作者:Pranav Dar;翻譯:陳之炎;校對:丁楠雅;
本文約4200字,建議閱讀10+分鐘。
本文為你整理了多個高質量和受歡迎的資料科學培訓課程、學習文章及學習指南。
簡介
Analytics Vidhya是由Kunal發起的一個資料科學社群,上面有許多精彩的內容。2018年我們把社群的內容建設提升到了一個全新的水平,推出了多個高質量和受歡迎的培訓課程,出版了知識豐富的機器學習和深度學習文章和指南,部落格訪問量每月超過250萬次。
當拉上2018年的精彩帷幕之時,我們想和社群的讀者來分享這一年中的精彩華文。本文也是該系列文章的一部分,希望你能喜歡。其他幾篇回溯性文章見:
A Technical Overview of AI & ML (NLP, Computer Vision, Reinforcement Learning) in 2018 & Trends for 2019:
https://www.analyticsvidhya.com/blog/2018/12/key-breakthroughs-ai-ml-2018-trends-2019/
The 25 Best Data Science Projects on GitHub from 2018 that you Should Not Miss:
https://www.analyticsvidhya.com/blog/2018/12/best-data-science-machine-learning-projects-github/

在這個文集中,我總結了每一篇文章,並根據它們各自的領域進行了分類。每一篇文章還包含對內容的總結。如果你有其他你覺得特別有用的文章,請在下麵的評論框中告訴我們。
現在,我們來看看2018年在Analytics Vidhya上的那些最受歡迎程的文章吧!
本文所涵蓋的專題
一、機器學習與深度學習-終極二重奏
二、商業智慧與資料視覺化
三、資料科學方向的職業
四、自然語言處理(NLP)
五、播客
一、機器學習與深度學習-終極二重奏
1. Scratch構建推薦引擎的綜合指南(用Python語言)
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/

推薦技術已經存在了幾十年(不是幾百年)。機器學習的興起無疑加速了這些技術的進步,我們已經不再需要依靠直覺,手動地對行為進行監控——只要把資料和正確的技術有機結合起來,瞧!你便有了一個非常高效和划算的組合。
本文是你在這個主題中能找到的最全面的指南之一。它涵蓋了各種型別的推薦引擎演演算法以及在Python中建立它們的基本原理。Pulkit首先解釋了什麼是推薦引擎,它們是如何工作的。然後用Python(使用流行的MovieLens資料集)進行了一個案例研究,並利用它解釋瞭如何構建特定模型,他關註的兩項主要技術是協同過濾和矩陣因式分解。
一旦建立好了推薦引擎,該如何評估它呢?我們怎麼知道它是否按照我們的計劃運作呢?Pulkit展示了六種不同的評估技術來驗證我們的模型,從而解答了這個問題。
2. 24個可以提高你的知識和技能的終極資料科學專案(&可以自由訪問,無需付費)
https://www.analyticsvidhya.com/blog/2018/05/24-ultimate-data-science-projects-to-boost-your-knowledge-and-skills/

這是Analytics Vidhya有史以來最受歡迎的文章之一。最初釋出於2016年,我們的團隊更新了來自不同行業的最新資料集。資料集被劃分為三個職業級別-各個級別適合於職業生涯中的不同階段:
-
初級:這個級別主要使用易用的資料集,並且不需要複雜的資料科學技術
-
中級:這個級別主要使用更富挑戰性的資料集,它由中、大型資料集組成,要求具備一些高階的樣式識別技能
-
高階:這個級別最適合那些瞭解高階主題的人,如神經網路、深度學習、推薦系統等。
蛋糕上的糖霜呢?每個專案都有一個與之相關的教程!因此,無論你是想從scratch開始學習,還是被困在某個點上,或者只是想用一個分數來評估你的結果,你都可以將它標記為書簽,迅速回到該教程之中。
3. 在Scratch中用Python理解和建立標的檢測模型
https://www.analyticsvidhya.com/blog/2018/06/understanding-building-object-detection-model-python/

標的檢測在2018年真正開始了起飛,它可以為自動駕駛汽車安全導航,使之順利透過交通擁堵,在人群擁擠的地方發現暴力行為,協助運動隊分析和建立偵察報告,在製造過程中確保質量控制等等,這些只是標的檢測技術所涉及的錶面而已,它能做到的事情遠不止這些。
在本文中,Faizan Shaikh首先解釋了標的檢測是什麼,然後再深入探討解決標的檢測問題的多種不同的方法。他從非常基本的方法開始,將影象分割成不同的部分,併在每個部分上使用影象分類器。在此基礎上,對每個步驟進行了改進,最終展示瞭如何利用深度學習來構建端到端的物件檢測模型。
如果這個話題吸引到了你,並且你正在尋找一個切入點開始你的深度學習之旅,我建議你去看看“利用深度學習的計算機視覺”課程。
4. 整合學習綜合指南(附Python程式碼)
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/
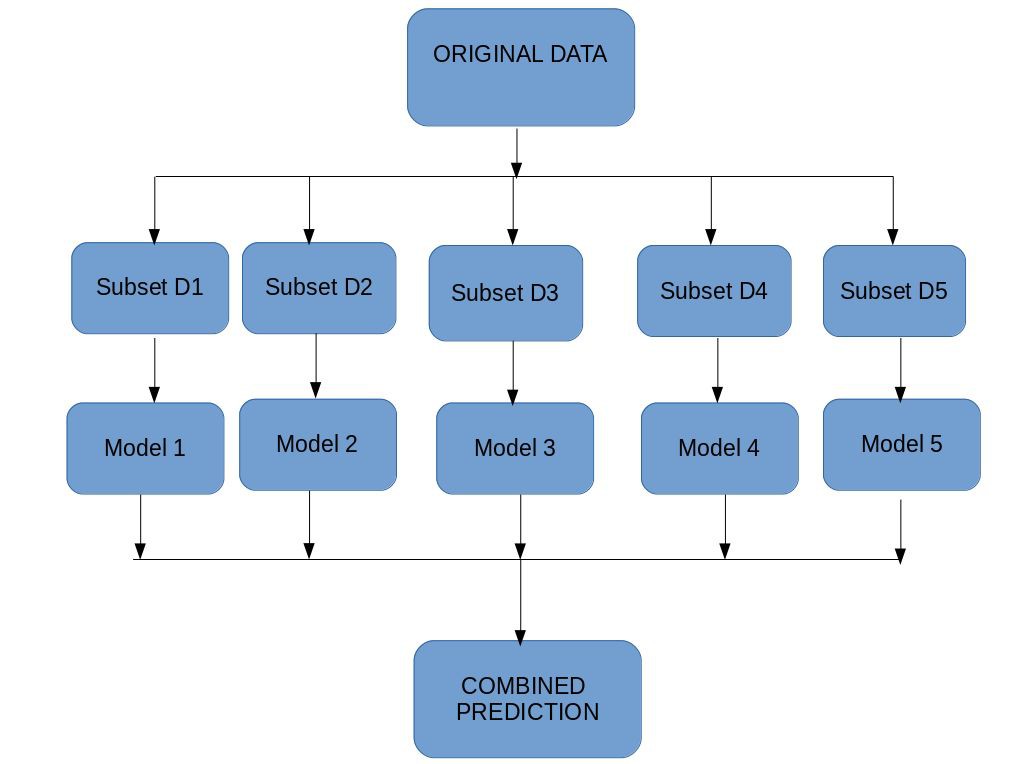
一旦我們掌握了基本的機器學習演演算法,接下來就是整合學習了。這是一個迷人的概念,併在本文中得到了非常好的解釋。有大量的例子可以幫助把複雜的主題分解成容易理解的想法。
由於本指南的綜合性,Aishwarya指導我們透過許多技術-bagging,boosting,隨機森林,LightGBM,CatBoost等等,所有的資訊寶庫都集中在一個地方!
在駭客比賽中,你經常會遇到這種方法-它是一種已經被證實的、成為領頭羊的方法。
5. 每個資料科學家必須使用的25個深度學習開放資料集
https://www.analyticsvidhya.com/blog/2018/03/comprehensive-collection-deep-learning-datasets/

學習和吸收一個概念的最好方法是什麼?學習理論是一個很好的開始,但是隻有當我們真正理解這種技術是如何工作之後,我們才能從實踐中真正學到東西。對於像深度學習這樣廣闊的領域來說,尤其如此。
訓練技能的資料集並不短缺-但是應該從哪裡開始呢?哪一組資料集最適合用來建立你的個人資料?你能得到特定領域的資料集來幫助你熟悉這一領域的工作嗎?為了能夠幫助到你,我們為你精心挑選了25個開放的深度學習資料集。
這些資料集分為三類:
-
影象處理
-
自然語言處理
-
音訊/語音處理
所以,選擇你感興趣的領域,從今天起就開始吧!
6. 12種降維技術的終極指南(附Python程式碼)
https://www.analyticsvidhya.com/blog/2018/08/dimensionality-reduction-techniques-python/

啊,維度的詛咒。能有更多的資料固然好,它有助於構成一個足夠大的訓練集。但正如大多數資料科學家所證實的那樣,擁有過多的資料最終會讓人頭疼。當面對一個擁有1000個變數的資料集時,應該做什麼?要在粒度級別上分析每個變數是不太可能的。
這就是降維技術會如此重要的原因。在不丟失(太多)資訊的情況下減少特徵的數量是我們共同努力的標的,降維是一種非常有效的方法,Pulkit在這篇文章中對此做了全面的展示。他討論了12種降維技術,以及它們在Python中的實現,其中包括主成分分析(PCA)、因子分析和t-SNE。
二、商業智慧與資料視覺化
1. 資料科學和商業智慧專業人員的Tableau中級指南
https://www.analyticsvidhya.com/blog/2018/01/tableau-for-intermediate-data-science/
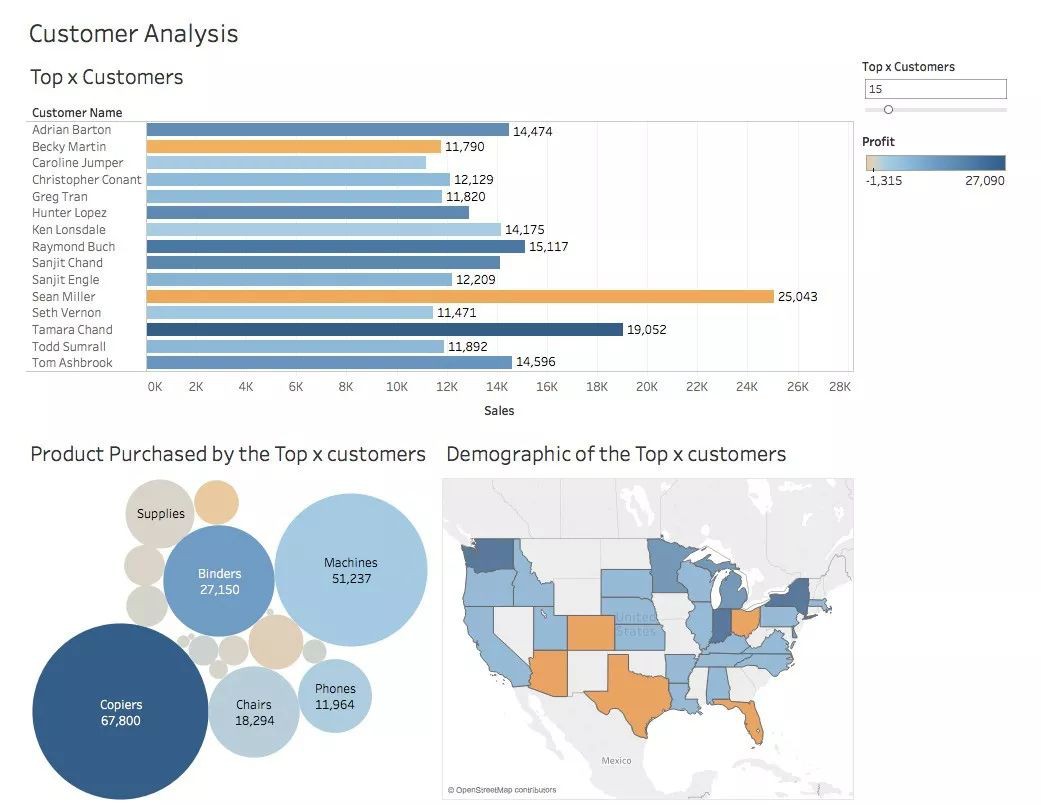
Tableau是分析手頭資料的一個非常好的工具,它的功能不僅僅侷限於生成漂亮的視覺化圖表——利用 Excel同樣也可以實現類似的任務。
Tableau的擴充套件功能確實可以將智慧放入到BI之中。
本文針對的是已經熟悉Tableau的基本功能,但是希望拓展對該工具的認識的使用者。作者介紹了連線、資料混合、執行計算、分析和理解引數等主題。文中的華美描述,將使你更加想要立即啟動Tableau!
如果需要快速複習一下Tableau,也可以先閱讀Tableau初學者指南。
2. 資料科學和商業智慧專業人員的Tableau高階進階指南
https://www.analyticsvidhya.com/blog/2018/03/tableau-for-advanced-users-easy-expertise-in-data-visualisation/
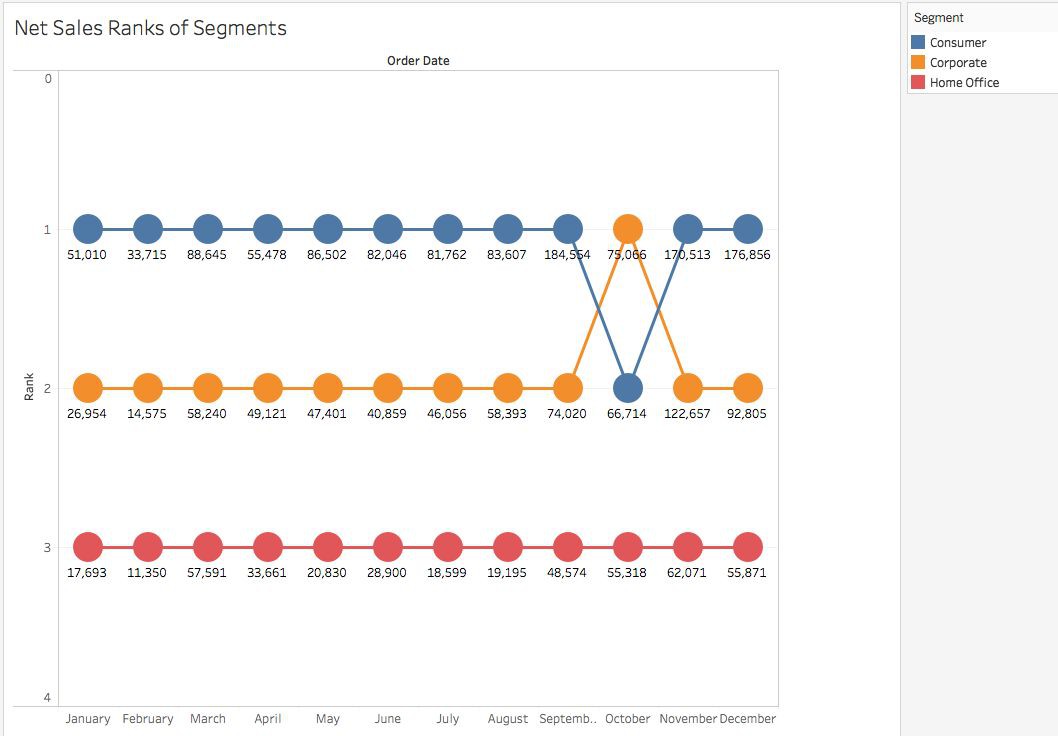
在完成Tableau中級指南之後,接下來順理成章地可以學習本指南。在這裡,我們超越了Tableau的“ShowMe”(秀我)特性,探索出更為高階的圖表。Pavleen雄辯地如是說-“這些高階圖表的壯美令人興奮和陶醉”。
這篇文章中涵蓋多種不同型別的圖表- Motion,Bump,Donut,Waterfall 和Pareto。此外,還介紹了Tableau中R程式設計的概念。當你希望將資料科學與BI結合起來時,這的確非常有用!
三、資料科學方向的職業
1. 最全面的資料科學與機器學習面試指南
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-data-science-machine-learning-interview-guide/

把這些個指南放在一起真的很有趣。面試往往是資料科學家們面臨的絆腳石,要想透過面試,需要一定的技能組合,如果你來自非技術背景(比如我),那麼破解這些面試就變得更具挑戰性了。
資料科學方向的面試通常會問什麼樣的問題?面試官要尋找的是什麼?技術和軟技能的正確結合是什麼?如果沒有做好充分的準備,這些都會讓人望而生畏,這就是撰寫這篇冗長而詳細的指南背後的想法。
這個全面的帖子涵蓋了多個主題與豐富的資源,包括資料科學和機器學習問題,特定工具的小測驗,各種案例研究,謎題,猜測,甚至是幾個引導你奔向終點線的真實的勵志小故事!
2. 業餘資料科學家所犯的13個常見錯誤及如何避免這些錯誤
https://www.analyticsvidhya.com/blog/2018/07/13-common-mistakes-aspiring-fresher-data-scientists-make-how-to-avoid-them/

有抱負的資料科學家在匆忙闖入這個領域時往往會犯很多錯誤,我同樣在這個領域也出過很多錯,在這篇文章中,記錄了13個我見過的業餘資料科學家所犯的常見錯誤。相信我,成為一名資料科學家是一條艱難的道路,而你並不是唯一犯這些錯誤的人。
從別人的錯誤中吸取教訓也可能是一種職業生涯的經歷,為此,我還提供了一份資源清單,目的是幫助你剋服這些障礙,助力你邁向資料科學希望之地的旅程。
3. 想成為一名資料工程師嗎?這是一份助你啟程的全面的資源串列。
https://www.analyticsvidhya.com/blog/2018/11/data-engineer-comprehensive-list-resources-get-started/
到目前為止,我們主要討論的是資料科學家。但是資料科學領域還有很多其他的角色,目前最熱門的是資料工程師。在所有的資料科學家的大肆宣傳中,他們往往被忽視了,但在任何DS專案中,資料工程師都是非常關鍵的一環。
要成為資料工程師,目前沒有單一的結構化路徑可以遵循,我希望這篇文章能提供一個不同的選項。這裡有大量免費資源,包括電子書、影片課程、基於文字的文章等。
瞭解了什麼是資料工程師,以及這個角色與資料科學家的不同之處之後,我們便直接深入到你需要瞭解的各個方面的知識和技能,以便使你順利成為自己希望成為的那個角色。文中,我還提到了一些在資料科學界得到了認可的資料工程證書。
四、自然語言處理
1. 資料科學家和工程師們處理文字資料的終極指南(附Python語言)
https://www.analyticsvidhya.com/blog/2018/02/the-different-methods-deal-text-data-predictive-python/

這是一本你的必讀指南。這本NLP初學者基礎指南,從一些基本概念開始,逐步構建起更先進的概念,如包詞和單詞嵌入。解決文字資料問題有多種方法,在這裡將介紹這些不同的方法。
特徵提取、預處理和高階技術-所有這些都是文字資料包含的內容。每種技術都使用Python程式碼和一個開放的資料集來展示,這樣可以做到一邊學習一邊編寫程式碼。
你還可以加入 ‘使用Python的自然語言處理’綜合課程,開啟自己的NLP職業生涯。
2. 用Python構建FAQ聊天機器人-資訊搜尋的未來
https://www.analyticsvidhya.com/blog/2018/01/faq-chatbots-the-future-of-information-searching/

2018年是聊天機器人達到頂峰的一年,這是自然語言處理(NLP)在市場上最常見的應用。不難理解的是,越來越多的人想要學習如何構建一個聊天機器人。那麼,你來對地方了!
本文探討如何提取與印度最近引入的商品和服務稅(GST)相關資訊,在Python中構建聊天機器人。一個GST-FAQ機器人!作者利用Rasa-NLU庫構建了該BOT。
3. 在Python中使用ULMFiT和Quickai庫進行文字分類(NLP)教程
https://www.analyticsvidhya.com/blog/2018/11/tutorial-text-classification-ulmfit-fastai-library/
這是一個非常重要的話題-無論對於初學者還是高階NLP使用者來說都是如此。ULMFiT框架是由Sebastian Ruder和JeremyHoward開發的,它為其他遷移學習庫鋪平了道路。這篇文章更適合那些熟悉基本NLP技術並希望拓展知識面的人。
Prateek Joshi採用通俗易懂方法,向我們介紹了遷移學習的世界:ULMFiT框架,以及如何在Python中實現這些概念。正如Sebastian Ruder所說,“NLP的ImageNet時刻已經到來”,是時候跳上這架馬車了。
五、播客(一種可訂閱下載音訊檔案的網際網路服務,多為個人自發製作)
註:播客是一種可訂閱下載音訊檔案的網際網路服務,多為個人自發製作。
1. 必聽的10個資料科學、機器學習和人工智慧的播客
https://www.analyticsvidhya.com/blog/2018/01/10-data-science-machine-learning-ai-podcasts-must-listen/
播客是一個很好的消費資訊的媒介。不是所有的人都有時間閱讀文章,播客正是填補了這一空白,使得我們更為便捷地瞭解機器學習的最新發展。這個前10名播客集在出版時就走紅了,之後便一直位居榜首。
我們今年還推出了自己的播客系列:DataHack Radio。DHR的特點是資料科學和機器學習行業的頂級先驅者和實踐者,並迎合資料科學界各層級的需要。它可以在SoundCloud,iTunes上訪問到,當然也可以在我們自己的網站上訪問到!
尾註
再一次對Analytics Vidhya社群的成員大聲表示:感謝你們一如既往的支援和對資料科學的熱愛。讓我們共同努力,使2019年成為更加美好和更為壯大的一年,並承諾保持我們對學習的無限渴望!明年見。
原文標題:
The 15 Most Popular Data Science and Machine Learning Articles on Analytics Vidhya in 2018
原文連結:
https://www.analyticsvidhya.com/blog/2018/12/most-popular-articles-analytics-vidhya-2018/
譯者簡介:陳之炎,北京交通大學通訊與控制工程專業畢業,獲得工學碩士學位,歷任長城計算機軟體與系統公司工程師,大唐微電子公司工程師,現任北京吾譯超群科技有限公司技術支援。目前從事智慧化翻譯教學系統的運營和維護,在人工智慧深度學習和自然語言處理(NLP)方面積累有一定的經驗。
