
〇. python 基礎
先放上python 3 的官方檔案:https://docs.python.org/3/ (看檔案是個好習慣)
關於python 3 基礎語法方面的東西,網上有很多,大家可以自行查詢.
一. 最簡單的爬取程式
爬取百度首頁原始碼:

來看上面的程式碼:
-
對於python 3來說,urllib是一個非常重要的一個模組 ,可以非常方便的模擬瀏覽器訪問網際網路,對於python 3 爬蟲來說, urllib更是一個必不可少的模組,它可以幫助我們方便地處理URL.
-
urllib.request是urllib的一個子模組,可以開啟和處理一些複雜的網址
The urllib.request
module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more.
-
urllib.request.urlopen()方法實現了開啟url,並傳回一個 http.client.HTTPResponse物件,透過http.client.HTTPResponse的read()方法,獲得response body,轉碼最後透過print()打印出來.
urllib.request.urlopen(url, data=None, [timeout, ]***, cafile=None, capath=None, cadefault=False, context=None)
For HTTP and HTTPS URLs, this function returns a http.client.HTTPResponse
object slightly modified.
< 出自: https://docs.python.org/3/library/urllib.request.html >
-
decode(‘utf-8’)用來將頁面轉換成utf-8的編碼格式,否則會出現亂碼
二 模擬瀏覽器爬取資訊
在訪問某些網站的時候,網站通常會用判斷訪問是否帶有頭檔案來鑒別該訪問是否為爬蟲,用來作為反爬取的一種策略。
先來看一下Chrome的頭資訊(F12開啟開發者樣式)如下:

如圖,訪問頭資訊中顯示了瀏覽器以及系統的資訊(essay-headers所含資訊眾多,具體可自行查詢)
Python中urllib中的request模組提供了模擬瀏覽器訪問的功能,程式碼如下:
from urllib import request
url = 'http://www.baidu.com'
# page = request.Request(url)
# page.add_essay-header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')
essay-headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url, essay-headers=essay-headers)
page_info = request.urlopen(page).read().decode('utf-8')
print(page_info)
可以透過add_essay-header(key, value) 或者直接以引數的形式和URL一起請求訪問,urllib.request.Request()
urllib.request.Request(url, data=None, essay-headers={}, origin_req_host=None, unverifiable=False, method=None)
三 爬蟲利器Beautiful Soup
Beautiful Soup是一個可以從HTML或XML檔案中提取資料的Python庫.它能夠透過你喜歡的轉換器實現慣用的檔案導航,查詢,修改檔案的方式.
檔案中的例子其實說的已經比較清楚了,那下麵就以爬取簡書首頁文章的標題一段程式碼來演示一下:
先來看簡書首頁的原始碼:
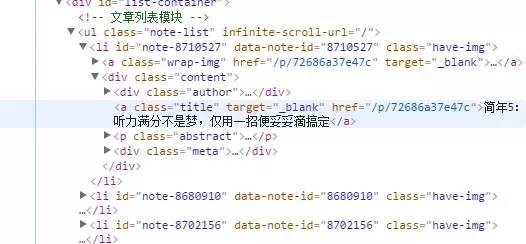
可以發現簡書首頁文章的標題都是在標簽中,並且class=’title’,所以,透過
find_all('a', 'title')
便可獲得所有的文章標題,具體實現程式碼及結果如下:
# -*- coding:utf-8 -*-
from urllib import request
from bs4 import BeautifulSoup
url = r'http://www.jianshu.com'
# 模擬真實瀏覽器進行訪問
essay-headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url, essay-headers=essay-headers)
page_info = request.urlopen(page).read()
page_info = page_info.decode('utf-8')
# 將獲取到的內容轉換成BeautifulSoup格式,並將html.parser作為解析器
soup = BeautifulSoup(page_info, 'html.parser')
# 以格式化的形式列印html
# print(soup.prettify())
titles = soup.find_all('a', 'title') # 查詢所有a標簽中class='title'的陳述句
# 列印查詢到的每一個a標簽的string
for title in titles:
print(title.string)
Beautiful Soup支援Python標準庫中的HTML解析器,還支援一些第三方的解析器,下表列出了主要的解析器,以及它們的優缺點:

四 將爬取的資訊儲存到本地
之前我們都是將爬取的資料直接列印到了控制臺上,這樣顯然不利於我們對資料的分析利用,也不利於儲存,所以現在就來看一下如何將爬取的資料儲存到本地硬碟。
1 對.txt檔案的操作
讀寫檔案是最常見的操作之一,python3 內建了讀寫檔案的函式:open
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None))
Open file and return a corresponding file object. If the file cannot be opened, an OSError
is raised.
其中比較常用的引數為file和mode,引數file為檔案的路徑,引數mode為操作檔案的方式(讀/寫),函式的傳回值為一個file物件,如果檔案操作出現異常的話,則會丟擲 一個OSError
還以簡書首頁文章題目為例,將爬取到的文章標題存放到一個.txt檔案中,具體程式碼如下:
# -*- coding:utf-8 -*-
from urllib import request
from bs4 import BeautifulSoup
url = r'http://www.jianshu.com'
essay-headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url, essay-headers=essay-headers)
page_info = request.urlopen(page).read().decode('utf-8')
soup = BeautifulSoup(page_info, 'html.parser')
titles = soup.find_all('a', 'title')
try:
# 在E盤以只寫的方式開啟/建立一個名為 titles 的txt檔案
file = open(r'E:\titles.txt', 'w')
for title in titles:
# 將爬去到的文章題目寫入txt中
file.write(title.string + '\n')
finally:
if file:
# 關閉檔案(很重要)
file.close()
open中mode引數的含義見下表:

其中’t’為預設樣式,’r’相當於’rt’,符號可以疊加使用,像’r+b’
另外,對檔案操作一定要註意的一點是:開啟的檔案一定要關閉,否則會佔用相當大的系統資源,所以對檔案的操作最好使用try:…finally:…的形式。但是try:…finally:…的形式會使程式碼顯得比較雜亂,所幸python中的with陳述句可以幫我們自動呼叫close()而不需要我們寫出來,所以,上面程式碼中的try:…finally:…可使用下麵的with陳述句來代替:
with open(r'E:\title.txt', 'w') as file:
for title in titles:
file.write(title.string + '\n')
效果是一樣的,建議使用with陳述句

2 圖片的儲存
有時候我們的爬蟲不一定只是爬取文字資料,也會爬取一些圖片,下麵就來看怎麼將爬取的圖片存到本地磁碟。
我們先來選好標的,知乎話題:女生怎麼健身鍛造好身材? (單純因為圖多,不要多想哦 (# _ # ) )
看下頁面的原始碼,找到話題下圖片連結的格式,如圖:

可以看到,圖片在img標簽中,且class=origin_image zh-lightbox-thumb,而且連結是由.jpg結尾,我們便可以用Beautiful Soup結合正則運算式的方式來提取所有連結,如下:
links = soup.find_all('img', "origin_image zh-lightbox-thumb",src=re.compile(r'.jpg$'))
提取出所有連結後,使用request.urlretrieve來將所有連結儲存到本地
Copy a network object denoted by a URL to a local file. If the URL points to a local file, the object will not be copied unless filename is supplied. Return a tuple (filename, essay-headers)
where filename is the local file name under which the object can be found, and essay-headers is whatever the info()
method of the object returned by urlopen()
returned (for a remote object). Exceptions are the same as for urlopen()
.
具體實現程式碼如下:
# -*- coding:utf-8 -*-
import time
from urllib import request
from bs4 import BeautifulSoup
import re
url = r'https://www.zhihu.com/question/22918070'
essay-headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url, essay-headers=essay-headers)
page_info = request.urlopen(page).read().decode('utf-8')
soup = BeautifulSoup(page_info, 'html.parser')
# Beautiful Soup和正則運算式結合,提取出所有圖片的連結(img標簽中,class=**,以.jpg結尾的連結)
links = soup.find_all('img', "origin_image zh-lightbox-thumb",src=re.compile(r'.jpg$'))
# 設定儲存的路徑,否則會儲存到程式當前路徑
local_path = r'E:\Pic'
for link in links:
print(link.attrs['src'])
# 儲存連結並命名,time防止命名衝突
request.urlretrieve(link.attrs['src'], local_path+r'\%s.jpg' % time.time())
執行結果

註意營養哦~~~
'''
作者:Veniendeavor
連結:https://www.jianshu.com/p/2cc8310a51c4
'''
