來自:開源中國
www.oschina.net/translate/what-is-llvm-the-power-behind-swift-rust-clang-and-more
原文:https://www.infoworld.com/article/3247799/development-tools/what-is-llvm-the-power-behind-swift-rust-clang-and-more.html

要瞭解用於以程式設計方式生成機器原生程式碼的編譯器框架是如何讓新語言的推出以及對現有的語言進行增強比以往更加容易了。
新的語言,還有對現有語言的提升,在整個程式設計環境中正大行其道。Mozilla 的 Rust、Apple 的 Swift、Jetbrains 的 Kotlin,以及許多其它的語言都給開發者在速度、安全性、便利性、可移植性還有能力這些方面提供了新的選擇。
為什麼現在正當時呢?一個大因素就是那些用來構建語言的新工具,特別是編譯器。它們中首當其衝就是 LLVM (底層虛擬機器 Low-Level Virtual Machine),這是一個開源專案,最開始作為伊利諾伊州大學的一個研究專案由 Swift 語言的創始人 Chris Lattner 進行開發。
LLVM 使建立新語言變得更加容易,同時也可以增強現有語言的開發。它提供了一些工具,用於自動執行語言建立任務中最不討人喜歡的部分:建立一個編譯器,將輸出的程式碼移植到多個平臺和架構,編寫程式碼來處理常見的語言隱喻,比如異常。它的自由授權意味著它可以自由地作為軟體元件重用或作為服務部署。
使用 LLVM 的語言名冊中有許多熟悉的名字。蘋果的 Swift 語言使用 LLVM 作為它的編譯器框架,而 Rust 則將 LLVM 作為其工具鏈的核心元件。而且,許多編譯器都有一個 LLVM 版本,如 Clang、C/C++ 編譯器(這個名稱叫做“C-lang”),它本身就是一個與 LLVM 緊密相連的專案。而 Kotlin,名義上是一種 JVM 語言,正在開發一種名為 Kotlin Native 的語言版本,它使用 LLVM 來編譯成機器原生程式碼。
LLVM 定義
在它的核心,LLVM 是一個以程式設計方式建立機器原生程式碼的庫。開發人員使用該 API 以一種稱為中間代理或 IR 的格式生成指令。然後 LLVM 可以將 IR 編譯成一個獨立的二進位制檔案,或者在另一個程式(如語言直譯器)的背景關係中執行 JIT (just-in-time) 編譯。
LLVM 的 API 為開發在程式語言中發現的許多常見結構和樣式提供了原始的方式。例如,幾乎每種語言都有函式和全域性變數的概念。LLVM 將函式和全域性變數作為其 IR 中的標準元素,因此,你只需在意 LLVM 的實現,並關註需要註意的語言部分,而不是花費時間和精力重新建立這些特定的輪子。
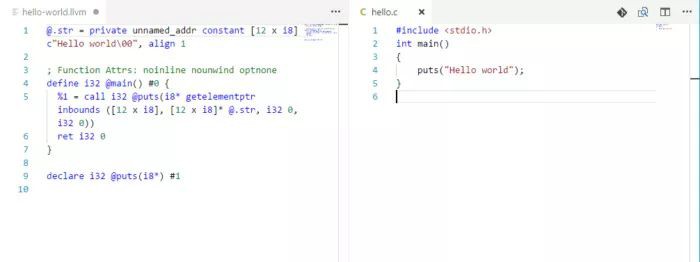
這是一個 LLVM 中間代理(IR)的例子。右邊是一個簡單的 C 程式;左邊是由 Clang 編譯器翻譯成 LLVM IR 的程式碼。
LLVM:專為可移植性而生
關於 LLVM 的一個說法是它像常提到的 C 程式語言:C 語言有時候被認為是一種行動式、高階的組合語言,因為它可以緊密地對映到系統硬體的結構,而且它已經被移植到幾乎所有的系統架構。但是,C 語言只是作為一種可移植的組合語言,是其工作方式的另一種效果;這並不是它的設計標的之一。
相比之下,LLVM 的 IR 是從一開始就設計為可移植的元件。它實現這種可移植性的一種方法是提供獨立於任何特定機器架構的原語。例如,整數型別不侷限於底層硬體的最大位寬度(例如 32 或 64 位),您可以根據需要使用盡可能多的位元位元組來建立基本的整數型別,比如 128 位整數。您也不必擔心手工輸出來匹配特定處理器的指令集;LLVM 也會為你處理這個問題。
程式語言中如何使用 LLVM
LLVM 最常見的用例是作為一種語言的預先(AOT ahead-of-time)編譯器。但 LLVM 也可以用於即時編譯。
用 LLVM 進行即時編譯
有些情況下需要在執行時動態生成程式碼,而不是預先編譯。例如,Julia 語言就是使用 JIT 編譯程式碼,因為它需要快速執行,並透過 REPL(read-eval-print loop)或互動式提示與使用者互動。.Net 和 Mono 可以選擇透過 LLVM 後端方式編譯為原生程式碼。
Numba 是一個 Python 的數學加速包,JIT 將所選擇的 Python 函式編譯成機器碼。它也可以預先編譯使用 Numba 裝飾器裝飾的程式碼,但是(比如 Julia)Python 作為一種快速發展的解釋性語言,使用 JIT 編譯來產生這樣的程式碼更好地補充了 Python 的互動式工作流,比 Python 的預先編譯方式更好。
其他人正在嘗試以非正統方式使用 LLVM 作為 JIT 編譯方式,例如編譯 PostgreSQL 查詢,據說效能提高了五倍。
 Numba 使用 LLVM 進行即時編譯數字程式碼並加速其執行。JIT 加速過的 sum2d 函式的執行速度比常規 Python 程式碼快 139 倍。
Numba 使用 LLVM 進行即時編譯數字程式碼並加速其執行。JIT 加速過的 sum2d 函式的執行速度比常規 Python 程式碼快 139 倍。
使用 LLVM 進行自動程式碼最佳化
LLVM 不僅將 IR 編譯為原生機器碼。你也可以直接以程式設計的方式在整個連結過程中高度精細地最佳化程式碼。最佳化方式是相當積極主動的,能夠實現包括行內函式在內,消除死程式碼(包括未使用的型別宣告和函式引數)和展開迴圈這些事情。
這裡再一次強調,LLVM 的力量讓你不必自己實現所有這一切。LLVM 可以為您處理它們,您也可以根據需要直接禁用。例如,如果你想要一些更小的二進位制程式碼,那麼你可以讓你的編譯器告訴 LLVM 禁用迴圈展開。
使用 LLVM 的領域特定語言
LLVM 已被用於生成多種通用語言的編譯器,但它也可用於生成高度垂直或排他性問題域的語言。從某種意義上說,這就是 LLVM 最閃光的地方,因為它在創造這樣一類語言方面消除了諸多苦差事,並使其表現良好。
例如,Emscripten 專案採用 LLVM IR 程式碼並將其轉換為 JavaScript,理論上支援使用 LLVM 作為後端的任何語言匯出可在瀏覽器中執行的程式碼。長期規劃是支援基於 LLVM 的後端並能夠生成 WebAssembly 程式碼,Emscripten 是 LLVM 靈活性的一個很好的例子。
LLVM 可以被使用的另一種方法是將特定領域的擴充套件新增到現有語言。Nvidia 使用 LLVM 建立了 Nvidia CUDA 編譯器,該編譯器允許語言為 CUDA 新增原生支援,它是作為你生成的原生程式碼的一部分編譯的,而不是透過附帶的庫進行呼叫的。
在不同語言中使用 LLVM
使用 LLVM 的典型方式是透過你所熟悉的語言來編寫程式碼(當然也要有支援 LLVM 的庫)。
兩種常見的可選語言是 C 和 C++。許多 LLVM 開發者會因為以下的原因而預設選擇其中的一個:
-
LLVM 本身是用 C++ 編寫的
-
LLVM 的 API 以 C 和 C++ 版本提供
-
大量的語言開發往往會以 C/C++ 作為一個基礎
不過,這兩種語言並不是唯一的選擇。許多語言都可以原生呼叫 C 語言庫,所以理論上可以用任何這樣的語言進行 LLVM 開發。但需要有一個實際的語言庫可以很好地封裝 LLVM API。幸運的是,許多語言和語言執行時都有這樣的庫,包括 C#/.Net/Mono, Rust, Haskell, OCAML, Node.js, Go, 和 Python。
需要註意的是,一些與 LLVM 的語言系結可能不完整。以 Python 為例,有很多種系結選擇,但每個選項的完整性和實用性各不相同:
-
LLVM 專案維護著自己的一套到 LLVM 的 C API 的系結,但是目前他們沒有繼續維護。
-
llvmpy 在 2015 年後就沒有進行維護了 —— 這對於任何軟體專案都是不利的,在使用 LLVM 時更是如此,因為每個版本的 LLVM 都有一些變化。
-
由建立 Numba 的團隊開發的 llvmlite 已經成為當前在 Python 中的 LLVM 的競爭者。它只實現了 LLVM 功能的一個子集,正如 Numba 專案的需求所規定的那樣。但是這個子集滿足了絕大多數 LLVM 使用者所需。
-
llvmcpy 旨在為 C 庫帶來最新的 Python 系結,它以自動化的方式保持更新,並使用 Python 的習慣用法來訪問它們。llvmcpy 還處於早期階段,但是已經可以用 LLVM API 做一些基本的工作。
如果你對如何使用 LLVM 庫構建語言感興趣,不妨看看 LLVM 的建立者撰寫的使用 C++ 或 OCAML 語言的教程,它將一步步指導你建立一種簡單的名為 Kaleidoscope 的語言。它還被移植到其他語言之上:
-
Haskell:參考原始教程的直接移植。
-
Python:在此網站的教程和原始版本非常相近,而另一個版本則是用互動式命令列進行更為雄心勃勃的重寫。這兩種版本都使用 llvmlite 作為到 LLVM 的系結。
-
Rust 和 Swift:不可避免地,我們不得不將該教程移植到這兩種語言之上,它們都是由 LLVM 自身幫助使其誕生的。
LLVM 尚未實現的功能
瞭解 LLVM 可以實現的功能的同時,有必要知道 LLVM 目前尚未實現的功能。
例如,LLVM 不解析語言的語法。因為目前已經有許多工具實現這個功能,比如 lex/yacc, flex/bison,以及ANTLR。解析語法就意味著必須從編譯中解耦出來,難怪 LLVM 並沒有涉及這個領域。
LLVM 也不會直接干涉到開發語言的軟體文化,比如安裝編譯器的二進位制檔案、如何在安裝中管理軟體包、升級工具鏈 —— 這些都需要開發者自己去實現。
最後也是最重要的一點是,LLVM還沒有對部分通用語言成分給出原語。許多語言都具有某種垃圾回收的記憶體管理方式,或者是作為管理記憶體的主要方式,或者作為對 RAII ( C++ 底層實現的自動垃圾回收,錶面使用 Rust 語法)等策略的附屬方式。LLVM 並不會給你一個垃圾回收機制,但是它提供了實現垃圾回收的工具,它允許在程式碼中使用元資料標記,讓編寫垃圾回收器變得更加容易。
儘管如此,但是 LLVM 未來還有有可能新增原生的機制來實現垃圾回收機制。LLVM 正在快速發展中,大概 6 個月就會有一次大版本的更新。由於當前的許多語言都使用 LLVM 作為開發的核心,因此 LLVM 的迭代速度只會更快而不會放慢。
●本文編號240,以後想閱讀這篇文章直接輸入240即可
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦:《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
