集分佈到不同的節點上。
註意,這裡提到,資料分片需要按照一定的規則,不同的分散式應用有不同的規則,但都遵循同樣的原則:按照最主要、最頻繁使用的訪問方式來分片。
一、三種資料分片方式
首先介紹三種分片方式:hash方式、一致性hash(consistent hash)、按照資料範圍(range based)。對於任何方式,都需要思考以下幾個問題:
-
具體如何劃分原始資料集?
-
當原問題的規模變大的時候,能否透過增加節點來動態適應?
-
當某個節點故障的時候,能否將該節點上的任務均衡的分攤到其他節點?
-
對於可修改的資料(比如資料庫資料),如果某節點資料量變大,能否以及如何將部分資料遷移到其他負載較小的節點,達到動態均衡的效果?
-
元資料的管理(即資料與物理節點的對應關係)規模?元資料更新的頻率以及複雜度?
為了後面分析不同的資料分片方式,假設有三個物理節點,編號為N0、N1、N2,有以下幾條記錄:
R0: {id: 95, name: ‘aa’, tag:’older’}
R1: {id: 302, name: ‘bb’,}
R2: {id: 759, name: ‘aa’,}
R3: {id: 607, name: ‘dd’, age: 18}
R4: {id: 904, name: ‘ff’,}
R5: {id: 246, name: ‘gg’,}
R6: {id: 148, name: ‘ff’,}
R7: {id: 533, name: ‘kk’,}
雜湊表(散串列)是最為常見的資料結構,根據記錄(或者物件)的關鍵值將記錄對映到表中的一個槽(slot),便於快速訪問。
絕大多數程式語言都有對hash表的支援,如Python中的dict、C++中的map、Java中的Hashtable,Lua中的table等等。在雜湊表中,最為簡單的雜湊函式是mod N(N為表的大小),即首先將關鍵值計算出hash值(這裡是一個整型),透過對N取餘,餘數即在表中的位置。
資料分片的hash方式也是這個思想,即按照資料的某一特徵(key)來計算雜湊值,並將雜湊值與系統中的節點建立對映關係,從而將雜湊值不同的資料分佈到不同的節點上。
我們選擇id作為資料分片的key,那麼各個節點負責的資料如下:

由此可以看到,按照hash方式做資料分片,優點是對映關係非常簡單,需要管理的元資料也非常之少,只需要記錄節點的數目以及hash方式就行了。
但hash方式的缺點也非常明顯:當加入或者刪除一個節點的時候,大量的資料需要移動。比如在這裡增加一個節點N3,因此hash方式變為了mod4,資料的遷移如下:

這種方式是不滿足單調性(Monotonicity)的:如果已經有一些內容透過雜湊分派到了相應的緩衝中,又有新的緩衝加入到系統中,雜湊的結果應能夠保證原有已分配的內容可以被對映到原有的或者新的緩衝中去,而不會被對映到舊的緩衝集合中的其他緩衝區。
在工程中,為了減少遷移的資料量,節點的數目可以成倍增長,這樣機率上來講至多有50%的資料遷移。
hash方式還有一個缺點,即很難解決資料不均衡的問題。有兩種情況:
-
原始資料的特徵值分佈不均勻,導致大量的資料集中到一個物理節點上;
-
對於可修改的記錄資料,單條記錄的資料變大。
在這兩種情況下,都會導致節點之間的負載不均衡,而且在hash方式下很難解決。
一致性hash是將資料按照特徵值對映到一個首尾相接的hash環上,同時也將節點(按照IP地址或者機器名hash)對映到這個環上。對於資料,從資料在環上的位置開始,順時針找到的第一個節點即為資料的儲存節點。
這裡仍然以上述的資料為例,假設id的範圍為[0,1000],N0、N1、N2在環上的位置分別是100、400、800,那麼hash環示意圖與資料的分佈如下:
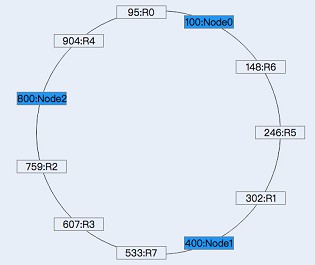

可以看到相比於上述的hash方式,一致性hash方式需要維護的元資料額外包含了節點在環上的位置,但這個資料量也是非常小的。
一致性hash在增加或者刪除節點的時候,受到影響的資料比較有限,比如這裡增加一個節點N3,其在環上的位置為600,因此,原來N2負責的範圍段(400,800]現在由N3(400,600]N2(600,800]負責,因此只需要將記錄R7(id:533)從N2,遷移到N3。
不難發現一致性hash方式在增刪的時候只會影響到hash環上響應的節點,不會發生大規模的資料遷移。
但是,一致性hash方式在增加節點的時候,只能分攤一個已存在節點的壓力;同樣,在其中一個節點掛掉的時候,該節點的壓力也會被全部轉移到下一個節點。我們希望的是“一方有難,八方支援”,因此需要在增刪節點的時候,已存在的所有節點都能參與響應,達到新的均衡狀態。
所以,在實際工程中,一般會引入虛擬節點(virtual node)的概念,即不是將物理節點對映在hash環上,而是將虛擬節點對映到hash環上。虛擬節點的數目遠大於物理節點,因此一個物理節點需要負責多個虛擬節點的真實儲存。運算元據的時候,先透過hash環找到對應的虛擬節點,再透過虛擬節點與物理節點的對映關係找到對應的物理節點。
引入虛擬節點後的一致性hash需要維護的元資料也會增加:第一,虛擬節點在hash環上的問題,且虛擬節點的數目又比較多;第二,虛擬節點與物理節點的對映關係。但帶來的好處是明顯的,當一個物理節點失效時,hash環上多個虛擬節點失效,對應的壓力也就會發散到多個其餘的虛擬節點,事實上也就是多個其餘的物理節點。在增加物理節點的時候同樣如此。
工程中,Dynamo、Cassandra都使用了一致性hash演演算法,且在比較高的版本中都使用了虛擬節點的概念。在這些系統中,需要考慮綜合考慮資料分佈方式和資料副本,當引入資料副本之後,一致性hash方式也需要做相應的調整,可以參加cassandra的相關檔案。
簡單來說,就是按照關鍵值劃分成不同的區間,每個物理節點負責一個或者多個區間。其實這種方式跟一致性hash有點像,可以理解為物理節點在hash環上的位置是動態變化的。
還是以上面的資料舉例,三個節點的資料區間分別是N0(0,200],N1(200,500],N2(500,1000]。那麼資料分佈如下:

註意,區間的大小不是固定的,每個資料區間的資料量與區間的大小也是沒有關係的。比如說,一部分資料非常集中,那麼區間大小應該是比較小的,即以資料量的大小為片段標準。
在實際工程中,一個節點往往負責多個區間,每個區間成為一個塊(chunk、block),每個塊有一個閾值,當達到這個閾值之後就會分裂成兩個塊。這樣做的目的在於當有節點加入的時候,可以快速達到均衡的目的。
不知道大家有沒有發現,如果一個節點負責的資料只有一個區間,range based與沒有虛擬節點概念的一致性hash很類似;如果一個節點負責多個區間,range based與有虛擬節點概念的一致性hash很類似。
range based的元資料管理相對複雜一些,需要記錄每個節點的資料區間範圍,特別單個節點對於多個區間的情況。而且,在資料可修改的情況下,如果塊進行分裂,那麼元資料中的區間資訊也需要同步修改。
range based這種資料分片方式應用得非常廣泛,比如MongoDB、PostgreSQL、 HDFS。
在這裡對三種分片方式(應該是四種,有沒有virtual node的一致性hash算兩種)進行簡單總結,主要是針對提出的幾個問題:

上面的資料動態均衡,指的是本章內容開頭提出的第四個問題,即如果某節點資料量變大,能否以及如何將部分資料遷移到其他負載較小的節點。
二、分片特徵值的選擇
上面的三種方式都提到了對資料的分片是基於關鍵值、特徵值的。這個特徵值在不同的系統中有不同的叫法。
比如:
-
MongoDB中的sharding key:
https://docs.mongodb.com/manual/core/sharding-shard-key/
-
Oracle中的Partition Key:
https://docs.oracle.com/cd/B28359_01/server.111/b32024/partition.htm
不管怎麼樣,這個特徵值的選擇都是非常非常重要的。
那麼怎麼選擇這個特徵值,《Distributed systems for fun and profit》給出了言簡意賅的標準:
參考連結:http://book.mixu.net/distsys/intro.html
based on what you think the primary access pattern will be
大概翻譯為:基於最常用的訪問樣式。
訪問時包括對資料的增刪改查的。比如上面的列子,我們選擇“id”作為分片的依據,那麼就是預設對的資料增刪改查都是透過“id”欄位來進行的。
如果在應用中,大量的資料操作都是透過這個特徵值進行,那麼資料分片就能提供兩個額外的好處:
-
提升效能和併發,操作被分發到不同的分片,相互獨立;
-
提升系統的可用性,即使部分分片不能用,其他分片不會受到影響。
如果大量操作並沒有使用到特徵值,那麼就很麻煩了。比如在本文的例子中,如果用name去查詢,而元資料記錄的是如何根據按照id對映資料位置,那就尷尬了,需要到多有分片都去查一下,然後再做一個聚合。
另外一個問題,如果以單個欄位為特徵值(如id),那麼不管按照什麼分佈方式,在多條資料擁有相同的特徵值(如id)的情況下,這些資料一定都會分佈到同一個節點上。
在這種情況下有兩個問題,一是不能達到節點間資料的均衡,二是如果資料超過了單個節點的儲存能力怎麼辦?關鍵在於,即使按照分散式系統解決問題的常規辦法——增加節點——也是於事無補的。
在這個時候,單個欄位做特徵值就不行了,可能得再增加一個欄位作為“聯合特徵值”,類似資料庫中的聯合索引。
比如,資料是使用者的操作日誌,可以使用id和時間戳一起作為hash函式的輸入,然後算出特徵值;但在這種情況下,如果還想以id為查詢關鍵字來查詢,那就得遍歷所有節點了。
所以說沒有最優的設計,只有最符合應用需求的設計。
下麵以MongoDB中的sharding key為例,解釋特徵值選擇的重要性以及對資料操作的影響。如果有資料庫操作基礎,即使沒有使用過MongoDB,閱讀下麵的內容應該也沒有問題。
以MongoDB sharding key為例:
在我的工作場景中,除了聯合查詢(join)和事務,MongoDB的使用和MySQL還是比較相似的,特別是基本的CRUD操作、資料庫索引。MongoDB中,每一個分片成為一個shard,分片的特徵值成為sharding key,每個資料稱之為一個document。
選擇適合的欄位作為shardingkey很重要,為什麼:
前面也提到,如果使用非sharding key去訪問資料,那麼元資料伺服器,或者元資料快取伺服器,是沒法知道對應的資料在哪一個shard上的,那麼該訪問就得傳送到所有的shard,得到所有shard的結果之後再做聚合。
在MongoDB中,由mongos(快取有元資料資訊)做資料聚合。
對於資料讀取(R:read or retrieve),透過同一個欄位獲取到多個資料,是沒有問題的,只是效率比較低而已;對於資料更新,如果只能更新一個資料,那麼在哪一個shard上更新似乎都不對,這個時候,MongoDB是拒絕的。對應到MongoDB(MongoDD3.0)的命令包括但不限於:
-
findandmodify:這個命令只能更新一個document,因此查詢部分必須包含sharding key。
When using findAndModify in a sharded environment, the query must contain the shard key for all operations against the shard cluster for the sharded collections.
-
update:這個命令有一個引數multi,預設是false,即只能更新一個document,此時查詢部分必須包含sharding key。
All update() operations for a sharded collection that specify the multi: false option must include theshard key or the _id field in the query specification.
-
remove:有一個引數JustOne,如果為True,只能刪除一個document,也必須使用sharidng key。
另外,熟悉SQL的同學都知道,在資料中索引中有unique index(唯一索引),即保證這個欄位的值在table中是唯一的。MongoDB中,也可以建立unique index,但是在sharded cluster環境下,只能對sharding key建立unique index。道理也很簡單,如果unique index不是sharidng key,那麼插入的時候就得去所有shard上檢視,而且還得加鎖。
分片到shard上的資料不均:
接下來,討論分片到shard上的資料不均的問題。如果一段時間內shardkey過於集中(比如按時間增長),那麼資料只往一個shard寫入,導致無法平衡叢集壓力。
MongoDB為我們提供了:
-
range partition:
https://docs.mongodb.com/manual/core/ranged-sharding/
-
hash partition:
https://docs.mongodb.com/manual/core/hashed-sharding/
它們跟上面提到的分片方式hash方式、ranged based不是一回事兒,而是指對sharding key處理。MongoDB一定是ranged base分片方式,docuemnt中如是說:
MongoDB partitions data in the collection using ranges of shard key values. Each range defines a non-overlapping range of shard key values and is associated with a chunk.
參考連結:
https://docs.mongodb.com/manual/core/sharding-shard-key/
那麼什麼是“range partition”和“hash partition”?官網的一張圖很好說明瞭二者的區別:


上圖左是range partition,右是hash partition。range partition就是使用欄位本身作為分片的邊界,比如上圖的x;而hash partition會將欄位重新hash到一個更大、更離散的值域區間。
hash partition的最大好處在於保證資料在各個節點上均勻分佈(這裡的均勻指的是在寫入的時候就均勻,而不是透過MongoDB的balancing功能)。比如MongoDB中預設的_id是objectid,objectid是一個12個位元組的BSON型別,前4個位元組是機器的時間戳,那麼如果在同一時間大量建立以ObjectId為_id的資料會分配到同一個shard上,此時若將_id設定為hash index和hash sharding key,就不會有這個問題。
當然,hash partition相比range partition也有一個很大的缺點,就是範圍查詢的時候效率低,因此到底選用hash partition還是range partition還得根據應用場景來具體討論。
最後得知道,sharding key一但選定,就無法修改。如果應用必須要修改sharidng key,那麼只能將資料匯出,新建資料庫並建立新的sharding key,最後匯入資料。
三、元資料伺服器
在上面討論的三種資料分片分式中,或多或少都會記錄一些元資料:資料與節點的對映關係、節點狀態等等。我們稱記錄元資料的伺服器為元資料伺服器(metaserver),不同的系統叫法不一樣,比如master、configserver、namenode等。
元資料伺服器就像人類的大腦,一隻手不能用了還沒忍受,大腦不工作整個人就癱瘓了。因此,元資料伺服器的高效能、高可用,要達到這兩個標的,元資料伺服器就得高可擴充套件——以此應對元資料的增長。
元資料的高可用要求元資料伺服器不能成為故障單點(single point of failure),因此需要元資料伺服器有多個備份,並且能夠在故障的時候迅速切換。
有多個備份,那麼問題就來了,怎麼保證多個備份的資料一致性?
多個副本的一致性、可用性是CAP理論討論的範疇,這裡簡單介紹兩種方案:
-
方案一:主從同步,首先選出主伺服器,只有主伺服器提供對外服務,主伺服器將元資料的變革資訊以日誌的方式持久化到共享儲存(例如nfs),然後從伺服器從共享儲存讀取日誌並應用,達到與主伺服器一致的狀態,如果主伺服器被檢測到故障(比如透過心跳),那麼會重新選出新的主伺服器。
-
方案二:透過分散式一致性協議來達到多個副本件的一致,比如大名鼎鼎的Paxos協議以及工程中使用較多的Paxos的特化版本——Raft協議,協議可以實現所有備份均可以提供對外服務,並且保證強一致性。
HDFS中,元資料伺服器被稱之為namenode。在hdfs1.0之前,namenode還是單點,一旦namenode掛掉,整個系統就無法工作。在hdfs2.0,解決了namenode的單點問題。
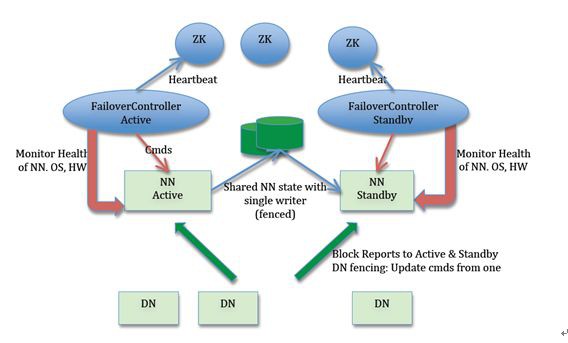
上圖中NN即NameNode,DN即DataNode(即實際儲存資料的節點)。從圖中可以看到,兩臺NameNode形成互備,一臺處於Active狀態,為主NameNode;另外一臺處於Standby狀態,為備NameNode,只有主NameNode才能對外提供讀寫服務。
Active NN與standby NN之間的資料同步透過共享儲存實現,共享儲存系統保證了Namenode的高可用。為了保證元資料的強一致性,在進行準備切換的時候,新的Active NN必須要在確認元資料完全同步之後才能繼續對外提供服務。
另外,Namenode的狀態監控以及準備切換都是Zookeeper叢集負責,在網路分割(network partition)的情況下,有可能Zookeeper認為原來的Active NN掛掉了,選舉出新的ActiveNN,但實際上原來的Active NN還在繼續提供服務。這就導致了“雙主”或者腦裂(brain-split)現象。為瞭解決這個問題,提出了fencing機制,也就是想辦法把舊的Active NameNode隔離起來,使它不能正常對外提供服務。
MongoDB中,元資料伺服器被稱為config server。在MongoDB3.2中,已經不再建議使用三個映象(Mirrored)MongoDB實體作為config server,而是推薦使用複製集(replica set)作為config server,此舉的目的是增強config server的一致性,而且config sever中mongod的數目也能從3個達到replica set的上線(50個節點),從而提高了可靠性。
-
在MongoDB3.0及之前的版本中,元資料的讀寫按照下麵的方式進行:
When writing to the three config servers, a coordinator dispatches the same write commands to the three config servers and collects the results. Differing results indicate an inconsistent writes to the config servers and may require manual intervention.
MongoDB的官方檔案並沒有詳細解釋這一過程,不過在stackexchange上,有人指出這個過程是兩階段提交。
-
MongoDB3.2及之後的版本,使用了replica set config server,在config server中,使用了WriteConcern:Majority;ReadConcern:Majority;Read References:nearest。
即使元資料伺服器可以由一組物理機器組成,也保證了副本集之間的一致性問題。但是如果每次對資料的請求都經過元資料伺服器的話,元資料伺服器的壓力也是非常大的。很多應用場景,元資料的變化並不是很頻繁,因此可以在訪問節點上做快取,這樣應用可以直接利用快取資料進行資料讀寫,減輕元資料伺服器壓力。
在這個環境下,快取的元資料必須與元資料伺服器上的元資料一致,快取的元資料必須是準確的、未過時的。相反的例子是DNS之類的快取,即使使用了過期的DNS快取也不會有太大的問題。
怎麼達到快取的強一致性呢?比較容易想到的辦法是當metadata變化的時候立即通知所有的快取伺服器(mongos),但問題是通訊有延時,不可靠。
解決不一致的問題:
一個比較常見的思路是版本號:比如網路通訊,通訊協議可能會發生變化,通訊雙方為了達成一致,那麼可以使用版本號。在快取一致性的問題上,也可以使用版本號,基本思路是請求的時候帶上快取的版本號,路由到具體節點之後比較實際資料的版本號,如果版本號不一致,那麼表示快取資訊過舊,此時需要從元資料伺服器重新拉取元資料並快取。在MongoDB中,mongos快取上就是使用的這種辦法。
另外一種解決辦法,就是Lease機制 :“An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency”,Lease機制在分散式系統中使用非常廣泛,不僅僅用於分散式快取,在很多需要達成某種約定的地方都大顯身手,下麵會對lease機制進行簡單介紹。
lease機制:
既然lease機制提出的時候是為瞭解決分散式儲存系統中快取一致性的問題,那麼首先來看看lease機制是怎麼保證快取的強一致性的。註意,為了方便後文描述,在本小節中,我們稱元資料伺服器為伺服器,快取伺服器為客戶端。
要點:
-
伺服器向所有客戶端傳送快取資料的同時,頒發一個lease,lease包含一個有限期(即過期時間);
-
lease的含義是:在這個有效期內,伺服器保證元資料不會發生變化;
-
客戶端在這個有效期內可以放心大膽的使用快取的元資料,如果超過了有效期,就不能使用資料了,就得去伺服器請求;
-
如果外部請求修改伺服器上的元資料(元資料的修改一定在伺服器上進行),那麼伺服器會阻塞修改請求,直到所有已頒發的lease過期,然後修改元資料,並將新的元資料和新的lease傳送到客戶端;
-
如果元資料沒有發生變化,那麼伺服器也需要在之前已頒發的lease到期之間,重新給客戶端頒發新的lease(只有lease,沒有資料)。
在lease論文的標題中,提到了“Fault-Tolerant”,那麼lease是怎麼做到容錯的呢。關鍵在於,只要伺服器一旦發出資料和lease,不關心客戶端是否收到資料,只要等待lease過期,就可以修改元資料;另外,lease的有效期透過過期時間(一個時間戳)來標識,因此即使從伺服器到客戶端的訊息延時到達、或者重覆傳送都是沒有關係的。
不難發現,容錯的前提是伺服器與客戶端的時間要一致。
-
如果伺服器的時間比客戶端的時間慢,那麼客戶端收到lease之後很快就過期了,lease機制就發揮不了作用;
-
如果伺服器的時間比客戶端的時間快,那麼就比較危險,因為客戶端會在伺服器已經開始更新元資料的時候繼續使用快取,工程中,通常將伺服器的過期時間設定得比客戶端的略大,來解決這個問題;
-
為了保持時間的一致,最好的辦法是使用NTP(Network Time Protocol)來保證時鐘同步。
lease機制的本質是頒發者授予的在某一有效期內的承諾,承諾的範圍是非常廣泛的:
-
比如上面提到的cache;
-
比如做許可權控制,例如當需要做併發控制時,同一時刻只給某一個節點頒發lease,只有持有lease的節點才可以修改資料;
-
比如身份驗證,例如在primary-secondary架構中,給節點頒發lease,只有持有lease的節點才具有primary身份;
-
比如節點的狀態監測,例如在primary-secondary架構中監測primary是否正常,這個後文再詳細介紹。
工程中,lease機制也有大量的應用:
-
GFS中使用lease確定Chuck的Primary副本,lease由Master節點頒發給primary副本,持有lease的副本成為primary副本。
-
chubby透過paxos協議實現去中心化的選擇primary節點,然後Secondary節點向primary節點傳送lease,該lease的含義是:“承諾在lease時間內,不選舉其他節點成為primary節點”。
-
chubby中,primary節點也會向每個client節點頒發lease。該lease的含義是用來判斷client的死活狀態,一個client節點只有有了合法的lease,才能與chubby中的primary進行讀寫操作。
四、總結
文末我們來劃一下本文的重點。
本文主要介紹了分散式系統中的分片相關問題,包括三種分佈方式:hash、一致性hash、range based,以及各自的優缺點。
分片都是按照一定的特徵值來進行,特徵值應該從應用的使用場景來選取,並結合MongoDB展示了特徵值(mongodb中的sharding key)對資料操作的影響。
分片資訊(即元資料)需要專門的伺服器儲存,元資料伺服器是分散式儲存系統的核心,因此需要提到其可用性和可靠性,為了減輕元資料伺服器的壓力,分散式系統中,會在其他節點快取元資料,快取的元資料又帶來了一致性的挑戰,由此引入了lease機制。
參考文獻:
1、劉傑:《分散式系統原理介紹》:
http://blog.sciencenet.cn/home.php?mod=attachment&id;=31413
2、《Distributed systems for fun and profit》 :
http://book.mixu.net/distsys/
3、《Wiki:Consistent_hashing》:
https://en.wikipedia.org/wiki/Consistent_hashing
4、《Hadoop NameNode 高可用 (High Availability) 實現解析》:
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/
5、《CAP理論與MongoDB一致性、可用性的一些思考》:
http://www.cnblogs.com/xybaby/p/6871764.html
6、《Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency》:
http://web.eecs.umich.edu/~mosharaf/Readings/Leases.pdf
作者:xybaby
來源:www.cnblogs.com/xybaby/p/7076731.html
轉自:dbaplus社群
推薦閱讀:
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳情。

求知若渴, 虛心若愚

