來自:程式員小灰(微訊號:chengxuyuanxiaohui)


————— 第二天 —————









————————————







Zookeeper的資料模型
Zookeeper的資料模型是什麼樣子呢?它很像資料結構當中的樹,也很像檔案系統的目錄。

樹是由節點所組成,Zookeeper的資料儲存也同樣是基於節點,這種節點叫做Znode。
但是,不同於樹的節點,Znode的取用方式是路徑取用,類似於檔案路徑:
/ 動物 / 倉鼠
/ 植物 / 荷花
這樣的層級結構,讓每一個Znode節點擁有唯一的路徑,就像名稱空間一樣對不同資訊作出清晰的隔離。



data:
Znode儲存的資料資訊。
ACL:
記錄Znode的訪問許可權,即哪些人或哪些IP可以訪問本節點。
stat:
包含Znode的各種元資料,比如事務ID、版本號、時間戳、大小等等。
child:
當前節點的子節點取用,類似於二叉樹的左孩子右孩子。
這裡需要註意一點,Zookeeper是為讀多寫少的場景所設計。Znode並不是用來儲存大規模業務資料,而是用於儲存少量的狀態和配置資訊,每個節點的資料最大不能超過1MB。


Zookeeper的基本操作和事件通知
Zookeeper包含了哪些基本操作呢?這裡列舉出比較常用的API:
create
建立節點
delete
刪除節點
exists
判斷節點是否存在
getData
獲得一個節點的資料
setData
設定一個節點的資料
getChildren
獲取節點下的所有子節點
這其中,exists,getData,getChildren屬於讀操作。Zookeeper客戶端在請求讀操作的時候,可以選擇是否設定Watch。
Watch是什麼意思呢?
我們可以理解成是註冊在特定Znode上的觸發器。當這個Znode發生改變,也就是呼叫了create,delete,setData方法的時候,將會觸發Znode上註冊的對應事件,請求Watch的客戶端會接收到非同步通知。
具體互動過程如下:
1.客戶端呼叫getData方法,watch引數是true。服務端接到請求,傳回節點資料,並且在對應的雜湊表裡插入被Watch的Znode路徑,以及Watcher串列。
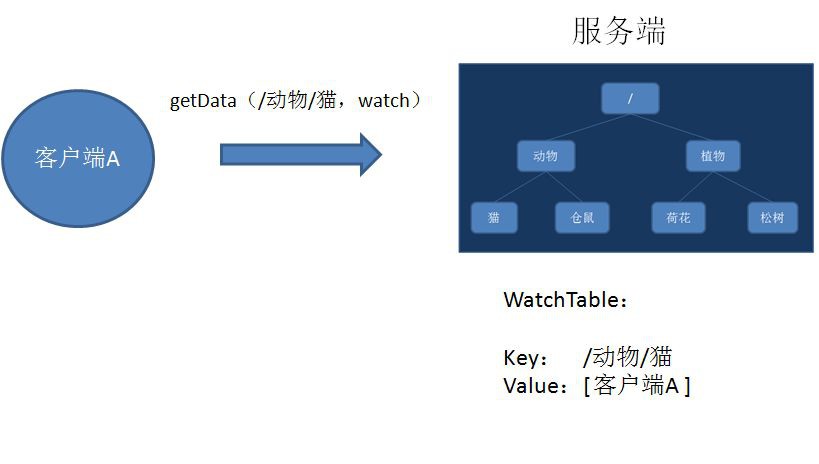
2.當被Watch的Znode已刪除,服務端會查詢雜湊表,找到該Znode對應的所有Watcher,非同步通知客戶端,並且刪除雜湊表中對應的Key-Value。

Zookeeper的一致性


Zookeeper的叢集長成什麼樣呢?就像下圖這樣:

Zookeeper Service叢集是一主多從結構。
在更新資料時,首先更新到主節點(這裡的節點是指伺服器,不是Znode),再同步到從節點。
在讀取資料時,直接讀取任意從節點。
為了保證主從節點的資料一致性,Zookeeper採用了ZAB協議,這種協議非常類似於一致性演演算法Paxos和Raft。


在學習ZAB之前,我們需要首先瞭解ZAB協議所定義的三種節點狀態:
Looking :選舉狀態。
Following :Follower節點(從節點)所處的狀態。
Leading :Leader節點(主節點)所處狀態。
我們還需要知道最大ZXID的概念:
最大ZXID也就是節點本地的最新事務編號,包含epoch和計數兩部分。epoch是紀元的意思,相當於Raft演演算法選主時候的term。
假如Zookeeper當前的主節點掛掉了,叢集會進行崩潰恢復。ZAB的崩潰恢復分成三個階段:
1.Leader election
選舉階段,此時叢集中的節點處於Looking狀態。它們會各自向其他節點發起投票,投票當中包含自己的伺服器ID和最新事務ID(ZXID)。
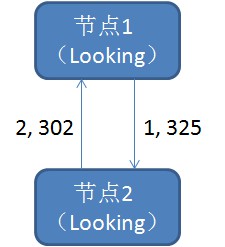
接下來,節點會用自身的ZXID和從其他節點接收到的ZXID做比較,如果發現別人家的ZXID比自己大,也就是資料比自己新,那麼就重新發起投票,投票給目前已知最大的ZXID所屬節點。

每次投票後,伺服器都會統計投票數量,判斷是否有某個節點得到半數以上的投票。如果存在這樣的節點,該節點將會成為準Leader,狀態變為Leading。其他節點的狀態變為Following。

這就相當於,一群武林高手經過激烈的競爭,選出了武林盟主。
2.Discovery
發現階段,用於在從節點中發現最新的ZXID和事務日誌。或許有人會問:既然Leader被選為主節點,已經是集群裡資料最新的了,為什麼還要從節點中尋找最新事務呢?
這是為了防止某些意外情況,比如因網路原因在上一階段產生多個Leader的情況。
所以這一階段,Leader集思廣益,接收所有Follower發來各自的最新epoch值。Leader從中選出最大的epoch,基於此值加1,生成新的epoch分發給各個Follower。
各個Follower收到全新的epoch後,傳回ACK給Leader,帶上各自最大的ZXID和歷史事務日誌。Leader選出最大的ZXID,並更新自身歷史日誌。
3.Synchronization
同步階段,把Leader剛才收集得到的最新曆史事務日誌,同步給叢集中所有的Follower。只有當半數Follower同步成功,這個準Leader才能成為正式的Leader。
自此,故障恢復正式完成。


什麼是Broadcast呢?簡單來說,就是Zookeeper常規情況下更新資料的時候,由Leader廣播到所有的Follower。其過程如下:
1.客戶端發出寫入資料請求給任意Follower。
2.Follower把寫入資料請求轉發給Leader。
3.Leader採用二階段提交方式,先傳送Propose廣播給Follower。
4.Follower接到Propose訊息,寫入日誌成功後,傳回ACK訊息給Leader。
5.Leader接到半數以上ACK訊息,傳回成功給客戶端,並且廣播Commit請求給Follower。

Zab協議既不是強一致性,也不是弱一致性,而是處於兩者之間的單調一致性。它依靠事務ID和版本號,保證了資料的更新和讀取是有序的。
Zookeeper的應用


1.分散式鎖
這是雅虎研究員設計Zookeeper的初衷。利用Zookeeper的臨時順序節點,可以輕鬆實現分散式鎖。
2.服務註冊和發現
利用Znode和Watcher,可以實現分散式服務的註冊和發現。最著名的應用就是阿裡的分散式RPC框架Dubbo。
3.共享配置和狀態資訊
Redis的分散式解決方案Codis,就利用了Zookeeper來存放資料路由表和 codis-proxy 節點的元資訊。同時 codis-config 發起的命令都會透過 ZooKeeper 同步到各個存活的 codis-proxy。
此外,Kafka、HBase、Hadoop,也都依靠Zookeeper同步節點資訊,實現高可用。

幾點補充:
1.ZAB協議相對比較複雜,小灰對此也只是淺層次的理解,有興趣的小夥伴們可以去官方社群進行進一步學習。
2.本漫畫純屬娛樂,還請大家儘量珍惜當下的工作,切勿模仿小灰的行為哦。
●編號689,輸入編號直達本文
●輸入m獲取文章目錄

Python程式設計
更多推薦:《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
