
-
回顧:計算儲存分離, 本地儲存優缺點
-
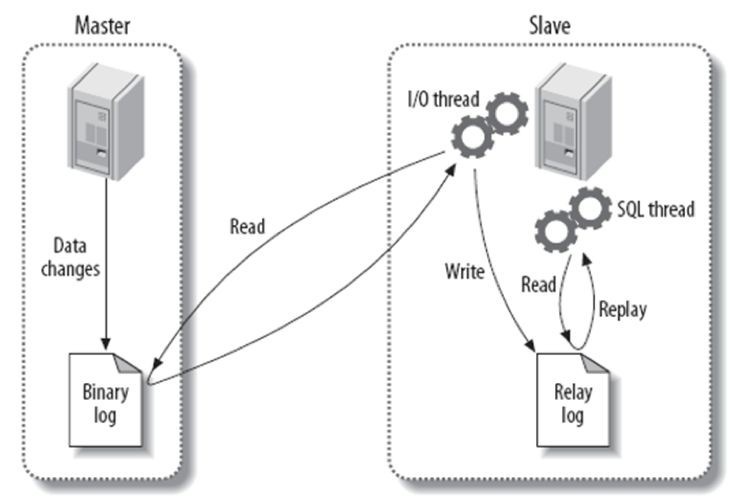
MySQL 基於本地儲存實現資料零丟失
-
效能對比
-
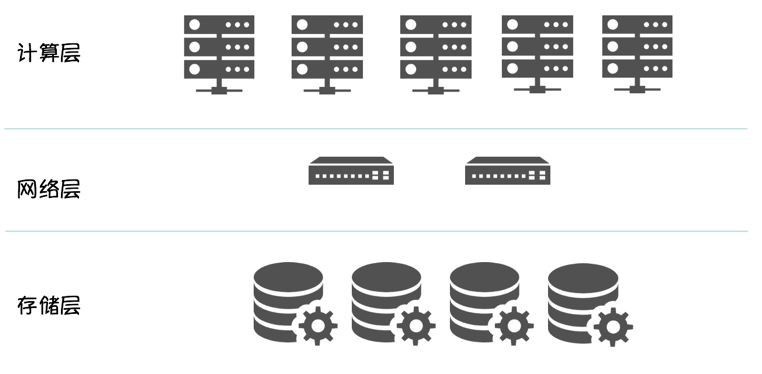
基於 Docker + Kubernetes 的實現

-
架構清晰
-
計算資源 / 儲存資源獨立擴充套件
-
提升實體密度,最佳化硬體利用率
-
簡化實體切換流程:將有狀態的資料下沉到儲存層,Scheduler 排程時,無需感知計算節點的儲存介質,只需排程到滿足計算資源要求的 Node,資料庫實體啟動時,只需在分散式檔案系統掛載 mapping volume 即可。可以顯著的提高資料庫實體的部署密度和計算資源利用率。

以 MySQL 為例
-
通用性更好,同時適用於 Oracle、MySQL,詳見:《容器化RDS——計算儲存分離架構下的”Split-Brain”》。
-
引入分散式儲存,架構複雜度加大。一旦涉及到分散式儲存的問題,DBA 無法閉環解決。
-
分散式儲存選型:
選擇商用,有 Storage Verdor Lock In 風險。
選擇開源,大多數使用者(包括沃趣)都測試過 GlusterFS 和 Ceph,針對資料庫(Sensitive Lantency)場景,效能完全無法接受。

-
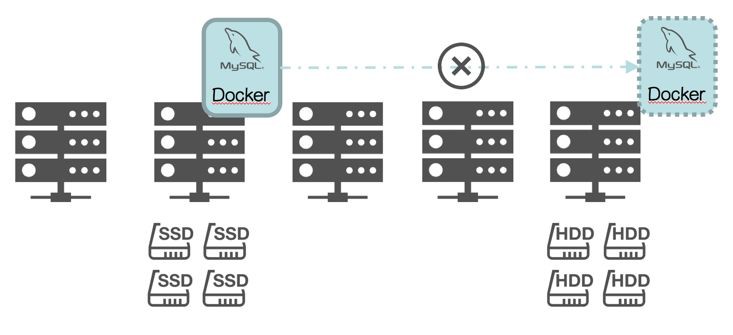
物理容量受限於單機容量;
-
排程更複雜,選定資料庫實體的儲存型別(比如 SSD)後,一旦該實體發生“failover”,只能排程到擁有 SSD 的物理節點,這導致排程器需要對物理節點“Physical Topology Aware”;
-
密度難提升,這是“Physical Topology Aware”的副作用;
-
因資料庫的不同方案差異性較大,通用性無法保證。
-
單位時間內事務能力(TPS)會跟叢集成員數量成反比
-
增加叢集成員會顯著且無法預期的增加事務響應時間
-
增加了叢集成員資料複製的衝突和死鎖的可能性
-
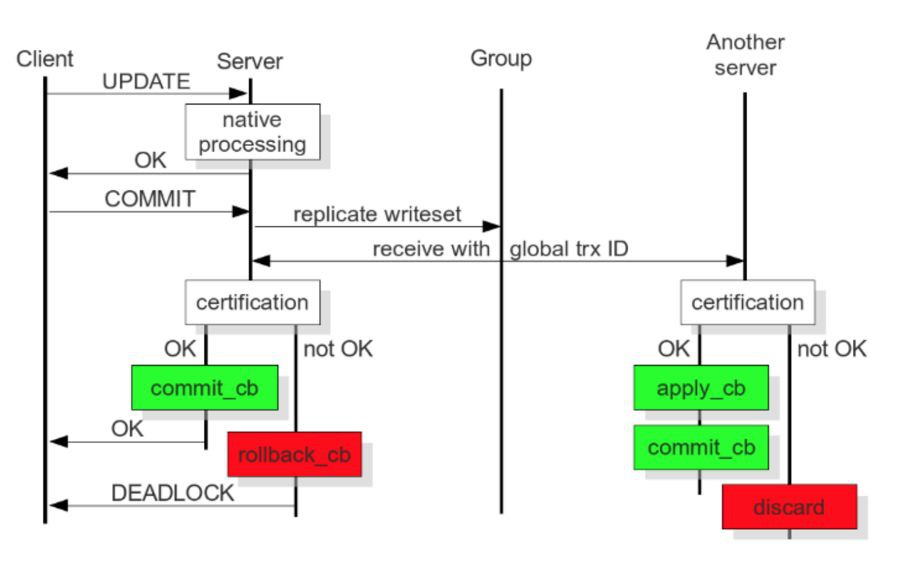
將基於 binlog 改為基於 write-set,write-set 中包含修改的資料,Global Transaction ID(後面簡稱 GTID)和 Primary Key。
GTID 類似 45eec521-2f34-11e0-0800-2a36050b826b:94530586304
94530586304 為 64-bit 有符號整型,用來表示事務在序列中的位置
-
將傳統的 Synchronous Replication 改為 Deferred Update Replication,並將整個過程大致分解成四個階段,本地階段、傳送階段、驗證階段和應用階段,其中:
本地階段:樂觀執行,在事務 Commit 前,假設該 Transcation 在叢集中複製時不會產生衝突。
傳送階段:最佳化同步時間視窗,除去全域性排序並獲取 GTID 為同步操作,衝突驗證和事務應用都為非同步,極大的優化了複製效率。
驗證階段:只有收到該事務的所有前置事務後(不能有 “hole”),該事務和所有未執行的前置事務才能併發驗證,不然不能保證 Global Ordering,因此這裡需要犧牲效率,引入一定的序列化。

需要等待事務 3

-
3 資料庫節點:
-
4 資料庫節點:設定權重避免”split-brain” (⅙ + ⅙ ) + ⅓ + ⅓
-
5 資料庫節點:

-
6 資料庫節點:

-
7 資料庫節點 : 可支援兩種拓撲關係

-
基於Corosync實現(Totem協議),外掛式安裝,MySQL 官方原生外掛。
-
叢集架構,支援多寫(建議單寫)
-
允許少數節點故障,同步延遲較小,保證強一致,資料零丟失
-
單位時間的交易量受 flow control 影響。
-
該專案由 Youtube 開源,從檔案看功能極為強大,高度產品化。
-
作為第二個儲存類專案(第一個是 Rook,有意思是儲存類而不是資料庫類)加入 CNCF,目前還處於孵化階段(incubation-level)。
-
筆者沒有使用經驗,也不知道國內有哪些使用者,不做評論。
-
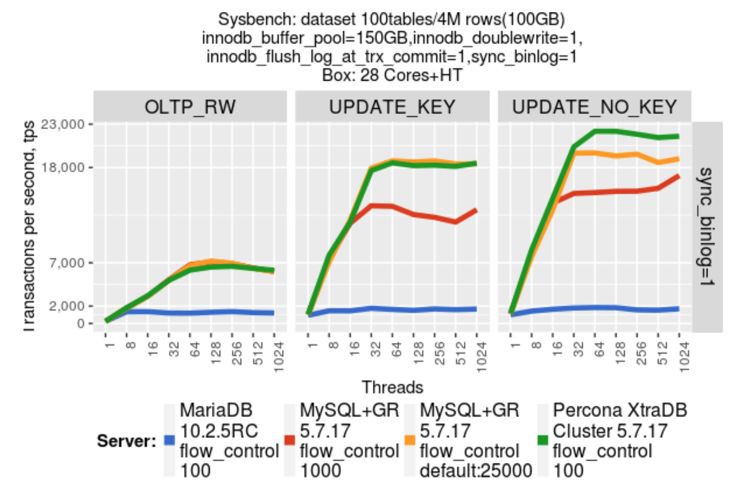
MGR 5.7.17 / PXC 5.7.14-26.17
-
MGR 5.7.17 / PXC 5.7.17-29.20 / MariaDB 10.2.5 RC
-
本地儲存 / 計算儲存分離
-
MGR 5.7.17 對比 PXC 5.7.14-26.17(基於 Galera 3實現)
-
負載模型:OLTP Read/Write (RW)
-
durability:sync_binlog=1,innodb_flush_log_at_trx_commit=1
-
non-durability:sync_binlog=0,innodb_flush_log_at_trx_commit=2

-
增加了 MariaDB 參與對比
-
PXC 升級到 5.7.17-29.20,該版本改進了MySQL write-set 複製層效能[3]。
-
負載模型:依然使用 OLTP Read/Write (RW)
-
durability:sync_binlog=1
-
non-durability:sync_binlog=0

-
Docker + Kubernetes + PXC
-
Docker + Kubernetes + MGC
-
Docker + Kubernetes + MGR

-
運維:部署、備份
-
彈性:計算儲存擴容,叢集擴容
-
高可用:比如 “failover” 的細微差別對業務的影響
-
容錯:比如網路對叢集的影響,尤其是在網路抖動或有明顯延時的情況下
-
社群活躍度
-
……
-
https://dev.mysql.com/doc/refman/5.7/en/group-replication-background.html
-
http://mysqlhighavailability.com/performance-evaluation-mysql-5-7-group-replication/
-
https://www.percona.com/blog/2017/04/19/performance-improvements-percona-xtradb-cluster-5-7-17/
-
https://github.com/kubernetes/kubernetes/tree/master/examples/storage/mysql-galera
-
https://github.com/kubernetes/kubernetes/tree/master/examples/storage/vitess
