
前言:
這個沒什麼技術難度,懂爬蟲的人和程式員都可以用學的語言寫出來
只是很多安全問題的存在,的確影響著我們的生活,
希望大家可以認識到一些網站的後臺密碼的規則與自己的安全性
簡單的說,就是是程式員的懶,讓使用者的資訊暴露在網際網路上
還有一點:
就是希望正在接觸python,和快要放棄學習的同學,可以試試換種思路,
來試試爬蟲,這樣有成就感的累積,可以慢慢提升你的自信
爬蟲開始前的準備:
-
python2.7
-
庫檔案(xlwt,urllib2,BeautifulSoup4,xlrd)
安裝庫檔案的方法:
最好在你的python2.7/script/下麵開啟power shell(可以shift+右擊) 執行下麵的:
安裝庫檔案:
pip install *** ***是指上面的庫檔案,下麵不一定都用,只要上面的,以後出什麼錯,你就繼續pip install
觀察網站結構(密碼規則):

-
首先這個規則是針對大二和已經畢業了的
-
密碼規則沒有新增驗證碼(其實新增驗證碼也沒什麼用,只是添加了爬取門檻)
-
規則是 使用者名稱==密碼
符合條件

-
這裡的使用者資訊
-
不要在意這些細節(馬賽克) 朦朧美一直是我的追求
具體思路:模擬登陸 ==》製作學號規則==》資訊查詢(爬取)==》存入xls模擬登陸:因為我們是用爬蟲取資訊,每次訪問,
-
肯定是登陸了以後才可以訪問我們的資訊 ==》模擬登陸
-
當我們用指令碼訪問下一個頁面,需要一個cookie資訊,就好比,當你開啟
qq空間,其實是想騰訊那裡提交了自己的資訊,而我們的資訊就存在cookie中
-
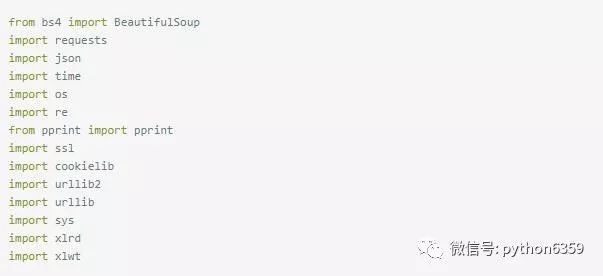
python 中cookie維持會話訪問:
-
模擬登陸
具體網址不分享,避免帶來不必要的麻煩

-
學號的串列

-
使用者資訊的獲取
這裡用的的是beautifulsoup庫

-
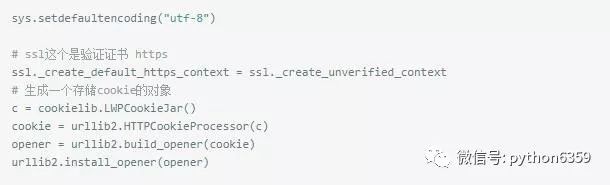
寫入xls(這個是思路)測試用的函式
因為在寫的時候因為編碼問題,不能寫入中文

-
開始行動:
-
新增上延遲訪問: time.sleep(1)
-
因為爬蟲訪問的不和人一樣,訪問會很快,
-
這樣可以避免被封ip 還有避免給站點帶來不好的影響
程式執行結束:
部分截圖:有圖有真相,避免無知的噴子
學號規則很好找的,這樣就獲取半個學校的call和qq啦,至於能幹嘛,自己腦補。。。


作者:IFTC
源自:https://www.jianshu.com/p/bdcd11afcc2b
宣告:文章著作權歸作者所有,如有侵權,請聯絡小編刪除
