
系統的物理記憶體是有限的,而對記憶體的需求是變化的, 程式的動態性越強,記憶體管理就越重要,選擇合適的記憶體管理演演算法會帶來明顯的效能提升。
比如nginx, 它在每個連線accept後會malloc一塊記憶體,作為整個連線生命週期內的記憶體池。 當HTTP請求到達的時候,又會malloc一塊當前請求階段的記憶體池, 因此對malloc的分配速度有一定的依賴關係。(而apache的記憶體池是有父子關係的,請求階段的記憶體池會和連線階段的使用相同的分配器,如果連線記憶體池釋放則請求階段的子記憶體池也會自動釋放)。
標的
記憶體管理可以分為三個層次,自底向上分別是:
-
作業系統內核的記憶體管理
-
glibc層使用系統呼叫維護的記憶體管理演演算法
-
應用程式從glibc動態分配記憶體後,根據應用程式本身的程式特性進行最佳化, 比如使用取用計數std::shared_ptr,apache的記憶體池方式等等。當然應用程式也可以直接使用系統呼叫從核心分配記憶體,自己根據程式特性來維護記憶體,但是會大大增加開發成本。
本文主要介紹了glibc malloc的實現,及其替代品。
一個優秀的通用記憶體分配器應具有以下特性:
-
額外的空間損耗儘量少
-
分配速度盡可能快
-
儘量避免記憶體碎片
-
快取本地化友好
-
通用性,相容性,可移植性,易除錯
目前大部分服務端程式使用glibc提供的malloc/free系列函式,而glibc使用的ptmalloc2在效能上遠遠弱後於google的tcmalloc和facebook的jemalloc。 而且後兩者只需要使用LD_PRELOAD環境變數啟動程式即可,甚至並不需要重新編譯。
ptmalloc原理
系統呼叫介面
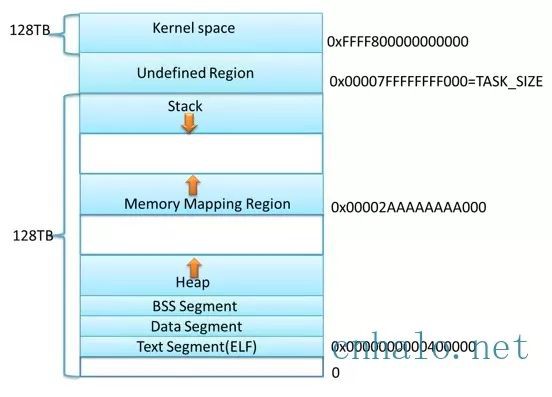
上圖是 x86_64 下 Linux 行程的預設地址空間, 對 heap 的操作, 作業系統提供了brk()系統呼叫,設定了Heap的上邊界; 對 mmap 對映區域的操作,操作系 統 供了 mmap()和 munmap()函式。
因為系統呼叫的代價很高,不可能每次申請記憶體都從核心分配空間,尤其是對於小記憶體分配。 而且因為mmap的區域容易被munmap釋放,所以一般大記憶體採用mmap(),小記憶體使用brk()。
-
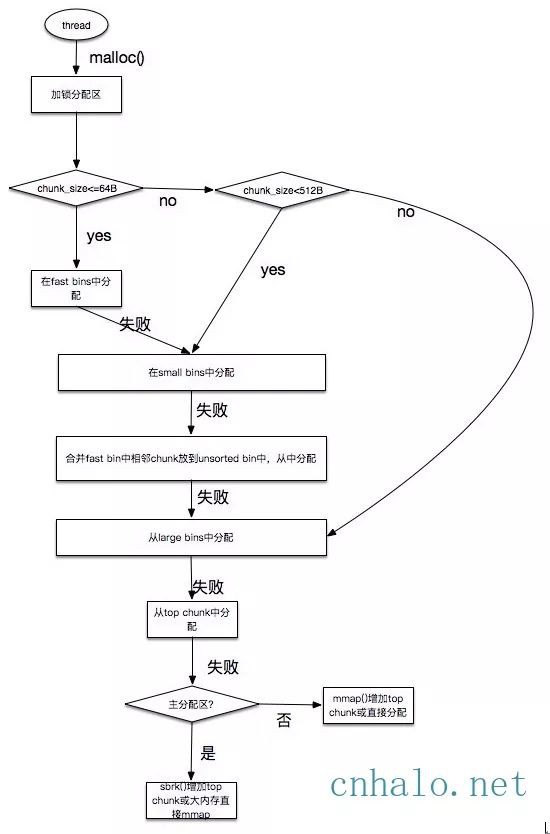
- Ptmalloc2有一個主分配區(main arena), 有多個非主分配區。 非主分配區只能使用mmap向作業系統批發申請HEAP_MAX_SIZE(64位系統為64MB)大小的虛擬記憶體。 當某個執行緒呼叫malloc的時候,會先檢視執行緒私有變數中是否已經存在一個分配區,如果存在則嘗試加鎖,如果加鎖失敗則遍歷arena連結串列試圖獲取一個沒加鎖的arena, 如果依然獲取不到則建立一個新的非主分配區。
- free()的時候也要獲取鎖。分配小塊記憶體容易產生碎片,ptmalloc在整理合併的時候也要對arena做加鎖操作。在執行緒多的時候,鎖的開銷就會增大。
ptmalloc 將相似大小的 chunk 用雙向鏈錶連結起來, 這樣的一個連結串列被稱為一個 bin。Ptmalloc 一共 維護了 128 個 bin,並使用一個陣列來儲存這些 bin(如下圖所示)
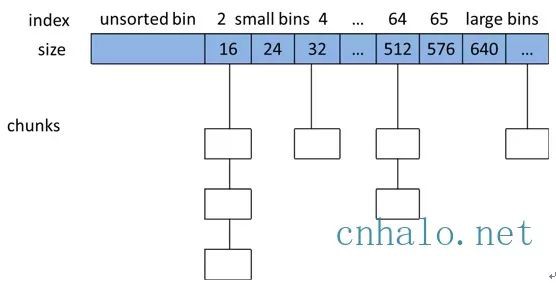
陣列中的第一個為 unsorted bin, 陣列中從 2 開始編號的前 64 個 bin 稱為 small bins, 同一個small bin中的chunk具有相同的大小。small bins後面的bin被稱作large bins。
當free一個chunk並放入bin的時候, ptmalloc 還會檢查它前後的 chunk 是否也是空閑的, 如果是的話,ptmalloc會首先把它們合併為一個大的 chunk, 然後將合併後的 chunk 放到 unstored bin 中。 另外ptmalloc 為了提高分配的速度,會把一些小的(不大於64B) chunk先放到一個叫做 fast bins 的容器內。
-
-
在fast bins和bins都不能滿足需求後,ptmalloc會設法在一個叫做top chunk的空間分配記憶體。 對於非主分配區會預先透過mmap分配一大塊記憶體作為top chunk, 當bins和fast bins都不能滿足分配需要的時候, ptmalloc會設法在top chunk中分出一塊記憶體給使用者, 如果top chunk本身不夠大, 分配程式會重新mmap分配一塊記憶體chunk, 並將 top chunk 遷移到新的chunk上,並用單鏈錶連結起來。如果free()的chunk恰好 與 top chunk 相鄰,那麼這兩個 chunk 就會合併成新的 top chunk,如果top chunk大小大於某個閾值才還給作業系統。主分配區類似,不過透過sbrk()分配和調整top chunk的大小,只有heap頂部連續記憶體空閑超過閾值的時候才能回收記憶體。
-
需要分配的 chunk 足夠大,而且 fast bins 和 bins 都不能滿足要求,甚至 top chunk 本身也不能滿足分配需求時,ptmalloc 會使用 mmap 來直接使用記憶體對映來將頁對映到行程空間。
-
tcmalloc是Google開源的一個記憶體管理庫, 作為glibc malloc的替代品。目前已經在chrome、safari等知名軟體中運用。
根據官方測試報告,ptmalloc在一臺2.8GHz的P4機器上(對於小物件)執行一次malloc及free大約需要300納秒。而TCMalloc的版本同樣的操作大約只需要50納秒。
tcmalloc為每個執行緒分配了一個執行緒本地ThreadCache,小記憶體從ThreadCache分配,此外還有個中央堆(CentralCache),ThreadCache不夠用的時候,會從CentralCache中獲取空間放到ThreadCache中。
小物件(<=32K)從ThreadCache分配,大物件從CentralCache分配。大物件分配的空間都是4k頁面對齊的,多個pages也能切割成多個小物件劃分到ThreadCache中。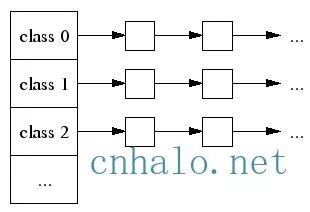
小物件有將近170個不同的大小分類(class),每個class有個該大小記憶體塊的FreeList單連結串列,分配的時候先找到best fit的class,然後無鎖的獲取該連結串列首元素傳回。如果連結串列中無空間了,則到CentralCache中劃分幾個頁面並切割成該class的大小,放入連結串列中。
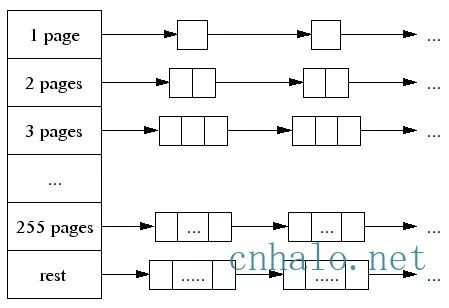
當best fit的頁面連結串列中沒有空閑空間時,則一直往更大的頁面空間則,如果所有256個連結串列遍歷後依然沒有成功分配。 則使用sbrk, mmap, /dev/mem從系統中分配。
tcmalloc PageHeap管理的連續的頁面被稱為span.
如果span未分配, 則span是PageHeap中的一個連結串列元素。
如果span已經分配,它可能是傳回給應用程式的大物件, 或者已經被切割成多小物件,該小物件的size-class會被記錄在span中。
在32位系統中,使用一個中央陣列(central array)映射了頁面和span對應關係, 陣列索引號是頁面號,陣列元素是頁面所在的span。 在64位系統中,使用一個3-level radix tree記錄了該對映關係。
如果是小物件,span會告訴我們他的size class,然後把該物件插入當前執行緒的ThreadCache中。如果此時ThreadCache超過一個預算的值(預設2MB),則會使用垃圾回收機制把未使用的object從ThreadCache移動到CentralCache的central free lists中。
如果是大物件,span會告訴我們物件鎖在的頁面號範圍。 假設這個範圍是[p,q], 先查詢頁面p-1和q+1所在的span,如果這些臨近的span也是free的,則合併到[p,q]所在的span, 然後把這個span回收到PageHeap中。
CentralCache的central free lists類似ThreadCache的FreeList,不過它增加了一級結構,先根據size-class關聯到spans的集合, 然後是對應span的object連結串列。如果span的連結串列中所有object已經free, 則span回收到PageHeap中。
Tcmalloc佔用更少的額外空間。例如,分配N個8位元組物件可能要使用大約8N * 1.01位元組的空間。即,多用百分之一的空間。Ptmalloc2使用最少8位元組描述一個chunk。
更快。小物件幾乎無鎖, >32KB的物件從CentralCache中分配使用自旋鎖。 並且>32KB物件都是頁面對齊分配,多執行緒的時候應儘量避免頻繁分配,否則也會造成自旋鎖的競爭和頁面對齊造成的浪費。
測試環境是2.4GHz dual Xeon,開啟超執行緒,redhat9,glibc-2.3.2, 每個執行緒測試100萬個操作。
上圖中可以看到尤其是對於小記憶體的分配, tcmalloc有非常明顯效能優勢。
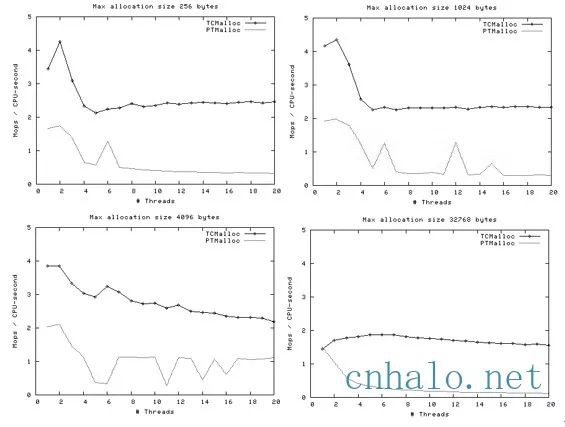 上圖可以看到隨著執行緒數的增加,tcmalloc效能上也有明顯的優勢,並且相對平穩。
上圖可以看到隨著執行緒數的增加,tcmalloc效能上也有明顯的優勢,並且相對平穩。
github使用tcmalloc後,mysql效能提升30%
jemalloc是facebook推出的, 最早的時候是freebsd的libc malloc實現。 目前在firefox、facebook伺服器各種元件中大量使用。
- 與tcmalloc類似,每個執行緒同樣在<32KB的時候無鎖使用執行緒本地cache。
- Jemalloc在64bits系統上使用下麵的size-class分類:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB]
Huge: [4 MiB, 8 MiB, 12 MiB, …] - small/large物件查詢metadata需要常量時間, huge物件透過全域性紅黑樹在對數時間內查詢。
- 虛擬記憶體被邏輯上分割成chunks(預設是4MB,1024個4k頁),應用執行緒透過round-robin演演算法在第一次malloc的時候分配arena, 每個arena都是相互獨立的,維護自己的chunks, chunk切割pages到small/large物件。free()的記憶體總是傳回到所屬的arena中,而不管是哪個執行緒呼叫free()。
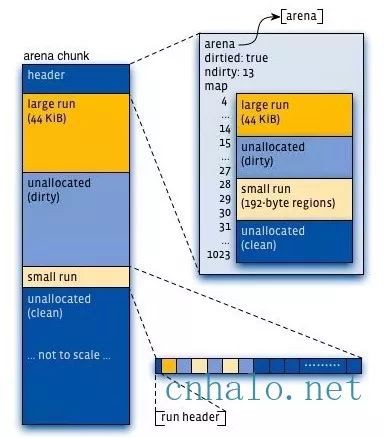
上圖可以看到每個arena管理的arena chunk結構, 開始的essay-header主要是維護了一個page map(1024個頁面關聯的物件狀態), essay-header下方就是它的頁面空間。 Small物件被分到一起, metadata資訊存放在起始位置。 large chunk相互獨立,它的metadata資訊存放在chunk essay-header map中。
透過arena分配的時候需要對arena bin(每個small size-class一個,細粒度)加鎖,或arena本身加鎖。
並且執行緒cache物件也會透過垃圾回收指數退讓演演算法傳回到arena中。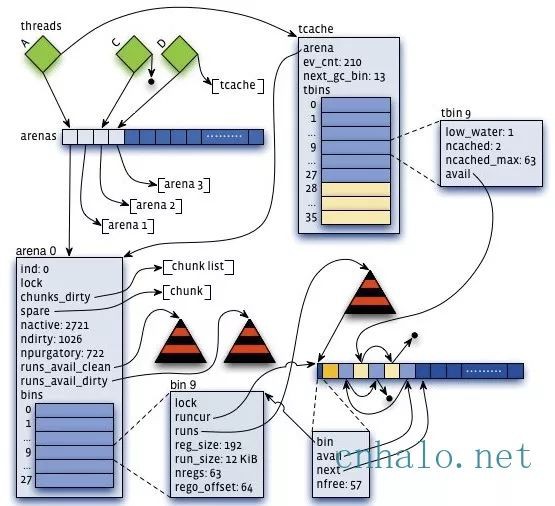
Jemalloc大概需要2%的額外開銷。(tcmalloc 1%, ptmalloc最少8B)
Jemalloc和tcmalloc類似的執行緒本地快取,避免鎖的競爭
相對未使用的頁面,優先使用dirty page,提升快取命中。
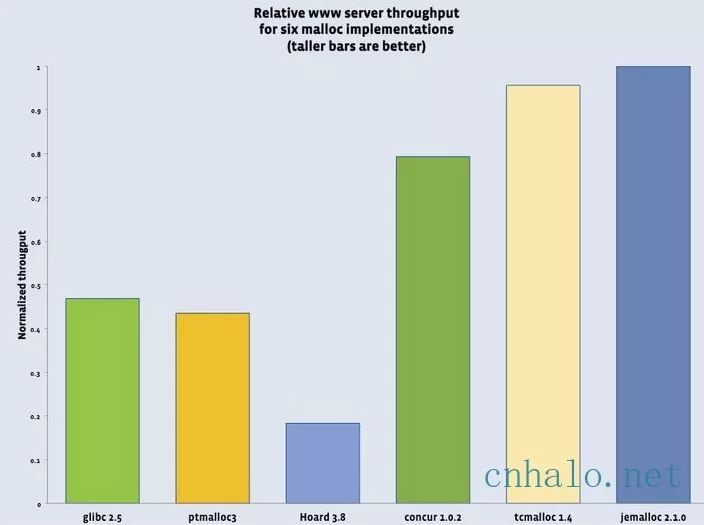
上圖是伺服器吞吐量分別用6個malloc實現的對比資料,可以看到tcmalloc和jemalloc最好(facebook在2011年的測試結果,tcmalloc這裡版本較舊)。
4.3.2 mysql最佳化
測試環境:2x Intel E5/2.2Ghz with 8 real cores per socket,16 real cores, 開啟hyper-threading, 總共32個vcpu。 16個table,每個5M row。
OLTP_RO測試包含5個select查詢:select_ranges, select_order_ranges, select_distinct_ranges, select_sum_ranges,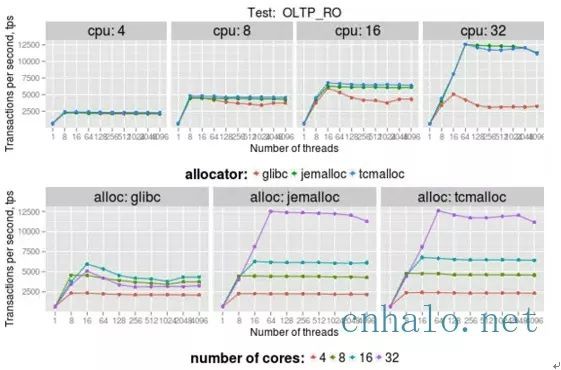
可以看到在多核心或者多執行緒的場景下, jemalloc和tcmalloc帶來的tps增加非常明顯。
在多執行緒環境使用tcmalloc和jemalloc效果非常明顯。
當執行緒數量固定,不會頻繁建立退出的時候, 可以使用jemalloc;反之使用tcmalloc可能是更好的選擇。
