即使不使用 Kubernetes,在編排持久化 workload 時,你都需要瞭解編排框架和 Cloud Provider 是如何互動的,資料又是如何被寫”壞”的。以下描述的場景具有普遍意義,也是必須要回答的問題。
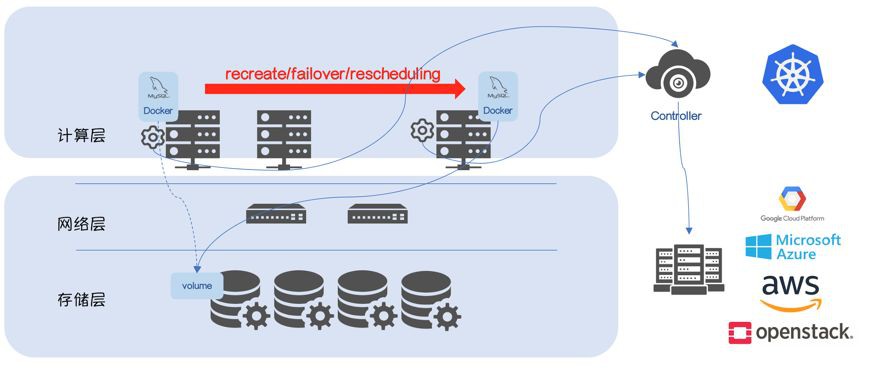
從儲存池中獲取 RW Volume,掛載到指定 Node 上,併在該 Node 上啟動持久化應用 MySQL。
-
生成 Volume
-
mount 到資料庫實體所在節點,資料庫啟動
大多數情況下 Kubernetes 不會直接管理 bare-metal,而是執行在第三方 Cloud Provider 上(GCE/Azure/AWS/OpenStack),Kubernetes 會作為 Volume 的使用者,由 Cloud Provider 負責 Volume 的生命週期,所以之前的 mount/unmount 會有所變化:
如果Volume 在 unmount 之後,沒有“通知” Cloud Provider,Cloud Provider 會保證該 Volume 不會被掛載到其他 Node 上,“多點掛載”在大多數場景下會導致“Data Corruption”,所以新增這兩個步驟是有必要的,Cloud Provider 需要感知 Volume 的“使用場景”(譬如在 GCE 環境,是不允許RW Volume 同時掛載到多個節點)。這兩個步驟被稱為 attach/detach。
需要繼續思考一個問題:誰來“通知”Cloud Provider?
Kubernetes 1.3 之前,以上所有的工作由 Kubelet 完成,由Volume Plugin 適配第三方 Cloud Provider 的邏輯。
但 Kubelet 是執行在 Node 端的 Agent。
一旦 Node 重啟 / Crash / 網路故障,都會導致無法“通知”Cloud Provider,即便該 Volume 已經沒有應用訪問,Cloud Provider 都不會讓任何節點使用它。
當然,還會有其他問題,譬如多個 Kubelet 帶來的“race condition”。
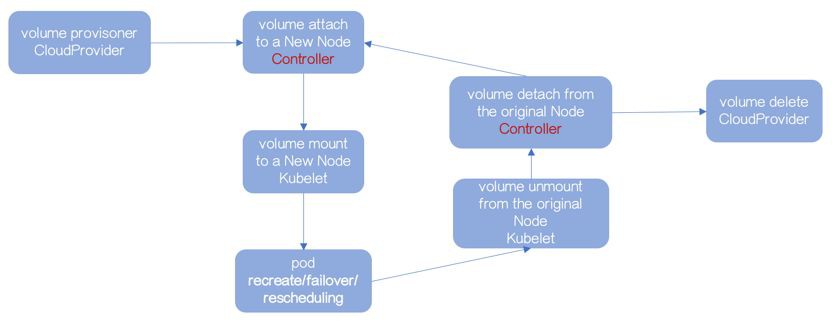
解耦 Attach-Mount-Unmount-Detach

流程不變,Kubernetes 1.3 之後,嘗試使用專門的 Controller 管理 Attach 和 Detach 操作。
該 Controller 被叫做 AttachDetach Controller,它執行在已有的 Controller Plane 上。
透過“volumes.kubernetes.io/controller-managed-attach-detach”啟動該特性(預設使用該特性)。
attach-mount-umount-detach流程的序列有序是保障資料不被寫“壞”的基礎。
所以,如果 Volume 不能被 Kubelet 成功地 unmount,AttachDetach Controller 不能進行 detach 操作。
Kubelet 是執行在 Node 端的 Agent,一旦 Node 重啟 / Crash / 網路故障,都會導致無法完成 unmount 操作。
AttachDetach Controller 不可能無限制的等待前置動作 unmount,所以透過引數 maxWaitForUnmountDuration(預設6分鐘)解決該問題。
超過 maxWaitForUnmountDuration,AttachDetach Controller 會啟動 force detaching。
這破壞了 attach-mount-umount-detach 流程的序列有序,一個 RW Volume 在多個節點上掛載的可能性出現了。
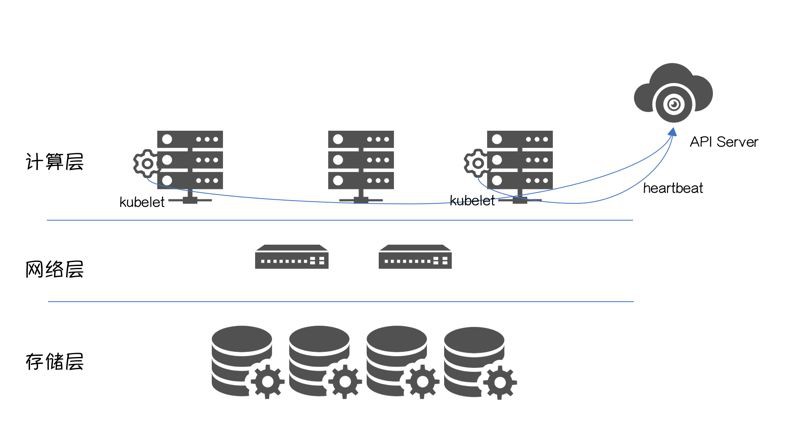
Kuberetes 叢集的正常執行,依賴 API Server 跟 Kubelet 的正常互動,可以理解為”心跳”。
-
Node 重啟 / Crash;
-
Node 跟 API Server 網路故障;
-
Node 在高負載下,Kubelet無法獲得 CPU 時間分片;
-
等等
換句話說,一旦“心跳”丟失,叢集無法判斷 Node 的真實狀態。這時執行在 Controller Plane 之上的 NodeLifecycle Controller 會把該節點標記為“ConditionUnknown”。
一旦超過閾值podEvictionTimeout,NodeLifecycle Controller會對該節點上執行的 MySQL 進行驅逐,Scheduler會將 MySQL排程到其他“available”節點。
配合上 force detaching 導致的“多點掛載”,多個實體對同一個 Volume 的“Write”導致“Data Corruption”。
Kubernetes 是極好的編排平臺,前提是我們需要深入的瞭解它。
作者介紹:熊中哲,沃趣科技產品&研發負責人。曾就職於阿裡巴巴和百度,超過10年關係型資料庫工作經驗,目前致力於將雲原生技術引入到關係型資料庫服務中。
原文連結:https://docs.google.com/document/d/1Q0xYOGpHvZ0LFXpzG98f6tZeWguBjgvBaGrSDiTkMXM/edit
本次培訓內容包括:容器原理、Docker架構及工作原理、Docker網路與儲存方案、Harbor、Kubernetes架構、元件、核心機制、外掛、核心模組、Kubernetes網路與儲存、監控、日誌、二次開發以及實踐經驗等,點選瞭解具體培訓內容。

長按二維碼向我轉賬
![]()
受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。