作者:Tirthajyoti Sarkar;翻譯:張逸;校對:馮羽
本文約3090字,建議閱讀6分鐘。
本文從非線性資料進行建模,帶你用簡便並且穩健的方法來快速實現使用Python進行機器學習。
使用Python庫、流水線功能以及正則化方法對非線性資料進行建模。
在資料科學和分析領域中,對非線性資料進行建模是一項常規任務。但找到一個結果隨自變數線性變化的自然過程很不容易。因此,需要有一種簡便並且穩健的方法來快速將測量資料集與一組變數進行擬合。我們假定測量資料可能包含了一種複雜的非線性函式關係。這應該是資料科學家或機器學習工程師常用的工具。
我們要考慮以下幾個相關的問題:
-
怎麼確定擬合多項式的順序?是否需要為多變數回歸加上交叉耦合項?有沒有簡單的方法將這一過程自動化?
-
怎樣判斷模型是否過擬合?
-
如何得知模型在面對噪聲時夠不夠穩健?
-
模型能不能輕鬆拓展到更高維度或更大的資料集上?
如何確定擬合多項式的順序?
“我們能不能畫出資料圖形直接得到結論?”
資料如果能清楚的視覺化表示(即特徵維度為1或2)時,方法可行。一旦資料的特徵維度等於3或者更多,這事兒就麻煩了。而且如果對結果產生影響的特徵存在交叉耦合,這麼做就完全是在浪費時間。下麵我們畫個圖來感受一下:

很明顯,直接畫圖的方法最多也只能做到上面這種程度。對那些更高維度並且變數相互作用的資料集,如果你試圖每次只檢視單個輸入變數和輸出之間的關係,會得出完全錯誤的結論。而且目前沒有什麼好辦法同時顯示兩個以上的變數。所以,我們必須採用某種機器學習的技術來擬合多維資料集。
實際上,已經有了不少好的解決方案。
在你看到“…但這些是高維非線性資料集…”這句話發出尖叫之前,線性回歸應該是頭一個能找到的工具。註意一點:線性回歸模型中的“線性”二字指的是繫數,而不是特徵。特徵(即自變數)可以是任意多維度的,甚至可以是指數、對數、正弦這些函式。更厲害的是,可以使用這些變換和線性模型(近似)對令人驚訝的大量自然現象進行建模。
來看看下邊這個有三個特徵、單輸出的資料集。我們再一次使用了前邊提到的畫圖方法,很明顯它表現的差強人意。

因此,我們決定學習一個具有高階多項式項線性模型來擬合資料集。那麼問題來了:
-
怎樣確定什麼多項式是有用的?
-
如果我們開始將一次項、二次項、三次項…逐個進行組合,什麼時候停止比較合適呢?
-
我們怎麼判定哪些交叉耦合的項是重要的?比如:是隻需要_X_1²、_X_2³還是需要有_X_1._X_2以及_X_1².X3這種項?
-
最後,我們是不是必須手動將這些多項式轉換的方程/函式式寫出來並且應用到資料集上?
強大的Python機器學習庫來幫忙
幸運的是,有一個很厲害的機器學習庫–scikit-learn提供了很多成熟的類/物件來解決上邊說的這些問題。
這兒有一個對使用scikit-learn進行線性回歸進行概述的資料(原文中說是影片,但開啟連結看了一下是這個庫的使用檔案,故直接翻譯為了資料)
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression
還有一篇很好的文章供大家檢視。
https://towardsdatascience.com/simple-and-multiple-linear-regression-in-python-c928425168f9?gi=69160943145f
但本文要介紹的不僅僅是一個簡單的線性擬合,請大家接著往下看。(原文有一句提到程式碼在作者的GitHub,但是發現連結已經404,所以沒加)
我們從引入scikit-learn中相關的包開始:
from sklearn.cross_validation#引入函式進行訓練集和測試集的劃分
import train_test_split
#引入函式自動生成多項式特徵
from sklearn.preprocessing import PolynomialFeatures
# 引入線性回歸和一個正則化的回歸函式
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LassoCV
from sklearn.pipeline import make_pipeline
下麵快速說明一下我們等會兒要用到的一些概念。
訓練/測試集劃分:表示將已有的單獨資料集劃分為兩個子集。其中一個(訓練集)用來建立模型,另外一個(測試集)用來評估模型的準確性和穩定性。這個步驟對任何一個機器學習任務來說都是必不可少的。經過處理,我們沒有用所有的資料建立出一個看似異常準確的模型。(因為模型接觸到所有的資料,當然會擬合的很好)這個模型通常在新資料(未知)資料上表現很差。
模型在測試集上的準確性比其在訓練集上的準確性更有說服力。這兒有一篇關於這個話題延伸的文章,有興趣的讀者可以看看。
https://towardsdatascience.com/train-test-split-and-cross-validation-in-python-80b61beca4b6
下麵你會看到Google car的先驅Sebastion Thrun對這個概念的說法。
多項式特徵自動生成
Scikit-learn提供了一個從一組線性特徵中生成多項式特徵的方法。你需要做的就是傳入線性特徵串列,並指定希望生成的多項式項的最大階數。它還可以讓你選擇是生成所有交叉耦合項還是隻生成主要特徵的階數。這裡有一個Python程式碼進行演示。
http://scikit-learn.org/stable/auto_examples/linear_model/plot_polynomial_interpolation.html#sphx-glr-auto-examples-linear-model-plot-polynomial-interpolation-py
正則化回歸
正則化的重要性不言而喻,它是機器學習的一個中心概念。在建立線性模型時,最基本的想法是對模型的繫數進行“懲罰”,使它們不會變得太大而過擬合資料(對噪聲資料過於敏感)。有兩個廣泛使用的正則化方法,其中我們要用的被稱為LASSO。下邊這篇文章對兩種正則化方法做了很好的概述。
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
機器學習流水線
一個機器學習專案幾乎不會是單一的建模任務。它最常見的形式包括資料生成、資料清洗、資料轉換、模型擬合、交叉驗證、模型準確性評估和最終的部署。
列舉一些相關的學習資料如下:
-
對上述概念總結的一個Quora回答:
https://www.quora.com/What-is-a-pipeline-and-baseline-in-machine-learning-algorithms
-
另外一篇關於機器學習流水線的總結:
https://medium.com/@yanhann10/a-brief-view-of-machine-learning-pipeline-in-python-5f50b941fca8
-
對piplines在實踐中重要性作出闡述:
https://www.oreilly.com/ideas/building-and-deploying-large-scale-machine-learning-pipelines
-
Scikit-learn提供了一個流水線功能,可以將多個模型和資料預處理類組合在一起,把原始資料轉換為可用模型。
http://scikit-learn.org/stable/tutorial
/statistical_inference/putting_together.html
怎樣最終整合併建立一個穩健的模型?
在這裡,我們提供了一些程式碼樣例,你可以對它進行修改,應用在你自己的資料集上。
# LASSO回歸的引數設定
lasso_eps = 0.0001
lasso_nalpha=20
lasso_iter=5000
# 多項式特徵項的最大、最小階數
degree_min = 2
degree_max = 8
# 訓練集、測試集劃分
X_train, X_test, y_train, y_test =
train_test_split(df[‘X’], df[‘y’],test_size=test_set_fraction)
# 建立一個流水線模型
for degree in range(degree_min,degree_max+1):
model=make_pipeline(PolynomialFeatures(degree, interaction_only=False),LassoCV(eps=lasso_eps,
n_alphas=lasso_nalpha,max_iter=lasso_iter,
normalize=True,cv=5))
model.fit(X_train,y_train)
test_pred = np.array(model.predict(X_test))
RMSE=np.sqrt(np.sum(np.square(test_pred-y_test)))
test_score = model.score(X_test,y_test)
不過這些冷冰冰的程式碼是給機器看的,我們還準備了有詳細註釋的版本。
為了進一步提煉它,下麵是更精簡的流程圖:

為了進一步提煉它,下麵是更精簡的流程圖:

讓我們來討論討論結果
對於所有的模型,我們給出了測試誤差、訓練誤差(均方根)還有R²繫數作為模型準確性的度量。然後把它們畫出來:

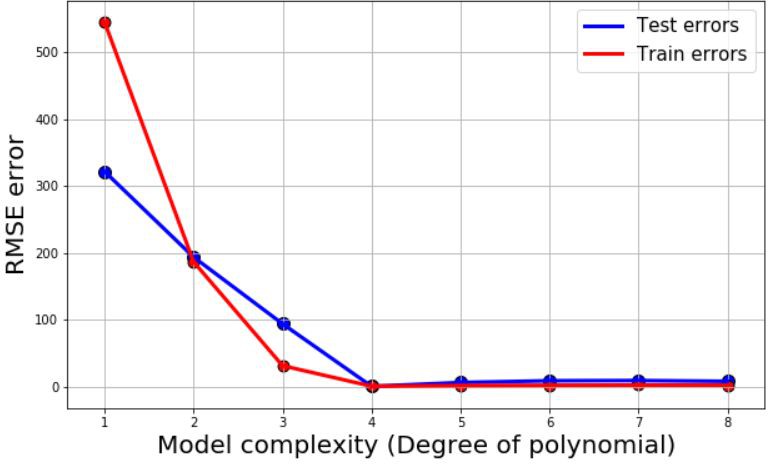
這些圖回答了最早提出的兩個問題。
可以看出,我們需要四階和五階的多項式項來進行擬合。線性、二次甚至三次模型對這個資料來說都不夠複雜。
同時,我們也沒必要使階數超過5,這會使得模型過於複雜。

等等!問題來了:在這條曲線中,我們熟悉的表現出偏差和方差之間權衡(即過擬合與欠擬合)的形狀在哪?為什麼測試誤差沒有隨著模型複雜度的增加急劇升高?
答案在於,使用LASSO回歸之後,我們基本消除了複雜模型中的高階項。對於更細節的東西,比如這個結果到底是怎麼出現的,可以參考這篇文章。
https://dataorigami.net/blogs/napkin-folding/79033923-least-squares-regression-with-l1-penalty
實際上,這正是LASSO回歸和L1正則的關鍵優勢之一,它不是僅僅將模型中的部分繫數減小,而是將它們直接變為零。這相當於提供了“自動特徵選擇”的功能。即便你一開始使用了很複雜的模型來擬合資料,經過這種處理後,也可以讓那些不重要的特徵自動被忽略。
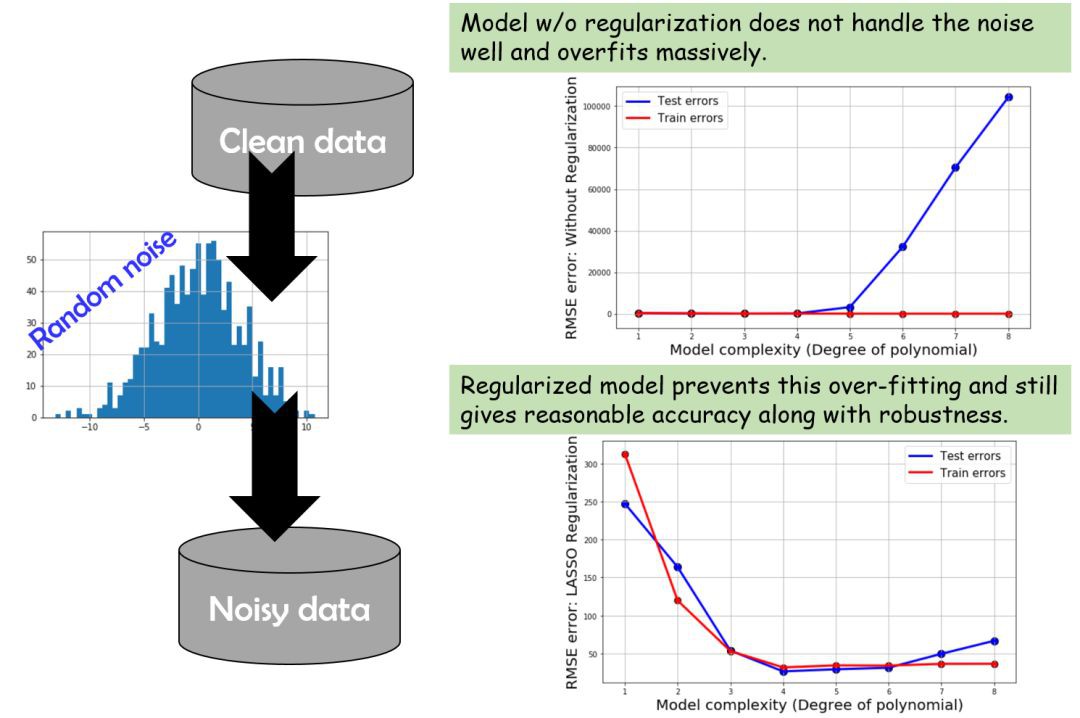
為了進行對比,我們這次不做正則化處理,並且使用一個簡單的線性模型來擬合資料。下邊是得出的結果。這次可以看到那條熟悉的偏差/方差權衡曲線了(補充:表示訓練誤差及測試誤差隨著模型複雜度增長的變化,體現過擬合及欠擬合)

噪聲資料會發生什麼?
(這裡作者有提到自己的程式碼,同樣因為GitHub地址失效沒有加進來)
資料中的噪聲會讓模型很難變得準確,甚至還會產生過擬合。因為模型會試圖解釋噪聲,而不是發掘真正的樣式。基本上,簡單的線性回歸模型在這種情況下都會失敗,而正則化模型仍然表現良好。不過即便這樣,在模型足夠複雜時,過擬合現象也會現出端倪。
下麵是總結:
結語
簡而言之,本文討論了一個擬合多變數回歸模型的方法,它適用於高度非線性、具有耦合項並且含有噪聲的資料集。我們知道瞭如何利用Python的機器學習庫來生成多項式特徵、對資料進行正則化處理,防止模型中的繫數變得過大、畫圖來評估模型的準確性及穩定性等。
對於更高階的具有非多項式特徵的模型,你可以看看sklearn中關於核回歸或支援向量機的內容。還有這篇文章有對高斯核回歸的介紹。
http://mccormickml.com/2014/02/26/kernel-regression/
如果你有任何問題或者看法要分享,
可以點這裡給作者發郵件。(mailto:tirthajyoti@gmail.com)
原文連結:
https://www.codementor.io/tirthajyotisarkar/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-hfgyw7i4f#how-to-decide-the-order-of-polynomial-and-related-dilemma
譯者簡介:張逸,中國傳媒大學大三在讀,主修數字媒體技術。對資料科學充滿好奇,感慨於它創造出來的新世界。目前正在摸索和學習中,希望自己勇敢又熱烈,學最有意思的知識,交最志同道合的朋友。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
