來源: tuohai666
http://www.cnblogs.com/tuohai666/p/8718107.html

大家好,《手把手教你寫網路爬蟲》連載開始了!在筆者的職業生涯中,幾乎沒有發現像網路爬蟲這樣的程式設計實踐,可以同時吸引程式員和門外漢的註意。本文由淺入深的把爬蟲技術和盤托出,為初學者提供一種輕鬆的入門方式。請跟隨我們一起踏上爬蟲學習的打怪升級之路吧!
介紹
什麼是爬蟲?
先看看百度百科的定義:






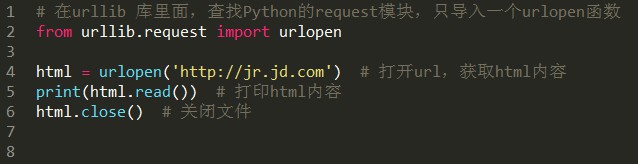
把這段程式碼儲存為get_html.py,然後執行,看看輸出了什麼:



定位到的html程式碼:

有了這些資訊,就可以用BeautifulSoup提取資料了。升級一下程式碼:

把這段程式碼儲存為get_data.py,然後執行,看看輸出了什麼:

沒錯,得到了我們想要的資料!
BeautifulSoup提供一些簡單的、Python式的函式用來處理導航、搜尋、修改分析樹等功能。它是一個工具箱,透過解析檔案為使用者提供需要抓取的資料,因為簡單,所以不需要多少程式碼就可以寫出一個完整的應用程式。怎麼樣,是不是覺得只要複製貼上就可以寫爬蟲了?簡單的爬蟲確實是可以的!
一個迷你爬蟲
我們先定一個小標的:爬取網易雲音樂播放數大於500萬的歌單。
開啟歌單的url: http://music.163.com/#/discover/playlist,然後用BeautifulSoup提取播放數3715。結果表明,我們什麼也沒提取到。難道我們開啟了一個假的網頁?


Selenium:是一個強大的網路資料採集工具,其最初是為網站自動化測試而開發的。近幾年,它還被廣泛用於獲取精確的網站快照,因為它們可以直接執行在瀏覽器上。Selenium 庫是一個在WebDriver 上呼叫的API。WebDriver 有點兒像可以載入網站的瀏覽器,但是它也可以像BeautifulSoup物件一樣用來查詢頁面元素,與頁面上的元素進行互動(傳送文字、點選等),以及執行其他動作來執行網路爬蟲。安裝方式與其他Python第三方庫一樣。
$pip install Selenium
驗證一下:
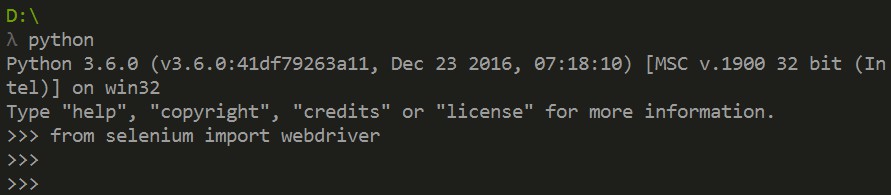
Selenium 自己不帶瀏覽器,它需要與第三方瀏覽器結合在一起使用。例如,如果你在Firefox 上執行Selenium,可以直接看到一個Firefox 視窗被開啟,進入網站,然後執行你在程式碼中設定的動作。雖然這樣可以看得更清楚,但不適用於我們的爬蟲程式,爬一頁就開啟一頁效率太低,所以我們用一個叫PhantomJS的工具代替真實的瀏覽器。
PhantomJS:是一個“無頭”(headless)瀏覽器。它會把網站載入到記憶體並執行頁面上的JavaScript,但是它不會向用戶展示網頁的圖形介面。把Selenium和PhantomJS 結合在一起,就可以執行一個非常強大的網路爬蟲了,可以處理cookie、JavaScript、essay-header,以及任何你需要做的事情。
PhantomJS並不是Python的第三方庫,不能用pip安裝。它是一個完善的瀏覽器,所以你需要去它的官方網站下載,然後把可執行檔案複製到Python安裝目錄的Scripts檔案夾,像這樣:

開始幹活!
開啟歌單的第一頁:
http://music.163.com/#/discover/playlist/?order=hot&cat;=%E5%85%A8%E9%83%A8&limit;=35&offset;=0
用Chrome的“開發者工具”F12先分析一下,很容易就看穿了一切。

播放數nb (number broadcast):29915
封面 msk (mask):有標題和url
同理,可以找到“下一頁”的url,最後一頁的url是“javascript:void(0)”。
最後,用18行程式碼即可完成我們的工作。

把這段程式碼儲存為get_data.py,然後執行。執行結束後,在程式的目錄裡生成了一個playlist.csv檔案。

看到成果後是不是很有成就感?如果你感興趣,還可以按照這個思路,找找評論數最多的單曲,再也不用擔心沒歌聽了!
今天的內容比較淺顯,希望對你有用。就先介紹到這裡,我們下期再見!
●編號408,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
