
【文末有彩蛋】
作者簡介
李燁,高階軟體工程師,現就職於微軟(Microsoft),曾在易安信(EMC)和太陽微系統(Sun Microsystems)任軟體工程師。先後參與聊天機器人、大資料分析平臺等專案的開發。

引言
AI原本是一個專業領域,沒什麼特別的。作為碼農一枚,筆者的工作內容正好在這個領域。
近來這一年左右時間裡,連續發生了多件事情,使得筆者不得不抬起原本一直低著敲程式碼的頭,看看這個為AI狂歡的世界。
【Case 1】 居然在一個月裡碰到兩位在相對傳統行業創業的親友,來打聽將AI技術應用到他們所在行業上的問題,例如:是聊天機器人是否可以代替人工客服。
兩位親友居然都動了僱傭一位演演算法工程師的念頭。其中一位真的已經開始物色了。
頗費周折找到一位某非 985 院校專業對口的博士,友人有點動心想要聘用,奈何人家開口就要100萬年薪。
創業企業雖然已經拿了兩輪融資,還是不敢燒錢作死,故而多方打聽“演演算法”這東西的用處。
【Case 2】 筆者所在公司今年的校園招聘,本人照例作為 interviewer 參加,面試了幾個來自不同985院校的學生(明年畢業)。順便又和幾位今年剛入職的應屆生聊了聊。
結果發現,所有 interviewee(至少是我碰到的),全都是人工智慧或機器學習方向的學生,所有交流過的新同事,在學校裡做的也全部都是機器學習 or 深度學習演演算法。
而且,每一個人對於入職後工作的期望都是做演演算法。
人工智慧,已經跌入到兩三年前大資料風口上,全民皆“資料科學家”的套路里了。
到底做什麼,算是入行AI?
這個話題其實在筆者之前的幾個chat裡面已經反覆提到過了,在此再說一遍:工業界直接應用AI技術的人員,大致可以分為三個不同角色:演演算法、工程,和資料。
現在各種媒體上,包括 GitChat 中有大量的文章教大家怎麼入行AI,怎麼成為具體某個領域的工程師,告訴大家要在某領域內發展需要掌握的技術棧是什麼,等等……
我們不說怎麼能夠成為XXX,我們先來看看成為XXX之後要做什麼事情,而做這些事情,需要什麼樣的能力,在擁有了這些能力、做上了這件事情之後,又能向什麼方向發展。
換言之,本文中,我們將從直觀的角度,管窺承擔不同角色工作所需要具備的素質,日常工作的狀態,和職業發展路徑。
做演演算法
1.1 日常工作
所有人都想做演演算法,那麼,說到底,在工業界做演演算法倒是乾什麼?
真正的演演算法工程師(也有公司叫科學家),最基本的日常工作其實是:讀論文&實現之——確認最新論文中的闡述是否真實可重現,進一步確認是否可應用於本企業的產品,進而將其應用到實踐中提升產品質量。
1.2 必備能力
既然日常工作首先是讀別人論文。那麼,必不可少,作為演演算法工程師得具備快速、大量閱讀英語論文的能力。
有一個網站,所有有志於演演算法的同學必須要知道:https://arxiv.org ——這裡有多個學科(包括computer science)大量的最新論文。
現在許多科學家、學者、研究人員和博士生在論文剛剛完成,尚未在正式期刊會議上發表時就先將論文釋出在此處,為的是在儘量短的時間延誤下對外傳播自己的成果。
傳統的正規渠道,從論文完成到正式發表之間存在短則三四個月,長則一年半載的延遲。這對一些傳統學科,還勉強可以接受。
但電腦科學,尤其是人工智慧、機器學習、深度學習這幾個當今世界最熱門的主題,大家都在爭分奪秒地搶佔制高點,幾個月的耽擱根本不能容忍。
因此,對於AI的學術性文獻而言,arxiv.org 實際上已經成為了當前的集大成之地。
如果要做演演算法,平均而言,大致要保持每週讀一篇最新論文的頻率。
也許這就是為什麼,到目前為止,筆者所聽聞和見過的演演算法工程師都是名校相關專業博士的原因。
經過幾年強化學術研究訓練,這些博士們,就算英語綜合水平不過 CET-4,也能讀得進去一篇篇硬骨頭似的英語論文!
1.3 自測“演演算法力”
但當然不能說碩士、學士或者其他專業的有志之士就做不成演演算法了。人都不是生而知之,不會可以學嘛。
但是到底能不能學會,其實也並不需要三年五載的時間,花費幾萬十幾萬金錢在各種培訓或者付費閱讀上才能夠知道。
有個很簡單的驗證方法:現在就去https://arxiv.org找一篇論文(比如這篇:[Dynamic Routing Between Capsules](https://arxiv.org/pdf/1710.09829.pdf)),從頭到尾讀一遍。
現在不懂沒關係,至少先試試在不懂的情況下能不能把它從頭到尾一字不漏的讀完,有不認識的字查字典。
如果這都做不到,還是當機立斷和“演演算法”分手吧。既然註定無緣,何必一味糾纏?
1.4 學術實踐能力
如果,碰巧你喜歡讀論文,或者就算不喜歡也有足夠強大的意志力、專註力壓迫自己去強行閱讀論文。那麼恭喜你,你已經跨上了通往演演算法山門的第一級臺階。
下麵一級是:讀懂論文。
既然要讀論文,讀最新論文,而且閱讀的目的是指導實踐,那麼自然要讀懂。拿起一篇論文就達到*懂*的程度,至少需要下麵這三種能力:
1.4.1 回溯學習能力
一篇論文拿來一看,一大堆名詞術語不懂,它們互相之間是什麼關係也不知道。怎麼辦?去讀參考文獻,去網上搜索,去書籍中查詢……總之,動用一切資源和手段,搞清不明概念的含義和聯絡。
這種能力是學術研究的最基礎能力之一,一般而言,有學術背景的人這一點不在話下。
如果現在沒有,也可以去主動培養,那麼可能首先需要學習一下學術研究方法論。
1.4.2 數學能力
如果只是本著學習的目的讀經典老論文,那麼只要清楚文中圖表含義,看公式推導明白一頭一尾(最開始公式成立的物理意義,以及結束推導後最終形式所具備的基本性質)也就可以了。
但讀最新論文就不同。因其新,必然未經時光檢驗,因此也就沒人預先替你驗證的它的正確性。
在這種情況下,看公式就得看看推導了。否則,外一是數學推導有錯,導致了過於喜人的結果,卻無法在實踐中重現,豈不空耗時力?
如果目前數學能力不夠,當然也可以學。但就與後面要說的做工程用到什麼學什麼的碎片化學習不同,做演演算法,需要系統學習數學。
微積分、線性代數、機率統計,是無法迴避的。如果在這方面有所缺乏,那還是先從計算機系的本科數學課開始吧,個人推薦北師大教材。
1.4.3 理論聯絡實際,將學術論述與產品、業務結合的能力
一般來說,在大企業裡做到真正的演演算法工程師/科學家,也就不需要自己去動手開發產品了。但做 demo/prototype 還是不能避免的。
演演算法工程師,可不是用別人寫好的工具填幾個引數去執行就可以的,需要負責實際業務問題到數學模型的抽象,並能夠將他人最新成果(敲黑板——那些論文!!!)應用到業務資料上去。
說得更通俗一點,就算是用別人寫的工具或框架,做演演算法的,也得是i)第一撥、最前沿那批試用者,或者ii)工具最新玩法的發明者。
1.5 創新型人才
演演算法工程師,即使自己不發明新的演演算法,不提出新的演演算法最佳化方法,也得去嘗試最新演演算法的使用或者把已有演演算法用出新花樣來。
毋庸置疑,這是一個有著必然創新性的角色。因此,這個角色必然不適合絕大多數人!
做工程
2.1 日常工作
相對於演演算法的創新和尖端,做工程要平實得多。
這一角色比較有代表性的一種崗位就是:機器學習工程師(或戲稱調參工程師)——他們使用別人開發的框架和工具,執行已有演演算法,訓練業務資料,獲得工作模型。
其間可能需要一些處理資料、選取特徵或者調節引數的手段,不過一般都有據可循,並不需要自己去發明一個XXXX。
做工程也得讀論文,不過和做演演算法不同,做工程讀論文的一般目的不是嘗試最新方法,而是用已知有效的方法來解決實際問題。
這就導致了,做工程的,讀的經常是“舊”論文,或者相對學術含量低一些(不那麼硬)的論文。
而且在閱讀時,主要是為了直接找到某個問題的處理方法,因此,可以跳讀。
對於其中的數學公式,能夠讀懂頭尾也就可以了。論文閱讀頻率和學術深度的要求,都比做演演算法低得多。
TIP:很多title寫的是“人工智慧/機器學習/深度學習演演算法工程師”的招聘崗位,其實招的是做工程的人。不要執著於辭藻,看清楚具體職責和工作內容。
2.2 軟體工程師的分支
說到底,機器學習工程師,是廣義的軟體工程師(或雲程式員)的一個分支。AI產品開發,是廣義軟體開發的一個領域。
說起來,每一個程式員都有一個領域。不過,不同領域在不同時期熱度不同,發展趨勢不同。
若干年前,做*底層*的程式員在程式界睥睨群雄。寫協議棧的、開發驅動的、實現各種系統介面的程式員,站在鄙視鏈的最頂端。
如今,風水輪流轉,昨日黃花已謝,輪到AI封神了。
但說到底,開發人工智慧產品的程式員,也還是程式員。不過是需要懂一定程度的領域內理論知識而已,和以前開發 PCI 協議棧要懂 PCI 協議,寫網絡卡 driver 要懂 TCP/IP 的道理是一樣的。
2.3 程式員的基本素質
既然是程式員,首先就不能丟掉 程式員的基本素質:編碼能力,和基礎演演算法能力(不是前面說的那種演演算法,而是鏈、樹、圖的構建、刪除、遍歷、查詢、排序等資料結構裡講的那種演演算法),是最起碼要求。
其實,在AI成為潮流的今天,只要能找到一個在AI方面相對比較前沿的企業,進去做一名普通程式員。
那麼即使本來開發的產品不屬於AI範疇,未來透過在舊產品上應用新的AI技術,或者在公司內部 transfer 到做 AI 產品的 team,都可能獲得入行的機會。
甚至具體知識的掌握,都可以在入職後慢慢積累——對於大多數AI工程人員,這可能才是一條自然的入行之路。
但這一切的前提是:此人首先得是一個合格的程式員!
而不是本末倒置,雖然花功夫學了幾個模型、演演算法,卻連最基本的程式設計面試題都做不對。
2.4 做工程,「機器學習」學到多深夠用
當然,既然是有領域的程式員,在專業上達到一定深度也是必要的。
雖然做工程一般要使用現成技術框架,但並不是說,直接把演演算法當黑盒用就可以做一名合格的“調參”工程師了。
把演演算法當黑盒用的問題在於:黑盒能夠解決問題的時候,使用方便,而一旦不能解決問題,或者對質量有所要求,就會感覺無所適從。
作為程式員、工程人員,想用機器學習演演算法解決實際問題,就得對演演算法有一定程度的掌握,此外對於資料處理和模型驗證,也需具備相應知識。
2.4.1 演演算法
僅從使用角度而言,掌握演演算法,大致可分為如下由淺入深的幾步:
【1】簡單使用:瞭解某個演演算法基本原理,應用領域,功能和侷限。
-
a) 該演演算法的應用問題域是什麼?(e.g. 分類、回歸、聚類……)
-
b) 該演演算法的應用標的是什麼?(e.g. 判別演演算法、生成演演算法……)
-
c) 該演演算法適合應用在怎樣的資料集,它能對資料造成怎樣的影響?(e.g. 適用少量高維稀疏資料……)
-
d) 能夠主動獲取該演演算法的函式庫,呼叫該演演算法生成模型。
【2】模型調優:對所採用演演算法和對應模型的數學公式有所瞭解。
-
a) 知道呼叫函式中各個引數的意義(e.g. 迭代次數,對應到公式中引數的含義……),能夠透過調節這些引數達到最佳化結果的目的。
-
b) 能夠透過加約束條件(e.g. L0, L1, L2 ……)來最佳化演演算法。
-
c) 瞭解在當前問題域,標的和輸入資料確定的情況下,還可以用哪些其他模型可替換現有模型,併進行嘗試。
-
d) 能夠將多個弱模型加權組成強模型(e.g. adaboost)。
【3】執行效率最佳化:對模型本身的數學推導過程和模型最最佳化方法有所掌握,對於各種最最佳化方法的特點、資源佔用及消耗情況有所瞭解。
-
a) 瞭解演演算法在當前資料集上的執行效率(e.g. 需要進行哪些運算,是否易於被分散式等)。
-
b) 瞭解在其他語言、平臺、框架的工具包中有否同等或近似功能但在當前應用場景下效率更高的演演算法。
-
c) 能夠針對具體場景,透過轉換模型的最最佳化方法(optimizer)來改進執行效率。
2.4.2 資料
僅僅只有演演算法,並不能解決問題。演演算法和資料結合,才能獲得有效的模型。
對於資料,需要從:i). 具有業務含義的資訊,和ii).用於運算的數字,這兩個角度來對其進行理解和掌握。
【1】特徵選取:從業務角度區分輸入資料包含的特徵,並認識到這些特徵對結果的貢獻。
-
a) 對資料本身和其對應的業務領域有所瞭解。
-
b) 能夠根據需要標註資料。
-
c) 知道如何從全集中透過劃分特徵子集、加減特徵等方法選取有效特徵集。
【2】向量空間模型(VSM)構建:瞭解如何將自然語言、圖片等人類日常使用的資訊轉化成演演算法可以運算的資料。
-
a) 能夠把文字、語音、影象等輸入轉化成演演算法所需輸入格式(一般為實數空間的矩陣或向量)。
-
b) 能夠根據資訊熵等指標選取有效特徵。
【3】資料清洗和處理:對直接的業務資料進行篩選並轉換為模型可處理形式。
-
a) 能夠運用統計學方法等ETL手段清洗輸入資料。
-
b) 能夠對資料進行歸一化(normalization), 正則化(regularization)等標準化操作。
-
c) 能夠採用bootstrap等取樣方法處理有限的訓練/測試資料,以達到更好的運算效果。
2.4.3 模型驗證
演演算法+資料就能夠得到模型。但是,
-
這個模型的質量如何?
-
這個模型和那個模型比較,哪個更適合解決當前問題?
-
在做瞭如此這般的最佳化之後得出了一個新的模型,怎麼能夠確認它比舊的模型好?
為瞭解答這些問題,就需要掌握度量模型質量的方法。為此,需要做到:
-
i) 瞭解 bias,overfitting 等基本概念,及針對這些情況的基本改進方法。
-
ii) 瞭解各種模型度量指標(e.g. Accuracy, Precision,Recall, F1Score……)的計算方法和含義,及其對模型質量的影響。
-
iii) 能夠構建訓練集、測試集,併進行交叉驗證。
-
iv) 能夠運用多種不同的驗證方法(e.g. 2-Fold cross-validation,K-Fold cross-validation, Leave-One-Out cross-validation……)來適應不同的資料集。
做資料
此處說得做資料並非資料的清洗和處理——大家可以看到做工程的崗位,有一部分工作內容就是 ETL 和處理資料。此處說的做資料是指資料標註。
3.1 標註資料的重要性
雖然機器學習中有無監督學習,但在實踐領域被證明有直接作用的,基本上還都是有監督模型。
近年來,深度學習在很多應用上取得了巨大的成功,而深度學習的成功,無論是影象、語音、NLP、自動翻譯還是AlphaGo,恰恰依賴於海量的標註資料。
無論是做ML還是DL的工程師(演演算法&工程),後者有甚,都共同確認一個事實:現階段而言,資料遠比演演算法重要。
3.2 資料人工標註的必要性
很多人誤以為 AlphaGo Zero 100:0大勝 AlphaGo 是無監督學習的勝利。
其實,之所以有這樣的結果,恰恰是因為 Zero 利用圍棋嚴格完備而明晰的規則,自己製造出了巨大量的標註資料——這些標註資料的數量遠超其前輩 AlphaGo 的輸入,而且可以隨時造出更多。
圍棋是一個人為定義的在19×19點陣範圍內,按完備無二義性規則執行的遊戲,因此計算機程式才能依據規則自動產生標註資料。
真實人類世界的事情,基本沒有完全按矩而行無意外的情況。因此,對人類真正有用的模型,還是需要人工標註的訓練資料。
固然,目前有多種技術用以在標註的過程中輔助人工,以減小工作量及降低人工標註比例。但至今沒有能在應用領域完全自動化標註的技術出現。
換言之,在看得見的未來之內,人工標註資料仍然是AI落地的必要和主流。
3.3 人工智慧的“勤行”
3.3.1 什麼叫做標註
舉個很簡單的例子說明一下什麼是資料標註:
在開發聊天機器人的時候,我們需要訓練意圖判定和物體識別模型,因此也就需要標註使用者問題的意圖和出現的物體。
這是使用者問題原始資料:“00183號商品快遞到伊犁郵費多少?”
這樣一句話,很顯然問它的使用者是想知道某一種商品發往某地的郵費。郵費是商品的一個屬性,我們把所有查詢商品屬性的意圖都定義為“商品查詢”。
因此,這樣一句話的意圖是“商品查詢”。其中有包含了幾個物體,分別是商品Id,目的地和商品屬性。
這句話被標註出來以後,就是下麵這個樣子:
[00183]
具體格式不必糾結。核心一點:標註就是將原始資料內全部或者部分內容,按照業務需求打上定義好的標簽。
3.3.2 資料標註的日常工作
簡單說:資料標註的日常工作就是給各種各樣的資料(文字、影象、影片、音訊等)打上標簽。
【好訊息】:資料標註工作幾乎沒有門檻。一般任何專業的大學畢業生,甚至更低學歷,都能夠勝任。上手不需要機器學習之類的專業知識。
【壞訊息】:這樣一份工作,是純粹的“臟活累活”,一點都不cool,起薪也很低。
打個不太恰當的比喻:
做演演算法是屠龍,仗劍江湖,天外飛仙;
做工程是狩獵,躍馬奔騰,縱酒狂歌;
做資料是養豬,每天拌豬食清豬糞,一臉土一身泥。
所以,雖然這是一件誰都能幹的工作,但是恐怕,沒幾個人想乾。
3.3.3 資料標註的難點
就單個任務而言,資料標註是一項很簡單的工作。它的難點在於資料的整體一致性,以及與業務的集合。
【1】資料一致性是指:所有資料的標註原則都是一樣的。
當資料很多的時候,一致性是相當難以保證的,尤其是在有精標需求的情況下。
如果一份 raw data 由多個人同時標註,就算是反覆宣講標註原則,每個人也都有自己的理解和側重,很難保證一致,很可能一句話在某個人看來是“查詢商品”,而在另一個人看來就是“要求售後”。(即使是將所有資料交給一個人,也可能在不同時間段理解不同。)
出於對資料標註工作的不重視(正好與對演演算法的過分重視相映成趣),很多公司外包了資料標註工作。
對於資料標註的不一致性,則採取一種暴力解決方案:讓多個人(比如3個)同時標註同一份資料,一旦出現不一致,就採用簡單多數法,取最多人一致認定的那種結果(比如:3個人中兩個都選“查詢商品“,則選定”查詢商品“為最終 label)。
這種方案對於粗標資料還可以起到一定作用,但如果是精標,則往往連多數人一致的情況都難以出現。
如果三個人所標結果完全不一樣,那麼這條資料也就失去了標註價值。
在現實中,經常會出現同一份資料因為質量過低,被要求重覆標註的情況出現,費時費力。
【2】與業務的集合是資料標註面對的另一個挑戰。
這一點在目前還不是很明顯。因為:目前人工智慧的落地點還比較有限,真正的商業化領域也就是語音和影象處理的少數應用;
owner 都是大公司,有自己的標註團隊,或者僱傭有長期合作關係的第三方標註公司,標註人員都相對有經驗;
業務要求也相對穩定,所需資料標註又相對通用化,普通人都不難理解資料含義和標註原則。
一旦未來人工智慧的落地點在各個領域全面鋪開,很可能需要的是針對具體企業、具體業務,不斷變更的標註需求。
標註這件事情看似容易,但是一旦標註原則有所改變,就要整個重新來過。以前的標註不但不是積累,反而是累贅。
如何應對快速變更的業務需求,同步更新標註結果,將是一個在AI真正服務於大眾時全面爆發的問題。偏偏現階段還未引起足夠重視。
3.3.4 資料標註的潛力
就目前而言,資料對模型的影響遠勝於演演算法。一群年薪百萬起步的演演算法工程師耗費經年的成果,對於模型質量直接的影響甚至比不上一個靠譜標註團隊一兩個月的精心標註。對模型的影響尚且如此,更何況是商業價值。
此時此刻,AI 在風口浪尖,大公司、拿了巨額風投的獨角獸 startup,一個個拿出千金市馬骨的氣概,將不可思議的高薪狠狠砸向 AI 領域的頂尖學者,順便捧起了一批年輕的博士,也引來了世人的垂涎。
這種情形能維持多久?商業企業能承受多少年不掙錢只燒錢?待潮湧過後,行業回歸理性,模型還是要用來掙錢的。
到了那個階段,大小企業不會去算成本收益嗎?他們會意識不到將資源投入資料和演演算法的不同產出比嗎?
企業為了創造利潤應用AI技術,演演算法工程師不是剛需,而資料標註這個人工智慧領域的“勤行”,人工智慧藍領,一定是剛需!
一切標註工作的難點和潛藏的風險,也就是這項工作的潛力和從事這項工作未來職業發展的可能性所在。
認清形勢,腳踏實地
近來一段時間,能明顯感到,想入行AI的人越來越多,而且增幅越來越大。
為什麼這麼多人想入行AI呢?真的是對電腦科學研究或者擴充套件人類智慧抱著無限的熱忱嗎?說白了,大多數人是為了高薪。
人們為了獲得更高的回報而做出選擇、努力工作,原本是非常正當的事情。關鍵在於,找對路徑。
尋求入行的人雖多,能真的認清市場當前的需求,瞭解不同層次人才定位,並結合自己實際尋找一條可行之路的人太少。
人人都想“做演演算法”,卻不想想:大公司裡的研究院養著一群高階科學家,有得是讀了十幾二十年論文始終站在AI潮頭的資深研究人員。
想要與他們為伍做演演算法,須有可以與之併列的成就:要麼有足夠分量的學術成果,要麼解決過大使用者量產品的實際業務問題——你佔哪一條呢?
僅僅是學過課程,做過練習或實習性質的小專案,是不足以去做演演算法的。
誰在自己的想象世界裡不是屠龍的劍客?但現實當中能屠龍的人又有幾個?留給人去屠的龍又有幾條?養豬雖然沒那麼高大上,有豬肉吃是實實在在的。
好高騖遠只會虛擲光陰,腳踏實地才能實現理想——這也是筆者寫作此文的初衷。
入門 AI,先吃透「機器學習」
首先,我們來看一下當前機器學習領域招聘市場的行情。
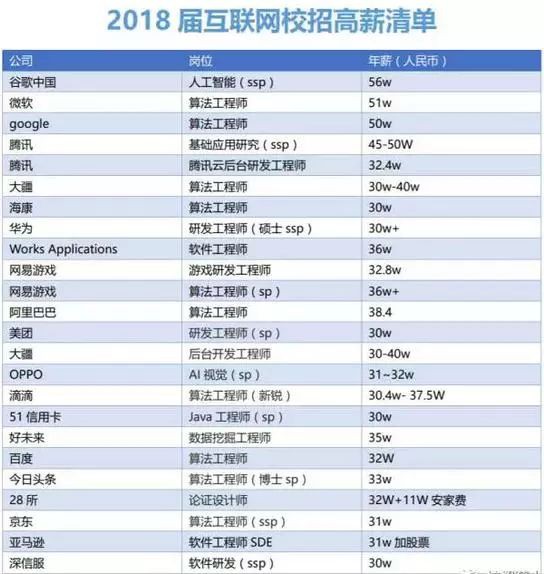
上面表格中所有帶有“演演算法”、“人工智慧”、“資料挖掘”、“視覺”字樣的職位,都需要懂機器學習。
在產品和服務中應用機器學習模型,已經逐步成為了網際網路行業的通行方法。甚至很多傳統軟體企業,也開始嘗試應用機器學習。
說得更直接一點,人工智慧正處在炙手可熱的風口浪尖上,作為程式員不會機器學習都不好意思去找工作了。
很多技術開發者迫切希望快速進入人工智慧領域,從事工程或者演演算法等相關工作。
從「模型」入手
針對機器學習初學者,我們可以從機器學習、深度學習最基本的原理及學習意義入手,以模型為驅動,吃透幾大最經典的機器學習模型——學習其原理、數學推導、訓練過程和最佳化方法。
以【機器學習極簡入門】為例的設定:
1. 有監督學習:
-
詳細講解有監督學習中經典的線性回歸、樸素貝葉斯、邏輯回歸、決策樹、支援向量機、支援向量回歸、隱馬爾科夫和條件隨機場模型。
2. 無監督學習
-
重在詳細講解無監督學習中的聚類、高斯混合及主成分分析等模型。
3. 從機器學習到深度學習。
-
講解深度學習基本原理、深度學習與機器學習的關聯與銜接、以及深度學習目前的應用領域,為「深度學習」的進階奠定基礎。
配合精心設計的極小資料量的「極簡版」實體,方便讀者從直觀上瞭解模型的執行原理,利用實體大家還可將自己變身為「人肉計算機」,透過口算/筆算每一步的推導,模擬演演算法全過程,進而徹底理解每個模型的運作方式。
從【機器學習極簡入門】可以收穫什麼?
(1)AI 技術崗位求職知識儲備
如果大家真的有意投身到人工智慧領域做技術性工作,那麼經過技術筆試、面試是必要條件。
在面試中被要求從頭解釋某一個機器學習模型的執行原理、推導過程和最佳化方法,是目前非常常見的一種測試方法。
機器學習模型雖然很多,但是經典、常用的很有限。如果能把這個課程中講解的經典模型都學會,用來挑戰面試題相信是足夠了。
(2)觸類旁通各大模型與演演算法
各種機器學習模型的具體形式和推導過程雖然有很大差別,但卻在更基礎的層面有許多共性。
掌握共性之後,再去學新的模型、演演算法,就會高效得多。雖然本課的第二部分集中描述了部分一般性共同點,但真要理解個中含義,卻還要以若干具體模型為載體,經由學習其從問題發源,到解決方案,再到解決方案的數學抽象,以及後續數學模型求解的全過程,來瞭解體味。這也就是本課以模型為驅動的出發點。
(3)極簡版實體體驗實際應用
運用到實踐中去,是我們學習一切知識的目的。機器學習本身更是一種實操性很強的技術,學習它,原本就是為了應用。反之,應用也能夠促進知識的深化理解和吸收。
本課雖然以原理為核心,但也同樣介紹了:劃分資料集;從源資料中提取特徵;模型訓練過程;模型的測試和評估等方法和工具。
(4)配套資料+程式碼快速實操上手
本課程中各個實體的 Python 程式碼及相應資料,大家可以下載、執行、改寫、參考。
除了上述幾點,我希望本課的讀者在知識和技巧的掌握之外,能夠將學習到的基本規律運用到日常生活中,更加理性地看待世界。
再遇到“人工智慧產品”,能夠根據自己的知識,去推導:How it works——
它背後有沒有用到機器學習模型?如果有的話是有監督的還是無監督的模型?是分類模型還是回歸模型?選取的特徵會是哪些?如果由你來解決這個問題,有沒有更好的方法?……
掃碼試讀
《機器學習極簡入門》

訂閱福利
-
限時特價 29 元,2018.6.14 日零時恢復至原價 49 元。
-
訂購本課程可獲得專屬海報,分享專屬海報每成功邀請一位好友購買,即可獲得 25% 的返現獎勵,多邀多得,上不封頂,立即提現。
GitChat
「1000000 粉絲」成就達成
超級會員 5 折起

