(點選上方公眾號,可快速關註)
來源:CHEN
www.jianshu.com/p/d7665192aaaf
說起MySQL的查詢最佳化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用NULL欄位、合理建立索引、為欄位選擇合適的資料型別….. 你是否真的理解這些最佳化技巧?是否理解其背後的工作原理?在實際場景下效能真有提升嗎?我想未必。因而理解這些最佳化建議背後的原理就尤為重要,希望本文能讓你重新審視這些最佳化建議,併在實際業務場景下合理的運用。
MySQL邏輯架構
如果能在頭腦中構建一幅MySQL各元件之間如何協同工作的架構圖,有助於深入理解MySQL伺服器。下圖展示了MySQL的邏輯架構圖。

MySQL邏輯架構,來自:高效能MySQL
MySQL邏輯架構整體分為三層,最上層為客戶端層,並非MySQL所獨有,諸如:連線處理、授權認證、安全等功能均在這一層處理。
MySQL大多數核心服務均在中間這一層,包括查詢解析、分析、最佳化、快取、內建函式(比如:時間、數學、加密等函式)。所有的跨儲存引擎的功能也在這一層實現:儲存過程、觸發器、檢視等。
最下層為儲存引擎,其負責MySQL中的資料儲存和提取。和Linux下的檔案系統類似,每種儲存引擎都有其優勢和劣勢。中間的服務層透過API與儲存引擎通訊,這些API介面遮蔽了不同儲存引擎間的差異。
MySQL查詢過程
我們總是希望MySQL能夠獲得更高的查詢效能,最好的辦法是弄清楚MySQL是如何最佳化和執行查詢的。一旦理解了這一點,就會發現:很多的查詢最佳化工作實際上就是遵循一些原則讓MySQL的最佳化器能夠按照預想的合理方式執行而已。
當向MySQL傳送一個請求的時候,MySQL到底做了些什麼呢?

MySQL查詢過程
客戶端/服務端通訊協議
MySQL客戶端/服務端通訊協議是“半雙工”的:在任一時刻,要麼是伺服器向客戶端傳送資料,要麼是客戶端向伺服器傳送資料,這兩個動作不能同時發生。一旦一端開始傳送訊息,另一端要接收完整個訊息才能響應它,所以我們無法也無須將一個訊息切成小塊獨立傳送,也沒有辦法進行流量控制。
客戶端用一個單獨的資料包將查詢請求傳送給伺服器,所以當查詢陳述句很長的時候,需要設定max_allowed_packet引數。但是需要註意的是,如果查詢實在是太大,服務端會拒絕接收更多資料並丟擲異常。
與之相反的是,伺服器響應給使用者的資料通常會很多,由多個資料包組成。但是當伺服器響應客戶端請求時,客戶端必須完整的接收整個傳回結果,而不能簡單的只取前面幾條結果,然後讓伺服器停止傳送。因而在實際開發中,儘量保持查詢簡單且只傳回必需的資料,減小通訊間資料包的大小和數量是一個非常好的習慣,這也是查詢中儘量避免使用SELECT *以及加上LIMIT限制的原因之一。
查詢快取
在解析一個查詢陳述句前,如果查詢快取是開啟的,那麼MySQL會檢查這個查詢陳述句是否命中查詢快取中的資料。如果當前查詢恰好命中查詢快取,在檢查一次使用者許可權後直接傳回快取中的結果。這種情況下,查詢不會被解析,也不會生成執行計劃,更不會執行。
MySQL將快取存放在一個取用表(不要理解成table,可以認為是類似於HashMap的資料結構),透過一個雜湊值索引,這個雜湊值透過查詢本身、當前要查詢的資料庫、客戶端協議版本號等一些可能影響結果的資訊計算得來。所以兩個查詢在任何字元上的不同(例如:空格、註釋),都會導致快取不會命中。
如果查詢中包含任何使用者自定義函式、儲存函式、使用者變數、臨時表、mysql庫中的系統表,其查詢結果
都不會被快取。比如函式NOW()或者CURRENT_DATE()會因為不同的查詢時間,傳回不同的查詢結果,再比如包含CURRENT_USER或者CONNECION_ID()的查詢陳述句會因為不同的使用者而傳回不同的結果,將這樣的查詢結果快取起來沒有任何的意義。
既然是快取,就會失效,那查詢快取何時失效呢?MySQL的查詢快取系統會跟蹤查詢中涉及的每個表,如果這些表(資料或結構)發生變化,那麼和這張表相關的所有快取資料都將失效。正因為如此,在任何的寫操作時,MySQL必須將對應表的所有快取都設定為失效。如果查詢快取非常大或者碎片很多,這個操作就可能帶來很大的系統消耗,甚至導致系統僵死一會兒。而且查詢快取對系統的額外消耗也不僅僅在寫操作,讀操作也不例外:
-
任何的查詢陳述句在開始之前都必須經過檢查,即使這條SQL陳述句永遠不會命中快取
-
如果查詢結果可以被快取,那麼執行完成後,會將結果存入快取,也會帶來額外的系統消耗
基於此,我們要知道並不是什麼情況下查詢快取都會提高系統效能,快取和失效都會帶來額外消耗,只有當快取帶來的資源節約大於其本身消耗的資源時,才會給系統帶來效能提升。但要如何評估開啟快取是否能夠帶來效能提升是一件非常困難的事情,也不在本文討論的範疇內。如果系統確實存在一些效能問題,可以嘗試開啟查詢快取,併在資料庫設計上做一些最佳化,比如:
-
用多個小表代替一個大表,註意不要過度設計
-
批次插入代替迴圈單條插入
-
合理控制快取空間大小,一般來說其大小設定為幾十兆比較合適
-
可以透過SQL_CACHE和SQL_NO_CACHE來控制某個查詢陳述句是否需要進行快取
最後的忠告是不要輕易開啟查詢快取,特別是寫密集型應用。如果你實在是忍不住,可以將query_cache_type設定為DEMAND,這時只有加入SQL_CACHE的查詢才會走快取,其他查詢則不會,這樣可以非常自由地控制哪些查詢需要被快取。
當然查詢快取系統本身是非常複雜的,這裡討論的也只是很小的一部分,其他更深入的話題,比如:快取是如何使用記憶體的?如何控制記憶體的碎片化?事務對查詢快取有何影響等等,讀者可以自行閱讀相關資料,這裡權當拋磚引玉吧。
語法解析和預處理
MySQL透過關鍵字將SQL陳述句進行解析,並生成一顆對應的解析樹。這個過程解析器主要透過語法規則來驗證和解析。比如SQL中是否使用了錯誤的關鍵字或者關鍵字的順序是否正確等等。預處理則會根據MySQL規則進一步檢查解析樹是否合法。比如檢查要查詢的資料表和資料列是否存在等等。
查詢最佳化
經過前面的步驟生成的語法樹被認為是合法的了,並且由最佳化器將其轉化成查詢計劃。多數情況下,一條查詢可以有很多種執行方式,最後都傳回相應的結果。最佳化器的作用就是找到這其中最好的執行計劃。
MySQL使用基於成本的最佳化器,它嘗試預測一個查詢使用某種執行計劃時的成本,並選擇其中成本最小的一個。在MySQL可以透過查詢當前會話的last_query_cost的值來得到其計算當前查詢的成本。
mysql> select * from t_message limit 10;
…省略結果集
mysql> show status like ‘last_query_cost’;
+—————–+————-+
| Variable_name | Value |
+—————–+————-+
| Last_query_cost | 6391.799000 |
+—————–+————-+
示例中的結果表示最佳化器認為大概需要做6391個資料頁的隨機查詢才能完成上面的查詢。這個結果是根據一些列的統計資訊計算得來的,這些統計資訊包括:每張表或者索引的頁面個數、索引的基數、索引和資料行的長度、索引的分佈情況等等。
有非常多的原因會導致MySQL選擇錯誤的執行計劃,比如統計資訊不準確、不會考慮不受其控制的操作成本(使用者自定義函式、儲存過程)、MySQL認為的最優跟我們想的不一樣(我們希望執行時間盡可能短,但MySQL值選擇它認為成本小的,但成本小並不意味著執行時間短)等等。
MySQL的查詢最佳化器是一個非常複雜的部件,它使用了非常多的最佳化策略來生成一個最優的執行計劃:
-
重新定義表的關聯順序(多張表關聯查詢時,並不一定按照SQL中指定的順序進行,但有一些技巧可以指定關聯順序)
-
最佳化MIN()和MAX()函式(找某列的最小值,如果該列有索引,只需要查詢B+Tree索引最左端,反之則可以找到最大值,具體原理見下文)
-
提前終止查詢(比如:使用Limit時,查詢到滿足數量的結果集後會立即終止查詢)
-
最佳化排序(在老版本MySQL會使用兩次傳輸排序,即先讀取行指標和需要排序的欄位在記憶體中對其排序,然後再根據排序結果去讀取資料行,而新版本採用的是單次傳輸排序,也就是一次讀取所有的資料行,然後根據給定的列排序。對於I/O密集型應用,效率會高很多)
隨著MySQL的不斷發展,最佳化器使用的最佳化策略也在不斷的進化,這裡僅僅介紹幾個非常常用且容易理解的最佳化策略,其他的最佳化策略,大家自行查閱吧。
查詢執行引擎
在完成解析和最佳化階段以後,MySQL會生成對應的執行計劃,查詢執行引擎根據執行計劃給出的指令逐步執行得出結果。整個執行過程的大部分操作均是透過呼叫儲存引擎實現的介面來完成,這些介面被稱為handler API。查詢過程中的每一張表由一個handler實體表示。實際上,MySQL在查詢最佳化階段就為每一張表建立了一個handler實體,最佳化器可以根據這些實體的介面來獲取表的相關資訊,包括表的所有列名、索引統計資訊等。儲存引擎介面提供了非常豐富的功能,但其底層僅有幾十個介面,這些介面像搭積木一樣完成了一次查詢的大部分操作。
傳回結果給客戶端
查詢執行的最後一個階段就是將結果傳回給客戶端。即使查詢不到資料,MySQL仍然會傳回這個查詢的相關資訊,比如該查詢影響到的行數以及執行時間等等。
如果查詢快取被開啟且這個查詢可以被快取,MySQL也會將結果存放到快取中。
結果集傳回客戶端是一個增量且逐步傳回的過程。有可能MySQL在生成第一條結果時,就開始向客戶端逐步傳回結果集了。這樣服務端就無須儲存太多結果而消耗過多記憶體,也可以讓客戶端第一時間獲得傳回結果。需要註意的是,結果集中的每一行都會以一個滿足①中所描述的通訊協議的資料包傳送,再透過TCP協議進行傳輸,在傳輸過程中,可能對MySQL的資料包進行快取然後批次傳送。
回頭總結一下MySQL整個查詢執行過程,總的來說分為6個步驟:
-
客戶端向MySQL伺服器傳送一條查詢請求
-
伺服器首先檢查查詢快取,如果命中快取,則立刻傳回儲存在快取中的結果。否則進入下一階段
-
伺服器進行SQL解析、預處理、再由最佳化器生成對應的執行計劃
-
MySQL根據執行計劃,呼叫儲存引擎的API來執行查詢
-
將結果傳回給客戶端,同時快取查詢結果
效能最佳化建議
看了這麼多,你可能會期待給出一些最佳化手段,是的,下麵會從3個不同方面給出一些最佳化建議。但請等等,還有一句忠告要先送給你:不要聽信你看到的關於最佳化的“絕對真理”,包括本文所討論的內容,而應該是在實際的業務場景下透過測試來驗證你關於執行計劃以及響應時間的假設。
Scheme設計與資料型別最佳化
選擇資料型別只要遵循小而簡單的原則就好,越小的資料型別通常會更快,佔用更少的磁碟、記憶體,處理時需要的CPU週期也更少。越簡單的資料型別在計算時需要更少的CPU週期,比如,整型就比字元操作代價低,因而會使用整型來儲存ip地址,使用DATETIME來儲存時間,而不是使用字串。
這裡總結幾個可能容易理解錯誤的技巧:
-
通常來說把可為NULL的列改為NOT NULL不會對效能提升有多少幫助,只是如果計劃在列上建立索引,就應該將該列設定為NOT NULL。
-
對整數型別指定寬度,比如INT(11),沒有任何卵用。INT使用32位(4個位元組)儲存空間,那麼它的表示範圍已經確定,所以INT(1)和INT(20)對於儲存和計算是相同的。
-
UNSIGNED表示不允許負值,大致可以使正數的上限提高一倍。比如TINYINT儲存範圍是-128 ~ 127,而UNSIGNED TINYINT儲存的範圍卻是0 – 255。
-
通常來講,沒有太大的必要使用DECIMAL資料型別。即使是在需要儲存財務資料時,仍然可以使用BIGINT。比如需要精確到萬分之一,那麼可以將資料乘以一百萬然後使用BIGINT儲存。這樣可以避免浮點數計算不準確和DECIMAL精確計算代價高的問題。
-
TIMESTAMP使用4個位元組儲存空間,DATETIME使用8個位元組儲存空間。因而,TIMESTAMP只能表示1970 – 2038年,比DATETIME表示的範圍小得多,而且TIMESTAMP的值因時區不同而不同。
-
大多數情況下沒有使用列舉型別的必要,其中一個缺點是列舉的字串串列是固定的,新增和刪除字串(列舉選項)必須使用ALTER TABLE(如果只只是在串列末尾追加元素,不需要重建表)。
-
schema的列不要太多。原因是儲存引擎的API工作時需要在伺服器層和儲存引擎層之間透過行緩衝格式複製資料,然後在伺服器層將緩衝內容解碼成各個列,這個轉換過程的代價是非常高的。如果列太多而實際使用的列又很少的話,有可能會導致CPU佔用過高。
-
大表ALTER TABLE非常耗時,MySQL執行大部分修改表結果操作的方法是用新的結構建立一個張空表,從舊表中查出所有的資料插入新表,然後再刪除舊表。尤其當記憶體不足而表又很大,而且還有很大索引的情況下,耗時更久。當然有一些奇技淫巧可以解決這個問題,有興趣可自行查閱。
建立高效能索引
索引是提高MySQL查詢效能的一個重要途徑,但過多的索引可能會導致過高的磁碟使用率以及過高的記憶體佔用,從而影響應用程式的整體效能。應當儘量避免事後才想起新增索引,因為事後可能需要監控大量的SQL才能定位到問題所在,而且新增索引的時間肯定是遠大於初始新增索引所需要的時間,可見索引的新增也是非常有技術含量的。
接下來將向你展示一系列建立高效能索引的策略,以及每條策略其背後的工作原理。但在此之前,先瞭解與索引相關的一些演演算法和資料結構,將有助於更好的理解後文的內容。
索引相關的資料結構和演演算法
通常我們所說的索引是指B-Tree索引,它是目前關係型資料庫中查詢資料最為常用和有效的索引,大多數儲存引擎都支援這種索引。使用B-Tree這個術語,是因為MySQL在CREATE TABLE或其它陳述句中使用了這個關鍵字,但實際上不同的儲存引擎可能使用不同的資料結構,比如InnoDB就是使用的B+Tree。
B+Tree中的B是指balance,意為平衡。需要註意的是,B+樹索引並不能找到一個給定鍵值的具體行,它找到的只是被查詢資料行所在的頁,接著資料庫會把頁讀入到記憶體,再在記憶體中進行查詢,最後得到要查詢的資料。
在介紹B+Tree前,先瞭解一下二叉查詢樹,它是一種經典的資料結構,其左子樹的值總是小於根的值,右子樹的值總是大於根的值,如下圖①。如果要在這課樹中查詢值為5的記錄,其大致流程:先找到根,其值為6,大於5,所以查詢左子樹,找到3,而5大於3,接著找3的右子樹,總共找了3次。同樣的方法,如果查詢值為8的記錄,也需要查詢3次。所以二叉查詢樹的平均查詢次數為(3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3次,而順序查詢的話,查詢值為2的記錄,僅需要1次,但查詢值為8的記錄則需要6次,所以順序查詢的平均查詢次數為:(1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3次,因此大多數情況下二叉查詢樹的平均查詢速度比順序查詢要快。

二叉查詢樹和平衡二叉樹
由於二叉查詢樹可以任意構造,同樣的值,可以構造出如圖②的二叉查詢樹,顯然這棵二叉樹的查詢效率和順序查詢差不多。若想二叉查詢數的查詢效能最高,需要這棵二叉查詢樹是平衡的,也即平衡二叉樹(AVL樹)。
平衡二叉樹首先需要符合二叉查詢樹的定義,其次必須滿足任何節點的兩個子樹的高度差不能大於1。顯然圖②不滿足平衡二叉樹的定義,而圖①是一課平衡二叉樹。平衡二叉樹的查詢效能是比較高的(效能最好的是最優二叉樹),查詢效能越好,維護的成本就越大。比如圖①的平衡二叉樹,當使用者需要插入一個新的值9的節點時,就需要做出如下變動。
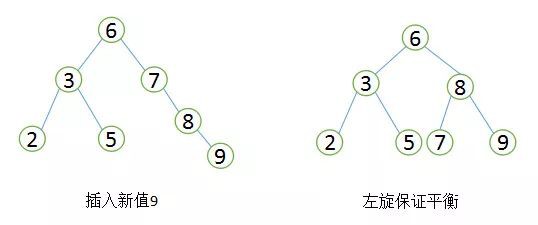
平衡二叉樹旋轉
透過一次左旋操作就將插入後的樹重新變為平衡二叉樹是最簡單的情況了,實際應用場景中可能需要旋轉多次。至此我們可以考慮一個問題,平衡二叉樹的查詢效率還不錯,實現也非常簡單,相應的維護成本還能接受,為什麼MySQL索引不直接使用平衡二叉樹?
隨著資料庫中資料的增加,索引本身大小隨之增加,不可能全部儲存在記憶體中,因此索引往往以索引檔案的形式儲存的磁碟上。這樣的話,索引查詢過程中就要產生磁碟I/O消耗,相對於記憶體存取,I/O存取的消耗要高幾個數量級。可以想象一下一棵幾百萬節點的二叉樹的深度是多少?如果將這麼大深度的一顆二叉樹放磁碟上,每讀取一個節點,需要一次磁碟的I/O讀取,整個查詢的耗時顯然是不能夠接受的。那麼如何減少查詢過程中的I/O存取次數?
一種行之有效的解決方法是減少樹的深度,將二叉樹變為m叉樹(多路搜尋樹),而B+Tree就是一種多路搜尋樹。理解B+Tree時,只需要理解其最重要的兩個特徵即可:第一,所有的關鍵字(可以理解為資料)都儲存在葉子節點(Leaf Page),非葉子節點(Index Page)並不儲存真正的資料,所有記錄節點都是按鍵值大小順序存放在同一層葉子節點上。其次,所有的葉子節點由指標連線。如下圖為高度為2的簡化了的B+Tree。
 簡化B+Tree
簡化B+Tree
怎麼理解這兩個特徵?MySQL將每個節點的大小設定為一個頁的整數倍(原因下文會介紹),也就是在節點空間大小一定的情況下,每個節點可以儲存更多的內結點,這樣每個結點能索引的範圍更大更精確。所有的葉子節點使用指標連結的好處是可以進行區間訪問,比如上圖中,如果查詢大於20而小於30的記錄,只需要找到節點20,就可以遍歷指標依次找到25、30。如果沒有連結指標的話,就無法進行區間查詢。這也是MySQL使用B+Tree作為索引儲存結構的重要原因。
MySQL為何將節點大小設定為頁的整數倍,這就需要理解磁碟的儲存原理。磁碟本身存取就比主存慢很多,在加上機械運動損耗(特別是普通的機械硬碟),磁碟的存取速度往往是主存的幾百萬分之一,為了儘量減少磁碟I/O,磁碟往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個位元組,磁碟也會從這個位置開始,順序向後讀取一定長度的資料放入記憶體,預讀的長度一般為頁的整數倍。
頁是計算機管理儲存器的邏輯塊,硬體及OS往往將主存和磁碟儲存區分割為連續的大小相等的塊,每個儲存塊稱為一頁(許多OS中,頁的大小通常為4K)。主存和磁碟以頁為單位交換資料。當程式要讀取的資料不在主存中時,會觸發一個缺頁異常,此時系統會向磁碟發出讀盤訊號,磁碟會找到資料的起始位置並向後連續讀取一頁或幾頁載入記憶體中,然後一起傳回,程式繼續執行。
MySQL巧妙利用了磁碟預讀原理,將一個節點的大小設為等於一個頁,這樣每個節點只需要一次I/O就可以完全載入。為了達到這個目的,每次新建節點時,直接申請一個頁的空間,這樣就保證一個節點物理上也儲存在一個頁裡,加之計算機儲存分配都是按頁對齊的,就實現了讀取一個節點只需一次I/O。假設B+Tree的高度為h,一次檢索最多需要h-1次I/O(根節點常駐記憶體),複雜度O(h) = O(logmN)。實際應用場景中,M通常較大,常常超過100,因此樹的高度一般都比較小,通常不超過3。
最後簡單瞭解下B+Tree節點的操作,在整體上對索引的維護有一個大概的瞭解,雖然索引可以大大提高查詢效率,但維護索引仍要花費很大的代價,因此合理的建立索引也就尤為重要。
仍以上面的樹為例,我們假設每個節點只能儲存4個內節點。首先要插入第一個節點28,如下圖所示。
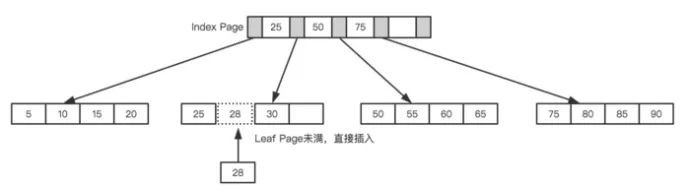
leaf page和index page都沒有滿
接著插入下一個節點70,在Index Page中查詢後得知應該插入到50 – 70之間的葉子節點,但葉子節點已滿,這時候就需要進行也分裂的操作,當前的葉子節點起點為50,所以根據中間值來拆分葉子節點,如下圖所示。
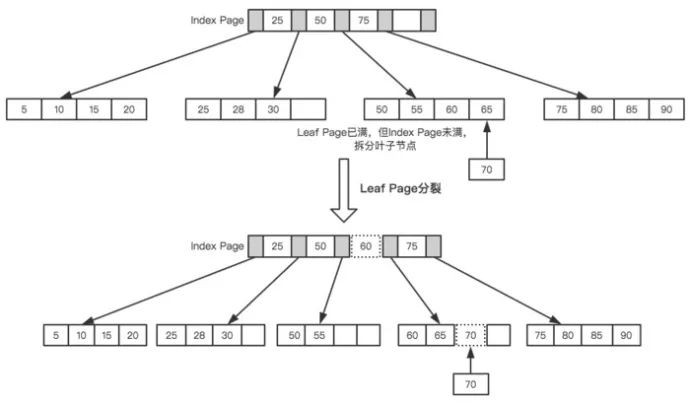
Leaf Page拆分
最後插入一個節點95,這時候Index Page和Leaf Page都滿了,就需要做兩次拆分,如下圖所示。
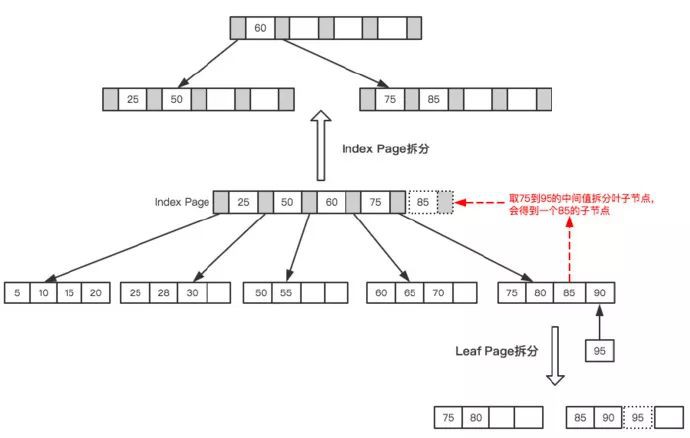
Leaf Page與Index Page拆分
拆分後最終形成了這樣一顆樹。

最終樹
B+Tree為了保持平衡,對於新插入的值需要做大量的拆分頁操作,而頁的拆分需要I/O操作,為了盡可能的減少頁的拆分操作,B+Tree也提供了類似於平衡二叉樹的旋轉功能。當Leaf Page已滿但其左右兄弟節點沒有滿的情況下,B+Tree並不急於去做拆分操作,而是將記錄移到當前所在頁的兄弟節點上。通常情況下,左兄弟會被先檢查用來做旋轉操作。就比如上面第二個示例,當插入70的時候,並不會去做頁拆分,而是左旋操作。

左旋操作
透過旋轉操作可以最大限度的減少頁分裂,從而減少索引維護過程中的磁碟的I/O操作,也提高索引維護效率。需要註意的是,刪除節點跟插入節點類似,仍然需要旋轉和拆分操作,這裡就不再說明。
高效能策略
透過上文,相信你對B+Tree的資料結構已經有了大致的瞭解,但MySQL中索引是如何組織資料的儲存呢?以一個簡單的示例來說明,假如有如下資料表:
CREATE TABLE People(
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum(`m`,`f`) not null,
key(last_name,first_name,dob)
);
對於表中每一行資料,索引中包含了last_name、first_name、dob列的值,下圖展示了索引是如何組織資料儲存的。

索引如何組織資料儲存,來自:高效能MySQL
可以看到,索引首先根據第一個欄位來排列順序,當名字相同時,則根據第三個欄位,即出生日期來排序,正是因為這個原因,才有了索引的“最左原則”。
1、MySQL不會使用索引的情況:非獨立的列
“獨立的列”是指索引列不能是運算式的一部分,也不能是函式的引數。比如:
select * from where id + 1 = 5
我們很容易看出其等價於 id = 4,但是MySQL無法自動解析這個運算式,使用函式是同樣的道理。
2、字首索引
如果列很長,通常可以索引開始的部分字元,這樣可以有效節約索引空間,從而提高索引效率。
3、多列索引和索引順序
在多數情況下,在多個列上建立獨立的索引並不能提高查詢效能。理由非常簡單,MySQL不知道選擇哪個索引的查詢效率更好,所以在老版本,比如MySQL5.0之前就會隨便選擇一個列的索引,而新的版本會採用合併索引的策略。舉個簡單的例子,在一張電影演員表中,在actor_id和film_id兩個列上都建立了獨立的索引,然後有如下查詢:
select film_id,actor_id from film_actor where actor_id = 1 or film_id = 1
老版本的MySQL會隨機選擇一個索引,但新版本做如下的最佳化:
select film_id,actor_id from film_actor where actor_id = 1
union all
select film_id,actor_id from film_actor where film_id = 1 and actor_id <> 1
-
當出現多個索引做相交操作時(多個AND條件),通常來說一個包含所有相關列的索引要優於多個獨立索引。
-
當出現多個索引做聯合操作時(多個OR條件),對結果集的合併、排序等操作需要耗費大量的CPU和記憶體資源,特別是當其中的某些索引的選擇性不高,需要傳回合併大量資料時,查詢成本更高。所以這種情況下還不如走全表掃描。
因此explain時如果發現有索引合併(Extra欄位出現Using union),應該好好檢查一下查詢和表結構是不是已經是最優的,如果查詢和表都沒有問題,那隻能說明索引建的非常糟糕,應當慎重考慮索引是否合適,有可能一個包含所有相關列的多列索引更適合。
前面我們提到過索引如何組織資料儲存的,從圖中可以看到多列索引時,索引的順序對於查詢是至關重要的,很明顯應該把選擇性更高的欄位放到索引的前面,這樣透過第一個欄位就可以過濾掉大多數不符合條件的資料。
索引選擇性是指不重覆的索引值和資料表的總記錄數的比值,選擇性越高查詢效率越高,因為選擇性越高的索引可以讓MySQL在查詢時過濾掉更多的行。唯一索引的選擇性是1,這是最好的索引選擇性,效能也是最好的。
理解索引選擇性的概念後,就不難確定哪個欄位的選擇性較高了,查一下就知道了,比如:
SELECT * FROM payment where staff_id = 2 and customer_id = 584
是應該建立(staff_id,customer_id)的索引還是應該顛倒一下順序?執行下麵的查詢,哪個欄位的選擇性更接近1就把哪個欄位索引前面就好。
select count(distinct staff_id)/count(*) as staff_id_selectivity,
count(distinct customer_id)/count(*) as customer_id_selectivity,
count(*) from payment
多數情況下使用這個原則沒有任何問題,但仍然註意你的資料中是否存在一些特殊情況。舉個簡單的例子,比如要查詢某個使用者組下有過交易的使用者資訊:
select user_id from trade where user_group_id = 1 and trade_amount > 0
MySQL為這個查詢選擇了索引(user_group_id,trade_amount),如果不考慮特殊情況,這看起來沒有任何問題,但實際情況是這張表的大多數資料都是從老系統中遷移過來的,由於新老系統的資料不相容,所以就給老系統遷移過來的資料賦予了一個預設的使用者組。這種情況下,透過索引掃描的行數跟全表掃描基本沒什麼區別,索引也就起不到任何作用。
推廣開來說,經驗法則和推論在多數情況下是有用的,可以指導我們開發和設計,但實際情況往往會更複雜,實際業務場景下的某些特殊情況可能會摧毀你的整個設計。
4、避免多個範圍條件
實際開發中,我們會經常使用多個範圍條件,比如想查詢某個時間段內登入過的使用者:
select user.* from user where login_time > ‘2017-04-01’ and age between 18 and 30;
這個查詢有一個問題:它有兩個範圍條件,login_time列和age列,MySQL可以使用login_time列的索引或者age列的索引,但無法同時使用它們。
5、改寫索引
如果一個索引包含或者說改寫所有需要查詢的欄位的值,那麼就沒有必要再回表查詢,這就稱為改寫索引。改寫索引是非常有用的工具,可以極大的提高效能,因為查詢只需要掃描索引會帶來許多好處:
-
索引條目遠小於資料行大小,如果只讀取索引,極大減少資料訪問量
-
索引是有按照列值順序儲存的,對於I/O密集型的範圍查詢要比隨機從磁碟讀取每一行資料的IO要少的多
6、使用索引掃描來排序
MySQL有兩種方式可以生產有序的結果集,其一是對結果集進行排序的操作,其二是按照索引順序掃描得出的結果自然是有序的。如果explain的結果中type列的值為index表示使用了索引掃描來做排序。
掃描索引本身很快,因為只需要從一條索引記錄移動到相鄰的下一條記錄。但如果索引本身不能改寫所有需要查詢的列,那麼就不得不每掃描一條索引記錄就回表查詢一次對應的行。這個讀取操作基本上是隨機I/O,因此按照索引順序讀取資料的速度通常要比順序地全表掃描要慢。
在設計索引時,如果一個索引既能夠滿足排序,又滿足查詢,是最好的。
只有當索引的列順序和ORDER BY子句的順序完全一致,並且所有列的排序方向也一樣時,才能夠使用索引來對結果做排序。如果查詢需要關聯多張表,則只有ORDER BY子句取用的欄位全部為第一張表時,才能使用索引做排序。ORDER BY子句和查詢的限制是一樣的,都要滿足最左字首的要求(有一種情況例外,就是最左的列被指定為常數,下麵是一個簡單的示例),其他情況下都需要執行排序操作,而無法利用索引排序。
// 最左列為常數,索引:(date,staff_id,customer_id)
select staff_id,customer_id from demo where date = ‘2015-06-01’ order by staff_id,customer_id
7、冗餘和重覆索引
冗餘索引是指在相同的列上按照相同的順序建立的相同型別的索引,應當儘量避免這種索引,發現後立即刪除。比如有一個索引(A,B),再建立索引(A)就是冗餘索引。冗餘索引經常發生在為表新增新索引時,比如有人新建了索引(A,B),但這個索引不是擴充套件已有的索引(A)。
大多數情況下都應該儘量擴充套件已有的索引而不是建立新索引。但有極少情況下出現效能方面的考慮需要冗餘索引,比如擴充套件已有索引而導致其變得過大,從而影響到其他使用該索引的查詢。
8、刪除長期未使用的索引
定期刪除一些長時間未使用過的索引是一個非常好的習慣。
關於索引這個話題打算就此打住,最後要說一句,索引並不總是最好的工具,只有當索引幫助提高查詢速度帶來的好處大於其帶來的額外工作時,索引才是有效的。對於非常小的表,簡單的全表掃描更高效。對於中到大型的表,索引就非常有效。對於超大型的表,建立和維護索引的代價隨之增長,這時候其他技術也許更有效,比如分割槽表。最後的最後,explain後再提測是一種美德。
特定型別查詢最佳化
最佳化COUNT()查詢
COUNT()可能是被大家誤解最多的函式了,它有兩種不同的作用,其一是統計某個列值的數量,其二是統計行數。統計列值時,要求列值是非空的,它不會統計NULL。如果確認括號中的運算式不可能為空時,實際上就是在統計行數。最簡單的就是當使用COUNT(*)時,並不是我們所想象的那樣擴充套件成所有的列,實際上,它會忽略所有的列而直接統計行數。
我們最常見的誤解也就在這兒,在括號內指定了一列卻希望統計結果是行數,而且還常常誤以為前者的效能會更好。但實際並非這樣,如果要統計行數,直接使用COUNT(*),意義清晰,且效能更好。
有時候某些業務場景並不需要完全精確的COUNT值,可以用近似值來代替,EXPLAIN出來的行數就是一個不錯的近似值,而且執行EXPLAIN並不需要真正地去執行查詢,所以成本非常低。通常來說,執行COUNT()都需要掃描大量的行才能獲取到精確的資料,因此很難最佳化,MySQL層面還能做得也就只有改寫索引了。如果不還能解決問題,只有從架構層面解決了,比如新增彙總表,或者使用redis這樣的外部快取系統。
最佳化關聯查詢
在大資料場景下,表與表之間透過一個冗餘欄位來關聯,要比直接使用JOIN有更好的效能。如果確實需要使用關聯查詢的情況下,需要特別註意的是:
-
確保ON和USING字句中的列上有索引。在建立索引的時候就要考慮到關聯的順序。當表A和表B用列c關聯的時候,如果最佳化器關聯的順序是A、B,那麼就不需要在A表的對應列上建立索引。沒有用到的索引會帶來額外的負擔,一般來說,除非有其他理由,只需要在關聯順序中的第二張表的相應列上建立索引(具體原因下文分析)。
-
確保任何的GROUP BY和ORDER BY中的運算式只涉及到一個表中的列,這樣MySQL才有可能使用索引來最佳化。
要理解最佳化關聯查詢的第一個技巧,就需要理解MySQL是如何執行關聯查詢的。當前MySQL關聯執行的策略非常簡單,它對任何的關聯都執行巢狀迴圈關聯操作,即先在一個表中迴圈取出單條資料,然後在巢狀迴圈到下一個表中尋找匹配的行,依次下去,直到找到所有表中匹配的行為為止。然後根據各個表匹配的行,傳回查詢中需要的各個列。
太抽象了?以上面的示例來說明,比如有這樣的一個查詢:
SELECT A.xx,B.yy
FROM A INNER JOIN B USING(c)
WHERE A.xx IN (5,6)
假設MySQL按照查詢中的關聯順序A、B來進行關聯操作,那麼可以用下麵的偽程式碼表示MySQL如何完成這個查詢:
outer_iterator = SELECT A.xx,A.c FROM A WHERE A.xx IN (5,6);
outer_row = outer_iterator.next;
while(outer_row) {
inner_iterator = SELECT B.yy FROM B WHERE B.c = outer_row.c;
inner_row = inner_iterator.next;
while(inner_row) {
output[inner_row.yy,outer_row.xx];
inner_row = inner_iterator.next;
}
outer_row = outer_iterator.next;
}
可以看到,最外層的查詢是根據A.xx列來查詢的,A.c上如果有索引的話,整個關聯查詢也不會使用。再看內層的查詢,很明顯B.c上如果有索引的話,能夠加速查詢,因此只需要在關聯順序中的第二張表的相應列上建立索引即可。
最佳化LIMIT分頁
當需要分頁操作時,通常會使用LIMIT加上偏移量的辦法實現,同時加上合適的ORDER BY字句。如果有對應的索引,通常效率會不錯,否則,MySQL需要做大量的檔案排序操作。
一個常見的問題是當偏移量非常大的時候,比如:LIMIT 10000 20這樣的查詢,MySQL需要查詢10020條記錄然後只傳回20條記錄,前面的10000條都將被拋棄,這樣的代價非常高。
最佳化這種查詢一個最簡單的辦法就是盡可能的使用改寫索引掃描,而不是查詢所有的列。然後根據需要做一次關聯查詢再傳回所有的列。對於偏移量很大時,這樣做的效率會提升非常大。考慮下麵的查詢:
SELECT film_id,description FROM film ORDER BY title LIMIT 50,5;
如果這張表非常大,那麼這個查詢最好改成下麵的樣子:
SELECT film.film_id,film.description
FROM film INNER JOIN (
SELECT film_id FROM film ORDER BY title LIMIT 50,5
) AS tmp USING(film_id);
這裡的延遲關聯將大大提升查詢效率,讓MySQL掃描盡可能少的頁面,獲取需要訪問的記錄後在根據關聯列回原表查詢所需要的列。
有時候如果可以使用書簽記錄上次取資料的位置,那麼下次就可以直接從該書簽記錄的位置開始掃描,這樣就可以避免使用OFFSET,比如下麵的查詢:
SELECT id FROM t LIMIT 10000, 10;
改為:
SELECT id FROM t WHERE id > 10000 LIMIT 10;
其他最佳化的辦法還包括使用預先計算的彙總表,或者關聯到一個冗餘表,冗餘表中只包含主鍵列和需要做排序的列。
最佳化UNION
MySQL處理UNION的策略是先建立臨時表,然後再把各個查詢結果插入到臨時表中,最後再來做查詢。因此很多最佳化策略在UNION查詢中都沒有辦法很好的時候。經常需要手動將WHERE、LIMIT、ORDER BY等字句“下推”到各個子查詢中,以便最佳化器可以充分利用這些條件先最佳化。
除非確實需要伺服器去重,否則就一定要使用UNION ALL,如果沒有ALL關鍵字,MySQL會給臨時表加上DISTINCT選項,這會導致整個臨時表的資料做唯一性檢查,這樣做的代價非常高。當然即使使用ALL關鍵字,MySQL總是將結果放入臨時表,然後再讀出,再傳回給客戶端。雖然很多時候沒有這個必要,比如有時候可以直接把每個子查詢的結果傳回給客戶端。
結語
理解查詢是如何執行以及時間都消耗在哪些地方,再加上一些最佳化過程的知識,可以幫助大家更好的理解MySQL,理解常見最佳化技巧背後的原理。希望本文中的原理、示例能夠幫助大家更好的將理論和實踐聯絡起來,更多的將理論知識運用到實踐中。
其他也沒啥說的了,給大家留兩個思考題吧,可以在腦袋裡想想答案,這也是大家經常掛在嘴邊的,但很少有人會思考為什麼?
-
有非常多的程式員在分享時都會丟擲這樣一個觀點:盡可能不要使用儲存過程,儲存過程非常不容易維護,也會增加使用成本,應該把業務邏輯放到客戶端。既然客戶端都能幹這些事,那為什麼還要儲存過程?
-
JOIN本身也挺方便的,直接查詢就好了,為什麼還需要檢視呢?
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

