-
影象中標的的自動檢測(駕駛員輔助和自動駕駛汽車的關鍵組成部分)
-
語音識別(提升語音命令技術)
-
醫學領域中的知識發現(用於增進我們對複雜疾病的理解)
-
預測分析(用於銷售和經濟預測)
為了能讓讀者從整體上瞭解機器學習的原理,我們首先討論一個微型機器學習問題:教計算機如何區分貓和狗的照片。透過該例子,我們採用非形式化的方式描述解決機器學習問題的一般過程。
作者:傑瑞米·瓦特,雷薩·博哈尼,阿格洛斯·K.卡薩格羅斯
如需轉載請聯絡大資料(ID:hzdashuju)
01 教計算機區分貓和狗
在教孩子區分“貓”和“狗”時,幾乎所有父母都不會告訴孩子某種形式的科學定義(例如,狗屬於哺乳動物這個大類中犬科的一員,而貓屬於相同大類中貓科的一員),反倒是會給孩子看一些貓和狗的圖片,同時告訴他們哪些是貓哪些是狗,直到他們完全掌握這兩個概念為止。
我們怎麼知道孩子何時學會區分貓和狗了呢?直覺上,應該是當他們遇到新的貓和狗(或圖片)並能夠逐一正確辨識的時候。像人類一樣,計算機也可以採用類似的方式學習如何執行這類任務。在機器學習領域,這種以教計算機區分不同類別事物為標的的任務被稱為分類。
1. 收集資料
像人類一樣,計算機也必須經過從實體中學習的訓練來識別兩種動物的不同之處,這些實體稱為資料的訓練集。圖1-1展示了這樣的訓練集,其中包含不同的貓和狗的圖片。直觀而言,更大和更多樣化的訓練集可使計算機(或人)更好地完成學習任務,這是因為更廣泛的例子可以賦予學習者更多的經驗。

▲圖1-1 包含六隻貓(左圖)和六條狗(右圖)的訓練集,這個資料集用來訓練區分貓和狗圖片的機器學習模型
2. 設計特徵
考慮一下你自己是如何區分貓和狗的圖片的。為了將二者分開,你會關註什麼?你可能會用顏色、大小、耳朵或鼻子的形狀,以及(或者)這些特徵的組合來區分它們。
換句話說,你不會只是簡單地將圖片當成許多小畫素塊的集合,而是會從這些圖中找出細節或者特徵來確定你看到的是什麼。對於計算機而言也是如此。為了成功地訓練計算機完成此項任務(或者任何更一般的機器學習任務),我們需要給它提供設計合理的特徵,或者更理想情況下,讓它自己找到這樣的特徵。
因為設計高質量的特徵非常依賴於應用,所以這通常不是一個簡單的任務。比如,像 “腿的數量”這樣的特徵對於區分貓和狗是沒有用的(因為它們都有4條腿!),但是這一特徵對於辨別貓和蛇非常有用。
此外,從訓練集中提取特徵也非常具有挑戰性。例如,如果一些訓練影象非常模糊,或者是從看不到動物的頭的角度拍攝出來的,那麼我們設計的特徵或許就無法正確地提取出來。
為了簡化我們討論的問題,假設可以很容易地從訓練集的圖片中提取以下兩個特徵:
-
鼻子的大小,相對於頭的大小(從小到大);
-
耳朵的形狀(從圓到尖)。
從圖1-1所示的訓練圖片中可以看出,所有的貓都有小鼻子和尖耳朵,2而所有的狗都有大鼻子和圓耳朵。值得註意的是,每一幅圖片中當前選擇的特徵都可以只由兩個數字表示:一個數字表示相對的鼻子大小,另外一個數字表示耳朵尖或圓的程度。
因此,訓練集中的圖片都可以在二維特徵空間中表示出來,其中“鼻子大小”特徵和“耳朵形狀”特徵分別由圖1-2中的水平坐標和垂直坐標表示。因為我們設計的特徵能很好地區分訓練集中的貓和狗,所以貓圖片的特徵表示都集中在空間的一部分,而狗圖片的特徵表示則聚集在另一部分。

▲圖1-2 訓練集的特徵空間表示,其中水平和垂直坐標分別表示“鼻子大小”特徵和“耳朵形狀”特徵,訓練集中的貓和狗分別處於特徵空間的不同位置,這說明特徵選得很合適
3. 訓練模型
現在我們有了訓練資料集合適的特徵表示,那麼教計算機區分貓和狗的最後一步就可歸為一個簡單的幾何問題:讓計算機在我們精心設計的特徵空間中找到能夠區分貓和狗的一條直線或者一個線性模型[1]。
直線(在二維空間中)有斜率和截距兩個引數,這意味著要為這兩個引數找到正確的值。直線的引數必鬚根據訓練資料(的特徵表示)來確定。確定引數的過程依賴於一組名為數值最佳化的工具,此過程被稱作模型的訓練。
圖1-3展示了一個已訓練好的線性模型,它將特徵空間分成貓和狗兩個區域。一旦確定了這條線,計算機會將出現在它之上的特徵表示(左上區域)判斷為貓,將出現在它之下的特徵表示(右下區域)判斷為狗。

▲圖1-3 一個已訓練好的線性模型完美地將訓練集中的兩類動物區分開來:如果將來任何新圖片的特徵表示落入這條線之上(左上區域),該圖片就會被歸類為貓;如果落入這條線之下(右下區域),該圖片就會被歸類為狗
4. 測試模型
為了測試我們的學習器效能,我們給計算機提供一些以前沒有見過的貓和狗的圖片(一般稱為資料的測試集),然後看看它對每幅圖片中動物的識別能力。基於當前問題,我們在圖1-4中展示了由三幅新的貓和狗的圖片組成的測試集。

▲圖1-4 貓和狗圖片的測試集,註意,其中的一條狗,也就是右上方的波士頓,有小鼻子和尖耳朵,根據我們選擇的特徵表示,計算機會認為這是一隻貓
為了測試,需要從新圖片中提取我們設計的特徵(鼻子大小和耳朵形狀),並簡單檢查一下它們落入特徵空間中直線的哪一側。在這個例子中,如圖1-5所示,測試集中所有貓的圖片以及兩張狗的圖片都被正確識別出來了。
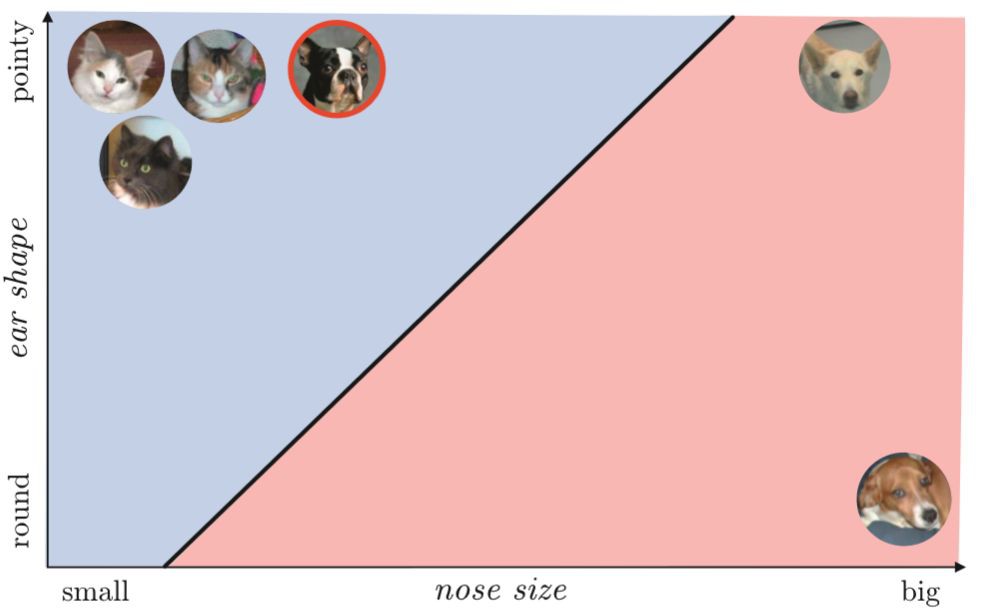
▲圖1-5 用我們已訓練好的線性模型來識別測試圖片(的特徵表示),註意,由於波士頓像訓練集中的貓一樣擁有尖耳朵和小鼻子,因此它被誤分類成一隻貓
這隻狗(波士頓)的誤分類完全是因為我們選擇的特徵,而這些特徵是根據圖1-1中的訓練集設計的。這隻狗的特徵是小鼻子和尖耳朵,恰好和訓練集中的貓相匹配,所以被誤分類。
因此,雖然剛開始鼻子大小和耳朵形狀的組合確實能區分貓和狗,但是由於訓練集太小且不夠多樣化,我們發現基於訓練集選擇出來的特徵是不能完全有效的。
為了提升學習器效能,我們必須從頭開始。
-
首先,應該收集更多的資料,組成一個龐大且多樣的訓練集。
-
其次,需要考慮設計更具有辨識性的特徵(比如,眼睛的顏色、尾巴的形狀等)來進一步幫助我們區分貓和狗。
-
最後,還要用設計的特徵訓練一個新的模型,並用同樣的方式來測試,看它與原來的模型相比是否有所改進。
02 經典機器學習問題的流程
現在我們簡要回顧一下前面描述的過程,透過該過程,我們建立了一個訓練模型,用於完成區分貓和狗的微型任務。同樣的過程基本上可用於完成所有的機器學習任務,因此很值得我們花一些時間來回顧解決典型機器學習問題所採取的步驟。
為了突出這些步驟的重要性,我們在下麵將其列舉出來。
我們把這些步驟稱為解決機器學習問題的一般流程,圖1-6簡潔地概括了該流程。

▲圖1-6 貓和狗分類問題的學習流程,相同的一般化流程基本上可用於所有的機器學習問題
-
定義問題:我們想教計算機做什麼任務?
-
收集資料:為訓練集和測試集收集資料。資料越大、越多樣越好。
-
設計特徵:什麼樣的特徵最能描述資料?
-
訓練模型:用數值最佳化技術在訓練集上調整恰當模型的引數。
-
測試模型:評估訓練模型在測試資料上的效能。如果評估結果不佳,則重新考慮所使用的特徵,並盡可能收集更多的資料。
註釋:
[1]雖然通常情況下我們可以找到一條曲線或者非線性模型來區分資料,但是在實際應用中,如果特徵設計合理,那麼線性模型是最常見的選擇。
關於作者:傑瑞米·瓦特(Jeremy Watt),獲得美國西北大學電腦科學與電氣工程專業博士學位,研究興趣是機器學習、計算機視覺和數值最佳化。
雷薩·博哈尼(Reza Borhani),獲得美國西北大學電腦科學與電氣工程專業博士學位,研究興趣是面向機器學習和計算機視覺問題的演演算法設計與分析。
阿格洛斯·K.卡薩格羅斯(Aggelos K. Katsaggelos),美國西北大學電腦科學與電氣工程系教授,Joseph Cummings名譽教授,影象與影片處理實驗室的負責人。
本文摘編自《機器學習精講:基礎、演演算法及應用》,經出版方授權釋出。
延伸閱讀《機器學習精講:基礎、演演算法及應用》
點選上圖瞭解及購買
轉載請聯絡微信:togo-maruko
推薦語:本書為瞭解機器學習提供了一種獨特的途徑。書中包含了新穎、直觀而又嚴謹的基本概念描述,它們是研究課題、製造產品、修補漏洞以及實踐不可或缺的部分。
