出處:https://www.cnblogs.com/wuxl360/category/874409.html
一、ZooKeeper 的實現
1.1 ZooKeeper處理單點故障
我們知道可以透過ZooKeeper對分散式系統進行Master選舉,來解決分散式系統的單點故障,如圖所示。

那麼我們繼續分析一下,ZooKeeper透過Master選舉來幫助分散式系統解決單點故障, 保證該系統中每時每刻只有一個Master為分散式系統提供服務。也就是說分散式的單點問題交給了ZooKeeper來處理,不知道大家此時有沒有發現一 個問題——”故障轉移到了ZooKeeper身上”。大家看一下圖就會發現,如果我們的ZooKeeper只用一臺機器來提供服務,若這臺機器掛了,那麼 該分散式系統就直接變成雙Master樣式了,那麼我們在分散式系統中引入ZooKeeper也就失去了意義。那麼這也就意味著,ZooKeeper在其實現的過程中要做一些可用性和恢復性的保證。這樣才能讓我們放心的以ZooKeeper為起點來構建我們的分散式系統,來達到節省成本和減少bug的目的。
1.2 ZooKeeper執行樣式
ZooKeeper服務有兩種不同的執行樣式。一種是”獨立樣式”(standalone mode),即只有一個ZooKeeper伺服器。這種樣式較為簡單,比較適合於測試環境,甚至可以在單元測試中採用,但是不能保證高可用性和恢復性。在生產環境中的ZooKeeper通常以”複製樣式”(replicated mode)執行於一個計算機叢集上,這個計算機叢集被稱為一個”集合體”(ensemble)。
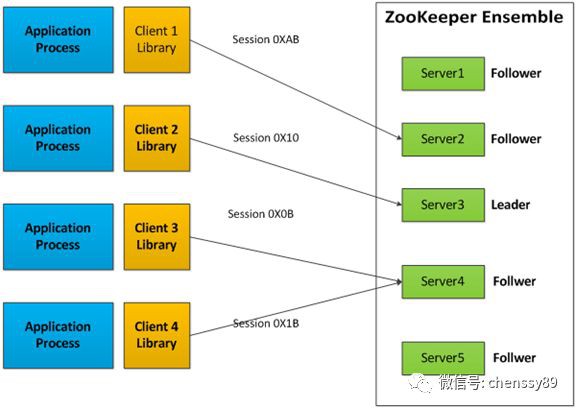
ZooKeeper透過複製來實現高可用性,只要集合體中半數以上的機器處於可用狀態,它就能夠提供服務。例如,在一個有5個節點的集合體中,每個Follower節點的資料都是Leader節點資料的副本,也就是說我們的每個節點的資料檢視都是一樣的,這樣就可以有五個節點提供ZooKeeper服務。並且集合體中任意2臺機器出現故障,都可以保證服務繼續,因為剩下的3臺機器超過了半數。
註意,6個節點的集合體也只能夠容忍2臺機器出現故障,因為如果3臺機器出現故障,剩下的3臺機器沒有超過集合體的半數。出於這個原因,一個集合體通常包含奇數臺機器。
從概念上來說,ZooKeeper它所做的就是確保對Znode樹的每一個修改都會被覆制到集合體中超過半數的 機器上。如果少於半數的機器出現故障,則最少有一臺機器會儲存最新的狀態,那麼這臺機器就是我們的Leader。其餘的副本最終也會更新到這個狀態。如果 Leader掛了,由於其他機器儲存了Leader的副本,那就可以從中選出一臺機器作為新的Leader繼續提供服務。
1.3 ZooKeeper的讀寫機制
(1) 概述
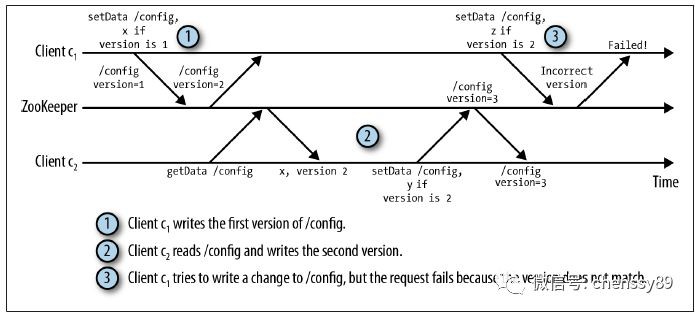
ZooKeeper的核心思想是,提供一個非鎖機制的Wait Free的用於分散式系統同步的核心服務。提供簡單的檔案建立、讀寫操作介面,其系統核心本身對檔案讀寫並不提供加鎖互斥的服務,但是提供基於版本比對的更新操作,客戶端可以基於此自己實現加鎖邏輯。如下圖1.3所示。
(2) ZK叢集服務
Zookeeper是一個由多個Server組成的叢集,該叢集有一個Leader,多個Follower。客戶端可以連線任意ZooKeeper服務節點來讀寫資料,如下圖1.4所示。

ZK叢集中每個Server,都儲存一份資料副本。Zookeeper使用簡單的同步策略,透過以下兩條基本保證來實現資料的一致性:
① 全域性序列化所有的寫操作
② 保證同一客戶端的指令被FIFO執行(以及訊息通知的FIFO)
所有的讀請求由Zk Server 本地響應,所有的更新請求將轉發給Leader,由Leader實施。
(3) ZK元件
ZK元件,如圖1.5所示。ZK元件除了請求處理器(Request Processor)以外,組成ZK服務的每一個Server會複製這些元件的副本。

ReplicatedDatabase是一個記憶體資料庫,它包含了整個Data Tree。為了恢復,更新會被記錄到磁碟,並且寫在被應用到記憶體資料庫之前,先被序列化到磁碟。
每一個ZK Server,可服務於多個Client。Client可以連線到一臺Server,來提交請求。讀請求,由每臺Server資料庫的本地副本來進行服務。改變伺服器的狀態的寫請求,需要透過一致性協議來處理。
作為一致性協議的一部分,來自Client的所有寫請求,都要被轉發到一個單獨的Server,稱作Leader。ZK叢集中其他Server 稱作Follower,負責接收Leader發來的提議訊息,並且對訊息轉發達成一致。訊息層處理leader失效,同步Followers和Leader。
ZooKeeper使用自定義的原子性訊息協議。由於訊息傳送層是原子性的,ZooKeeper能夠保證本地副本不產生分歧。當leader收到一個寫請求,它會計算出當寫操作完成後系統將會是什麼狀態,接著將之轉變為一個捕獲狀態的事務。
(4) ZK效能
ZooKeeper被應用程式廣泛使用,並有數以千計 的客戶端同時的訪問它,所以我們需要高吞吐量。我們為ZooKeeper 設計的工作負載的讀寫比例是 2:1以上。然而我們發現,ZooKeeper的高寫入吞吐量,也允許它被用於一些寫佔主導的工作負載。ZooKeeper透過每臺Server上的本地 ZK的狀態副本,來提供高讀取吞吐量。因此,容錯性和讀吞吐量是以新增到該服務的伺服器數量為尺度。寫吞吐量並不以新增到該服務的機器數量為尺度。
例如,在它的誕生地Yahoo公司,對於寫佔主導的工作負載來說,ZooKeeper的基準吞吐量已經超過每秒10000個操作;對於常規的以讀為主導的工作負載來說,吞吐量更是高出了好幾倍。
二、ZooKeeper的保證
經過上面的分析,我們知道要保證ZooKeeper服務的高可用性就需要採用分散式樣式,來冗餘資料寫多份,寫多份帶來一致性問題,一致性問題又會帶來效能問題,那麼就此陷入了無解的死迴圈。那麼在這,就涉及到了我們分散式領域的著名的CAP理論,在這就簡單的給大家介紹一下,關於CAP的詳細內容大家可以網上查閱。
2.1 CAP理論
(1) 理論概述
分散式領域中存在CAP理論:
① C:Consistency,一致性,資料一致更新,所有資料變動都是同步的。
② A:Availability,可用性,系統具有好的響應效能。
③ P:Partition tolerance,分割槽容錯性。以實際效果而言,分割槽相當於對通訊的時限要求。系統如果不能在時限內達成資料一致性,就意味著發生了分割槽的情況,必須就當前操作在C和A之間做出選擇,也就是說無論任何訊息丟失,系統都可用。
該理論已被證明:任何分散式系統只可同時滿足兩點,無法三者兼顧。 因此,將精力浪費在思考如何設計能滿足三者的完美系統上是愚鈍的,應該根據應用場景進行適當取捨。
(2) 一致性分類
一致性是指從系統外部讀取系統內部的資料時,在一定約束條件下相同,即資料變動在系統內部各節點應該是同步的。根據一致性的強弱程度不同,可以將一致性級別分為如下幾種:
① 強一致性(strong consistency)。任何時刻,任何使用者都能讀取到最近一次成功更新的資料。
② 單調一致性(monotonic consistency)。任何時刻,任何使用者一旦讀到某個資料在某次更新後的值,那麼就不會再讀到比這個值更舊的值。也就是說,可獲取的資料順序必是單調遞增的。
③ 會話一致性(session consistency)。任何使用者在某次會話中,一旦讀到某個資料在某次更新後的值,那麼在本次會話中就不會再讀到比這個值更舊的值。會話一致性是在單調一致性的基礎上進一步放鬆約束,只保證單個使用者單個會話內的單調性,在不同使用者或同一使用者不同會話間則沒有保障。
④ 最終一致性(eventual consistency)。使用者只能讀到某次更新後的值,但系統保證資料將最終達到完全一致的狀態,只是所需時間不能保障。
⑤ 弱一致性(weak consistency)。使用者無法在確定時間內讀到最新更新的值。
2.2 ZooKeeper與CAP理論
我們知道ZooKeeper也是一種分散式系統,它在一致性上有人認為它提供的是一種強一致性的服務(透過sync操作),也有人認為是單調一致性(更新時的大多說概念),還有人為是最終一致性(順序一致性),反正各有各的道理這裡就不在爭辯了。然後它在分割槽容錯性和可用性上做了一定折中,這和CAP理論是吻合的。ZooKeeper從以下幾點保證了資料的一致性
① 順序一致性
來自任意特定客戶端的更新都會按其傳送順序被提交。也就是說,如果一個客戶端將Znode z的值更新為a,在之後的操作中,它又將z的值更新為b,則沒有客戶端能夠在看到z的值是b之後再看到值a(如果沒有其他對z的更新)。
② 原子性
每個更新要麼成功,要麼失敗。這意味著如果一個更新失敗,則不會有客戶端會看到這個更新的結果。
③ 單一系統映像
一 個客戶端無論連線到哪一臺伺服器,它看到的都是同樣的系統檢視。這意味著,如果一個客戶端在同一個會話中連線到一臺新的伺服器,它所看到的系統狀態不會比 在之前伺服器上所看到的更老。當一臺伺服器出現故障,導致它的一個客戶端需要嘗試連線集合體中其他的伺服器時,所有滯後於故障伺服器的伺服器都不會接受該 連線請求,除非這些伺服器趕上故障伺服器。
④ 永續性
一個更新一旦成功,其結果就會持久存在並且不會被撤銷。這表明更新不會受到伺服器故障的影響。
三、ZooKeeper原理
3.1 原理概述
Zookeeper的核心是原子廣播機制,這個機制保證了各個server之間的同步。實現這個機制的協議叫做Zab協議。Zab協議有兩種樣式,它們分別是恢復樣式和廣播樣式。
(1) 恢復樣式
當服務啟動或者在領導者崩潰後,Zab就進入了恢復樣式,當領導者被選舉出來,且大多數server完成了和leader的狀態同步以後,恢復樣式就結束了。狀態同步保證了leader和server具有相同的系統狀態。
(2) 廣播樣式
一旦Leader已經和多數的Follower進行了狀態同步後,他就可以開始廣播訊息了,即進入廣播狀態。這時候當一個Server加入ZooKeeper服務中,它會在恢復樣式下啟動,發現Leader,並和Leader進行狀態同步。待到同步結束,它也參與訊息廣播。ZooKeeper服務一直維持在Broadcast狀態,直到Leader崩潰了或者Leader失去了大部分的Followers支援。
Broadcast樣式極其類似於分散式事務中的2pc(two-phrase commit 兩階段提交):即Leader提起一個決議,由Followers進行投票,Leader對投票結果進行計算決定是否透過該決議,如果透過執行該決議(事務),否則什麼也不做。

在廣播樣式ZooKeeper Server會接受Client請求,所有的寫請求都被轉發給領導者,再由領導者將更新廣播給跟隨者。當半數以上的跟隨者已經將修改持久化之後,領導者才會提交這個更新,然後客戶端才會收到一個更新成功的響應。這個用來達成共識的協議被設計成具有原子性,因此每個修改要麼成功要麼失敗。

3.2 Zab協議詳解
3.2.1 廣播樣式
廣播樣式類似一個簡單的兩階段提交:Leader發起一個請求,收集選票,並且最終提交,圖3.3演示了我們協議的訊息流程。我們可以簡化該兩階段提交協議,因為我們並沒有”aborts”的情況。followers要麼確認Leader的Propose,要麼丟棄該Leader的Propose。沒有”aborts”意味著,只要有指定數量的機器確認了該Propose,而不是等待所有機器的回應。

廣播協議在所有的通訊過程中使用TCP的FIFO通道,透過使用該通道,使保持有序性變得非常的容易。透過FIFO通道,訊息被有序的deliver。只要收到的訊息一被處理,其順序就會被儲存下來。
Leader會廣播已經被deliver的Proposal訊息。在發出一個Proposal訊息前,Leader會分配給Proposal一個單調遞增的唯一id,稱之為zxid。因為Zab保證了因果有序, 所以遞交的訊息也會按照zxid進行排序。廣播是把Proposal封裝到訊息當中,並新增到指向Follower的輸出佇列中,透過FIFO通道傳送到 Follower。當Follower收到一個Proposal時,會將其寫入到磁碟,可以的話進行批次寫入。一旦被寫入到磁碟媒介當 中,Follower就會傳送一個ACK給Leader。 當Leader收到了指定數量的ACK時,Leader將廣播commit訊息併在本地deliver該訊息。當收到Leader發來commit訊息 時,Follower也會遞交該訊息。
需要註意的是, 該簡化的兩階段提交自身並不能解決Leader故障,所以我們 新增恢復樣式來解決Leader故障。
3.2.2 恢復樣式
(1) 恢復階段概述
正常工作時Zab協議會一直處於廣播樣式,直到Leader故障或失去了指定數量的Followers。 為了保證進度,恢復過程中必須選舉出一個新Leader,並且最終讓所有的Server擁有一個正確的狀態。對於Leader選舉,需要一個能夠成功高幾 率的保證存活的演演算法。Leader選舉協議,不僅能夠讓一個Leader得知它是leader,並且有指定數量的Follower同意該決定。如果 Leader選舉階段發生錯誤,那麼Servers將不會取得進展。最終會發生超時,重新進行Leader選舉。在我們的實現中,Leader選舉有兩種不同的實現方式。如果有指定數量的Server正常執行,快速選舉的完成只需要幾百毫秒。
(2)恢復階段的保證
該恢復過程的複雜部分是在一個給定的時間內,提議衝突的絕對數量。最大數量衝突提議是一個可配置的選項,但是預設是1000。為了使該協議能夠即使在Leader故障的情況下也能正常運作。我們需要做出兩條具體的保證:
① 我們絕不能遺忘已經被deliver的訊息,若一條訊息在一臺機器上被deliver,那麼該訊息必須將在每臺機器上deliver。
② 我們必須丟棄已經被skip的訊息。
(3) 保證示例
第一條:
若一條訊息在一臺機器上被deliver,那麼該訊息必須將在每臺機器上deliver,即使那臺機器故障了。例如,出現了這樣一種情況:Leader發送了commit訊息,但在該commit訊息到達其他任何機器之前,Leader發生了故障。也就是說,只有Leader自己收到了commit訊息。如圖3.4中的C2。

圖3.4是”第一條保證”(deliver訊息不能忘記)的一個示例。在該圖中Server1是一個Leader,我們用L1表示,Server2和Server3為Follower。首先Leader發起了兩個Proposal,P1和P2,並將P1、P2傳送給了Server1和Server2。然後Leader對P1發起了Commit即C1,之後又發起了一個Proposal即P3,再後來又對P2發起了commit即C2,就在此時我們的Leader掛了。那麼這時候,P3和C2這兩個訊息只有Leader自己收到了。
因為Leader已經deliver了該C2訊息,client能夠在訊息中看到該事務的結果。所以該事務必須能夠在其他所有的Server中deliver,最終使得client看到了一個一致性的服務檢視。
第二條:
一個被skip的訊息,必須仍然需要被skip。例如,發生了這樣一種情況:Leader發送了propose訊息,但在該propose訊息到達其他任何機器之前,Leader發生了故障。也就是說,只有Leader自己收到了propose訊息。如圖3.4中的P3所示。
在圖3.4中沒有任何一個server能夠看到3號提議,所以在圖3.5中當server 1恢復時他需要在系統恢復時丟棄三號提議P3。

在圖3.5是”第二條保證”(skip訊息必須被丟棄)的一個示例。Server1掛掉以後,Server3被選舉為Leader,我們用L2表示。L2中還有未被deliver的訊息P1、P2,所以,L2在發出新提議P10000001、P10000002之前,L2先將P1、P2兩個訊息deliver。因此,L2先發出了兩個commit訊息C1、C2,之後L2才發出了新的提議P10000001和P10000002。
如果Server1 恢復之後再次成為了Leader,此時再次將P3在P10000001和P10000002之後deliver,那麼將違背順序性的保障。
(4) 保證的實現
如果Leader選舉協議保證了新Leader在Quorum Server中具有最高的提議編號,即Zxid最高。那麼新選舉出來的leader將具有所有已deliver的訊息。新選舉出來的Leader,在提出一個新訊息之前,首先要保證事務日誌中的所有訊息都由Quorum Follower已Propose並deliver。需要註意的是,我們可以讓新Leader成為一個用最高zxid來處理事務的server,來作為一個最佳化。這樣,作為新被選舉出來的Leader,就不必去從一組Followers中找出包含最高zxid的Followers和獲取丟失的事務。
① 第一條
所有的正確啟動的Servers,將會成為Leader或者跟隨一個Leader。Leader能夠確保它的Followers看到所有的提議,並deliver所有已經deliver的訊息。透過將新連線上的Follower所沒有見過的所有PROPOSAL進行排隊,並之後對該Proposals的COMMIT訊息進行排隊,直到最後一個COMMIT訊息。在所有這樣的訊息已經排好隊之後,Leader將會把Follower加入到廣播串列,以便今後的提議和確認。這一條是為了保證一致性,因為如果一條訊息P已經在舊Leader-Server1中deliver了,即使它剛剛將訊息P deliver之後就掛了,但是當舊Leader-Server1重啟恢復之後,我們的Client就可以從該Server中看到該訊息P deliver的事務,所以為了保證每一個client都能看到一個一致性的檢視,我們需要將該訊息在每個Server上deliver。
② 第二條
skip已經Propose,但不能deliver的訊息,處理起來也比較簡單。在我們的實現中,Zxid是由64位數字組成的,低32位用作簡單計數器。高32位是一個epoch。每當新Leader接管它時,將獲取日誌中Zxid最大的epoch,新Leader Zxid的epoch位設定為epoch+1,counter位設定0。用epoch來標記領導關係的改變,並要求Quorum Servers 透過epoch來識別該leader,避免了多個Leader用同一個Zxid釋出不同的提議。
這 個方案的一個優點就是,我們可以skip一個失敗的領導者的實體,從而加速並簡化了恢復過程。如果一臺宕機的Server重啟,並帶有未釋出的 Proposal,那麼先前的未釋出的所有提議將永不會被deliver。並且它不能夠成為一個新leader,因為任何一種可能的 Quorum Servers ,都會有一個Server其Proposal 來自與一個新epoch因此它具有一個較高的zxid。當Server以Follower的身份連線,領導者檢查自身最後提交的提議,該提議的epoch 為Follower的最新提議的epoch(也就是圖3.5中新Leader-Server2中deliver的C2提議),並告訴Follower截斷 事務日誌直到該epoch在新Leader中deliver的最後的Proposal即C2。在圖3.5中,當舊Leader-Server1連線到了新leader-Server2,leader將告訴他從事務日誌中清除3號提議P3,具體點就是清除P2之後的所有提議,因為P2之後的所有提議只有舊Leader-Server1知道,其他Server不知道。
(5) Paxos與Zab
① Paxos一致性
Paxos的一致性不能達到ZooKeeper的要 求,我們可以下麵一個例子。我們假設ZK叢集由三臺機器組成,Server1、Server2、Server3。Server1為Leader,他生成了 三條Proposal,P1、P2、P3。但是在傳送完P1之後,Server1就掛了。如下圖3.6所示。
圖 3.6 Server1為Leader

Server1掛掉之後,Server3被選舉成為Leader,因為在Server3裡只有一條Proposal—P1。所以,Server3在P1的基礎之上又發出了一條新Proposal—P2',P2'的Zxid為02。如下圖3.7所示。
圖3.7 Server2成為Leader

Server2傳送完P2'之後,它也掛了。此時Server1已經重啟恢復,並再次成為了Leader。那麼,Server1將傳送還沒有被deliver的Proposal—P2和P3。由於Follower-Server2中P2'的Zxid為02和Leader-Server1中P2的Zxid相等,所以P2會被拒絕。而P3,將會被Server2接受。如圖3.8所示。
圖3.8 Server1再次成為Leader

我們分析一下Follower-Server2中的Proposal,由於P2’將P2的內容改寫了。所以導致,Server2中的Proposal-P3無法生效,因為他的父節點並不存在。
② Zab一致性
首先來分析一下,上面的示例中為什麼不滿足ZooKeeper需求。ZooKeeper是一個樹形結構,很多操作都要先檢查才能確定能不能執行,比如,在圖3.8中Server2有三條Proposal。P1的事務是建立節點”/zk”,P2’是建立節點”/c”,而P3是建立節點 “/a/b”,由於”/a”還沒建,建立”a/b”就搞不定了。那麼,我們就能從此看出Paxos的一致性達不到ZooKeeper一致性的要求。
為了達到ZooKeeper所需要的一致性,ZooKeeper採用了Zab協議。Zab做瞭如下幾條保證,來達到ZooKeeper要求的一致性。
(a) Zab要保證同一個leader的發起的事務要按順序被apply,同時還要保證只有先前的leader的所有事務都被apply之後,新選的leader才能在發起事務。
(b) 一些已經Skip的訊息,需要仍然被Skip。
我想對於第一條保證大家都能理解,它主要是為了保證每 個Server的資料檢視的一致性。我重點解釋一下第二條,它是如何實現。為了能夠實現,Skip已經被skip的訊息。我們在Zxid中引入了 epoch,如下圖所示。每當Leader發生變換時,epoch位就加1,counter位置0。
圖 3.9 Zxid

我們繼續使用上面的例子,看一下他是如何實現Zab的 第二條保證的。我們假設ZK叢集由三臺機器組成,Server1、Server2、Server3。Server1為Leader,他生成了三條 Proposal,P1、P2、P3。但是在傳送完P1之後,Server1就掛了。如下圖3.10所示。
圖 3.10 Server1為Leader
Server1掛掉之後,Server3被選舉成為 Leader,因為在Server3裡只有一條Proposal—P1。所以,Server3在P1的基礎之上又發出了一條新Proposal—P2', 由於Leader發生了變換,epoch要加1,所以epoch由原來的0變成了1,而counter要置0。那麼,P2'的Zxid為10。如下圖3.11所示。
圖 3.11 Server3為Leader

Server2傳送完P2'之後,它也掛了。此時Server1已經重啟恢復,並再次成為了Leader。那麼,Server1將傳送還沒有被deliver的Proposal—P2和P3。由於Server2中P2'的Zxid為10,而Leader-Server1中P2和P3的Zxid分別為02和03,P2'的epoch位高於P2和P3。所以此時Leader-Server1的P2和P3都會被拒絕,那麼我們Zab的第二條保證也就實現了。如圖3.12所示。
圖 3.12 Server1再次成為Leader

