我們在Manifold[1]始終致力於所做的一切都能得到充分利用。出於這個原因,我們不斷地考量做過的一些事情,看看它是否仍然滿足我們的標準。就在前陣子,我們決定深入研究一下我們的基礎設施設定。
在這篇文章裡,我們將一起來看看我們遷移到Kubernetes的原因以及我們自問自答的一些問題。隨後,我們將一起來看看我們為了遷移到Kubernetes不得不做出的一些妥協,以及為什麼需要做出這些妥協。我們也會一起來看看我們是如何配置叢集來實現標的。
我們剛到Manifold時,做了我們熟知的一些工作。我們使用Terraform在AWS EC2上部署容器並且透過ELB對外提供服務。我們發現自己的處境是可以花費更多時間來構建一個更成熟的平臺。剛開始實施的方案是非常簡單的,但是我們開始看到一些痛點:
在過去一年裡,Kubernetes變得更加受歡迎。憑藉團隊以往的經驗,我們堅信這項新技術的未來。出於這個原因,我們建立了我們的第一個Kubernetes整合。我們也開始思考怎樣整合可以使得Kubernetes變得更易於訪問。這也正是萌生出構建Heighliner的想法的地方。
這也引領著我們堅持另外一個生存原則:自給自足[3]。透過用Manifold來構建Manifold,我們也得以確切知道我們使用者的需求。
我們問自己的第一個問題是:“我們要在哪裡執行這個叢集?”。 AWS目前還沒有提供Kubernetes的解決方案,但是Azure和Google雲平臺都有。我們是否需要留在AWS然後管理自己的叢集,還是需要將所有內容遷移到其他雲廠商?
如果我們可以在AWS上輕鬆地建立和管理一個叢集的話,那麼自然沒有太多必要去更換廠商。我們用kops做的初步測試看上去很有希望,而且我們決定進一步推進。是時候去配置一套高可用的叢集了。
為了理解HA對於Kubernetes的意義,我們首先得明白它的通用含義。
一個高可用解決方案的核心基石是一個冗餘的,可靠的儲存層。高可用的第一原則就是保護資料。無論發生什麼意外,無論是怎樣的故障,如果你有資料,你就可以重建。如果你丟失了資料,那就完蛋了。
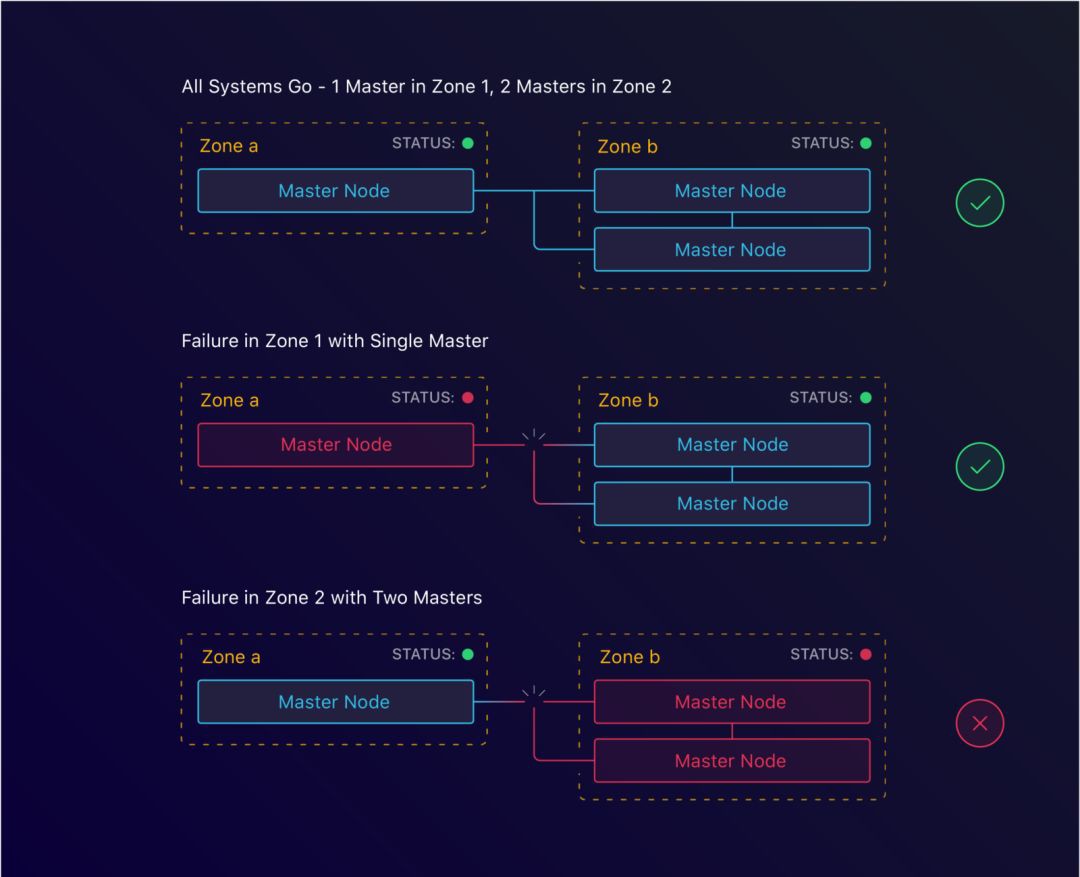
在一個Kubernetes集群裡,這個儲存層是etcd,並且執行在master實體上。etcd是一個分散式的鍵值對儲存,它遵循Raft共識演演算法來實現仲裁。實現仲裁意味著有一組伺服器贊成一組值。為了達成這一共識,它需要lower(n/2)+1的群體投贊成票。因此,我們往往需要的實體數量是至少3個。
第一個場景是一起來看看單個實體終止時會發生什麼。我們能從中恢復嗎?
透過指定我們期望的節點數量,kops會為每個實體組建立一個自動擴容組。它將確保在一個實體終止時,會創建出來一個新的實體替代它。這使得我們在失去一個實體時仍然能夠保持整個叢集的一致。
配置實體級別的故障處理使得我們可以容忍單臺機器層面的故障。但是如果整個資料中心出了問題,比如機房斷電了,會發生什麼情況呢?這時候就該地區(Region)和可用區域(AZ)的設定發揮作用了。
讓我們一起回頭看下我們的共識公式:lower(n/2)+1即至少3個實體。我們不妨把這個翻譯成區域,結果就是lower(n/2)+1的區域即至少3個可用區域。
藉助kops,這同樣很簡單就能辦到。透過指定我們master和從節點所要執行的區域,我們可以在區域層面配置HA。然而,這是我們遇到的第一個阻力。無論是出於什麼原因,總之我們剛開始在Manifold的時候,我們決定使用的地區是us-west-1。事實證明,該地區只有2個可用區域。這意味著我們必須找到另一種解決方案來容忍區域故障。
主要標的是複製同步現有的基礎設施。之前的基礎設施採用的設定沒有跨多個區域執行,因此新的配置也無需這樣做。我們相信在Kubernetes Federation的幫助下,這將更容易建立起來。
由於我們地區層面的限制,我們不得不尋找其他方式來容忍區域故障。一種選擇是在一個單獨的地區裡建立我們的叢集。
每個地區有它們自己單獨的網路。這意味著我們無法直接在其他地區裡使用這個地區的資源。針對這一點,我們研究了一下地區間的VPS對等。這將允許我們連到us-west-1地區然後訪問RDS和KMS。
在us-west-1和us-west-2之間的地區間對等
這個方案也讓我們失望了。事實證明,us-west-1地區不是最佳的地區選擇。在我們調查這一點時,us-west-1還不支援地區間VPC對等。這意味著這個解決方案也無法使用。
透過積累所有這些新的認知,是時候做出決定了。我們是選擇仍然留在AWS還是遷移到其他廠商呢?
值得一提的是,遷移到其他廠商也會帶來很多額外的開銷。我們必須對外暴露我們的資料庫,遷移我們的KMS並且重新加密我們所有的資料。
最後,我們決定堅持使用AWS並且執行容錯節點故障的解決方案。隨著Amazon EKS[5]的釋出以及即將推出的地區間對等,我們覺得這個開頭已經足夠出色了。
管理自己的叢集可能會很花時間。迄今為止,我們已經看到了一些最小化的影響,但是我們肯定會把叢集維護算在內。時間成本最高的應該是叢集的更新。
從財務角度來看,我們也做出了妥協。是的,它比傳統裝置便宜,但是它比競爭對手提供的價格都要貴。Azure和GCP提供的主節點都是免費的,這相對可以降低一些成本。
對於我們而言,kops工作很出色。它提供了一組使用者應該知道並且可以改寫的預設值。我們要做的重要事情之一是啟用etcd加密。這可以透過帶上–encrypt-etcd-storage標誌實現。
預設情況下,kops也不會啟用RBAC。RBAC是一個很棒的限制集群裡應用程式影響範疇的機制。我們強烈建議開啟這一選項,並且為其設定合適的角色。
出於安全因素考慮,我們禁用了實體的SSH登陸。這可以確保即便我們使用私有的網路拓撲來執行也不會有人能夠訪問到這些物體。
隨著叢集的啟動和執行,現在是時候開始投產了。 下一步將是配置它,以便我們可以開始將應用程式部署到裡面。
之前使用Terraform管理我們的服務意味著我們對於如何裝配上線有相當大的控制權。我們透過Terraform配置管理我們的ELB,DNS,日誌等。我們需要確保我們的Kubernetes配置上也能做到這些。
Kubernetes有Service和Ingress的概念。 透過Service,可以將Pod(通常由Deployment部署)進行分組,並把它們暴露在相同的端點下。該端點可以是內部的也可以是外部的。將一個service配置為負載均衡器時,Kubernetes將生成一個ELB。這個ELB隨後將連結到配置好的service。
這很棒,但是這樣做也限制了可以擁有的ELB數量[6]。透過使用Ingress,我們可以建立一個單個的ELB然後在叢集內路由流量。社群裡有幾個可選的Ingress,但是我們使用預設的Nginx Ingress。
如今我們已經可以將流量路由到一個service,那麼是時候將他們暴露到一個域名下提供服務了。為了達成這一點,我們採用了External DNS專案。這是一個很好的保持配置好的域名貼近應用的方式。
為了對外暴露我們的服務,還需要考慮的最後一步便是確保我們可以在SSL下提供流量。事實證明這件事很容易辦到,而且已經有現成可用的解決方案。我們選擇了cert-manager,它可以和我們的Nginx Ingress整合。
服務配置對我們來說是輕而易舉。我們已經開始在和Terraform整合後的Manifold之上構建Manifold自己。正因為如此,我們需要的所有證書都已經配置好了。
我們精心設計了Kubernetes整合和Terraform的整合。我們保持底層的語意相同,這意味著遷移證書不再是件難事。
我們還添加了自定義secret型別的選項。這使得我們能夠配置Docker認證的密碼。在從私有映象中心裡拉取Docker映象時,使用者需要知道這個密碼。
執行分散式系統最重要的事情之一就是需要知道內部發生了什麼。為此,使用者需要配置集中式的日誌和監控指標。我們在之前的傳統平臺上有這個功能,因此在我們的新平臺中肯定也需要有這個功能。
關於日誌,我們擴充套件了我們的dogfooding並且配置了LogDNA整合來收集日誌。 LogDNA本身提供了一個DaemonSet配置。這使得使用者可以將叢集中的日誌傳送到他們的平臺。
關於監控指標,我們依賴Datadog,迄今為止我們和它合作的很好。同LogDNA一樣,Datadog也提供了一個DaemonSet配置。 他們甚至還有一篇很棒的關於如何配置的部落格文章[7]!
在配置好叢集然後部署了我們的應用程式之後,是時候該遷移了。為了確保零停機時間,我們必須分幾個階段來完成。
第一個階段是在單獨的域上執行叢集。透過連通兩個系統,我們可以在不打斷任何人工作的情況下進行測試。這幫助我們找到並解決了一些早期遇到的問題。
在接下來的階段,我們會將一些流量路由到Kubernetes叢集。 為此,我們配置了一個輪詢。這是一個檢視接入真實流量後的使用者叢集行為的好辦法。大約一週後,我們已經有足夠的信心進入到下一階段。
在舊基礎設施和Kubernetes叢集之間配置的DNS round-robin
第三個階段涉及的便是刪除舊的DNS記錄。在刪除對應的Terraform配置後,我們所有的流量都將流向Kubernetes!
由於DNS快取的原因,我們決定讓這些舊版本繼續執行幾天。這樣一來,快取了DNS記錄的使用者就不會遇到錯誤。這也讓我們有能力在出現問題的情況下回滾。

現在我們已經完成了遷移,我們可以回過頭來反思一些東西。我們的團隊——和公司——都說這次遷移很成功。我們將部署時間從大約15分鐘縮短到大約1.5分鐘,並以此降低了運營成本。
我們還沒完成我們的持續交付流水線,這方面我們仍然在努力。我們已經開始了Heighliner[8]的開發工作,它將以能夠幫到我們放到第一位,不過也希望能夠幫到其他人。
我們遇到了一個重大挫折:沒有3個可用區域供我們使用。這阻礙我們跨區域執行的高可用性。決定啟動和執行也是一次妥協,我們將儘快完全解決這一問題。
哦,還有一件事。太多的YAML了。這也是Heighliner將能夠幫到我們的地方。
-
https://www.manifold.co/
-
https://containerjournal.com/2017/03/15/dockers-big-differentiator-vms-density/
-
https://www.urbandictionary.com/define.php?term=dogfooding%20%28to%20dogfood%29
-
https://kubernetes.io/docs/admin/high-availability/building/
-
https://aws.amazon.com/eks/
-
https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-limits.html
-
https://www.datadoghq.com/blog/monitor-kubernetes-docker/
-
https://heighliner.com/
原文連結:https://blog.manifold.co/migrating-to-kubernetes-with-zero-downtime-the-why-and-how-d64ba9a92619
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。