本文為Kubernetes監控系列的第四篇文章,前三篇目錄如下:
將Docker引入生產環境,既是一門科學,同時也是一門藝術。我們與WayBlazer的Kevin Kuhl和Kevin Cashman一起討論有關Docker和Kubernetes的監控、選擇正確的關註指標、決定使用Kubernetes來執行何種程式以及診斷Kubernetes故障轉移中的“多米諾效應”。
Update:在寫完這篇文章的一年後,我們與Wayblazer的Kevin Kuhl、Kevin Cashman再次進行了討論,併在他們的Kubernetes部署安全性方面增加了一些新的有洞察力的細節。
WayBlazer是世界上第一個專註於向旅遊行業提供人工智慧技術的認知推薦引擎。結合IBM Watson和專有認知計算技術,WayBlazer的AI技術對旅行者搜尋歷史提供的線索進行分析,以便為他們的旅行提供個性化的酒店推薦、見解、影象和當地文化。個性化內容與酒店推薦相結合可提高線上參與度並提高旅行者轉化率。
我們是一家AWS商店,所以可以想象我們會大量使用EC2。 同時我們還使用了許多AWS服務,這些服務易於使用,價格可取,而且管理得很好。 這些都能使我們的生活變得更輕鬆。 不久之前,我們開始使用Kubernetes,現在我們在EC2節點之上運行了十幾個Kubernetes工作節點(有時甚至更多)。 每個節點執行約15-20個容器。 另外,我們有許多Kubernetes名稱空間,如prod、test以及project-specific。
在上述環境中,我們運行了許多不同的服務。 我們的前端是JavaScript,API服務在Node.js上執行。 同時Java服務處理主要邏輯,還有一些在Python中執行的輔助應用程式。
我們使用Sysdig Monitor和AWS Cloudwatch來監控叢集。我們依靠許多Kubernetes和AWS平臺功能來保護叢集內的應用程式,但同時也開始使用Sysdig Secure來加強叢集的執行時防禦能力。
不是的。 我們的方法是首先說“它應該在Kubernetes中執行嗎?”,但在有些領域,我們的答案是否定的。 不在Kubernetes中執行的應用,要麼是功能需求不匹配,要麼是效能達不到要求。
最顯而易見的,我們的無狀態服務通常執行在Kubernetes中,這簡直是個完美的選擇。 然而有狀態的服務,例如圖形資料庫,還不是很適合。 也許使用PetSets最終能夠做到這一點,但現在不行。 最後,我們的批處理作業或者定時作業通常不會執行在Kubernetes上。 同樣,這是Kubernetes正在發展的方向,但現在不能滿足我們的需求。
從安全和訪問的角度來看,Docker,AWS,Kubernetes和其他服務都需要監控,而且從應用程式效能角度來看也是如此。 是如何做到同時監控這一切呢?
我們先談談平臺安全保護。 從一開始我們使用kubernetes TLS——這能控制對kube-ctl的訪問。 從網路角度來看,Amazon ELB是安全的,並可以保護應用程式免於暴露於外。 這對叢集免於外力攻擊非常給力。 然而,這些工具無法保證叢集內沒有發生任何不利事件。接下來當我們深入討論Sysdig Secure時會再談這個問題。
從傳統的監控角度來看,我們僅依靠AWS Cloudwatch提供的主機級監控。 這在使用Docker和Kubernetes,也就是更靜態的體系架構之前是沒有問題的。 而且,相對靜態的體系架構下,可以從基礎設施的監控資訊中獲得關於應用程式效能的更多資訊。 遷移到Kubernetes後發生了改變, 我們需要在容器和服務級別進行監控。
Kubernetes預設提供Heapster和Grafana,這是我們的第一次嘗試。 為了使用和管理這些元件,我們投入了大量的時間和努力。 鑒於我們是由兩人組成的運維團隊,這顯然不是值得我們投入大量時間的方式。 我們需要一個功能全面,健壯監控功能,並且易於開展工作的監控工具。
所以對於我們來說,這排除了自己組合元件的方式。 我們最終選擇了符合需求的商業產品。 實際上,我們仍然使用CloudWatch監控基本的AWS指標,同時使用Sysdig用於更高階別的內容。 儘管在監控底層基礎設施方面存在一些重覆,但沒有任何影響。
Kubernetes是否會影響Docker的監控? 並保護它?
是的,但Kubernetes影響很多方面,而不僅僅是監控。 如果我們回到為什麼選Kubernetes這一問題上,一方面是它能精確地描述它在做什麼,並且有它自己的語言來描述它:namespace,deployment等等。 這種“語言”統一了容器技術的使用方式。 這使得與工程師,運維人員或者任何參與到軟體開發過程的人員的交流變得容易。
為了獲取更加具體的監控資訊,到目前為止,遷移到Kubernetes最重要,最明顯的原因是對深入瞭解以Kubernetes為中心和以服務為中心的程式碼檢視。實際上,很多軟體可以透過與Docker API互動來監控基礎設施級別的Docker容器,但他們不知道容器的具體資訊。瞭解構成API服務的容器組,或者某個容器是某個Pod/ReplicaSet的一部分是非常有價值的,這使我們重新定義了對監控的需求。
對安全性有類似的思路:一個從以服務、Kubernetes為中心角度,且可以瞭解容器內部所發生事情的安全工具,比只通過映象名區分容器或容器組的工具強大得多。
好吧,既然我們正在和你一起寫這篇文章,我們都可以十分肯定地假設WayBlazer選擇了Sysdig。 為什麼?
是的。 我們現在使用了整個Sysdig容器智慧平臺——Sysdig Monitor,Sysdig Secure和開源故障排除工具。 Sysdig是一個優秀的整合基礎設施監控、Kubernetes叢集監控的工具。 基本上沒有其他工具具有如此能力,通常我們都需要這兩部分的監控才能在生產環境中執行容器。
Sysdig加強了Kubernetes的語言通用性。 它瞭解Kubernetes的基本結構。 不需要告訴Sysdig任何資訊,也不必去適應它。 一旦部署了Sysdig,就可以獲得想要的服務級別的指標資訊,命令歷史記錄以及安全策略違規記錄。
所有這些都來自一個統一的Agent。 在新增Sysdig Secure之前,Sysdig Monitor已經運行了大約18個月,我們只需新增一個額外的conf變數到Sysdig agent YAML檔案中,Kubernetes Daemonset便會負責剩下的事情。
另外重要的一點是Sysdig可以獲得容器內部更多的應用程式或以程式碼為中心的應用程式檢視。 雖然我們十分關註基礎架構指標,但同時也關註應用程式的監控資訊。 Sysdig可以做到開箱即用,甚至當Kubernetes正在對Docker容器進行擴縮容。
所有這些方面都降低了成本,也提升了我們的效率。 這意味著我們不必為了將Kubernetes元資料轉換成衡量指標而花費精力,也不必過多考慮如何使用我們的系統。
上文已經提到了平臺能提供安全性。 但是,我們仍然需要一些能夠為執行時行為提供安全性的服務。 這些行為可能發生在主機級別,應用程式級別或系統中其他任何地方。 我欣賞Sysdig Secure,因為除了擁有以服務為中心的策略來提醒或阻止行為之外,還能讓我們深入瞭解系統內發生的所有事情。 明確沒有發生的事情的確能使人安心很多。
執行時安全最讓人擔心的問題是(1)誰在登入系統,他們在做什麼;(2)是否有人正在修改系統內重要的檔案? Sysdig安全策略預設已經對登入,遠端shell連線,未經授權的連線以及其他一些行為進行了防禦和提醒,所以只需要為自定義應用程式建立一些特定的策略。 我們需要更高的優先順序和更嚴格定義的安全策略。
就上文所描述的可見性,Secure提供歷史命令檢視就是一個很好的例子。 它提供檢視系統中所執行的一切內容的能力,從微服務、到主機或容器等等,總之,一切我想看的內容。 另外,Sysdig Monitor的另一功能是可以及時檢視指標資訊,這也非常有用。 現在,如果將這兩者結合在一起會非常有用。 如果在監控頁面(顯示記憶體,響應時間資訊等)中看到不正常資訊或事件,便可以回到命令歷史記錄獲得更多資訊,如是否有人在該服務或容器上運行了新的東西?
讓我們更深入一點。 什麼是最重要的監控指標? 你一天到晚最想知道什麼?
有趣的是,我們正在討論Docker監控,但卻沒有真正地監控Docker。而是專註於監控應用程式,併在某種程度上監控Kubernetes以向我們提供有關應用程式執行的環境資訊。 我們經常使用Docker相關資訊進行故障排除,這是我們基礎架構棧中的另一個層面,並且可能經常提供幫助我們解決棘手問題的資訊。 以下是我們在應用程式級別監控的一些關鍵內容:
-
請求時間:我們密切關註前端和API的請求和響應時間。如果出現問題或變化,這些是需要首先關註的指標。 例如,一次新構建可能會導致應用程式執行失敗,或者,一次網路配置錯誤可能會對使用者產生負面影響。
-
後端查詢響應時間:這些可能直接與資料庫或Java後端相關。 當然,這是尋找潛在問題的好地方,也是改善系統的機會。 如果通常情況下,查詢執行緩慢,便可以將其傳回給團隊進行研究和修複。
-
堆使用和垃圾回收:雖然不經常使用,但我們已經使用這些資料來除錯基於JVM級資料的資料倉庫。 從應用程式級別來看,我們確實需要關註這些資源指標。
接下來是Kubernetes。 以下是我們關註的內容:
-
Pod重啟和容器計數:告訴我們是否有變化發生。
-
啟動失敗:這些是可以用來關聯其他指標的重要事件,無論是應用還是基礎架構。
-
服務請求延遲:這一點極具挑戰。 它涉及彙總來自特定服務的所有容器的延遲資訊,並以一個統一的檢視呈現。 這是在監控中使用“Kubernetes視點”的最佳例子。
-
容器平均資源利用率:我們最近在Kubernetes中添加了資源請求和限制機制,這意味著我們可以更有效地追蹤資源利用率。 相比根據主機級別CPU和記憶體資訊來監控資源利用率,我們選擇根據分配給特定容器的資源來進行監控。 這能在資源分配問題上更早的提示警告,而不是僅僅在主機利用率級別進行監控。
關鍵節點上高CPU、記憶體和磁碟使用率,我們已經有了報警機制。 你也需要這些功能。
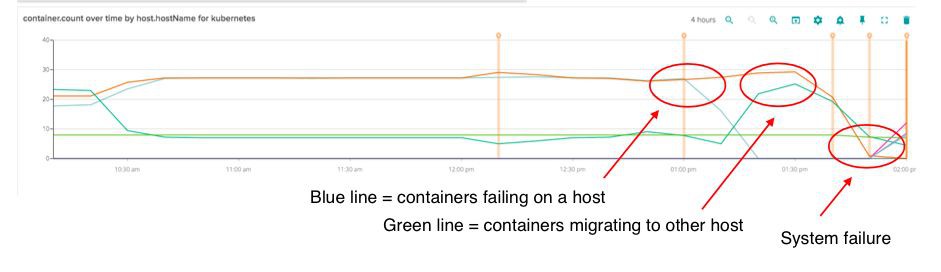
能談談你監控Kubernetes“多米諾骨牌效應”的故事嗎?
這是我們在EC2中執行Kubernetes時早就經歷的一件事。 我們的第一個警告指標是API高延遲的警報。 但此時延遲時間開始降低,雖然我們已準備好在必要時採取行動,但系統似乎穩定了。
但很快我們明白了問題的嚴重性。 我們看到了Kubernetes管理的節點縮容的警報。 我們立即查看了Sysdig,註意到藍線在下降。 這不太好,但事情還沒有結束。 Kubernetes正在幹掉相關容器,並移到另一個節點。
然後同時看到磁碟和記憶體使用率都非常高。 這是最後的警告。 然後整個系統崩潰了。
基本上這就是多米諾骨牌效應——Kubernetes對第一個節點做了failvoer,它在記憶體耗盡時清除了所有容器。 此時,某些服務上並不存在對記憶體使用的請求和限制。
問題在於叢集中的其他節點的磁碟使用已經比較高了,以至於無法為需要遷移的容器保留足夠的空間。
我們很快就能夠擴大自動伸縮組並修複一些節點,讓系統恢復正常。 但這通常來說比較痛苦,而且很不理想。在之後對此的回顧彙總,我們很有趣的發現,能夠透過Sysdig檢視到整個事情。 然後在一天內與團隊一起釋出了一個可靠的關於系統行為的報告。 同時我們整理了一份完整的操作串列,其中有在系統達到特定閾值、限制條件、擴容策略等的具體操作。 這使我們的系統更加健壯。
我們的經驗表明,採用Kubernetes和Docker會對監控方法產生很大影響。 就像Kubernetes使我們可以從一個更加service-centric的視角來對待整個基礎設定,監控策略也會以同樣的方式發生變化。
你需要在監控系統中使用基於基礎架構的檢視(監控的標準方式)和以服務為中心的檢視(監控的新方法),以在生產環境中執行容器。
確保你的監控系統能夠強化Kubernetes的語言通用性。 它必須瞭解Kubernetes開箱即用的基本結構。 而且你不應該告訴他任何資訊。 一旦部署,就可以獲得服務級別的監控資訊。
另外重要的一點你的工具應該在容器中看到更多的應用程式資訊或以程式碼為中心的應用程式檢視。 儘管我們密切關註基礎架構指標,但我們仍然專註於監控應用程式,不管Kubernetes正在啟動或停止Docker容器。
所有這些方面都降低了成本,也提升了我們的效率。 這意味著我們不必為了將Kubernetes元資料轉換成衡量指標而花費精力,也不必過多考慮如何使用我們的系統。
希望你喜歡Kubernetes監控這一系列文章! 如果你想瞭解更多,下麵我們的執行長和創始人Loris Degioanni在CloudNativeCon / KubeCon “You’re Monitoring Kubernetes Wrong”的演講。
原文連結:https://sysdig.com/blog/monitoring-docker-kubernetes-wayblazer/

本次培訓內容包括:容器介紹、容器網路、Kubernetes架構基礎介紹、安裝、設計理念、架構詳解、設計原則、常用物件、監控方案、Kubernetes高階設計和實現、微服務、實踐案例分享等,點選瞭解具體培訓內容。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。