
所謂爬蟲,我理解是對網路資料的定製化抓取。運用Python強大的網頁處理能力進行爬蟲,能為我們的債市交易及研究提供很多便捷,比如開發交易員培訓報名的搶位外掛;到從業公示網爬取同業小姐姐們的證件照;實現對中債登、上清所、貨幣中心、交易所、統計局、央行等常用網頁內資訊的批次抓取、監控、分析等。
以17年四季度至今的10年國開行情和10年國開借券存量為例。從下圖可以看出,在17年國慶後,10年國開的借券存量先於收益率上行,且於17年11月中旬早於收益率築頂;空方在17年底部分平倉後,18年開年借券量再度上行,隨後現券則對應呈現最近的“破5”行情,存在一定的領先性:

先不論上述研究的意義和缺陷,今天要討論的是,如果想複製上面的研究,該怎麼做?首先我們很容易拿到10年國開的收益率序列,難點是對170215和170210借券存量序列的獲取,這個數在中債登官網的中債資料→結算行情→風險監測→債券借貸風險監測裡可以找到:
然而,很坑爹的是,這個數在中債登上只能按日查詢,我們每次的點選,能且只能查詢到指定某一日的數值。如果想要連續區間的時間序列?不存在的。

也即是說,透過人工的方法,如果要獲取從17年9月至今每個交易日的10年國開借券存量資料,必須重覆開啟中債登網、選券(210和215各一次)、改日期、點選查詢、記錄下結果這個操作將近200次。這個時候,我們可以選擇請個實習生,又或者寫個Python爬蟲以代勞上面的操作。

在開始爬蟲前,需要做些準備工作:
首先,安裝Python並瞄幾眼語法入門···
然後,觀察剛剛查詢所用的中債登地址:http://www.chinabond.com.cn/jsp/include/EJB/jdtj_dzzq.jsp?sel4=1&tbSelYear6;=2018&tbSelMonth6;=1&calSelectedDate6;=4&ZQFXRJD1;=00&FUXFSJD1;=00&JXFSJD2;=00&JDQX2;=00&ZQFXRJD3;=00&ZQFXRJD4;=00&I;_ZQDM_JD=170215
地址結尾裡熟悉的170215告訴了我們,這個查詢網頁傳回的結果,是由網頁地址所控制的。刨除那些冗雜資訊,就能看出這個網址的規律所在(這也是選這個作第一篇例子的原因,下一篇將提到如果網址不變的情況如何處理)。網址中 “…Year6=2018 …Month6=1 …Date6=4 …JD=170215”的這串字元,顧名思義,是對2018年1月4日的170215借券存量的提取,大家可以試試保持其他內容不變,只改變網址中這幾個關鍵數字,就能實現對網址中指定日期/券程式碼借券存量的查詢。
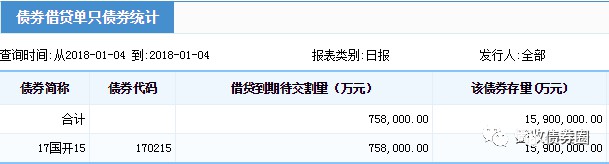
在掌握了網址規律後,接下來就是對網頁中想要的內容——借券存量進行提取。雖然在我們眼裡,中債登的查詢結果網頁是長這樣的:
而在瀏覽器和Python君的眼裡,網頁其實是下圖這樣的一堆“串串”(這些“串串”可以透過在Chrome裡開啟網頁後右擊“檢查”獲取到,其中,每一行都叫做一個tag,下圖裡tr、td等是tag的名稱;class、bgcolor、align等是tag的屬性;最關鍵的“170215”、“758,000.00”則分別是兩個相鄰的名為td的tag裡的內容):
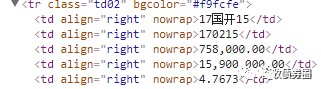
雖然和平常看到的網頁不太一樣,但這些tag內含的資訊和我們所見的是一致的。可以看到,此次的標的數值——170215的借券餘額75.8億,是藏在了
這個tag裡,就在那裡,不悲不喜。就像Word裡可以Ctrl+F查詢一樣,我們也可以透過Python,從這堆tag裡把含有170215這個數的tag用Ctrl+F找出來,也即
,再在往下一行的tag裡,就藏著我們想要查詢的18年1月4日170215的借券餘額數值,75.8億。
所以問題就已經非常簡化了。現在已知了兩個事情:1、中債登查詢借券餘額的地址是有規律的;2、這些規律網址裡的內容可透過Python被簡化為多個tag的形式並被查詢。接下來的思路就是,讓Python自動地根據網址規律讀取每天的網頁,接著讓Python把每天查詢的網頁剝皮成上面那堆tag,再從中Ctrl+F找到在170215和170210所在tag的下一個tag裡的借券量數值,提取出來並儲存。
要如何指揮Python完成了上面的工作呢?這裡用到兩個Python的包:urllib(這個包將在下一篇中變成selenium + phantomjs以抓取更複雜網頁)和BeautifulSoup。
urllib負責把網頁中的內容讀進Python裡,可以看做是個瀏覽器;BeautifulSoup則負責Ctrl+F處理那些tag的資訊。所以,這個案例裡實際要做的工作,就是按查詢日期批次把網頁內容透過urllib拉扯進Python,然後用BeautifulSoup把想要的東西Ctrl+F出來。
urllib包裡,我們主要用到urllib.request.urlopen(‘網址’)的函式,從名字可以看出來,就是把標的網頁請求並開啟讀取的函式,讀取完丟進Python後就可以把工作交給BeautifulSoup了。
BeautifulSoup則是網頁爬蟲的核心,建議大家多熟悉其官方檔案,這可能是剛接觸Python爬蟲時最常查閱的參考書。
在這個案例裡,主要用到BeautifulSoup的三個功能:
.find(‘td’, text=‘170215’):顧名思義就是找到名稱為td,且內容寫作170215的tag
.next_sibling:和字面意一樣,就是定位到下一個tag身上的意思
.string:把tag裡的內容拎出來
僅用這三個陳述句,就實現了“尋找170215所在地方,並下移到下一個tag裡抓數”的需求。
是不是很簡單?所以我已經幫大家寫好了,並且標註上了可能遇到的坑。把下麵程式碼複製進裝好相關包和萬得介面的Python3.6可以直接執行。(看不全的程式碼可左右滑動螢幕檢視,我的程式碼效率較低,供參考):
# By 債市小黃
# 首先匯入剛剛提到的兩個包urllib和BeautifulSoup
from urllib import request
from bs4 import BeautifulSoup
# 以及萬得介面用以提取交易日,xlwt用以輸出結果到Excel,os用以開啟輸出的Excel
from WindPy import w
from xlwt import Workbook
from os import system
# 定義借券餘額爬蟲函式,將年、月、日、觀察券串列作為輸入量
def jqye(year, month, day, bond_list):
# 將年月日填入,補齊中債登網址日期,用urllib讀取補齊的查詢網址,獲取當天的借券統計,並存為page
page = request.urlopen("http://www.chinabond.com.cn/jsp/include/EJB/jdtj_dzzq.jsp?sel4=1&tbSelYear6;="
+ str(year) + "&tbSelMonth6;=" + str(month) + "&calSelectedDate6;=" + str(day)
+ "&ZQFXRJD1;=00&FUXFSJD1;=00&JXFSJD2;=00&JDQX2;=00&ZQFXRJD3;=00&ZQFXRJD4;=00&I;_ZQDM_JD=")
# 接下來把剛剛讀到的網址內容page用Beautifulsoup解析
# 坑1:用html.parser解析器會少丟資訊,用gb18030編碼解析以避免中文亂碼
# 將解析出的內容儲存在soup裡
global soup
soup = BeautifulSoup(page, "html.parser", from_encoding="gb18030")
# 定義用以輸出的list
jqye_list = []
# 用for...in...迴圈遍歷標的券串列裡的所有券程式碼
# 用find找到券程式碼所對應的tag,如果找不到意味著沒有這個的數(往往因為查詢日這個券還沒發行),則計為0
# 如果找到了則往下數1個tag,裡面就是該債券對應的借券存量,把這個量提取出來
# 坑2:這裡連用了2個.next_sibling,因解析後tag間會多出個空格,因此索引下個tag要用到2個.next_sibling
# 坑3:網頁上的數字帶空格、逗號和小數點,需把都去掉,才能順利地被Python轉為整數識別,即.strip().replace(',', '').replace('.00', '')的作用
for bond_name in bond_list:
bond_position = soup.find('td', text=bond_name)
if bond_position is None:
bond_jqye = 0
else:
bond_jqye = int(bond_position.next_sibling.next_sibling.string.strip().replace(',', '').replace('.00', ''))
# 把爬到的借券存量輸出到螢幕上,並儲存在jqye_list裡
print(str(year) + str(month).zfill(2) + str(day).zfill(2) + ':' + bond_name + ':' + str(bond_jqye))
jqye_list.append(bond_jqye)
# 到這就爬完某一天裡bond_list裡各個標的券的數值了,把結果傳回
return jqye_list
# 用萬得介面提取交易日,這裡是提取17年9月1日至今的交易日
# 坑4:萬得的Python介面好像只有各交易所的交易日,沒法提取銀行間的交易日,要嚴謹的銀行間交易日序列的話需要用其Excel外掛
w.start()
trade_day_list = w.tdays("2017-9-1").Times
w.stop()
# 向程式給出要爬借券量的標的券串列,這裡可以是一隻,也可以是多隻併排
bond_list = ['170215', '170210']
total_jqye_list = []
for trade_day in trade_day_list:
# 將日期和標的券串列輸入定義的jqye函式裡跑起來
jqye_list = jqye(trade_day.year, trade_day.month, trade_day.day, bond_list)
total_jqye_list.append(jqye_list)
# 坑5:將結果一邊爬一邊往Excel裡儲存,之所以不全部爬完再一次性儲存是避免中途網路原因報錯中斷導致前功盡棄
output_workbook = Workbook()
sheet1 = output_workbook.add_sheet(u'jqye_data', cell_overwrite_ok=True)
sheet1.write(0, 0, 'Date')
for i in range(len(bond_list)):
sheet1.write(0, i + 1, bond_list[i])
for i in range(len(total_jqye_list)):
sheet1.write(i + 1, 0, trade_day_list[i])
for j in range(len(total_jqye_list[i])):
sheet1.write(i + 1, j + 1, total_jqye_list[i][j])
output_workbook.save('jqye_output.xls')
system('jqye_output.xls')
# 爬完收工,在Excel裡檢視結果,Date列如果顯示不正確改下單元格日期格式就好
可以發現,哪怕基於我十分糟糕的語法,除去註釋,Python也只需30行,就能把這次的需求完整表達。上述程式開動後,一般10分鐘以內能爬完一個季度的數。執行時,Python會是這樣的:
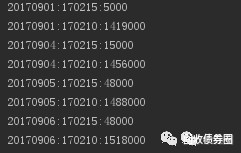
是不是很excited?
如果還想想練手,可以試試把中債登上每日買斷回購的210和215餘額也一併爬了,操作與上面類似。這樣就能更全面統計做空力量了。
在日常使用瀏覽器開啟網頁時,想看的內容往往是不會直接展示在我們面前的,需要我們輸入賬戶密碼登入、操作下拉選單、點選按鈕、等待載入等一些列過程後才會出現。而對這類網頁進行Python爬蟲,使用上一篇中的urllib+BeautifulSoup的方法是難以完成的。

對於這類複雜網頁的爬取,比較容易上手(也比較浪費記憶體)的做法是用selenium + phantomjs + BeautifulSoup(phantomjs是個瀏覽器,大家也可換成熟悉的Chrome、Firefox等)。其思路簡單粗暴卻有效,就是用Python程式碼透過selenium去控制一個瀏覽器,直接在瀏覽器上模擬和複製人工訪問網頁的操作,從而實現Python與網頁間的一些複雜互動,甚至能用來繞過大部分的反爬蟲和驗證碼機制。
還是繼續舉個例子吧。17年底的時候,市場上很多人在關註18年的國債新發行計劃的釋出,這個更新的公告可在中債登主頁→業務操作→發行與付息兌付→國債→發行計劃中找到。在等待新公告的日子裡,我們除了可以手工F5盯著網頁掃清外,還可以使用Python爬蟲,自動且實時對這個頁面進行持續監控(同理可實時監控最新的各類公告、統計資料、以及央行微播的微博證監會釋出的微博等),併在有新內容更新的時候,第一時間自動彈出一個提示:

啊,不好意思放錯了,是這個提示:

從而,就能實現對最新資訊的第一時間獲取和響應。
沿用上次的思路,來觀察一下這次網頁的特點。首先,開啟網頁並依次點選“國債”、“發行計劃”的按鈕後,可以看到這是我們想要監控到的內容:
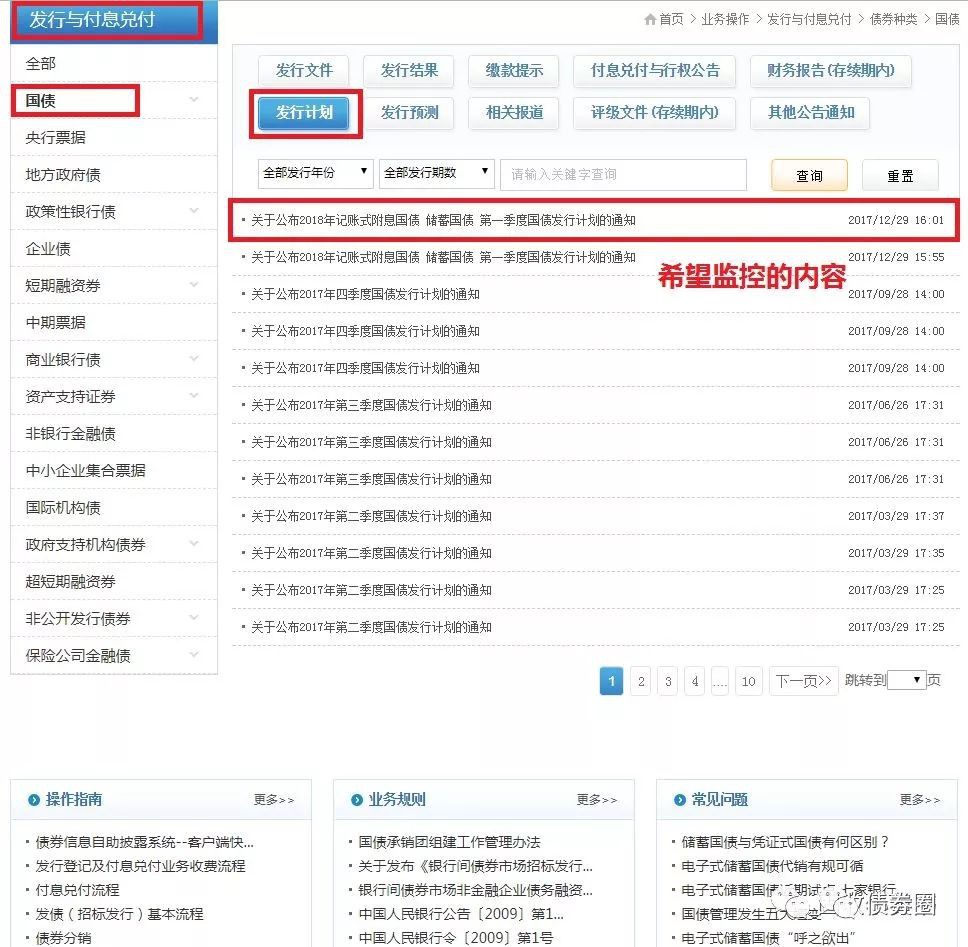
透過瀏覽器檢查網頁後,可知這個內容的具體位置,是在iframe這個tag下麵的一個名為a的tag裡title屬性的一串文字(關於tag的說明,請翻閱上一篇):

如果直接套用上一篇的方法,在Python裡用urllib+BeautifulSoup的組合來操作這個網頁的話:
from bs4 import BeautifulSoup
from urllib import request
page = request.urlopen("http://www.chinabond.com.cn/Channel/21000")
soup = BeautifulSoup(page, "html.parser", from_encoding="gb18030")
print(soup.prettify())
Python解析到iframe下麵的內容卻是這樣的:

上下對比可知,透過urllib+BeautifulSoup的方法,我們設想是能讀取到iframe這個tag下麵的大量內容,並找到其中一個名為a的tag中的最新公告資訊。然而事實上是,Python在iframe裡什麼都讀取不到,更遑論點選操作網頁上的按鈕讀取不同的公告資訊了。
回到網頁直觀感受一下,上述的操作是得到這樣的結果:

那種感覺就像,當我開始學會做蛋餅,才發現你,不吃早餐。
大家觀察可以發現,這次的網址和上一篇的不一樣:我們對這次的這個中債登發行公告頁面內的各類點選操作(如點選“企業債”→“付息兌付與行權公告”),將使網頁內容發生相對應的變化,但其位址列裡的實際網址http://www.chinabond.com.cn/Channel/21000,卻不會隨著我們在這個頁面內的點選操作而變更。事實上,這是一個透過js父頁面向iframe中子頁面通訊以實現內容載入的網頁,其呈現的內容並不受網頁地址所控制。
因此,這裡要用到selenium + phantomjs + BeautifulSoup的方法,透過selenium 操作phantomjs瀏覽器,直接模擬瀏覽這個網頁,併進行相關操作,以實現“平時所見所點即當下所爬”。在這個例子中,主要用到selenium的三個功能,一個是get(‘網址’),就是讀取網頁;一個是click(),就是點選按鈕,用來對上圖中“讀得到但操作不了”的那些按鈕進行點選;一個是switch_to.frame(‘frame名’),就是把爬取的標的移到上圖中“完全讀不到但正是我們要監控的內容”這塊東西上面。剩下的就是用BeautifulSoup把這個最新的公告索引出來,具體方法與上一篇完全一致。
可以看出,其實這也就是我們平時自己檢視網頁的順序操作,問題是不是又再度簡單化了?所以我又已經幫大家寫好了(看不全的程式碼可左右滑動螢幕檢視,我的程式碼效率較低,供參考):
# 首先匯入剛剛提到的兩個包urllib和BeautifulSoup
# PhantomJS無需匯入,是個exe檔案,需提前安裝,也可以直接用Chrome等其他瀏覽器,但中間解析tag的過程可能不同
from bs4 import BeautifulSoup
from selenium import webdriver
# time以使用時間相關函式,tkinter以實現彈窗提醒
import time
from tkinter import messagebox
# 定義監控爬取函式
def gz_fxjh_jk(old_news):
# 用selenium裡的webdriver啟用PhantomJS瀏覽器,註意要把路徑修改成自己安裝瀏覽器時所在位置
driver = webdriver.PhantomJS(executable_path='D:/Anaconda3/phantomjs/bin/phantomjs.exe')
# 讀取中債登標的地址
driver.get('http://www.chinabond.com.cn/Channel/21000')
# 找到網頁上“國債”按鈕所對應的名稱'span_21770',可以透過瀏覽器檢查網頁找到這個名稱
elem = driver.find_element_by_id('span_21770')
# 點選這個按鈕,進入國債公告查詢頁面
elem.click()
# 坑:點選後對應更新的頁面是在另一個js框架裡,需要切換frame以繼續接下來的操作
driver.switch_to.frame('ffrIframe')
# 找到網頁上“發行計劃”按鈕所對應的名稱'fxjh'並點選,進入發行計劃頁面
elem = driver.find_element_by_id('fxjh').find_element_by_tag_name('a')
elem.click()
# 和之前一樣,把讀取到的網頁資訊拉進BeautifulSoup分析
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 把最新公告的內容拉取進來
news_position = soup.find('li', 'liqxd1')
latest_news_time = news_position.span.string
latest_news = news_position.find('a')['title']
# 比對新老公告,如果有更新則彈窗提醒
if latest_news == old_news:
print(str(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))) + ' No News')
else:
print(messagebox.showinfo('最新公告更新', latest_news_time + '
' + latest_news))
return latest_news
# 建立一個死迴圈,實現對頁面的持續監控
latest_news = None
while True:
latest_news = gz_fxjh_jk(latest_news)
# 每次抓取完後等待60秒後再進行下一次抓取
time.sleep(60)
上述程式跑起來的時候,有新公告時Python會彈窗提醒:
沒的話,Python還是會世世生生為你站崗:

這樣,每當有什麼新訊息,我們就能跑得比西方記者還快了。
這種跨frame的操作會在很多網頁上出現,比如網易雲音樂的網頁版播放頁面就是這樣的,大家可以拿來練手。
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Python好文請點選【閱讀原文】哦
↓↓↓
