
來源:Python程式員
ID:pythonbuluo
你可能已經(或可能沒有)聽過或看過增強現實電子游戲隱形妖怪或Topps推出的3D棒球卡。其主要思想是在平板電腦,PC或智慧手機的螢幕上,根據卡片的位置和方向,渲染特定圖形的3D模型到卡片上。

圖1:隱形妖怪增強現實卡。
上個學期,我參加了計算機視覺課程,對投影幾何學的若干方面進行了研究,並認為自己開發一個基於卡片的增強現實應用程式將是一個有趣的專案。我提醒你,我們需要一點代數來使它工作,但我會儘量少用。為了充分利用它,你應該輕鬆使用不同的坐標系統和變換矩陣。
首先,這篇文章並不是一個教程,也不會涉及計算機視覺技術的全面指南或解釋,我只提及後續工作所需的要點。不過,我鼓勵你深挖這一路上出現的概念。
其次,不要指望一些專業的結果。我這樣做只是為了好玩,而且我做的很多決策本可以做的更好。文章的主要思想是開發一個概念驗證應用程式。
/免責宣告>
說到這裡,後面的我負責了。
我們從哪裡開始?
從整體上看這個專案可能會比實際上更困難。所幸的是,我們能夠把它劃分成更小的部分,當這些部分合併在一起時,我們就可以使增強現實應用程式工作了。現在的問題是,我們需要哪些更小的塊?
讓我們仔細看看我們想要達到的標的。如前所述,我們希望在螢幕上投影一個圖形的三維模型,其位置和方向與某個預定義平面的位置和方向相匹配。此外,我們希望實時進行,這樣,如果平面改變其位置或方向,投影模型就會相應地改變。
為了實現這一點,我們首先必須能夠識別影象或影片幀中的參考面。一旦確定,我們可以輕鬆確定從參考面影象(2D)到標的影象(2D)的轉換。這種變換叫做單應。但是,如果我們想要將放置在參考面頂部的3D模型投影到標的影象上,我們需要擴充套件前面的變換來處理參考面坐標系中要投影點的高度不是零的情況。這可以用一些代數來實現。最後,我們將這個轉換應用到我們的3D模型併在螢幕上繪製。考慮到前面的觀點,我們的專案可以分為:
1、識別參考平面。
2、估計單應性。
3、從單應性推匯出從參考面坐標繫到標的影象坐標系的轉換。
4、在影象(畫素空間)中投影我們的3D模型並繪製它。

圖2:概述增強現實應用程式的整個過程。
我們將使用的主要工具是Python和OpenCV,因為它們都是開源的,易於建立和使用,並且使用它們能快速構建原型。用到代數,我將使用numpy。
識別標的錶面
從物件識別的許多可能的技術中,我決定用基於特徵的識別方法來解決這個問題。這種方法不深入細節,包括三個主要步驟:特徵檢測或提取、特徵描述和特徵匹配。
特徵提取
大體而言,這一步驟包括先在參考影象和標的物件中尋找突出的特徵,並以某種方式描述要識別的物件的一部分。這些特徵稍後可以用於在標的物件中查詢參考物件。當標的物件和參考影象之間找到一定數量的正特徵匹配時,我們假設已經找到標的。為了使之工作,重要的是要有一個參考影象,在那裡唯一能看到的是要被髮現的物體(或錶面,在這種情況下)。我們不想檢測不屬於錶面的特徵。而且,雖然我們稍後會處理這個問題,但是當我們估計場景中錶面的樣子時,我們將用到參考影象的尺寸。
對於要被標記為特徵的影象的區域或點,它應該有兩個重要的屬性:首先,它應該至少在本地呈現一些唯一性。這方面典型的例子可能是角或邊。其次,因為我們事先不知道它是什麼,例如,在我們想要識別它的影象中,同一物體的方向、尺度或亮度條件,理想情況下,應該是不變的變換,即不變的尺度、旋轉或亮度變化。根據經驗,越恆定越好。

圖3:左側,從我將使用的錶面模型中提取的特徵。右側,從場景中提取的特徵。註意,最右側圖形的角落是如何檢測為興趣點的。
特徵描述
一旦找到特徵,我們應該找到它們提供的資訊的適當表示形式。這將允許我們在其它影象中尋找它們,並且還可以獲取比較時兩個檢測到的特徵相似的度量。描述符提供由特徵及其周圍環境給出的資訊的表示。一旦描述符被計算出來,待識別的物件就可以被抽象成一個特徵vector,該vector包含影象和參考物件中發現的關鍵點的描述符。
這當然是個好註意,但實際上該怎麼做呢?有很多演演算法可以提取影象特徵並計算其描述符,因為我不會更詳細地討論(整篇文章可能僅限於此),如果你有興趣瞭解更多的話,可以看看SIFT, SURF,或 Harris。我們將使用在OpenCV實驗室開發的,它被稱為ORB(Oriented FAST and Rotated BRIEF)。描述符的形狀和值取決於所使用的演演算法,在我們的例子中,所獲得的描述符將是二進位制字串。
使用OpenCV,透過ORB探測器提取特徵及其描述符很容易:

特徵匹配
一旦我們找到了物件和場景的特徵,就要找到物件並計算它的描述符,是時候尋找它們之間的匹配了。最簡單的方法是取第一個組中每個特徵的描述符,計算第二組中所有描述符的距離,並傳回最接近的一個作為最佳匹配 (在這裡我要指出,選擇一種與使用的描述符相匹配的距離測量方法很重要。因為我們的描述符是二進位制字串,所以我們將使用明漢距離)。這是一種暴力方法,而且存在更先進的方法。
例如,我們將使用的,我們可以檢查,前面解釋過的匹配從第二組向第一組方向來計算匹配時也是最好的匹配。這意味著這兩個特徵相互匹配。一旦兩個方向的匹配完成,我們只接受滿足先前條件的有效匹配。圖4顯示了使用該方法找到15個最佳匹配項。
減少誤報數量的另一種選擇是檢查到第二個最佳匹配的距離是否低於某一閾值。如果是,那麼匹配被認為是有效的。

圖4:參考面和場景之間找到最接近的15個暴力匹配
最後,在找到匹配之後,我們應該定義一些標準來決定物件是否被找到。為此,我定義了應該找到的最小匹配數的閾值。如果匹配的數量高於閾值,則我們假設物件該已經被找到。否則,我們認為沒有足夠的證據表明識別是成功的。
使用OpenCV ,所有這些識別過程都可以用幾行程式碼完成:

最後要說明的是,在進入這個過程的下一步之前,我必須指出,因為我們想要一個實時的應用程式,所以最好是實現一個跟蹤技術,而不僅僅是簡單的識別。這是因為,物件識別將獨立地在每個幀中執行,而不考慮以前的幀,這可以新增取用物件位置的有價值的資訊。另一件需要考慮的事是,找到參考面越簡單檢測越健壯。從這個特定的意義上,我使用的參考面可能不是最佳的選擇,但它有助於理解過程。
單應估計
一旦我們識別當前幀的參考面而且有一組有效匹配,我們可以估計兩幅圖之間的單應。前面已經解釋過,我們想要找到將點從參考面對映到影象平面的轉換(參見圖5)。這個轉換必須更新我們處理的每個新幀。
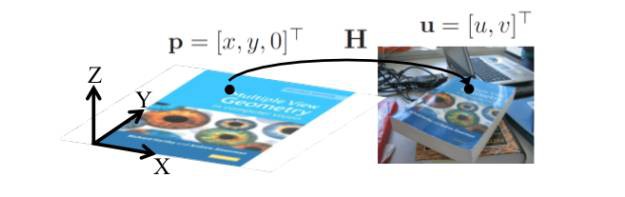
圖5:平面和影象之間的單應。來源: F. Moreno.
我們怎麼能找到這樣的轉變呢?既然我們已經找到了兩幅影象之間的一組匹配,我們當然可以直接透過任何現有的方法(我提議使用RANSAC)找到一個同構轉換來執行對映,但讓我們瞭解一下我們正在做什麼(見圖6)。如果需要,你可以跳過以下部分(在圖10之後繼續閱讀),因為我只會解釋我們將要估計的轉換背後的原因。
我們所擁有的是一個具有已知坐標的物件(在這種情況下是一個平面),比方說世界坐標系,我們用位於相對於世界坐標系的特定位置和方向的攝像機拍攝它。我們假定相機遵循針孔模型工作,這大致意味著穿過3D點p和相應的2D點u的光線相交於攝像機的中心c。如果你有興趣瞭解更多關於針孔模型的知識,這裡有一個好的資源。

圖6:成像假定為針孔成像模型。來源:F. Moreno.
雖然不是完全正確的,但針孔模型假設簡化了我們的計算,並對於我們的目的來說工作得很好。如果我們假設可以計算為針孔照相機(公式的推導作為練習留給讀者),則點p在相機坐標系統中表示為u,v坐標(影象平面中的坐標):

圖7: 成像假定為針孔成像模型。來源: F. Moreno。
在焦距是從針孔到影象平面的距離的情況下,光學中心的投影是光學中心在影象平面的位置,k是縮放因子。前面的方程告訴我們影象是如何形成的。然而,如前所述,我們知道點p在世界坐標系而不是相機坐標系中的坐標,因此我們必須新增另一個將世界坐標系中的點對映到相機坐標系的轉換。根據變換,世界坐標系中的p點的影象平面坐標是:

圖8:計算投影矩陣。來源: F. Moreno。
幸運的是,由於參考面的點的z坐標始終等於0(參考圖5),我們可以簡化上面發現的轉換。很容易看出,z坐標和投影矩陣的第三列的乘積將是0,所以我們可以將該列和z坐標從前面的等式中刪除。將校準矩陣重新命名為A,並考慮到外部校準矩陣是齊次變換:

圖9:簡化投影矩陣。來源: F. Moreno。
從圖9我們可以得出結論,參考面與圖形平面之間的單應,這是我們從之前發現的匹配中估計出的矩陣:

圖10:參考平面和標的影象平面之間的單應矩陣。來源: F. Moreno。
有幾種可以讓我們估計單應矩陣的值,並且你可能熟悉其中的一些。我們將使用的是RANdom SAmple Consensus(RANSAC)。RANSAC是一種用於存在大量異常值的模型擬合的迭代演演算法,圖12列出了該過程的綱要。因為我們不能保證我們發現的所有匹配都是有效的匹配,我們必須考慮有可能存在一些錯誤的匹配(這將是我們的異常值),因此我們必須使用一種對異常值有效的估計方法。圖11說明瞭如果我們認為沒有異常值估計單應時,可能會存在的問題。

圖11:存在異常值的單應估計。來源: F. Moreno。

圖12:RANSAC演演算法概述。來源: F. Moreno。
為了說明RANSAC如何工作,並且使事情更清楚,假設我們有一組要使用RANSAC擬合一條線的點:

圖13:初始點集。來源: F. Moreno。
根據圖12所示的概述,我們可以推匯出使用RANSAC擬合線的具體過程(圖14)。

圖14:RANSAC演演算法將一條線擬合到一組點。來源: F. Moreno。
執行上述演演算法的一個可能的結果可以在圖15中看到。註意,該演演算法的前3個步驟只顯示第一次迭代(由右下角的數字表示),並且只顯示評分步驟。

圖15:使用RANSAC將一條線代入一組點。來源:F. Moreno。
現在回到我們的用例,單應矩陣估計。對於單應估計,演演算法如圖16所示。由於它主要是數學,所以我不會詳細討論為什麼需要4個匹配或者如何估計H。但是, 如果你想知道為什麼以及如何完成,這有一個很好的解釋。

圖16:用於單應矩陣估計的RANSAC。來源: F. Moreno。
在看OpenCV如何為我們處理這個問題之前,我們應該討論一下演演算法的決定性的一個方面,就是匹配H的含義。它的主要含義是,如果在估計單應性之後,我們將未用於估計的匹配對映到標的影象,那麼參考面的投影點應該接近標的影象中的匹配點。 如何認為它們一致取決於你。
我知道要達到這一點很困難,但謝天謝地,在OpenCV中,使用RANSAC估計單應很簡單:

其中5.0是距離閾值,用來確定匹配與估計單應是否一致。如果在估計單應之後,我們將標的影象的參考面的四個角投影到一條線上,我們應該期望得到的線將參考麵包圍在標的影象中。我們可以這樣做:

結果是:

圖17:具有估算單應的參考面的投射角。
我想今天就到這裡了。在下一篇文章,我們將看到如何擴充套件我們已經估計的單應矩陣,不僅可以在投影參考面上的點,而且可以投影從參考面坐標繫到標的影象的任何3D點。我們將使用這個方法來實時計算,每個影片幀的特定投影矩陣,然後從.obj檔案選擇投影的影片流3D模型。在下一篇文章的結尾,你可以看到類似於下麵GIF中所看到的內容:

與往常一樣,釋出第2部分時,我會上傳該專案的完整程式碼和一些3D模型到GitHub供你測試。
英文原文:https://bitesofcode.wordpress.com/2017/09/12/augmented-reality-with-python-and-opencv-part-1/
譯者:張新英
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Python好文請點選【閱讀原文】哦
↓↓↓
